

家人们,我是远景。
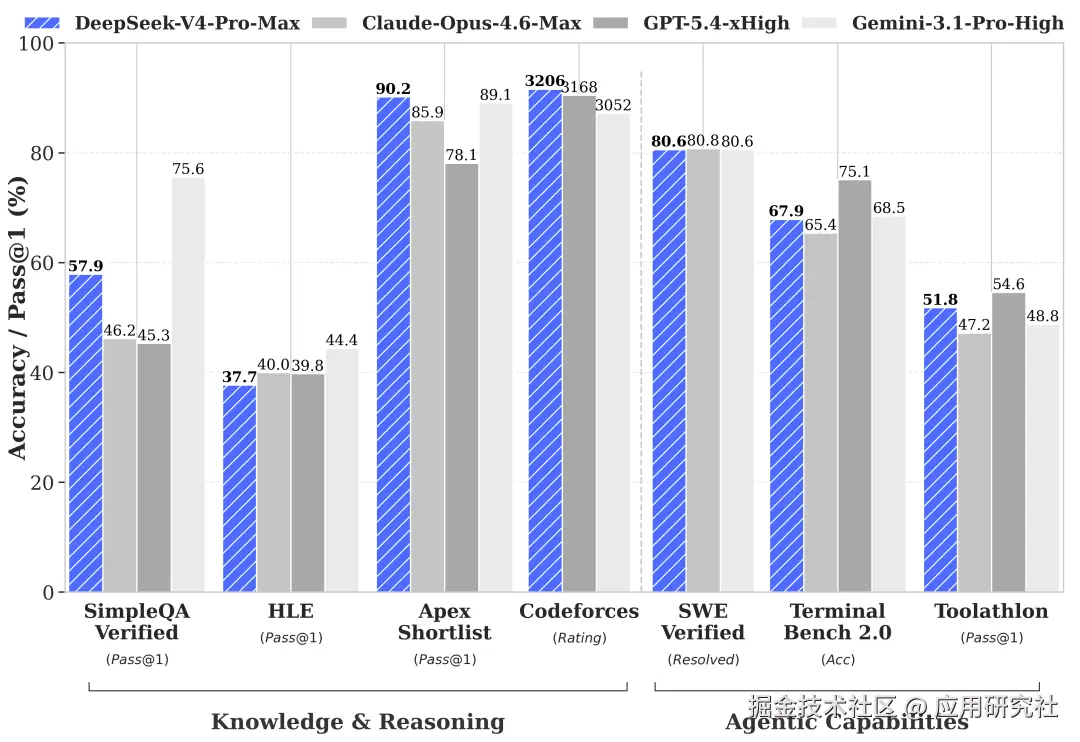
上周四 DeepSeek V4 发布的时候,我正调试一段屎山代码,看到 Codeforces 3206 这个数字,手直接停住了。
3206 什么概念?追平 GPT-5.5,开源模型第一次在编程赛道跟闭源旗舰掰手腕。
发布会没看完我直接去调 API 了。用了快一周,代码跑通了,坑也踩了,今天跟你们说实话。看看它到底是真实力还是 PPT 货色。
01 两个版本,到底该怎么选?
之前很多人吐槽 DeepSeek 的模型命名混乱,什么 chat、reasoner,搞得开发者一脸问号。这次 V4 直接来了个双版本策略,清晰明了:
版本 | 总参数量 | 激活参数 | 定位 | 价格(输入/输出 每百万token)
V4-Pro | 1.6万亿 | 490亿 | 旗舰版,性能拉满 | ¥12 / ¥24
V4-Flash | 2840亿 | 130亿 | 经济版,速度快 | ¥1 / ¥2
两个版本都是 MoE 架构,都支持 100 万 token 上下文。更良心的是,这次采用 MIT 开源协议,任何人、任何公司都能免费下载、修改、商用。
定价策略挺狠的。
V4-Flash 的价格只有 GPT-5.5 的约 1/9,Claude Opus 4.6 的约 1/25。
用 Claude 写 100 万字的钱,够你用 V4-Pro 写 2100 万字——这已经不是性价比了,这是价格屠杀。
02 技术亮点:这几个突破确实硬核
1. 百万上下文成标配
V4 这次把上下文窗口从 V3 的 128K token 直接拉到了 100 万 token,翻了将近 8 倍。
更关键的是,DeepSeek 不是靠堆算力硬撑的,而是用了自研的混合注意力架构(Hybrid Attention,含 DSA 稀疏注意力机制)。官方数据显示:处理 100 万 token 时,算力消耗仅为 V3.2 的 27%,KV Cache 占用降至传统方法的 10%。
翻译成人话就是:长上下文不再烧钱,老板终于可以笑了。
2. MoE 架构再进化
V4 延续并升级了混合专家(MoE)架构。1.6T 总参数中,每次推理只激活 49B,激活率仅 3%。
这就好比一家公司有 16000 名员工,但每次只派 490 个精英上场——剩下的 15510 人喝茶摸鱼,节省了大量"工资"(算力)。
V4-Flash 更极致,284B 总参、13B 激活,用更少的资源干更多的活。
3. 编程能力:Codeforces 3206 分,追平 GPT-5.5
这是最震撼的数据:
V4-Pro 在 Codeforces 竞赛中拿到 3206 分,超越 GPT-5.4 的 3168 分,是开源模型首次在编程赛道超越闭源旗舰之一!
完整榜单对比:
模型 | Codeforces 分数
DeepSeek V4-Pro | 3206
GPT-5.4 | 3168
Gemini 3.1 Pro | 3052
另外几个关键指标:
-
SWE-Bench Verified:80.6% 通过率,仅比 Claude Opus 4.6 的 80.8% 低 0.2 个百分点
-
LiveCodeBench:Pass@1 达 93.5%,创开源模型历史新高
-
Agentic Coding:达到开源模型最佳水平,接近 Claude Opus 4.6 非思考模式
DeepSeek 内部调研显示,85 名天天使用 V4 的工程师和研究员中,91% 认为 V4 已达到闭源模型水平。这个数字比我预期的还要高。
 4. 华为昇腾适配
4. 华为昇腾适配
V4 首次明确披露已适配华为昇腾芯片。在当前芯片持续收紧的背景下,DeepSeek 这一手意味着什么不言自明——它不仅是"中国最强开源模型",更是首个能在国产算力上跑的前沿级 AI 模型。
华为在模型发布当天宣布,昇腾超节点全系列产品全面支持 DeepSeek V4 系列模型,实现模型发布与算力适配同步推进。
03 实战!API 调用代码示例
说了这么多,不如直接上手跑代码来得实在。
pip install openai
基础调用(V4-Flash,轻量快)
from openai import OpenAI
client = OpenAI(
api_key="your-deepseek-api-key", # 去官网申请
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "你是一个专业的 Python 编程助手"},
{"role": "user", "content": "用 Python 实现一个高效的 LRU 缓存,要求 O(1) 时间复杂度"}
],
max_tokens=1024,
temperature=0.7
)
print(response.choices[0].message.content)
开启深度推理(数学/算法类任务用)
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "user", "content": "证明:任意偶数可表示为两个质数之和(哥德巴赫猜想弱形式)"}
],
extra_body={
"reasoning_effort": "high" # low / medium / high / max
},
max_tokens=4096
)
print(response.choices[0].message.content)
百万上下文实测(整本书丢进去)
with open("three_body.txt", "r", encoding="utf-8") as f:
book = f.read()
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "你是专业文学分析师"},
{"role": "user", "content": f"分析关键人物、情节转折点、主题:\n\n{book}"}
],
max_tokens=4096,
temperature=0.3
)
print(response.choices[0].message.content)
注意:旧版模型名 deepseek-chat 和 deepseek-reasoner 将于 2026 年 7 月 24 日停用,建议现在就开始迁移到新模型名。
04 Pro 还是 Flash?
很多同学纠结选哪个,我给个实用的判断标准:
场景 | 推荐版本 | 原因
日常问答、内容摘要、轻量客服 | Flash | ¥1/百万token,延迟低
代码生成、Code Review | Flash | 简单任务差距不大
复杂数学推理、竞赛编程 | Pro | 推理深度明显更强
多文件重构、长文档(>150K token) | Pro | 长上下文信息召回更高
高并发线上服务 | Flash | 延迟低、吞吐高
一个实用的生产策略:用 Flash 做默认模型扛 80% 的流量,遇到复杂任务或者用户主动触发"深度思考"时,路由到 Pro。这样成本能压到最低,体验又不打折。
05 我的观点:这次 V4 到底是什么水平?
说实话,用了一段时间 V4,我最大的感受是:DeepSeek 越来越懂开发者了。之前用其他模型,总有种"我在迁就 AI"的感觉;但 V4 不一样,它的反馈更直接,代码更实用。
几个具体的感受:
✅ 强项:
-
编程能力确实强,Codeforces 3206 分不是吹的
-
价格太香了,中小团队也能用上顶级模型
-
百万上下文是真的能用,不是噱头
-
开源 + 华为昇腾适配,国产化这条路走得稳
⚠️ 弱项:
-
预览版稳定性有待观察,官方跑分不等于所有场景都这样
-
知识类任务仍落后 Gemini 3.1 Pro,"知识最全"不是它的定位
-
暂不支持多模态(图像、视频),想要文生图还得找 GPT 或 Gemini
-
本地部署门槛不低,V4-Pro 约 865GB,不是普通机器能跑的
总结一下我的判断:如果你做的是文本推理 + 编程 + 中文能力 + 极致性价比,V4 是 2026 年的最优解之一。但如果你需要多模态或顶级知识问答,闭源模型仍有优势。
DeepSeek V4 的发布让我想到一个比喻:之前的 AI 行业像是一场军备竞赛——谁家 GPU 多,谁家参数大,谁家就牛。但 DeepSeek 一直在用更聪明的算法做更多的事,而不是靠堆算力硬撑。
当 OpenAI 还在卖 GPT-5.5 的 API 时,DeepSeek 已经把前沿模型的门槛拉到了"白菜价"。这种算力效率的革命,可能比单纯的性能突破更有意义。
记住一句话:没有最好的模型,只有最适合你场景的选择。
以上就是今天 DeepSeek V4 的深度解读,核心要点帮大家梳理好了:百万上下文全系标配、Codeforces 3206 分追平 GPT-5.5、双版本策略总有一款适合你。
评论区说说你最想用 V4 跑什么任务?有疑问尽管留言,我逐一回复。
关注微信公众号【应用研究社】,星标不迷路~
