

模型越大 vs 模型越近:从 DeepSeek V4 看 AI 的两条技术路线
4 月 27 日,DeepSeek 发布了 V4 系列模型。V4-Pro Base 版参数量达到 1.6 万亿,即便是激活参数也有 862B;轻量版 V4-Flash 同样达到 158B(Base 292B)。模型上线 HuggingFace 不到 48 小时,V4-Pro 已经获得超过 3000 次点赞和 17 万次下载。
万亿参数开源模型时代正式到来了。
但这篇文章不是 V4 的评测报告。我们想借这个节点,聊一个更底层的问题:AI 模型的发展方向,是不是只有"越大越好"这一条路?
Scaling Up:越大越好的逻辑
先说清楚 Scaling Up 的合理性,因为它确实在持续被验证。
2020 年 OpenAI 发表 Scaling Laws 论文,提出了一个核心观察:模型性能与参数量、数据量、计算量呈幂律关系。参数越多,数据越大,模型的能力越强——而且这种关系在相当大的范围内是稳定的。
从 GPT-3(175B)到 GPT-4,从 DeepSeek V2 到 V3 再到 V4(1.6T),每一代模型的参数量都在大幅增长,能力也确实在跟着涨。V4 的发布再次验证了这条路线:万亿参数的 MoE 架构在通用语言理解、代码生成、数学推理等任务上,确实把天花板又抬高了一截。
Scaling Up 的工程实现也在进步。MoE(Mixture of Experts)架构让万亿参数成为可能——不是所有参数都同时参与计算,而是通过路由机制只激活一部分专家网络,V4-Pro 的 1.6T 总参数实际推理时只激活 862B。加上分布式训练、通信优化、混合精度等工程手段,训练万亿参数模型的门槛在持续降低。
这条路线的成功是实在的,不需要回避。
但 Scaling Up 的边界也在显现
在肯定 Scaling Up 成就的同时,几个现实问题也越来越无法回避:
推理成本和算力门槛。 V4-Pro 1.6T 参数的推理需要多卡 GPU 集群。即便通过 Together、Novita 等推理服务商使用,每次 API 调用都有成本。对于需要高频调用的场景(实时交互、批量处理、持续运行的 Agent),成本会快速累积。个人开发者更不用说——你的 Mac 上跑不了 1.6T 参数的模型。
数据安全和隐私。 大模型运行在云端,意味着用户输入的数据需要离开本地设备。对于涉及屏幕截图、操作记录、企业内部数据的场景,这是一个绕不过去的合规问题。尤其是 AI Agent 场景下——Agent 需要"看到"用户屏幕上的所有内容,这些数据是否应该传到云端?
响应延迟。 云端推理受网络状况影响。在需要毫秒级响应的实时交互场景中,网络延迟可能成为瓶颈。对于需要连续执行数十步操作的 Agent 场景,每一步的延迟都会累积。
可用性边界。 没有网络就没有 AI。但很多真实使用场景——飞机上、保密网络中、网络不稳定的环境里——恰恰需要 AI 能力。
这些不是 Scaling Up 的"缺陷"——大模型在通用推理和复杂生成任务上的能力目前仍然无可替代。但这些边界意味着:不是所有场景都应该用同一种方案。
Scaling Out:另一条正在加速的路线
如果 Scaling Up 是"把一个模型做得越来越大",那另一条路线可以概括为 Scaling Out——让更多小而专精的 AI 分布在离用户更近的地方,通过协作完成任务。
Scaling Out 的核心逻辑不是否定大模型,而是换一个维度来思考 AI 的部署方式:
与其把所有能力塞进一个巨型模型运行在远端,不如让多个专精模型分布在不同设备和节点上,各自处理自己擅长的事情,必要时通过网络协作。
这个方向已经有清晰的技术基础在支撑:
模型压缩与端侧推理。 混合精度量化(如 w4a16)、视觉 token 剪枝、知识蒸馏等技术,让原本只能在服务器上运行的模型可以压缩到消费级硬件上。Apple M 系列芯片的 GPU 和 Neural Engine 提供了相当可观的本地推理算力。一个 4B 参数的量化模型,在 M4 芯片上可以做到 476 tokens/s 的 prefill 速度和 76 tokens/s 的 decode 速度,峰值内存只需 4.3GB。
垂直场景的专精模型。 通用大模型用一套参数覆盖所有任务;而专精模型只解决一个领域的问题,可以用更少的参数做到更高的精度。这不是理论推演——在 GUI 自动化领域,4B 参数的专精模型已经在特定评测中超过了参数量是它数百倍的通用模型。
多 Agent 协作框架。 多个 Agent 各自处理一个子任务,通过标准化协议互相通信,共同完成一个复杂流程。这种架构天然适合 Scaling Out——每个 Agent 可以运行在不同的设备或节点上,不需要集中到一台服务器。
数据主权。 模型运行在用户自己的设备上,数据不需要离开本地。这在个人隐私保护和企业合规场景中,是一个结构性优势。
两条路线的技术对比
| 维度 | Scaling Up | Scaling Out |
|---|---|---|
| 核心策略 | 增加模型参数和训练数据 | 压缩模型 + 分布在端侧/边缘节点 |
| 典型代表 | DeepSeek V4、GPT-4、Claude | 端侧 Agent、专精视觉模型、联邦学习 |
| 运行位置 | 云端 GPU 集群 | 用户设备、边缘服务器 |
| 算力要求 | 多卡 GPU、分布式推理 | 消费级硬件(如 Apple M4 芯片) |
| 数据流向 | 用户数据 → 云端 → 返回结果 | 数据不出设备,本地推理 |
| 响应延迟 | 受网络状况影响 | 本地推理,毫秒级响应 |
| 适用场景 | 通用推理、复杂生成、跨领域任务 | 隐私敏感、实时交互、离线环境、垂直任务 |
| 协作方式 | 单一模型处理全部任务 | 多个专精模型分工协作 |
这不是一个"谁好谁坏"的判断,而是两条路线各自解决不同层级的问题。Scaling Up 提供通用智能的底座,Scaling Out 让 AI 能力真正落地到终端场景。
一个具体案例:GUI Agent 领域的 Scaling Out
把讨论拉回具体场景。
GUI 自动化——让 AI 像人一样看屏幕、操作界面——是一个天然适合 Scaling Out 的方向。原因很直接:
-
GUI 操作需要实时响应。 用户屏幕上的界面状态在持续变化,Agent 需要快速识别、快速决策、快速执行。每一次"截屏→理解→操作"的循环都应该尽量短。
-
屏幕截图涉及隐私。 Agent 为了理解界面需要截取完整屏幕,截图中可能包含邮件、聊天记录、银行页面等敏感信息。这些数据在本地处理比传到云端安全得多。
-
操作步骤多,延迟会累积。 一个完整的 GUI 自动化任务可能包含数十到数百步操作。如果每一步都需要云端往返,总延迟会严重影响效率。
在这个方向上,明略科技开源的 Mano-P(Apache 2.0 协议)是一个值得关注的实践。Mano-P 是一个面向边缘设备的 GUI-VLA(Vision-Language-Action)Agent,核心思路是将视觉理解、语言推理和动作执行整合在一个端到端的模型中,完全运行在用户的 Mac 上,数据不出设备。
技术路线上,Mano-P 采用双向自强化学习框架,经过 SFT → 离线强化学习 → 在线强化学习三阶段训练,配合 think-act-verify 循环推理机制和 GS-Pruning 视觉 token 剪枝。
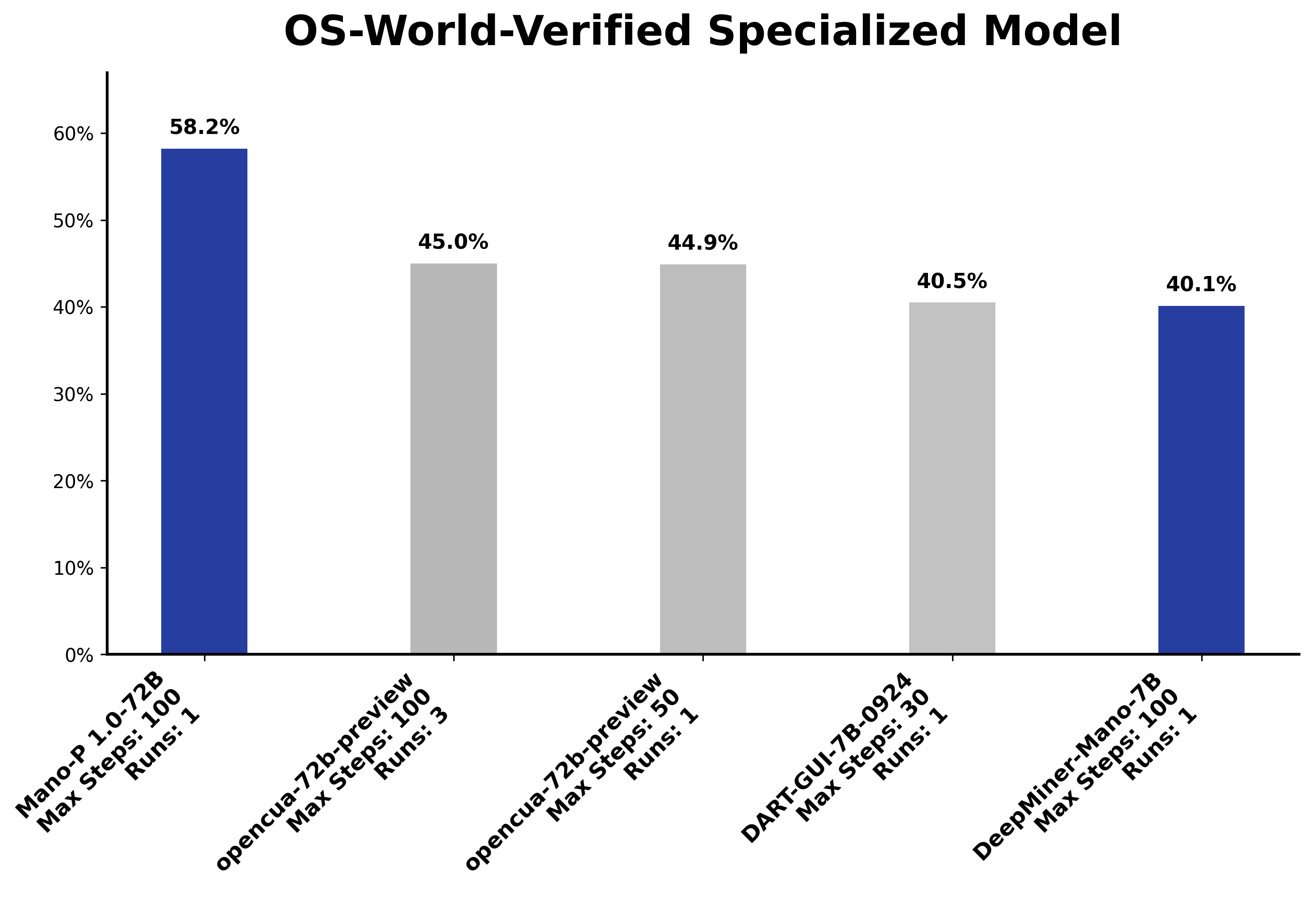
公开评测数据(标注评测基准和模型规格):
- Mano-P 72B 模型在 OSWorld 基准测试中达到 58.2% 准确率(排名第一,第二名 45.0%)
- 在 WebRetriever Protocol I 评测中达到 41.7 NavEval 分(排名第一),超过 Gemini 2.5 Pro(40.9)和 Claude 4.5(31.3)
- 4B 量化模型(w4a16)在 Apple M4 芯片上运行:prefill 476 tokens/s,decode 76 tokens/s,峰值内存 4.3GB
硬件要求:Apple M4 芯片 + 32GB RAM 的 Mac,或通过 Mano-P 算力棒(USB 4.0+)扩展。
这组数据说明一个事实:在 GUI 自动化这个垂直场景下,4B 参数的专精模型在端侧运行,已经可以达到领域顶尖的性能水平。 不是所有任务都需要万亿参数。
结论:两条路线不是对立,是生态分层
DeepSeek V4 的发布是一个里程碑——万亿参数的开源模型证明了 Scaling Up 的持续有效性。但与此同时,Scaling Out 方向也在加速,端侧模型、专精模型、多 Agent 协作框架都在快速成熟。
这两条路线不是非此即彼的选择。更合理的理解方式是 生态分层:
- 云端大模型:作为通用智能底座,处理复杂推理、跨领域生成、长文本理解等高算力需求任务
- 端侧专精模型:作为执行层,处理隐私敏感、实时交互、垂直场景的任务,数据不出设备
两层之间可以协作:端侧模型处理本地任务,遇到超出能力范围的请求时再调用云端模型。
对于开发者来说,关注点不应该只是"模型参数有多大",还应该包括"模型离我的场景有多近"。万亿参数是一个方向,4.3GB 内存跑通完整工作流也是一个方向。
相关资源:
Mano-P 开源仓库(Apache 2.0):github.com/Mininglamp-…
你在做 AI 应用开发时,更关注模型能力的上限(Scaling Up)还是部署场景的适配度(Scaling Out)?
