

企业 Agent 的第一公里,不是聊天框,而是文档资产化
很多企业做 Agent,一上来就做三件事:接大模型,搭工作流,做聊天框。
看起来很对。但真正落地时,第一个卡点往往不是模型
而是👉 企业最重要的知识,Agent 根本"吃"不进去。
一个被反复忽略的事实
企业知识,大多数不在对话里,它们在:PDF、扫描件、Excel、PPT、SOP、制度文件、合同附件、各种截图和长图文....
这些内容 —— 人能看懂,但Agent 未必能看懂
所以问题本质不是:
Agent 会不会回答?
而是:
企业知识,是否进入了 Agent 能用的形态?
为什么"上传文件 + 问答"一定会卡住?
几乎所有知识库 Demo,都是这么做的:上传文档切 chunk做向量开始问答
一开始效果很好。但很快你会发现:这张表解析对了吗?这个答案引用的是哪一页?版本对不对?权限谁来控制?跨页表格怎么办?印章、公式、截图里的内容怎么办?
👉 这些问题,不是模型问题。是数据问题。因为你处理的,只是"文本",不是"文档"。
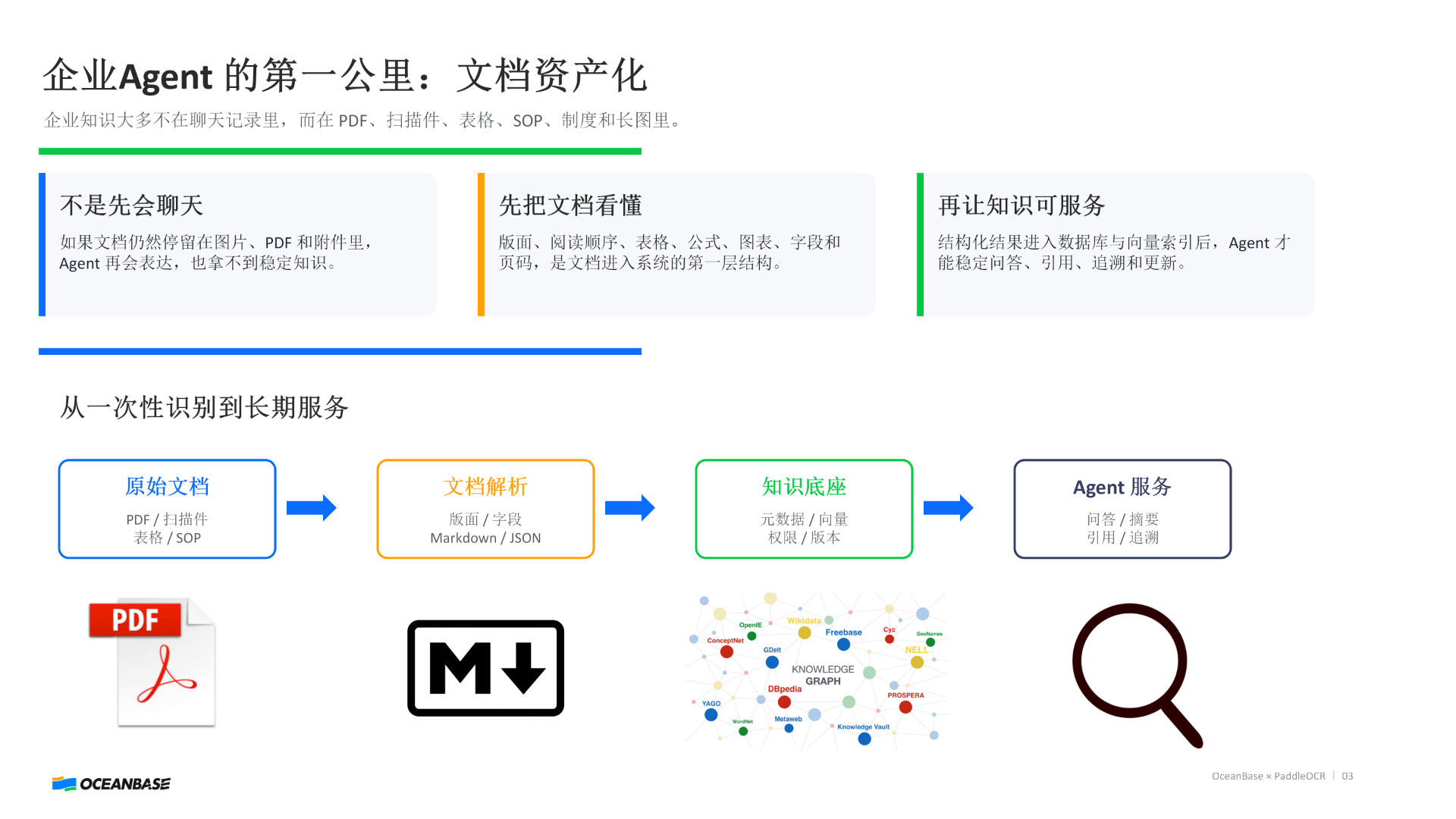
真正的分水岭:从"附件"到"资产"
一份文档,会经历三个阶段:👉 附件👉 文本👉 知识资产
只有第三阶段,才能真正进入 Agent。
这背后其实是一条完整链路:企业****文档(PDF / 图片 / Office)→ OCR + 文档解析 → 结构化数据(Markdown / JSON / 字段)→ **OceanBase **(数据库 + 向量 + 权限 + 版本) → A****gent 服务(问答 / 引用 / 审计 / 更新)
👉 这条链路,才是企业 Agent 的第一公里。
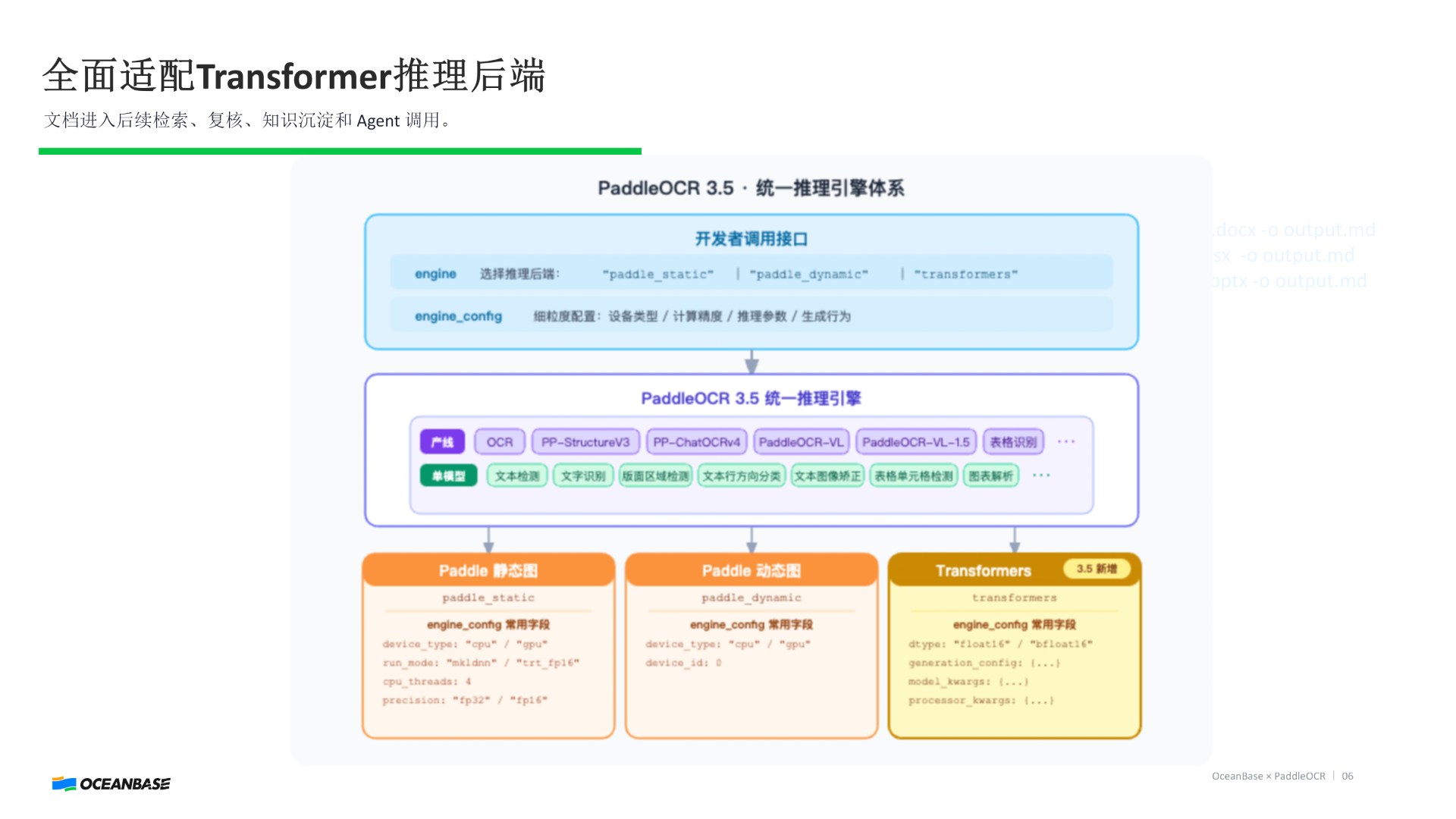
PaddleOCR 3.5:不是更准,而是"接入工程入口"
很多人以为 OCR 只是一个模型能力。但 PaddleOCR 3.5 做的事情,本质是:👉 把 OCR 接进系统入口
三件事最关键:
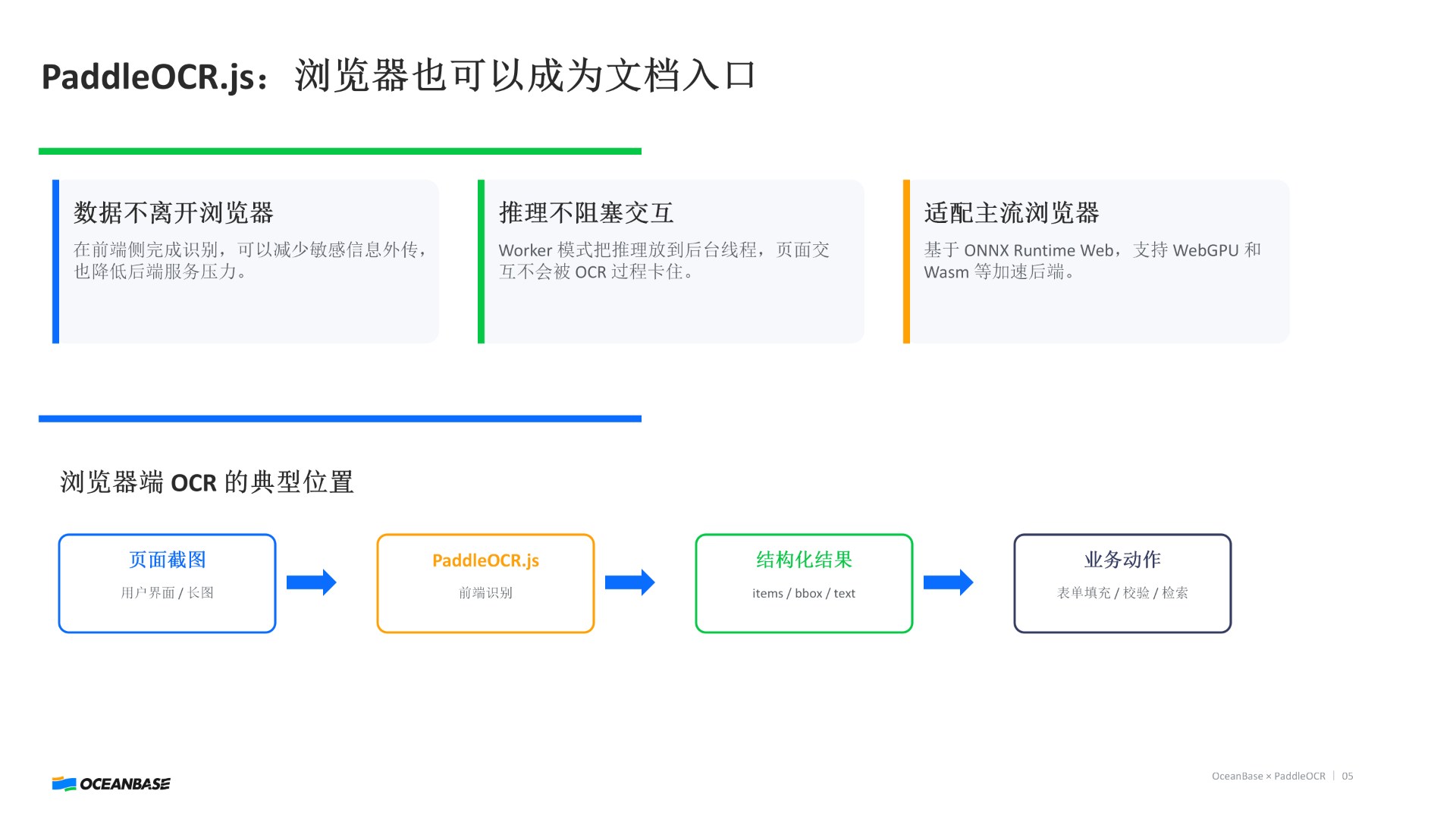
1️⃣ 浏览器入口(PaddleOCR.js)
OCR 可以直接跑在前端,意味着:截图 → 直接识别用户上传 → 直接解析敏感数据 → 不出端
👉 浏览器,变成文档入口
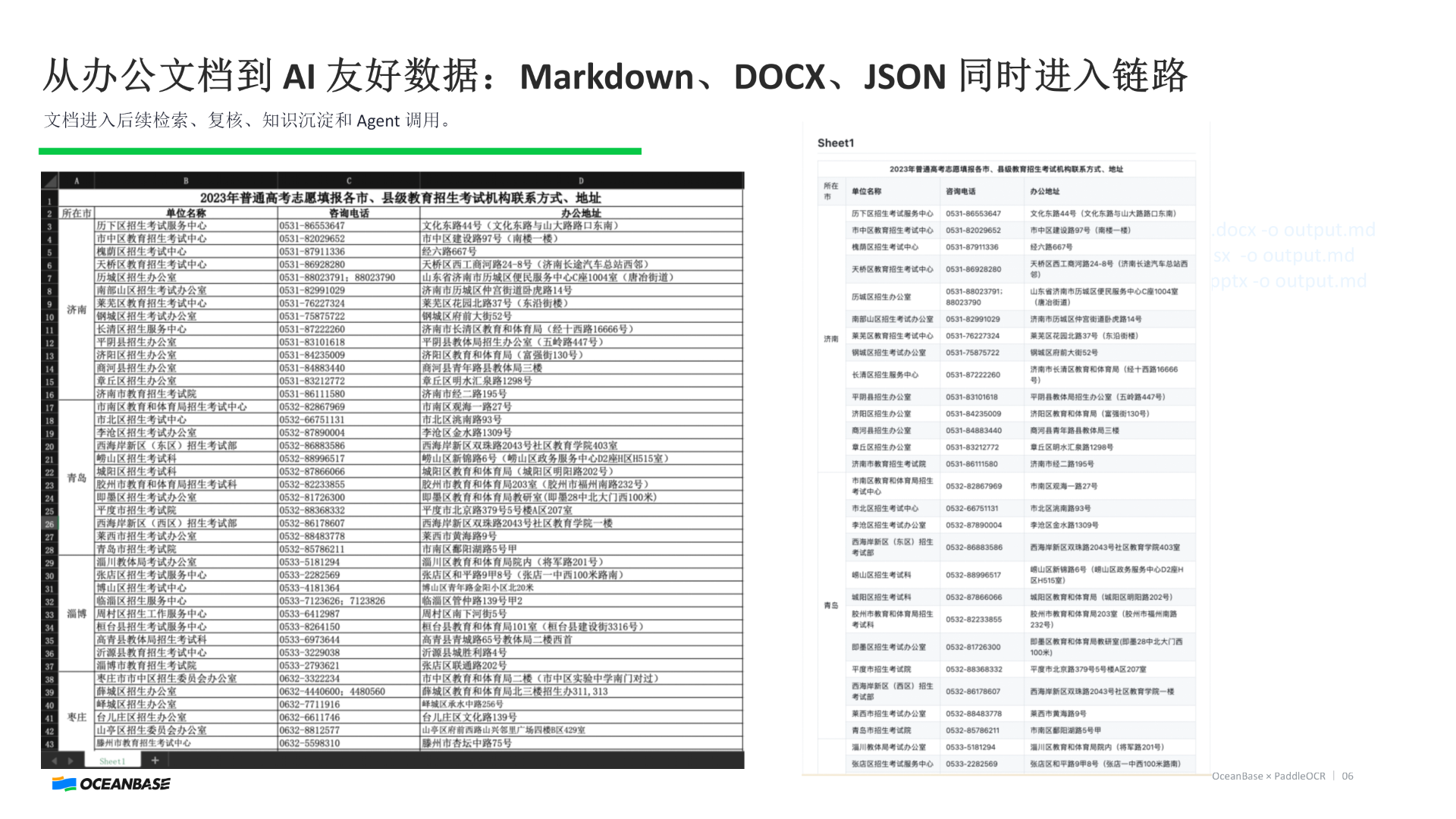
2️⃣ 文档流入口(doc2md / DOCX)
Word / Excel / PPT → Markdown
解析结果 → 还能导回 Word
👉 文档不再只是“看”,而是可以“流转 + 被 AI 消费”

3️⃣ AI 生态入口(Transformers)
统一推理引擎直接接入 Hugging Face 生态
👉 OCR 不再是孤岛,而是进入 Agent 体系
一个很重要但容易忽略的点
👉 不是识别出文字就够了不同数据形态,决定了不同能力:
- Markdown → 给 LLM 用
- DOCX → 给人用(复核 / 流转)
- JSON / 字段 → 给系统用(检索 / 权限 / 审计)
👉 如果只有文本,系统是“短期记忆”
👉 如果有结构化数据,系统才有“长期记忆”
真正的难点:复杂文档
现实里的文档,远比 Demo 复杂:表格公式、图表、印章、跨页结构、扫描件、手机拍照、倾斜 / 弯曲 / 光照问题...
👉 这些场景,传统 OCR 是不够的
PaddleOCR-VL-1.5 解决的是:不是“识别字”,而是理解文档结构、层级阅读顺序、跨页关系、精准提取各种真实复杂场景下的文档信息。
👉 这一步决定:知识是“碎片”,还是“系统可用”

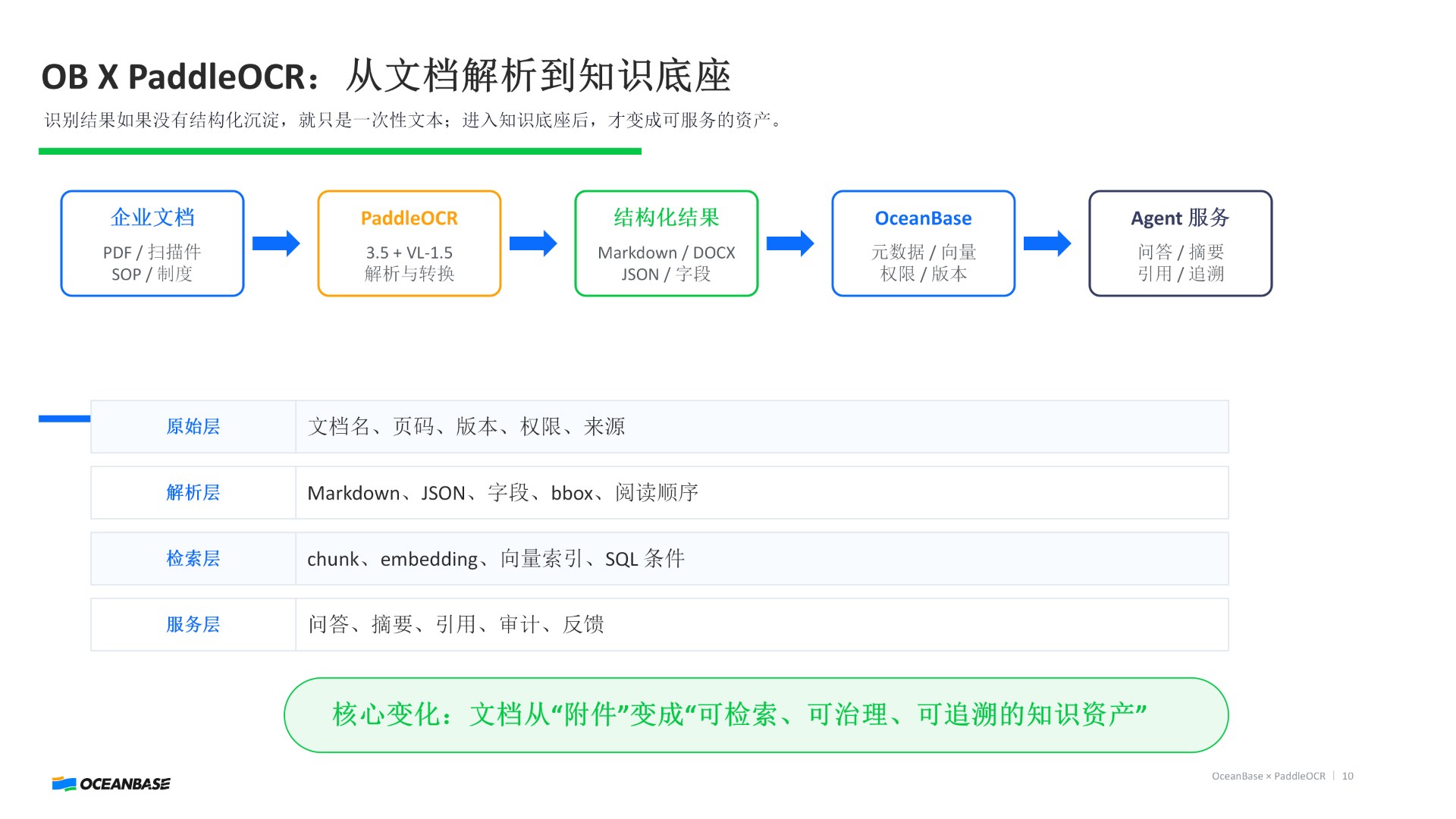
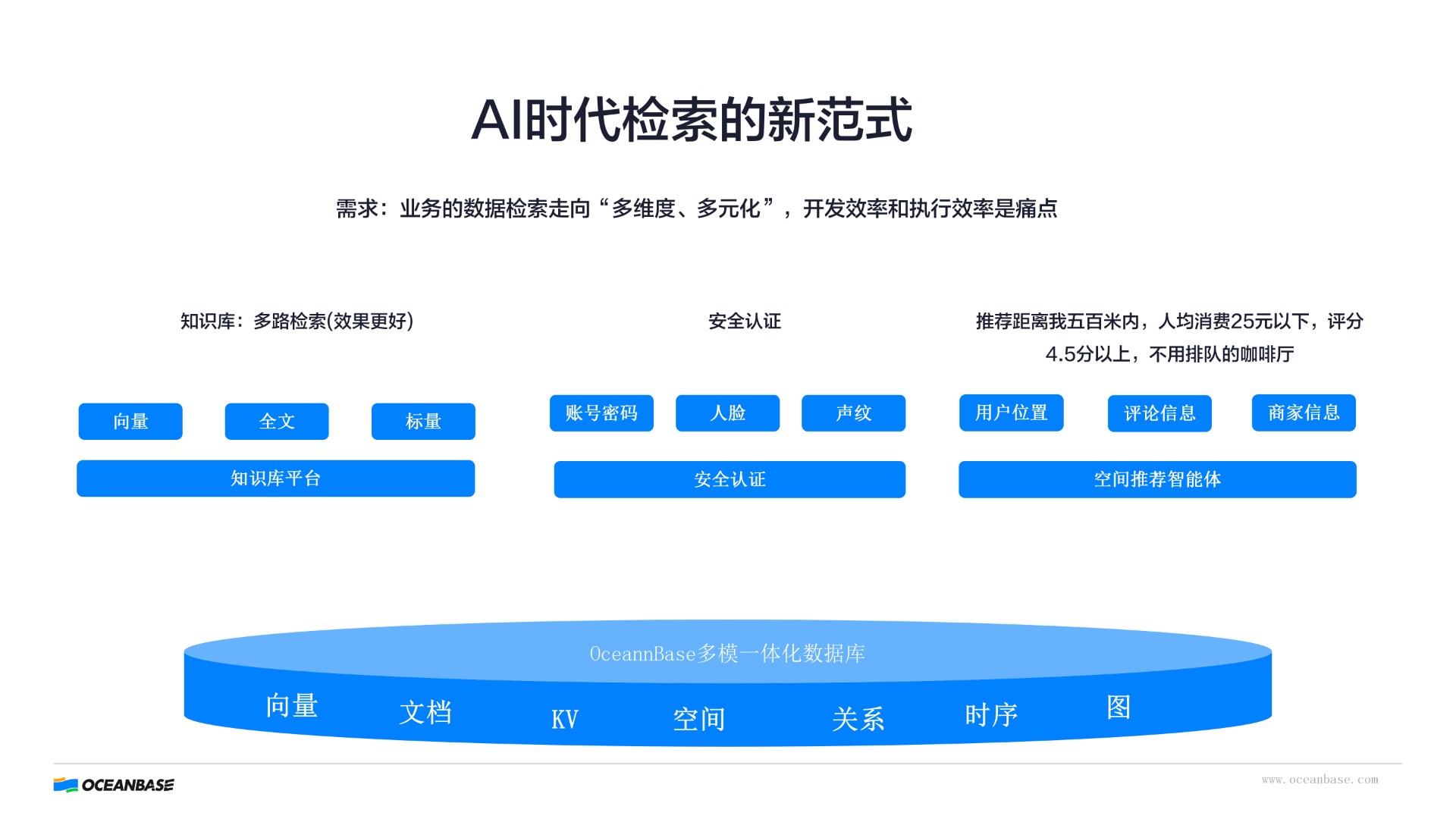
OceanBase:让知识真正“活下来”
很多系统做到 OCR 或 文档解析 就停了,但真正的关键在后面:
👉 知识如何长期存在?版本、权限、来源结构、索引反馈...
这些能力,本质是“数据库问题”。
OceanBase 的角色,是把这些数据变成:向量、文档、关系、图...
👉 支撑多维检索 + Agent 调用
把整条链路连起来
最终,你会得到这样一条路径:企业文档 → PaddleOCR(看懂)→ 结构化数据(整理)→ OceanBase(沉淀)→ Agent(使用)
👉 关键变化只有一句话:文档,从“附件”,变成“可服务的知识资产”。
不要一上来做 “大而全的 Agent”。
选一个场景,例如,客服知识Agent。
做成一件事:👉 把这一类文档,完整走通“资产化链路”
你会发现:Agent 的效果,是“自然长出来的”,不是“设计出来的”。
结语
很多人觉得,企业 Agent 的核心是模型。但真正的分水岭,其实在这里:
👉 谁能把文档变成知识资产?模型决定上限,数据决定下限。
所以:
企业 Agent 的第一公里,不是聊天框。
是文档资产化。
