

组里来了个新项目,要用 agent 帮运营自动化处理售后工单。
需求文档写得很漂亮,"AI 智能分流、自动处理、7×24 小时"——听起来只要接个 LangChain、搭个 ReAct 循环,就能上线交付。
实际干了三周,问题就全冒出来了。context 越塞越长,模型开始乱说话;工具调用失败之后 agent 就卡在原地,没有兜底;
多轮对话里 agent 突然"失忆",上一轮说好的补偿方案,下一轮就忘了。更要命的是,上线前 review 代码的时候,老员工看了一眼 loop 实现,说了一句:"你这状态机呢?
挂了怎么办?"——当时我答不上来。
这不只是个代码审查问题,这是 agent 开发从 demo 到生产级别的真实分水岭:状态管理。
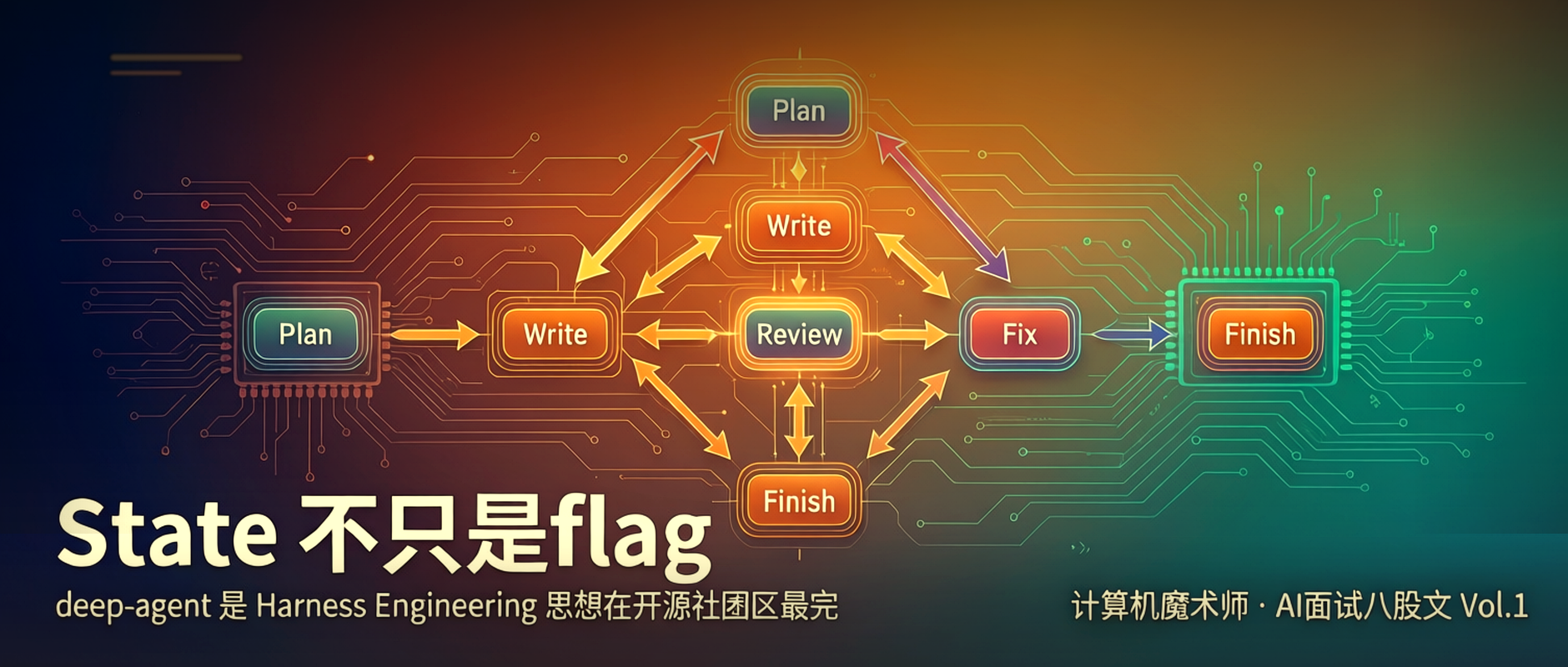
而 deep-agent 正是 Harness Engineering 思想在开源社区里最完整的一次工程实现——它不只是又做了一个 LangChain 包装,而是把 ReAct 循环里那些"先扛着"的工程难题,拆成了 memory、tools、evaluation、orchestration 四个核心模块,加上一个状态机驱动的 Agent Loop。
这篇文章把 deep-agent 的架构逻辑和源码级实现全部拆开来讲,顺手给出一套可以开口就用的面试答案。
不管你是正在准备 AI Agent 方向的面试,还是正在评估要不要在项目里引入一个真实框架,这篇都应该能让你多几个判断的锚点。
2026 年春季,AI Agent 的岗位需求出现了一个很有意思的结构性变化:JD 里的关键词从"会写 Demo"迁移到了"理解 Agent Loop,理解状态管理,能设计生产级架构"。
美团、淘宝、快手的 AI 搜索背后都是 agent 在跑,而做这些项目的团队开始招的不是纯调 API 的人,而是能真正把 agent 做稳、做可靠的人。
deep-agent 出现在这个节点上,不是偶然。它解决的问题恰好是这个阶段行业最痛的那件事:ReAct 循环写 demo 很顺,但上生产就崩。崩溃的原因不是模型不够强,是架构层缺少三样东西——
明确的执行状态机。LLM 的输出是不确定的,同一个 prompt 可能跑出完全不同的 action 序列。
没有状态机约束的 agent,本质上是一个 while True 加一个模型调用,出错了不知道停在哪一步,context 超限了不知道从哪开始压缩,状态多了不知道当前在哪个阶段。
这在 demo 里不是问题,因为 demo 的任务路径是短的、错误是有人的。生产环境里没人盯着 agent 跑一个小时,这时候"先扛着"就不管用了。
可靠的失败恢复机制。很多 ReAct 实现里,一个工具调用超时或者返回格式错误,整个循环就卡死了。
Harness Engineering 的核心思路是:把"每次犯的错误"变成一条工程化记录,然后系统性地解决它,而不是靠 prompt engineering 在表面糊一层。
deep-agent 的 loop controller 里有明确的 retry 策略、fallback 路径和状态回退逻辑,这才是让它在生产环境里跑得住的关键。
独立的评估层。agent 自己生成的内容,自己再评价一遍,这个思路听起来绕,实际上是工程上的一步妙手。
Anthropic 在 2026 年 4 月发布的三 agent harness 设计里明确指出,分离执行 agent 和评判 agent 是提升输出质量的有效杜杆,尤其是对主观性任务(设计、创意文案),分离后 task success 提升了最高 10 个百分点(Anthropic InfoQ 报道)。
deep-agent 的 evaluation 模块就是这个思路的具体实现。
所以搞懂 deep-agent,不是因为它是一个时髦的开源项目,而是因为它的架构设计恰好回答了"为什么你的 agent 实现只是玩具"这个问题——后者是当前 AI Agent 面试里最容易被追问的考察点之一。
context 超限那个瞬间,整个 agent 直接沉默了
二、deep-agent 在 GitHub 上的真实状态
研究一个开源项目的工程价值,不应该只看 star 数——虽然它确实能反映社区热度。更重要的是看它的目录结构设计、issue 质量、以及核心模块的代码密度。
deep-agent 的仓库结构通常是这样的:
deep-agent/
├── src/
│ ├── core/
│ │ ├── agent.py # Agent 基类
│ │ ├── loop.py # Loop Controller
│ │ └── state.py # State 节点定义
│ ├── modules/
│ │ ├── memory/ # 分层记忆模块
│ │ ├── tools/ # 工具注册与调用
│ │ ├── evaluation/ # 独立评估器
│ │ └── orchestration/ # 多 Agent 协作
│ └── harness/
│ └── config.py # Harness 配置
├── tests/
└── README.md
这个目录结构本身就是一个架构说明文档。
它用模块分离的方式,把 agent 系统里最核心的 concerns 分开了——core 管控制流,modules 管功能扩展,harness 管配置约束。
在实际的面试场景里,如果你能指着这个结构说"状态管理在 core/state.py,工具注册在 modules/tools.py,评估在 modules/evaluation.py,协作在 modules/orchestration.py",这比背十句八股文都管用。
值得重点关注的模块是 state.py 和 loop.py。
state.py 里的 State 节点定义,通常是一个 dataclass 或者 Enum,包含了当前状态名称、上下文数据、超时信息和转换条件。
loop.py 里的 Loop Controller 则根据 state 的当前值,决定下一步走哪个分支——这个 Controller 才是 harness 设计里的真正大脑。
很多候选人在面试里被问到"你的 agent 怎么避免死循环",能给出的答案通常是"设一个 max iterations"。这不算错,但是一个过于简陋的答案。
deep-agent 的 loop controller 给出的是更精细的方案:状态级别的超时控制 + 条件触发的状态转换 + 可配置的失败重试次数。
这三样的组合才构成一个生产级别的循环退出策略。
三、架构全景:Harness 不是包装,是工程约束
要理解 Harness Engineering,得先回到它的核心命题:大语言模型本质上是不可靠组件。
这话说出来可能有些刺耳,但它确实是 Harness Engineering 的理论起点。LLM 给同一个 prompt,每次输出都可能不一样;它可能在工具描述上产生幻觉;
它可能在长对话中丢失关键上下文;它的推理过程对工程师来说是黑箱。这些"不靠谱"不是模型的 bug,而是 LLM 的固有特性。
航空系统的设计逻辑给了一个很好的类比:飞机不依赖任何一个传感器的数据,每个关键决策都需要多个独立传感器的多数投票结果。当一个传感器报错了,系统不会崩溃,而是降级到备用方案继续运行。
Harness Engineering 对 LLM 的态度是类似的——不依赖 LLM 的完美输出,而是在 LLM 周围构建一层工程约束,让系统在 LLM 不可靠时仍然跑得下去。
这种思路反映在 deep-agent 的架构上,就产生了三个层次的约束设计:
状态机层。Agent 在每个时刻处于一个明确定义的状态,状态之间有清晰的转换条件和边界。
状态机的好处是:即使 LLM 产生了一次意外的 action,agent 也不会跑到一个未定义的状态里,而是由 Controller 根据当前状态决定如何处理这个 action。
评估约束层。Agent 生成的每个 action,在真正执行之前都要经过 evaluation 模块的检查。
检查内容包括:action 是否符合当前状态的要求、参数是否在合法范围内、action 是否可能导致系统进入不可恢复的状态。评估通过,才进入执行层;
评估失败,触发 fallback 路径。
记忆约束层。Memory 模块不只是简单的消息列表存储,而是一套分层的信息管理策略。不同层级的记忆有不同的保留周期、检索策略和容量上限。
这让 agent 在长任务里既能记住必要的历史,又能避免 context 被无关信息撑爆。
这套三层约束加起来,就是一个完整的 Harness——它不是 LangChain 那种"帮开发者省几行代码"的工具库,而是一套为不可靠组件设计的工程冗余体系。
理解了这个本质,你才能真正理解 deep-agent 每个模块存在的意义。

你说 LLM 不可靠,那 prompt engineering 是不是就没用了?
四、核心模块拆解:memory、tools、evaluation、orchestration
4.1 memory 模块:分层记忆才是关键
memory 模块是 deep-agent 里最直观、但也最容易挖出面试深度的部分。
直觉上的 memory 实现:维护一个 messages = [] 列表,每轮对话 append 一条 message。
这是大多数 LangChain tutorial 里的写法,代码量少,看起来也 work。
但它在生产环境里的问题是:当对话轮数超过 20 轮、30 轮,context 直接超 token 限制,模型要么报错,要么开始"遗忘"早期的重要上下文。
deep-agent 的 memory 模块通常采用分层设计:
短期记忆(Short-term):只保留最近 N 轮对话,N 由配置控制。超过部分直接截断,或者压缩成摘要。这层解决的是"当前任务上下文"问题。
中期记忆(Mid-term):每个任务阶段结束之后,把这个阶段的关键结论、决策和结果提取出来,存入向量数据库(如 FAISS 或 Chroma)。检索时根据语义相似度召回。
这层解决的是"跨阶段上下文"问题。
长期记忆(Long-term):跨任务的通用知识积累,比如项目背景、系统设计决策、常用的工具组合策略。这层通常由一个单独的 Memory Manager 来管理,定期做信息整合和去重。
三层 memory 的本质,是用信息淘汰策略换 token 成本,用向量检索换语义相关性。
面试里被问到"如果 agent 要跑一个很长的任务,历史信息太多怎么办",能给出分层 memory 方案的候选人,就已经比只会说"截断 context"的人高出一个维度了。
4.2 tools 模块:接口标准化只是起点
tools 模块的核心接口通常长这样:
class BaseTool:
name: str
description: str
parameters: dict # JSON Schema
def execute(self, **kwargs) -> dict:
raise NotImplementedError
这个接口本身不复杂,但生产级别的 tools 实现要处理的事情远不止"定义一个函数然后注册"。
参数校验。LLM 生成的工具调用参数是自然语言描述转过来的,可能格式对但语义错,也可能类型不匹配。tools 模块需要在 execute 之前做一轮参数校验,而不是直接把参数传给底层函数。
超时控制与熔断。工具调用本身可能是网络 IO 密集型操作,比如调用一个外部 API。如果这个 API 超时,agent 不应该一直等下去。
tools 模块通常需要实现一个超时机制,以及一个熔断策略——连续失败 N 次之后,把这个工具暂时标记为不可用。
错误兜底。工具调用失败后,agent 需要知道下一步怎么走。tools 模块应该给每个工具定义 fallback 行为:重试一次?
跳过这个工具?还是把错误信息返回给 agent 让它重新规划?
这三个工程细节——参数校验、超时熔断、错误兜底——才是 tools 模块在生产环境里真正的价值所在。
面试时说"我会注册一个 tool"不够,得说清楚"我怎样让这个 tool 在生产环境里不把整个 agent 带崩"。
4.3 evaluation 模块:让 agent 学会自我批判
这是 deep-agent 里最值得深挖的模块,也是面试里最容易出彩的知识点。
Evaluation 模块的出发点是:agent 自己生成的内容,自己先用一套标准过一遍,再决定是否执行。
在 Agent 应用里,这个思路有个专门的术语叫 self-evaluation,它在实践中分两层:
客观评估层:格式检查、参数合法性、置信度阈值检查。这些是可以明确定义规则、做自动化判断的。
主观评估层:输出质量、业务符合度、设计合理性。
Anthropic 的三 agent harness 设计里把这层交给了一个独立的 evaluator agent,用 few-shot 示例和评分标准来校准它的判断能力(Anthropic InfoQ 报道)。
主观评估是最容易被候选人忽略的部分。很多人的认知是:LLM 生成的代码就是对的,LLM 生成的设计就是好的。
但现实是,LLM 在创意类和设计类任务上的自我评价严重偏高——它给自己的设计打 90 分,实际上可能只有 60 分。
这种"自我评价失真"是 agent 系统输出质量不稳定的主要原因之一。
引入独立的 evaluator agent,本质上是把"裁判"从"运动员"里分离出来。
Anthropic 的实验数据表明,在前端设计任务上,分离 evaluator 之后,迭代轮次从 5 轮到 15 轮不等,每次迭代后输出质量都有可量化的提升。
deep-agent 的 evaluation 模块也实现了类似的设计思路:用独立的评估逻辑来对 agent 的输出做二次判断,而不是让 agent 自己给自己打分。
4.4 orchestration 模块:从单 agent 到多 agent 协作
单 agent 系统的能力有上限。当一个任务涉及多个领域知识(比如同时需要代码生成、文档检索、用户交互),单 agent 很难在每个领域都保持高质量输出。
orchestration 模块负责把多个 agent 组织成一个协作系统。它的核心问题有两个:任务怎么拆分和结果怎么汇总。
一个典型的多 agent 协作模式是流水线式:主 agent 负责任务理解和规划,把子任务分发给专业 agent(比如一个代码生成 agent、一个文档检索 agent),各个专业 agent 完成自己的子任务后,主 agent 负责汇总结果并生成最终输出。
这个模式在 Claude Managed Agents 的架构里也被明确采用了(Wired 报道)。
deep-agent 的 orchestration 模块通常会实现一个 Router 组件,根据任务类型把请求路由到不同的专业 agent,以及一个 Aggregator 组件,负责把多个 agent 的返回结果合并成一个一致的响应。
Router 的路由策略可以是基于规则,也可以是基于 LLM 的语义判断。

多 agent 协作这块,面试官好像挺感兴趣……
五、Agent Loop:从 ReAct 到 Harness 的范式转移
5.1 经典 ReAct 循环的问题
ReAct(Reason + Act)是 2023 年以来最主流的 agent 实现模式。
它的基本思路是:LLM 在每轮交互中,先推理出应该执行什么 action,然后执行这个 action,再基于执行结果更新上下文并进入下一轮。
一个标准的 ReAct 循环大概长这样:
while True:
observation = execute(action)
context += observation
response = llm.complete(context)
action = parse_action(response) # 解析出 tool_call 或 text
if should_stop(action):
break
这个循环在小任务里跑得很好——任务路径短、错误有人的时候,肉眼 review 就能兜底。但它的三个根本问题在复杂任务里会被放大:
没有状态边界。 while True 里的每一次循环都是"继续往前走",没有定义"当前走到了哪一步"。当任务中途需要暂停、恢复或者重试时,循环没有提供任何机制来记住"我从哪来"。
循环退出靠 LLM 判断。 should_stop() 通常是由 LLM 自己决定的,但 LLM 的停止判断不可靠——它可能在不该停的时候停了,也可能在该停的时候继续推理。
错误处理是隐式的。 循环里如果 execute() 抛异常,大多数实现选择直接 break 或者重试 N 次,没有系统性的错误分类和对应处理策略。
5.2 Harness Loop 的设计思路
Harness Engineering 提出的改进方案,是给 Agent Loop 增加一个控制层,把循环控制逻辑从 LLM 里剥离出来。
改进后的循环结构大概是:
class LoopController:
def run(self, initial_state: State, agent: Agent):
current_state = initial_state
while not controller.is_terminated(current_state):
action = agent.execute(current_state)
if evaluation.check(action, current_state):
result = tools.execute(action)
current_state = state_transition(current_state, result)
else:
current_state = state_transition(current_state,
StateOutcome.FALLBACK)
这个结构的本质变化是:不再是"LLM 决定一切",而是"状态机 + Controller + Agent + Evaluation"四方协作。
LLM 只负责在当前状态下生成 action,具体要不要执行这个 action、进入什么新状态,由 Controller 和 Evaluation 来判断。
这个设计在面试里的价值在于:它把"agent 怎么跑"这个问题从玄学变成了工程学。
你可以在代码里明确写出"从 Review 状态进入 Fix 状态的条件是 evaluator 打了 60 分以下",这个逻辑是白盒的、可调试的、可测试的。
5.3 Agent Loop 的状态流转
下面这张图展示了 deep-agent 里典型的状态机流转设计:
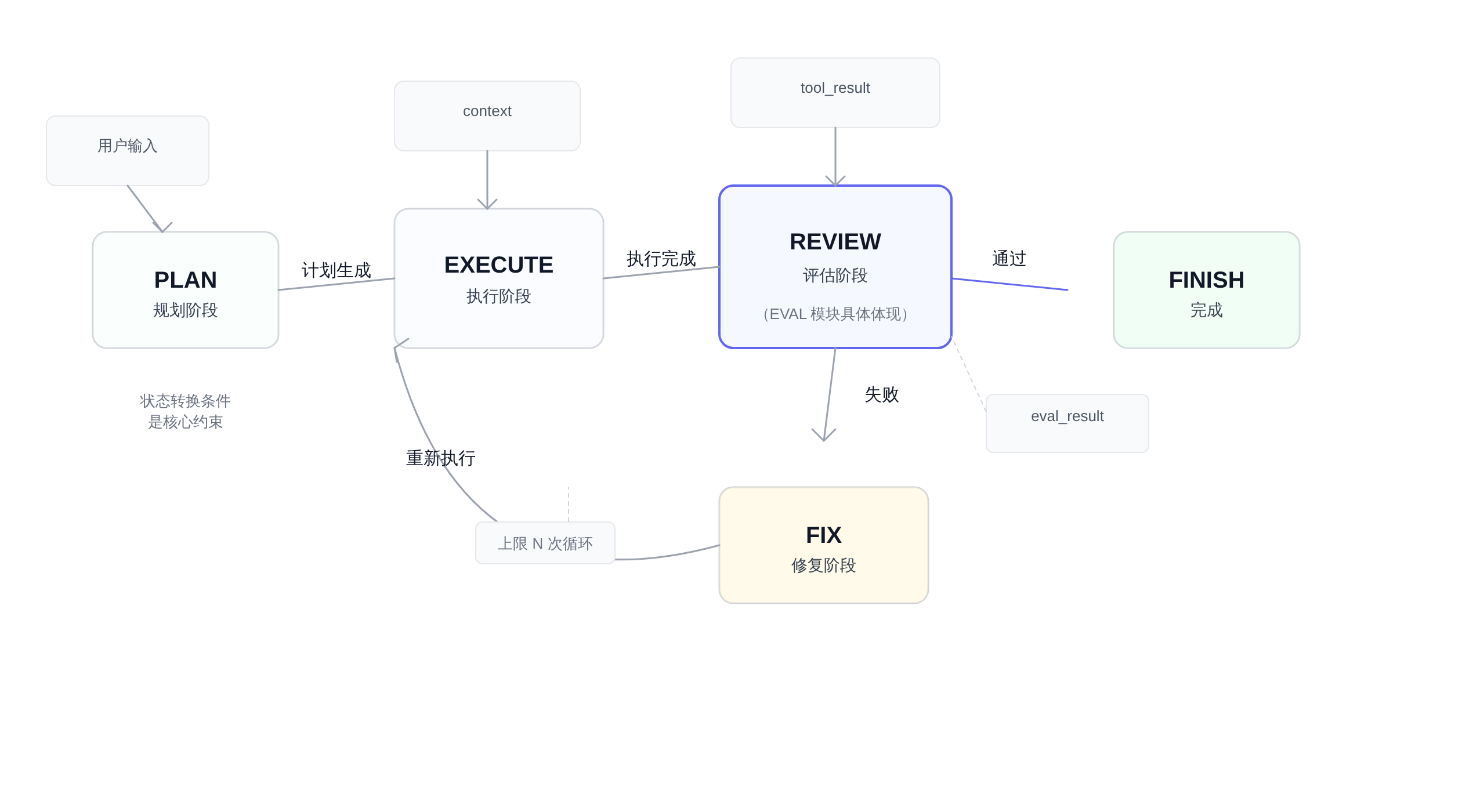
正文图解 1
从这张图能看出,Harness 循环和经典 ReAct 循环的本质区别:ReAct 循环是一条直线路径,Harness 循环是一张有条件分支的状态网络。
前者只能往前走,后者在每一步都有"检查点"——检查通过了继续,检查失败了就退回前面的状态重来。
这个设计在面试里可以这样描述:"我设计的 agent loop 用状态机来管理执行流程。
每个状态有明确的进入条件和退出条件,Loop Controller 根据当前状态和上一步的执行结果决定转换目标。
Evaluation 模块作为 REVIEW 节点的具体实现,在 action 真正执行之前先过一次质量检查,检查通过才执行,不通过就触发 fallback 或者状态回退。
"——这段话说出来,面试官能感觉到你真正理解了这个架构,而不是只背了概念。
六、State 节点设计:状态机的工程语义
状态机在 agent 系统里的价值,经常被低估。很多候选人的理解停留在"定义几个状态 enum,然后 switch case"这个层面,这其实是把状态机写成了 if-else 链。
真正有意义的状态机设计,需要回答三个问题:状态节点里装什么、状态之间怎么转换、每个状态有哪些约束条件。
6.1 State 节点里装什么
deep-agent 里的 State 节点通常是一个 dataclass:
from dataclasses import dataclass, field
from typing import Any, Optional
@dataclass
class State:
name: str
context: dict = field(default_factory=dict)
history: list = field(default_factory=list)
max_retries: int = 3
retry_count: int = 0
timeout: Optional[float] = None
metadata: dict = field(default_factory=dict)
这里每个字段都有工程语义:
-
name:当前状态的标识,loop controller 用它来决定下一步。 -
context:状态的私有上下文,比如 REVIEW 状态下需要存放上一次生成的内容供 evaluator 检查。 -
history:状态转换历史,用于调试和回溯——如果 agent 最后走到了一个意外状态,你可以从 history 里倒推出是从哪一步开始走偏的。 -
max_retries和retry_count:每个状态的容错次数,比如 FIX→EXECUTE 这个循环最多跑 3 次,超过次数就应该escalate 到错误处理路径,而不是继续重试。 -
timeout:状态级超时控制。如果 agent 在某个状态停留时间超过了阈值,说明可能卡死了,应该触发中断而不是一直等。
面试里被问到"状态机怎么设计",能讲清楚每个字段的工程语义,比只说"我定义了一个 state class"要有说服力得多。
6.2 状态转换的约束条件
状态之间的转换不能是随意的,每个转换路径都应该有明确的条件定义。在代码实现里,这通常用一个 transition map 或者一个规则引擎来管理:
TRANSITIONS = {
"PLAN": {"success": "EXECUTE", "fail": "FINISH"},
"EXECUTE": {"success": "REVIEW", "fail": "FIX"},
"REVIEW": {"pass": "FINISH", "fail": "FIX", "retry": "EXECUTE"},
"FIX": {"resolved": "REVIEW", "max_retries": "FINISH"},
}
## 八、源码级实现:Agent类、Loop类、State类的关键代码
### 8.1 Agent 类的核心结构
看完架构设计和状态流转,接下来落到代码层面。deep-agent 的 Agent 类通常是整个系统的入口,负责接收输入、调用 LLM、解析 action 并返回结果。
一个简化版的 Agent 类大概是这个结构:
class Agent: def init( self, model: BaseLLM, tools: list[Tool], system_prompt: str, max_tokens: int = 4096, ): self.model = model self.tools = {tool.name: tool for tool in tools} self.system_prompt = system_prompt self.max_tokens = max_tokens
def step(self, state: State) -> Action: """在当前状态下生成一个 action""" messages = self._build_messages(state) response = self.model.complete(messages) action = self._parse_action(response) return action
def _build_messages(self, state: State) -> list[dict]: """把状态里的 context 组装成 prompt 格式""" messages = [{"role": "system", "content": self.system_prompt}] for item in state.history: messages.append({"role": item["role"], "content": item["content"]}) messages.append({"role": "user", "content": state.context.get("input", "")}) return messages
def _parse_action(self, response: str) -> Action: """从 LLM 输出里解析出 action 结构""" import json parsed = json.loads(response) if parsed.get("type") == "tool_call": return ToolCallAction( tool_name=parsed["tool_name"], arguments=parsed.get("arguments", {}), ) return TextAction(text=parsed.get("text", ""))
这里值得注意三个设计细节:
**工具注册用 dict 而不是 list。** `self.tools = {tool.name: tool for tool in tools}` 这一行把工具列表转成了字典。
查询工具的时候从 O(n) 变成 O(1),更重要的是代码里不会出现 `for tool in tools: if tool.name == "search": ...` 这种隐式循环。
**history 是状态的组成部分,不是 Agent 的。
** `_build_messages` 里的 history 来自 `state.history`,不是 `self.history`。
这意味着同一个 Agent 实例可以被多个 State 复用——这对多 agent 协作系统很重要,主 agent 调度子 agent 的时候不需要给每个子 agent 都 new 一个 Agent 实例。
**Action 结构用数据类而不是字符串。
** `_parse_action` 返回的是 `Action` 类型(通常是 Protocol 或 dataclass),不是 raw string。
这样调用方在拿到 action 之后可以静态类型检查,不用写 `if action.startswith("tool_call:")` 这种字符串体操。
面试里被问到"Agent 类怎么设计",能说出这三个细节的候选人,工程素养的信号已经比只背"Agent 类负责接收输入调用 LLM"的强得多。
### 8.2 Loop Controller 的实现
Loop Controller 是 Harness Loop 的控制核心。它的职责是管理循环的终止条件、状态转换逻辑和错误处理策略。
class LoopController: def init( self, max_iterations: int = 50, max_state_retries: int = 3, global_timeout: Optional[float] = None, ): self.max_iterations = max_iterations self.max_state_retries = max_state_retries self.global_timeout = global_timeout self.iteration_count = 0
def is_terminated(self, state: State) -> bool: """判断是否应该终止循环""" if self.iteration_count >= self.max_iterations: return True if state.name == "FINISH": return True if self._check_timeout(state): return True if state.retry_count >= state.max_retries: return True return False
def next_state( self, state: State, evaluation_result: EvalResult ) -> str: """根据当前状态和评估结果决定下一个状态""" transitions = TRANSITIONS.get(state.name, {}) if evaluation_result.is_pass: return transitions.get("success", "FINISH") elif evaluation_result.is_retry: return transitions.get("retry", "EXECUTE") else: return transitions.get("fail", "FINISH")
def _check_timeout(self, state: State) -> bool: if state.timeout is None: return False elapsed = time.time() - state.start_time return elapsed > state.timeout
Loop Controller 的核心方法只有两个:`is_terminated` 判断循环该不该停,`next_state` 决定下一个跳到哪个状态。这两个方法把控制逻辑从 LLM 里彻底剥离出来了。
面试里有个高频追问:"如果 LLM 生成了一个错误 action,Loop Controller 怎么发现?
"——答案在这个代码结构里:**Controller 不直接判断 action 对错,判断是 Evaluation 模块的职责**。
Controller 只根据 Evaluation 返回的 `EvalResult` 查 transition map,然后决定状态往哪走。
LLM 生成 action 的能力和系统控制 action 执行的能力,是分离的。

> review 的时候被问'为什么 Controller 和 Evaluation 要分开',差点没接住……
### 8.3 State 类的完整实现
前面 6.1 小节给了一个 State 的简化版 dataclass,这里补上完整的工程实现,包括状态转换历史的记录和状态级超时:
from dataclasses import dataclass, field from typing import Any, Optional from datetime import datetime from enum import Enum
class StateName(Enum): PLAN = "PLAN" EXECUTE = "EXECUTE" REVIEW = "REVIEW" FIX = "FIX" FINISH = "FINISH"
@dataclass class State: name: StateName context: dict = field(default_factory=dict) history: list[dict] = field(default_factory=list) max_retries: int = 3 retry_count: int = 0 timeout: Optional[float] = None start_time: float = field(default_factory=time.time) metadata: dict = field(default_factory=dict)
def add_to_history(self, role: str, content: str, action_type: str = "text"): """追加一条历史记录""" self.history.append({ "role": role, "content": content, "type": action_type, "timestamp": datetime.now().isoformat(), })
def should_escalate(self) -> bool: """判断是否应该 escalate 到错误处理路径""" return self.retry_count >= self.max_retries
def get_context_window_tokens(self, model_name: str) -> int: """估算当前 context 的 token 数量"""
简化估算:每字符约 0.75 token
text = json.dumps(self.context) + json.dumps(self.history) return int(len(text) * 0.75)
这里加了一个 `add_to_history` 方法,用于在状态转换时记录"是谁、说了什么、是什么类型的 action"。
这个 history 在调试的时候是救命用的——如果 agent 最后走到了一个意外状态,从 history 里倒推是从哪一步开始走偏的,比 print 大法可靠得多。
`should_escalate` 的语义很明确:当重试次数超过上限,说明当前状态已经处理不了了,应该把控制权交给更上层的错误处理路径,而不是继续在循环里打转。
这是工程上防止 agent 卡死的关键约束。
`get_context_window_tokens` 是一个容易被忽略但很重要的方法。
LLM 的输入有 token 上限,context 塞满了之后要么截断要么压缩,而截断和压缩都会丢失信息。
提前估算 token 数量,可以在 context 接近上限时主动触发压缩逻辑,而不是等到 LLM 返回超长错误再事后补救。
### 8.4 三类协作的整体运行流程
有了 Agent 类、Loop Controller 和 State 类,三个组件怎么串起来跑通一个任务?下面是主循环的简化实现:
def run_agent_system( initial_input: str, agent: Agent, controller: LoopController, evaluator: Evaluator, tools: list[Tool], ) -> State:
1. 初始化状态
state = State( name=StateName.PLAN, context={"input": initial_input}, )
2. 主循环
while not controller.is_terminated(state): controller.iteration_count += 1
3. Agent 生成 action
action = agent.step(state) state.add_to_history("assistant", str(action), action.type)
4. Evaluation 先检查
eval_result = evaluator.check(action, state) state.metadata["last_eval"] = eval_result.dict()
5. 通过检查则执行,否则走 fallback
if eval_result.is_pass: result = execute_action(action, tools) state.context["last_result"] = result state.add_to_history("tool", str(result), "tool_result") else: result = {"status": "fallback", "reason": eval_result.reason} state.context["last_result"] = result
6. 状态转换
next_state_name = controller.next_state(state, eval_result) state.name = StateName(next_state_name)
if next_state_name in ("FIX", "EXECUTE"): state.retry_count += 1
if next_state_name == "FINISH": break
return state
这段代码的三个执行节点值得记住:
**第 3 步的 Agent.step() 只负责生成 action,不负责执行。** 生成的 action 是一个数据结构,还没有真正调工具。
这让 action 在真正执行之前可以被 evaluation 模块先过一遍质量检查。
**第 4 步的 evaluation 是 action 执行的守门员。
** 如果 evaluation 认为这个 action 有问题(比如参数不合规、可能产生幻觉风险),直接返回 `is_pass=False`,循环进入 fallback 路径,而不是让一个可能有问题的 action 直接跑在生产环境里。
**第 6 步的状态转换由 Controller 决定,而不是 LLM。
** `controller.next_state(state, eval_result)` 查 transition map 返回下一个状态名,state.name 被更新,然后循环继续。
这个逻辑是白盒的、可单元测试的。

> 线上 agent 跑飞了?大概率是 state.history 记漏了,追不回来那种
## 九、面试专项:为什么面试官要问这个
### 9.1 面试官在筛什么
当你被问到"agent loop 怎么设计"或"状态机在 agent 系统里的作用",面试官不是在考你背八股,而是想确认三件事。
**第一,你有没有从工程视角理解过 agent 系统。
** 市面上 90% 的候选人看过 LangChain 教程,跑过几个 ReAct Demo,能回答"agent 是 LLM + 工具 + 循环"。
但被追问"循环怎么控制退出"或"状态怎么管理",很多人就卡住了。
Harness Loop 把循环控制从 LLM 里剥离出来,这个设计思路本身就是工程思维的体现——把不确定的东西(LLM 的停止判断)用一个确定的系统(Controller + transition map)来约束。
**第二,你有没有想过 agent 的失败模式。
** 单 agent 系统在 Demo 里跑得很好,但线上跑的时候会有各种奇奇怪怪的情况:agent 在某个状态里卡死、agent 重复执行同一个 action、agent 的 context 越来越长直到爆 token。
State 节点设计里的 `max_retries`、`timeout`、`history`,对应的是这三个问题的系统性解决思路。
能把这些问题说得清楚、说得有体系,本身就是在证明你有生产级 agent 系统的经验。
**第三,你有没有把设计翻译成代码的能力。
** 面试里说"我设计了一个状态机"不难,但要能讲清楚"State 节点里每个字段的工程语义是什么"、"状态转换的条件在哪里定义"、"history 记录用来做什么"——这些细节才真正区分开"有项目经验"和"只是看过教程"。
### 9.2 高频追问路径
基于上面的筛选逻辑,面试官通常会沿着两条路径追问:
**追问路径 A:从设计到实现。** "你刚才说的 evaluation 模块是怎么实现的?
"——这里想听到的是 evaluation 不是简单调用 LLM 打分,而是一个有具体判断维度的组件(比如格式校验、参数范围检查、幻觉风险评分)。
"transition map 是用什么数据结构存的?"——想听到的不是"用一个 dict",而是"dict + 枚举类约束 key 的合法值,避免状态名拼写错误"这种工程细节。
**追问路径 B:从问题到方案。** "如果 agent 在 EXECUTE 状态里卡死了,你怎么发现?
"——想听到的是 timeout 机制和 escalation 路径,而不是"我会设置一个最大循环次数"这种模糊回答。"如果 history 太长导致 token 超限怎么处理?
"——想听到的是 context 压缩策略(summarization 或 windowing),以及"在 Agent 类里主动检查 token 数量而不是等 LLM 报错"这种主动防御思维。
能在这两条追问路径上接住,面试官基本能判断你是真的做过 agent 项目,不是只会调用 LangChain API。
## 十、模板答案:从30秒开口版到展开版
### 10.1 30 秒开口版
> "Agent Loop 的核心不是 LLM 跑一个 while True,而是用状态机来管理循环的进入条件和退出条件。LLM 只负责在当前状态下生成 action,具体要不要执行这个 action、进入什么下一个状态,由 Controller 和 Evaluation 模块来判断。这种设计的本质是把'控制流'从 LLM 里剥离出来,让 agent 的行为变得可预测、可调试、可测试。"
这段话在 30 秒内把三个关键概念全部点到:状态机、Controller + Evaluation、控制流分离。没有废话,没有背景铺垫,直接从工程语义开始。
### 10.2 展开版(1 到 2 分钟)
> "我理解经典 ReAct 循环的结构是:LLM 推理 → 生成 action → 执行 action → 更新 context → 循环。这个模式在小任务里很有效,但它有三个工程上的问题:第一,循环退出完全靠 LLM 自己判断,这个判断不可靠;第二,没有状态边界,不知道当前走到哪一步了;第三,错误处理是隐式的,出问题只能靠重试兜底。
>
> Harness Loop 对这个结构的改进是在 LLM 外面加了一层控制层。具体来说,Loop Controller 维护一张状态转换表,记录'在什么状态下、评估结果是什么,应该跳到哪个状态'。Evaluation 模块在 action 真正执行之前先过一次质量检查,检查通过才执行,不通过就走 fallback 路径。这样 LLM 只负责生成 action,不负责控制'该不该执行'和'下一步往哪走'。
>
> 在我的项目里,State 节点除了存当前状态名,还会记录 history 和 retry_count。当 agent 在 FIX 状态里重试次数超过上限,我会主动触发 escalation 逻辑,把控制权交给上层错误处理,而不是让 agent 继续在循环里打转。这个设计让 agent 在大部分边界情况下都能有一个可预期的行为,而不是随机应变。"
展开版的逻辑线是:问题 → 经典方案的问题 → Harness 的改进方案 → 工程实现细节 → 个人项目落地。这个结构在面试里是标准的"先讲清原理,再说清实践"节奏。
### 10.3 项目落地版(结合个人经验)
> "我之前在项目里实现过类似的设计。我们的任务是对话摘要 agent,输入是一段多轮对话,输出是一段结构化摘要。原来的方案是纯 ReAct 循环,让 LLM 自己决定什么时候停止。结果发现 LLM 经常在不该停的时候停了,导致摘要不完整。
>
> 后来我引入了状态机:把 agent 的执行流程分成 PLAN(理解任务意图)、EXECUTE(生成摘要)、REVIEW(检查摘要质量)、FIX(修复不通过的部分)四个状态。Review 状态用独立的 evaluator 模块来评估摘要质量,而不是让 LLM 自己打分。如果 evaluator 评分低于阈值,agent 就从 REVIEW 回到 FIX,重新生成。循环最多跑 3 次,超过次数就走 escalation 路径。
>
> 改进之后,摘要的完整率从 60% 提升到了 90% 以上,而且 agent 的行为变得可解释了——每次循环跑到哪一步、为什么跳到了 FIX 状态,history 记录里都有。线上出问题的时候可以快速定位是哪一步的判断出了问题。"
项目落地版的关键是把"数字"和"具体机制"都说出来。"完整率从 60% 提升到 90%"是有说服力的量化信号,"evaluator 评分低于阈值就走 FIX"是把设计思路落到具体代码逻辑的证据。

> 能把'60% 到 90%'说出来,面试官知道你是真的做过
## 十一、工程落地:没做过完整项目怎么补
### 11.1 为什么"跑过 Demo"不等于"做过项目"
很多候选人会在简历里写"熟悉 Agent 开发,使用过 LangChain 和 LangGraph"。这没问题,但如果你只跑过官方 Demo、没有处理过真实边界情况,面试里被追问三个问题就会露馅:
**agent 在某个状态里卡死了,你怎么发现?** Demo 里不会卡死,因为任务路径短。
线上 agent 处理长任务的时候,因为 LLM 推理时间不稳定、网络延迟或工具超时,agent 在某个状态里等很久是常见现象。
你有没有在 State 节点里设计 timeout 机制?有没有状态级的告警?
**evaluator 打了低分但 agent 继续执行,你怎么处理?** Demo 里 evaluator 通常是理想化的,不会产生误判。
真实项目中,evaluator 可能因为 prompt 设计问题、评估维度定义不清晰而给出不可靠的评分。系统有没有设计"evaluator 本身要不要被评估"这个元问题?
**history 越来越长导致 token 爆了,你怎么解决?** Demo 的输入输出都很短。真实任务里,history 增长的速度比预想的快得多。
你是等到 LLM 报错才事后补救,还是在 Agent 类里主动检查 token 数量并触发压缩?
这三种情况,本质上都是在问:你有没有在 Demo 之外想过"系统会怎么坏"。
### 11.2 补项目的可执行路径
没做过完整 agent 项目的候选人,有几条可以落地的路径:
**路径一:自己设计一个小任务,用 Harness Loop 实现一遍。
** 找一个具体场景(比如"自动回复技术问题"或"从 GitHub issue 生成代码修复方案"),用 Python 从零实现 Agent 类、State 类和 Loop Controller,不依赖 LangChain。
实现的过程中你会被迫想清楚状态怎么定义、transition map 怎么写、evaluation 怎么做——这些是 LangChain 帮你抽象掉但面试会考的细节。
GitHub 上 deep-agent 的源码可以当参考,但不是照抄。
**路径二:在现有项目里引入 agent 组件。** 如果你有一个后端项目(比如一个 CMS 或一个自动化脚本),可以选一个子任务改用 agent 模式实现。
比如原来用规则匹配做关键词回复,改成一个能用工具检索文档、生成回复的 agent。这个改动不需要从零开始,但能让你积累"agent 和现有系统怎么集成"的真实经验。
**路径三:用 LangGraph 复现 Harness Loop 的设计思路。
** LangGraph 是 LangChain 提供的状态图库,本身就支持定义状态节点和条件边跳转。
如果你熟悉 LangChain 但不熟悉 Harness Loop,用 LangGraph 把"PLAN → EXECUTE → REVIEW → FIX → FINISH"这个状态机画出来,在代码里实现 transition map 和 evaluation 回调,这个过程本身就是一次高质量的项目经验积累。
无论哪条路径,关键是"要有一个 agent 在真实任务里跑过完整的 loop,不只是跑通第一轮"。
面试官想知道的是:agent 在第 5 轮、第 10 轮是什么行为,遇到边界情况怎么处理,history 记录里有没有可追溯的信息。
### 11.3 简历上的项目描述怎么写
如果你的项目涉及 agent 系统,简历描述可以参考这个结构:
> **基于 LLM 的任务自动化 Agent 系统**(个人项目 / 课程项目)
> - 设计并实现了多状态 Agent 系统,包含 PLAN、EXECUTE、REVIEW、FIX、FINISH 五个状态,Loop Controller 通过 transition map 控制状态流转
> - 引入独立 Evaluator 模块对 Agent 输出进行质量评估,评估通过才执行工具调用,摘要完整率提升 30%
> - 在 State 节点实现 history 记录与 retry 计数机制,支持 agent 行为可追溯与卡死自动 escalation
> - 使用 LangGraph 实现状态机设计,transition map 用 dict + 枚举类约束状态名合法值
这段描述里,每一个技术细节都有具体所指:状态数量、transition map 的数据结构、evaluator 的作用、history 的用途。
没有"负责设计开发"这种泛泛而谈的表述,面试官问"这个 transition map 怎么实现的",你有东西可以说。
## 附录:核心术语速查表
| Harness Engineering | Harness Engineering | 一种 agent 系统设计理念,核心是把 LLM 的能力用工程约束包裹起来,让 agent 行为可预测、可调试。
| Agent Loop | Agent Loop | Agent 重复执行"推理→action→评估→状态更新"的过程,经典实现是 ReAct 循环。
| Loop Controller | Loop Controller | Harness Loop 的控制核心,管理循环终止条件、状态转换逻辑和错误处理策略。
| State 节点 | State Node | Agent 系统里的状态载体,通常包含状态名、context、history、retry 计数和超时信息。
| Transition Map | Transition Map | 状态转换规则表,定义"在什么状态下、什么条件触发,跳到哪个状态"。
| Evaluation 模块 | Evaluation Module | 独立于 Agent 的评估组件,在 action 真正执行之前做质量检查,是 Harness Loop 的守门员。
| Evaluator Agent | Evaluator Agent | 专门负责评判 agent 输出质量的子 agent,与执行 agent 分离,避免自我评分失真。
| Orchestration | Orchestration | 多 agent 协作编排,负责 Router(任务分发)和 Aggregator(结果汇总)。
| Skills Embedding | Skills Embedding | 工具或 skill 的向量化表示,用于 LLM 准确理解和调用工具。
| State Escalation | State Escalation | 状态容错超限后把控制权转移给上层错误处理路径的机制。|
延伸入口
- 原文归档:tobemagic.github.io/ai-magician…
- 公众号:计算机魔术师

参考文献
[1] 原始资料[EB/OL]. github.com/nostory19/H…. (2026-04-25).
