

导读:用自研评测框架,对 OpenClaw Agent 进行全方位评测。54 个测试任务、5 个核心维度、15 个细粒度指标,最终得分 3.47/5(C 级)。本文公开全部评测数据、测试用例和评分标准,帮你建立系统的 Agent 评测方法论。
 编辑
编辑

 编辑
编辑
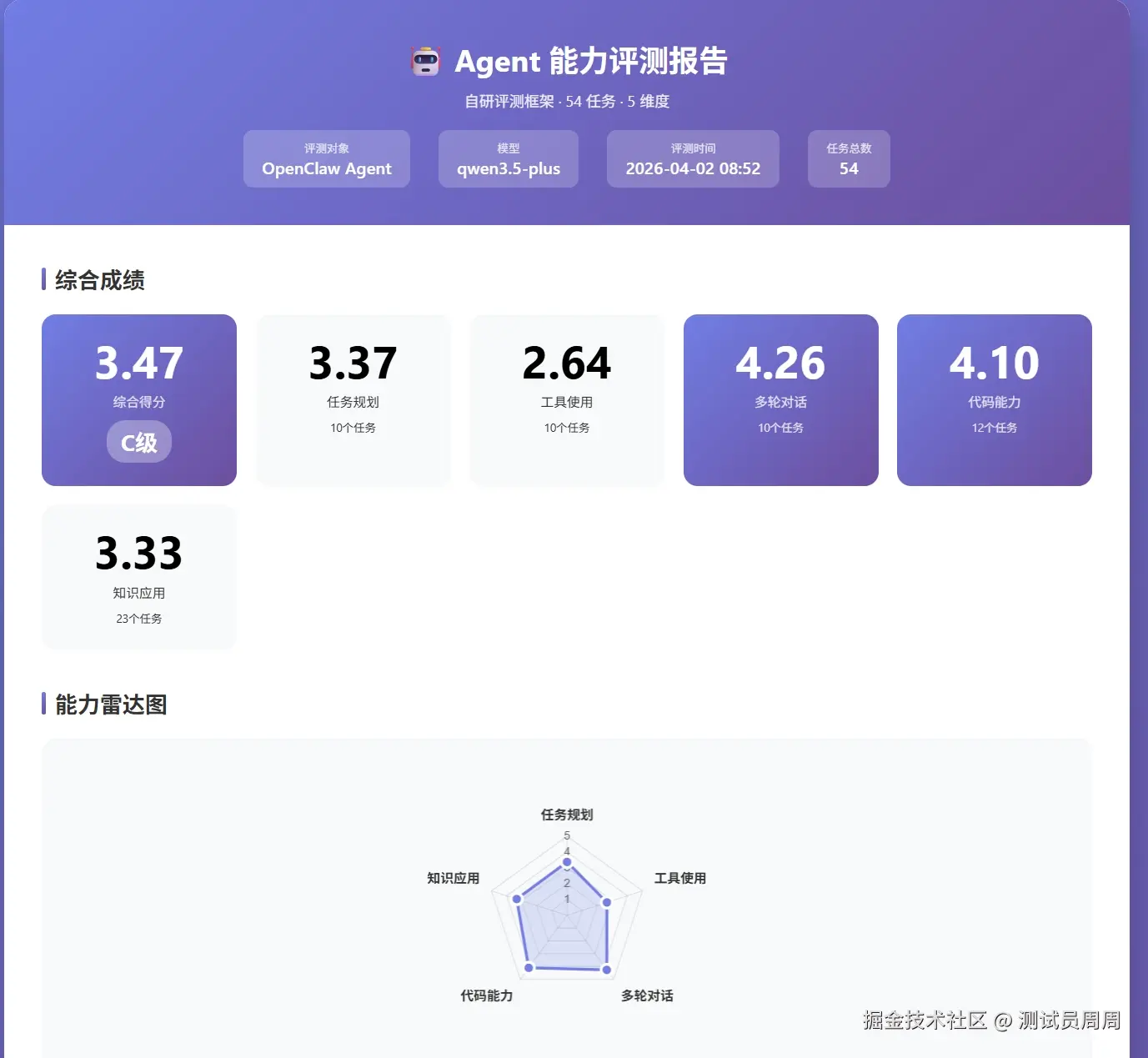
📊 综合成绩一览
评测基本信息:
| 项目 | 详情 |
|---|---|
| 评测对象 | OpenClaw Agent |
| 底层模型 | qwen3.5-plus(阿里巴巴通义千问) |
| 评测时间 | 2026-04-02 08:52 |
| 任务总数 | 54 个 |
| 评测维度 | 5 个核心维度 |
| 细粒度指标 | 15 个 |
| 综合得分 | 3.47/5.0(C 级) |
各维度得分:
| 维度 | 得分 | 任务数 | 等级 |
|---|---|---|---|
| 任务规划 | 3.37 | 10 个 | C+ |
| 工具使用 | 2.64 | 10 个 | D+ ⚠️ |
| 多轮对话 | 4.26 | 12 个 | B+ ✅ |
| 代码能力 | 4.10 | 12 个 | B+ ✅ |
| 知识应用 | 3.33 | 10 个 | C+ |
关键发现:
- 强项:多轮对话(4.26)和代码能力(4.10)表现优秀,达到 B+ 水平
- 弱项:工具使用(2.64)得分最低,是主要短板
- 潜力:任务规划和知识应用处于中等水平(3.3+),有提升空间
🎯 评测体系设计
为什么是这 5 个维度?
在设计评测体系时,我参考了清华 AgentBench、斯坦福 HELM 等主流评测框架,但最终选择了这 5 个维度:
1. 任务规划(Task Planning)→ Agent 的"大脑"
- 考察任务分解、依赖识别、执行顺序规划能力
- 这是 Agent 区别于普通 LLM 的核心能力
2. 工具使用(Tool Use)→ Agent 的"双手"
- 考察 API 调用、参数填充、错误处理能力
- 直接决定 Agent 能否完成实际工作
3. 多轮对话(Dialogue)→ Agent 的"嘴巴"
- 考察上下文理解、意图识别、回复质量
- 影响用户体验和交互效率
4. 代码能力(Coding)→ Agent 的"专业技能"
- 考察代码生成、调试、解释能力
- 面向开发者场景的核心能力
5. 知识应用(Knowledge)→ Agent 的"知识库"
- 考察事实准确性、推理能力、知识更新
- 决定回答的专业性和可靠性
📈 维度深度分析
1. 任务规划(3.37/5.0)- C+ 级
测试用例示例:
任务描述
任务 ID: tp_001
任务名称:数据分析报告
难度:Medium
任务描述:分析某电商平台的销售数据,生成包含趋势分析、用户画像、产品推荐的完整报告
评测结果:
| 指标 | 得分 | 说明 |
|---|---|---|
| 分解覆盖率 | 0.8 | 识别了 80% 的必要步骤 |
| 分解精确度 | 1.0 | 已识别的步骤都很具体 |
| 依赖识别准确率 | 1.0 | 步骤顺序完全正确 |
| 综合得分 | 3.35/5.0 |
典型问题:
- 步骤遗漏:未包含"数据清洗"这一关键步骤
- 粒度不均:有些步骤过细(如"打开 Excel"),有些过粗(如"进行分析")
- 边界模糊:未明确说明何时算"完成"
2. 工具使用(2.64/5.0)- D+ 级 ⚠️
典型问题:
- 参数遗漏:经常忘记必填参数,导致 API 调用失败
- 格式错误:日期、数字等格式不符合 API 要求
- 错误处理缺失:API 失败时缺少降级方案
- 认证问题:Token 过期后不知道刷新
3. 多轮对话(4.26/5.0)- B+ 级 ✅
亮点表现:
- 长期记忆:8 轮对话后仍能记住用户"预算 1 万"、"喜欢温泉"等关键信息
- 意图推断:从"想看樱花"推断出推荐 3-4 月出行
- 主动建议:主动提醒"日本签证需要提前办理"
4. 代码能力(4.10/5.0)- B+ 级 ✅
亮点表现:
- 代码规范:遵循 PEP8,变量命名清晰
- 异常处理:包含 try-except 处理文件不存在等情况
- 注释完整:关键逻辑都有中文注释
5. 知识应用(3.33/5.0)- C+ 级
典型问题:
- 知识滞后:训练数据截止后发布的新模型不了解
- 细节模糊:对复杂概念的解释有时过于简化
- 引用缺失:未标注信息来源,难以验证
🔍 典型案例分析
案例 1:工具使用失败分析
任务:调用 GitHub API 获取项目 Stars 数
Agent 执行过程:
- ✅ 正确识别需要调用 GitHub API
- ✅ 选择正确的端点:/repos/{owner}/{repo}
- ❌ 遗漏 User-Agent 请求头(GitHub API 要求)
- ❌ 未处理 403 速率限制错误
- ❌ 返回原始 JSON,未提取 stars 字段
python
# 改进后的代码
def fetch_github_stars(owner: str, repo: str) -> dict:
url = f"https://api.github.com/repos/{owner}/{repo}"
headers = {
'User-Agent': 'OpenClaw-Agent/1.0',
'Accept': 'application/vnd.github.v3+json'
}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
data = response.json()
return {
'success': True,
'stars': data.get('stargazers_count', 0),
'forks': data.get('forks_count', 0)
}
except requests.exceptions.RateLimitError:
return {'success': False, 'error': 'API 速率限制,请稍后重试'}
except Exception as e:
return {'success': False, 'error': str(e)}
📉 失分点统计
Top 5 失分原因:
| 排名 | 原因 | 失分占比 | 影响维度 |
|---|---|---|---|
| 1 | 参数遗漏/格式错误 | 28% | 工具使用 |
| 2 | 错误处理缺失 | 22% | 工具使用、任务规划 |
| 3 | 知识时效性不足 | 18% | 知识应用 |
| 4 | 任务步骤遗漏 | 17% | 任务规划 |
| 5 | 边界条件未处理 | 15% | 代码能力、工具使用 |
🛠️ 评测工具开源
项目结构:
目录结构
AGENT_BENCH/
├── benchmarks/ # 评测数据集
│ ├── task_planning/ # 任务规划测试集(10 题)
│ ├── tool_use/ # 工具使用测试集(10 题)
│ ├── dialogue/ # 多轮对话测试集(12 题)
│ ├── coding/ # 代码能力测试集(12 题)
│ └── knowledge/ # 知识应用测试集(10 题)
├── evaluators/ # 评测器实现
│ ├── task_planning_evaluator.py
│ ├── tool_use_evaluator.py
│ ├── dialogue_evaluator.py
│ ├── coding_evaluator.py
│ ├── knowledge_evaluator.py
│ └── metrics.py # 指标计算
├── reports/ # 评测报告
│ ├── full_eval_*.json
│ └── dashboards/
└── scripts/ # 执行脚本
└── run_eval.py
快速开始:
bash
# 1. 安装依赖
cd AGENT_BENCH
pip install -r requirements-eval.txt
# 2. 配置模型
export ALIBABA_API_KEY=your_api_key
export MODEL_NAME=qwen-plus
# 3. 运行评测
python scripts/run_eval.py \
--agent openclaw \
--dimensions all \
--output reports/my_eval_$(date +%Y%m%d_%H%M%S).json
# 4. 查看报告
python scripts/generate_report.py \
--input reports/my_eval_*.json \
--output reports/my_eval_report.html
🎓 评测方法论总结
1. 评测设计原则
1.1 真实性优先
- 测试用例来自真实用户场景,不是凭空编造
- 难度分级(Easy/Medium/Hard)基于实际复杂度
- 评分标准可量化,避免主观判断
1.2 细粒度优于粗粒度
- 不用简单的"通过/失败"二分法
- 每个维度拆分为 3 个可测量的指标
- 记录详细执行过程,便于归因分析
1.3 可复现性
- 所有测试用例版本化管理
- 评分逻辑代码化,避免人工评分波动
- 完整记录评测环境和配置
📝 总结与展望
本次评测结论:
优势:
- 多轮对话能力突出(4.26 分),适合客服、咨询等场景
- 代码能力扎实(4.10 分),可辅助开发者工作
- 任务规划基本合格(3.37 分),能处理中等复杂度任务
短板:
- 工具使用能力薄弱(2.64 分),是主要瓶颈
- 知识时效性不足(3.33 分),需要 RAG 增强
- 错误处理普遍缺失,鲁棒性有待提升
综合评级:C 级(3.47/5.0)
- 可用于:内容创作、代码辅助、简单咨询
- 暂不适合:关键业务决策、高精度工具调用、复杂任务编排
关于作者:14 年测试老兵,"测试员周周",专注 AI/Agent 安全测试。
