

一、尴尬的"智能"屏幕
上周带我的闺女去商场的有了场,看到商场大门口的位置,立着一块大屏,上面是个漂亮的数字人导购。我走过去问,抱着试试看的态度,想要看看他有没有接入大模型:“你好,请问我想去儿童游乐游场,怎么走?”
屏幕略微迟疑,然后闪烁了一下,数字人张嘴了——但声音和口型完全对不上,而且延迟了几秒才开始回答。尽管他给了我准确的回答,但是表情僵硬,口不对心,体验感很差。
这就是数字人行业的尴尬现状:看起来像AI,用起来像播放器。
问题出在哪?
我后来研究了一下,发现这类"智能屏"的技术架构基本是这样的:
问题显而易见:
-
- 延迟爆炸:每个环节都是独立的API调用,串行执行,3-5秒延迟是常态
-
- 表情僵硬:TTS只管声音,表情是预录的,两边根本没联动
-
- 无法交互:用户打断?不好意思,请等这一段播完
这哪是 AI Agent?这分明是个带语音的 PPT。
二、我想要的"真·智能屏"
作为一个开发者,我理想中的AI屏幕应该是这样的:
- 实时响应:说话后略微等待后,可能 1s 内开始回答,就像真人一样
- 表情自然:声音和表情同步,有情绪变化
- 可打断:像真人对话一样,随时可以插话
- 能开发:提供SDK,我能自己定制功能
带着这个需求,我找到了魔珐科技的星云SDK。
三、星云架构:为什么它能做到?
在动手之前,我先研究了一下星云的技术架构,发现它和传统方案有本质区别:
传统方案 vs 星云方案
| 维度 | 传统数字人 | 星云方案 |
|---|---|---|
| 渲染方式 | 服务端渲染 / 预录视频 | 端侧实时合成(碎片 + 参数混合) |
| 对话时传输 | 持续传输视频流(几 MB/s) | 只传驱动参数(几十 KB) |
| 素材加载 | 不需要(全靠服务端) | 首次下载碎片素材(~ 几 MB,可缓存) |
| 驱动响应 | 3-5 秒 | ~1 秒(实测 900-1100ms) |
| 表情驱动 | 预录 / 简单 TTS 联动 | AI 实时生成口型 + 表情参数 |
| 开发方式 | 封闭系统 | 开放 SDK/API |
| 硬件要求 | 昂贵 GPU 服务器 | 百元级芯片即可(端侧只做解码 + 合成) |
核心差异在于:星云把"合成"搬到了端侧。
这意味着:
- 对话时不传视频:交互过程只传输几十 KB 的口型/表情参数流,服务端不需要为每个用户做 GPU 渲染
- 素材一次加载:各状态的动画碎片(idle/think/speak 等)首次从 CDN 下载后缓存,后续不再重复下载
- 端侧实时合成:SDK 在本地将预加载的碎片 + 实时参数进行解码、变形、叠加,生成最终画面
四、实战:从零搭建一个会说话的屏幕助手
码农界的至理名言:Talk is cheap show me the code!
下面我用星云SDK(JS版本)实际搭建一个可运行的AI屏幕助手。
4.1 准备工作
第一步:注册账号
访问 魔珐星云官网,注册开发者账号。
第二步:创建驱动应用:
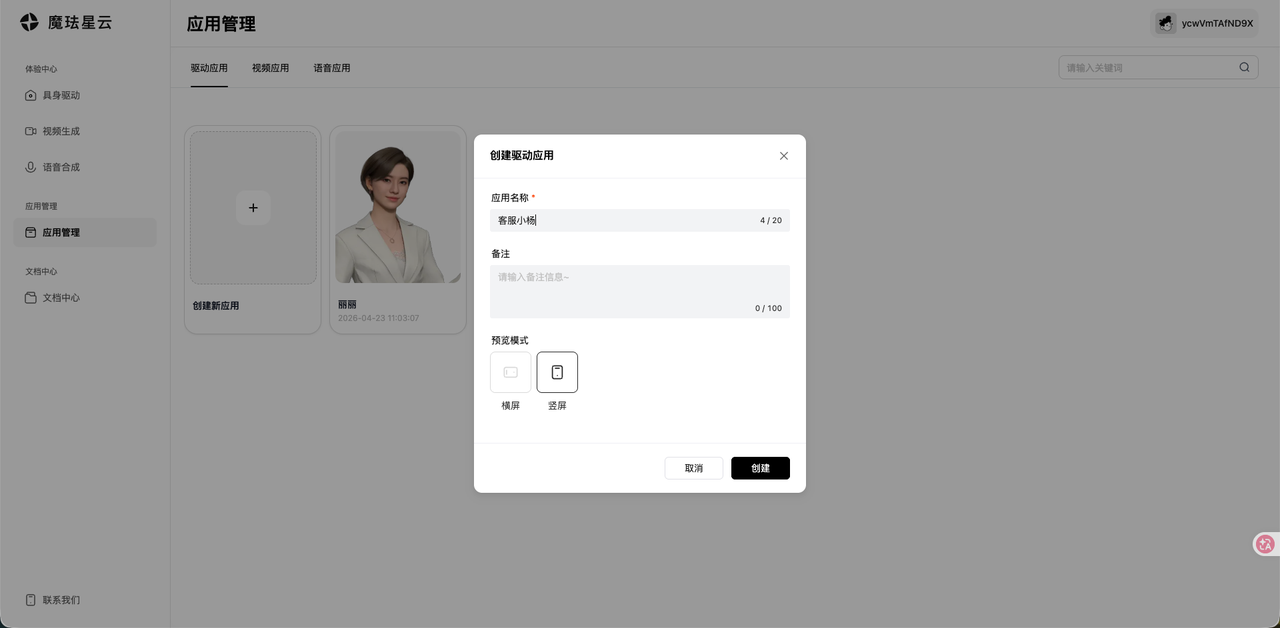
登录后进入「应用中心」,点击「创建驱动应用」。在这一步你需要:
- 选择数字人角色(超写实、二次元、卡通等多种风格),我粗略输了一下大概 130 多种任务选择
- 选择音色,音色大概有 70 多种,分为多种角色:教师、专业、电商、优雅,大多都做了优化,与人声很像
- 选择表演风格,大都都包含3种风格,自然、疑惑、严肃、开心等。
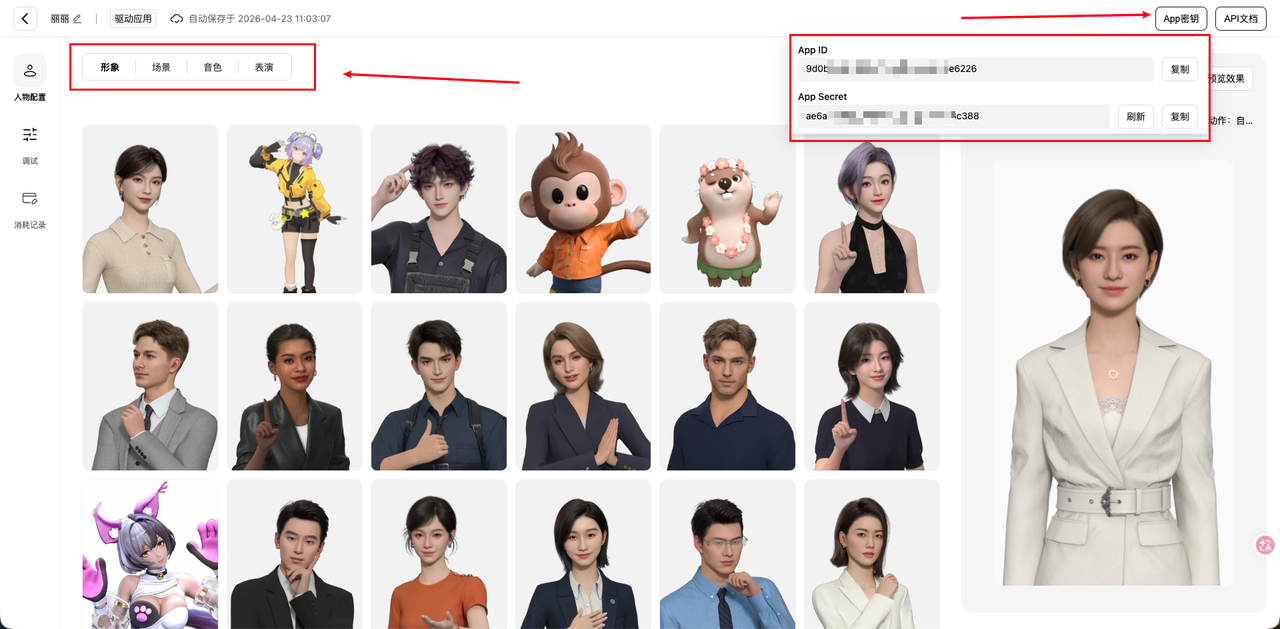
创建完成后,系统会生成 App ID 和 App Secret,这是后续接入SDK的唯一凭证。
第三步:了解SDK引入方式
星云JS SDK 通过 CDN
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
4.2 项目初始化(Vue 3 + Vite)
我选择 Vue 3 + Vite 作为开发框架,当然你也可以用纯HTML——SDK本身不依赖任何框架。其中在开发模式下注意,要开启日志,方便调试 bug;生产模式下记得关闭。
# 使用 pnpm 创建项目pnpm create vite xingyun-demo --template vue-ts
cd xingyun-demo
pnpm install
然后在 index.html 的 中引入SDK:
<body><div id="app"></div><!-- 引入魔珐星云SDK(必须在body中) --><script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script><script type="module" src="/src/main.ts"></script></body>
4.3 核心代码:封装 AvatarService
SDK的所有交互都围绕一个 XmovAvatar 实例展开。我将它封装成一个单例服务类,方便在整个项目中复用。
创建 src/services/AvatarService.ts:
/**
* 魔珐星云 SDK 服务封装
* 基于官方文档:https://www.xingyun3d.com/developers/52-183
*/export class AvatarService {private static instance: AvatarService | null = null;private avatar: any = null;private constructor() {}public static getInstance(): AvatarService {if (!AvatarService.instance) {
AvatarService.instance = new AvatarService();}return AvatarService.instance;}/**
* 初始化数字人
* @param containerId 渲染容器ID(如 '#sdk')
* @param appId 驱动应用的 appId
* @param appSecret 驱动应用的 appSecret
*/public async init(containerId: string, appId: string, appSecret: string) {if (this.avatar) return;// 1. 创建实例this.avatar = new (window as any).XmovAvatar({
containerId,
appId,
appSecret,// 网关地址
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session',// 开启硬件加速
hardwareAcceleration: 'prefer-hardware',// 接收SDK消息onMessage(message: any) {console.log('[SDK] onMessage:', message);},// 监听数字人状态变化onStateChange(state: string) {console.log('[SDK] 状态变化:', state);},// 监听语音播放状态onVoiceStateChange(status: string) {console.log('[SDK] 语音状态:', status);// status === 'voice_start' → 开始说话// status === 'voice_end' → 说话结束},// 是否开启日志
enableLogger: true,
});// 2. 初始化连接(异步,会下载3D模型资源)await this.avatar.init({onDownloadProgress: (progress: number) => {console.log(`[SDK] 资源加载: ${progress}%`);},});}/**
* 让数字人说话(非流式)
* 官方API: speak(ssml: string, is_start: boolean, is_end: boolean)
*/public speak(text: string) {this.avatar?.speak(text, true, true);}/**
* 流式说话(对接大模型流式输出)
* 第一句: speak(text, true, false)
* 中间句: speak(text, false, false)
* 最后句: speak(text, false, true)
*/public speakStream(text: string, isStart: boolean, isEnd: boolean) {this.avatar?.speak(text, isStart, isEnd);}// === 状态切换 ===public idle() { this.avatar?.idle(); } // 待机等待public interactiveIdle() { this.avatar?.interactiveidle(); } // 待机互动(也可用于打断)public listen() { this.avatar?.listen(); } // 倾听状态public think() { this.avatar?.think(); } // 思考状态// === 其他工具 ===public setVolume(v: number) { this.avatar?.setVolume(v); } // 音量 0~1public showDebugInfo() { this.avatar?.showDebugInfo(); } // 显示调试面板public hideDebugInfo() { this.avatar?.hideDebugInfo(); } // 隐藏调试面板/** 销毁实例,释放资源(页面离开时必须调用) */public destroy() {this.avatar?.destroy();this.avatar = null;}}export const avatarService = AvatarService.getInstance();
4.4 前端页面
创建 src/components/AvatarScreen.vue:
<script setup lang="ts">
import { ref, onUnmounted } from 'vue'
import { avatarService } from '../services/AvatarService'
const isInitialized = ref(false)
const isLoading = ref(false)
const inputText = ref('你好,欢迎使用魔珐星云数字人助手!')
// 从 .env 读取(Vite 要求 VITE_ 前缀)
const APP_ID = import.meta.env.VITE_XINGYUN_APP_ID
const APP_SECRET = import.meta.env.VITE_XINGYUN_APP_SECRET
const initAvatar = async () => {
isLoading.value = true
try {
// 容器ID对应页面中的 <div id="sdk">
await avatarService.init('#sdk', APP_ID, APP_SECRET)
isInitialized.value = true
} catch (e) {
console.error('初始化失败:', e)
alert('初始化失败,请检查控制台')
} finally {
isLoading.value = false
}
}
// 非流式播报
const handleSpeak = () => {
if (!inputText.value) return
avatarService.speak(inputText.value)
}
// 页面卸载时销毁实例
onUnmounted(() => avatarService.destroy())
</script>
<template>
<div class="container">
<h1>魔珐星云 AI 屏幕助手</h1>
<!-- 容器必须有明确的宽高,否则无法渲染 -->
<div id="sdk" style="width: 540px; height: 960px;"></div>
<button v-if="!isInitialized" @click="initAvatar" :disabled="isLoading">
{{ isLoading ? '加载中...' : '初始化数字人' }}
</button>
<div v-if="isInitialized">
<textarea v-model="inputText" placeholder="输入文本..."></textarea>
<button @click="handleSpeak">让TA说</button>
<button @click="avatarService.idle()">待机</button>
<button @click="avatarService.listen()">倾听</button>
<button @click="avatarService.think()">思考</button>
<button @click="avatarService.interactiveIdle()">打断</button>
</div>
</div>
</template>
4.5 环境变量
创建 .env 文件(不要提交到Git):
VITE_XINGYUN_APP_ID=你的AppID
VITE_XINGYUN_APP_SECRET=你的AppSecret
4.6 运行

pnpm dev
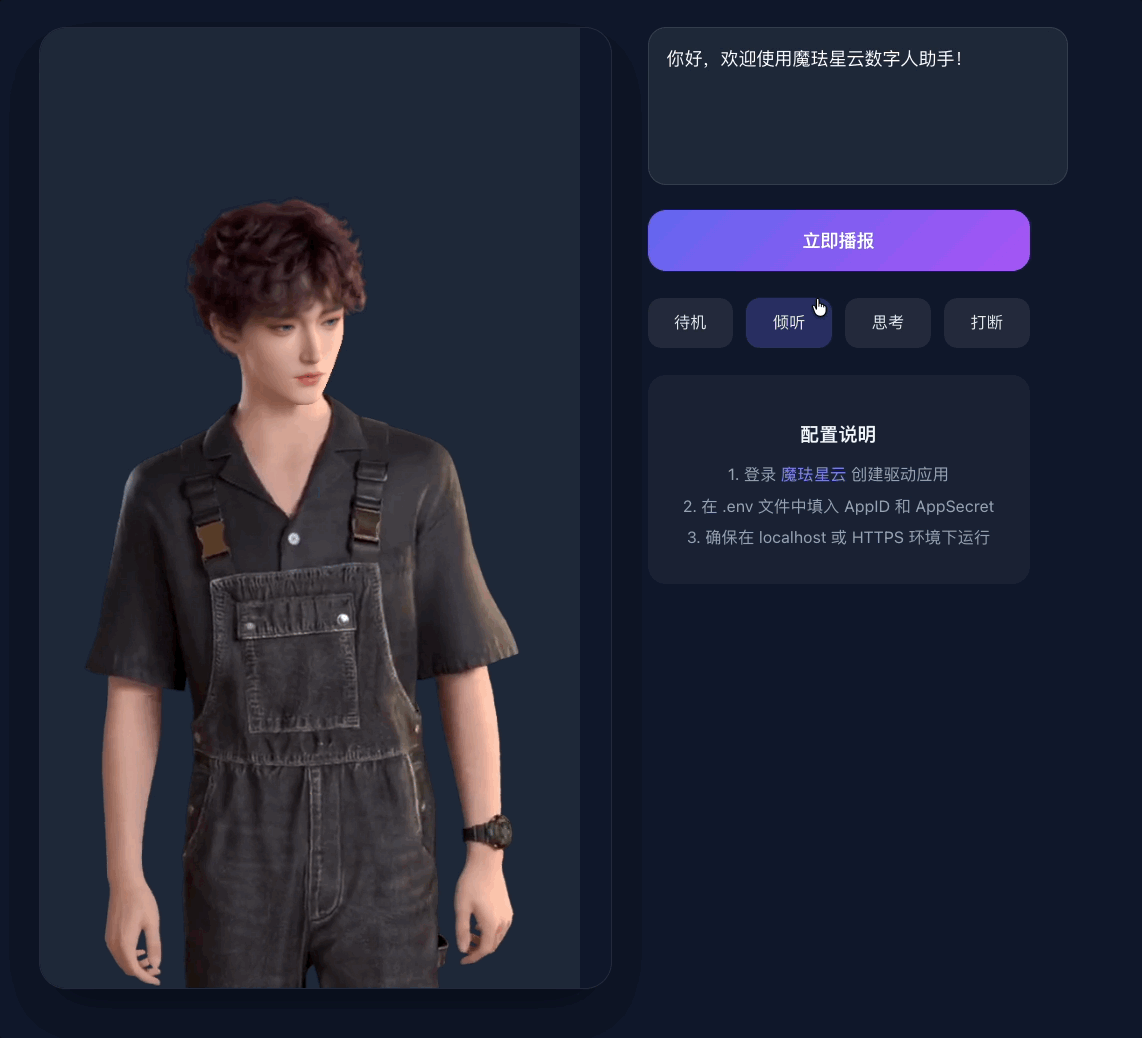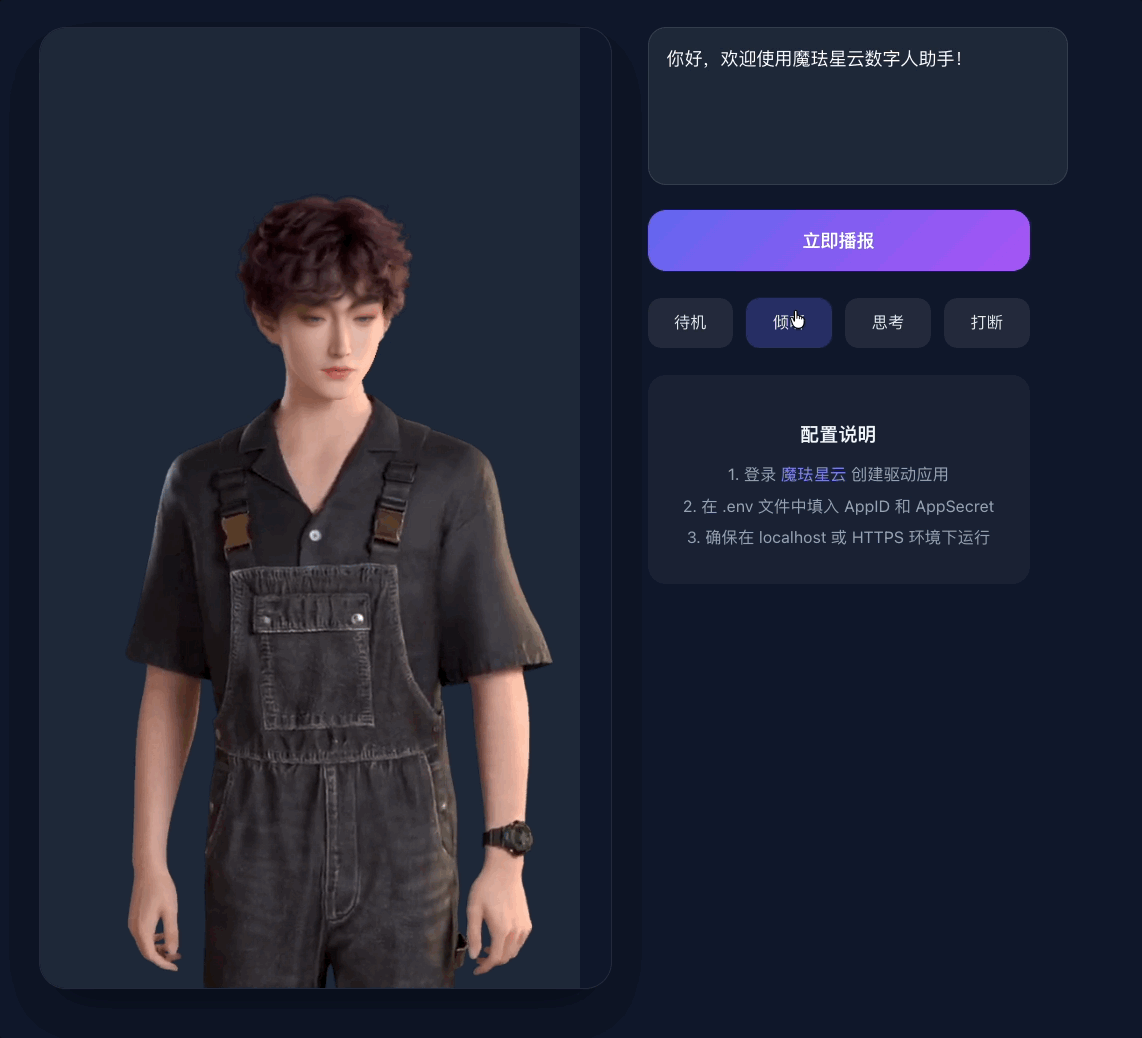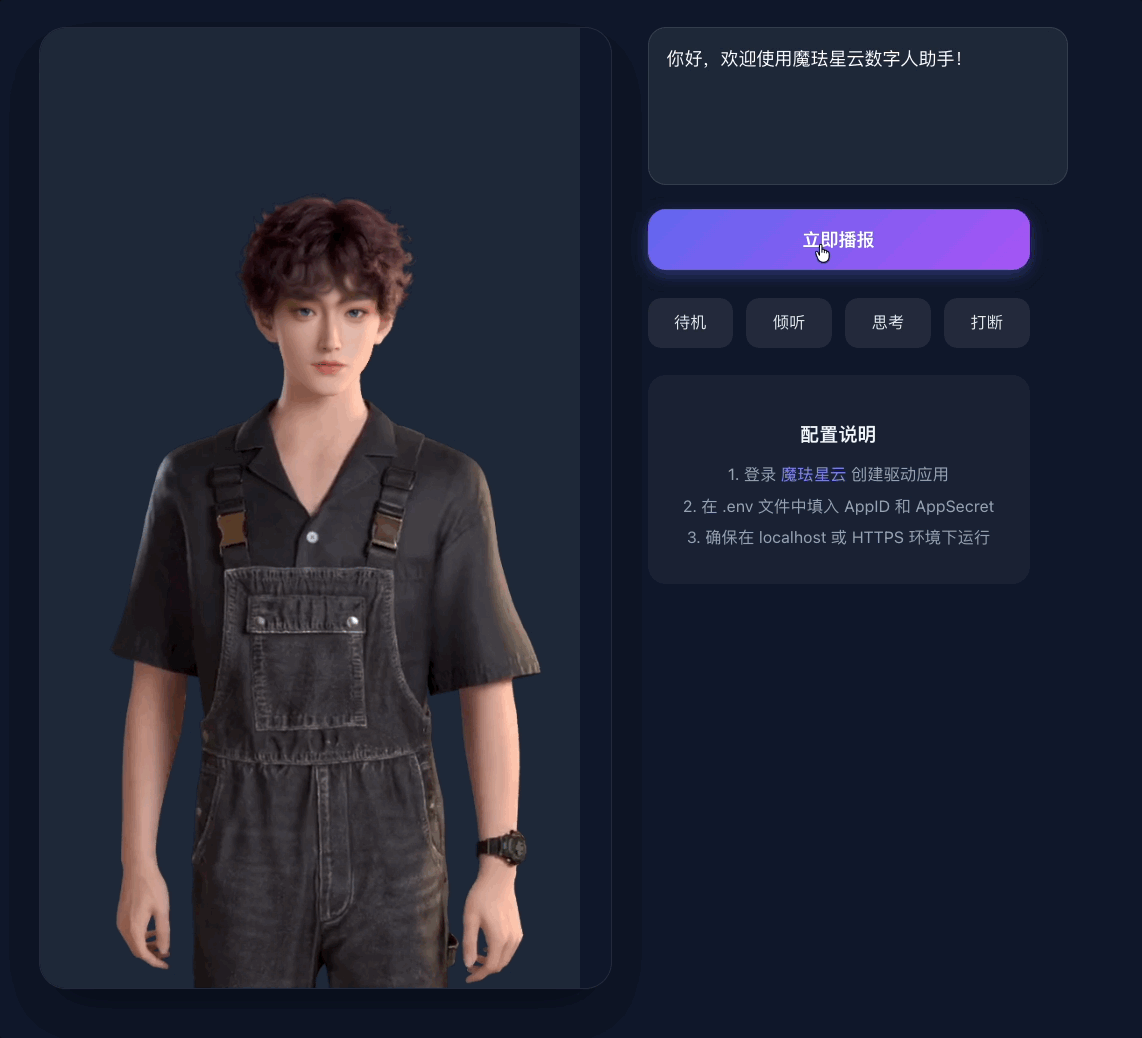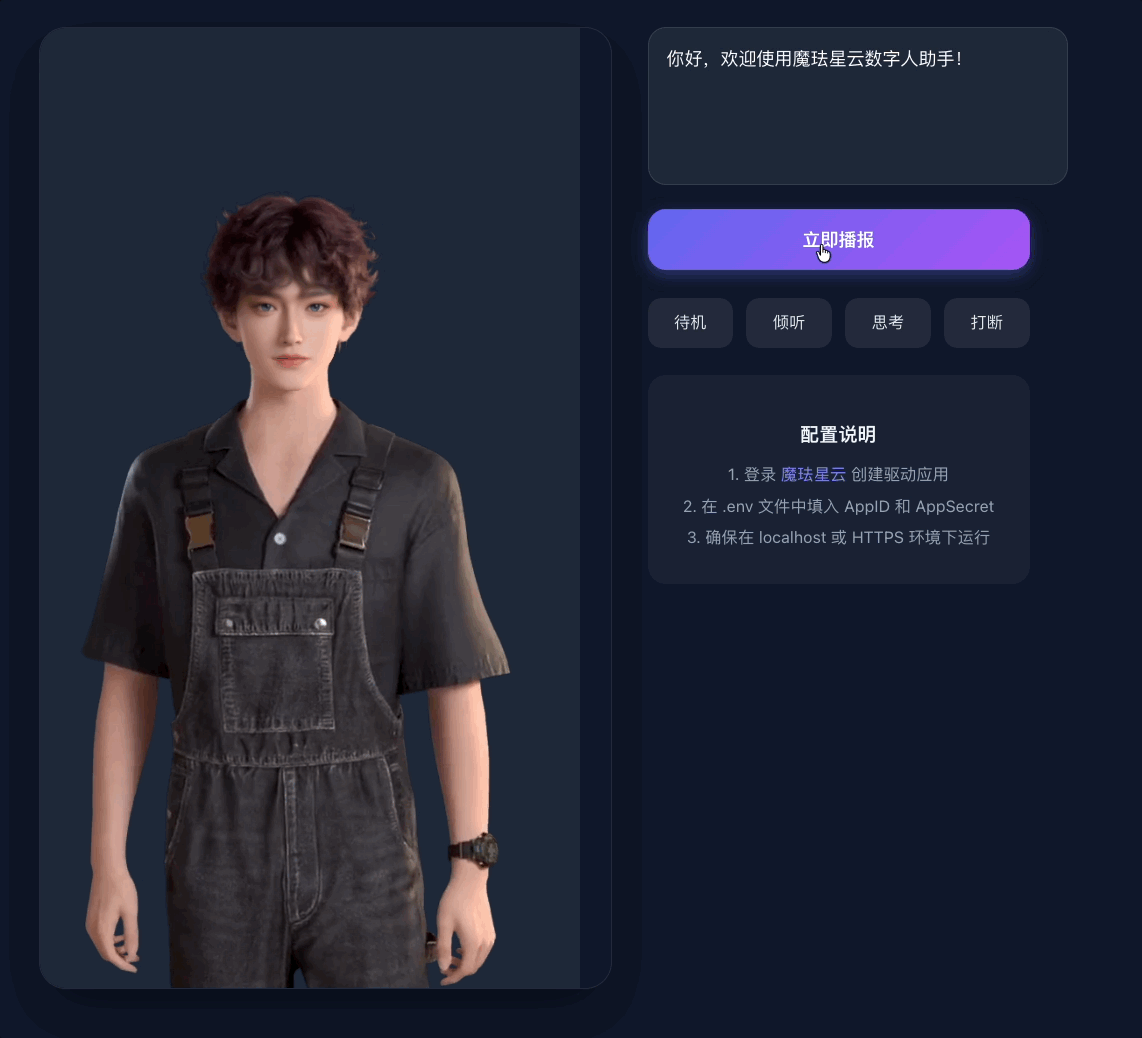
打开浏览器访问 http://localhost:5173,点击「初始化数字人」按钮。等待3D资源加载完成后(首次大约10-20秒),你就能看到一个活灵活现的数字人出现在页面上了。
在输入框输入文本,点击「让TA说」——数字人会用选定的音色开口说话,口型、表情、手势全部实时生成,不是播放预录视频。
4.7 实测结果
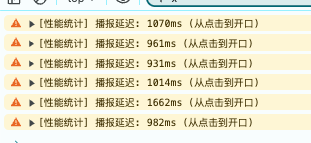
1. 语音播报
经过在 onVoiceStateChange 和 speak 的方法进行语音的监听,在点击播报按钮与语音播报的时间基本稳定在 1000ms 左右,速度是可以的。
2. 动作表情
经过在 onStateChange 和 idle、interactiveIdle、listen、think 方法中进行埋点,在点击切换状态时的延迟统计如下,少数在1s以内,大多均在2s左右。

五、关键技术解析
5.1 性能实测:响应速度究竟如何?
在开发 Demo 时,我通过监听 speak() 调用到 onVoiceStateChange(start) 事件,实测了 “从点击播报到数字人开口” 的真实延迟。
实测结果:
- 稳定在 900ms - 1100ms 之间(公网环境)。
- 对比传统方案:传统视频流驱动方案通常需要 3000ms 以上,星云在响应速度上快了近 3 倍。
为什么是 1000ms 左右?
这 1 秒钟内,SDK 完成了网络往返、云端 TTS 实时解算以及端侧为了保证播放流畅预留的微量缓冲(Buffer)。
5.2 speak 的流式调用:对接大模型
这是实际开发中最常用的模式。大模型(如豆包、通义千问)是流式输出的,你不需要等它全部生成完再让数字人开口。
// 模拟大模型流式输出const chunks = ['今天天气不错,', '适合出去走走,', '你有什么计划吗?'];for (let i = 0; i < chunks.length; i++) {const isStart = (i === 0);const isEnd = (i === chunks.length - 1);
avatarService.speakStream(chunks[i], isStart, isEnd);}
关键规则:
- 第一句:is_start = true
- 最后一句:is_end = true
- 中间所有句子:is_start = false, is_end = false
- 一段 speak 结束后,必须先调用 interactiveIdle() 或 listen() 切换状态,才能开始下一段 speak
5.3 SSML:让数字人做动作

星云支持通过 SSML 标记语言,在说话的同时触发预设动作(KA,Key Action):
// 让数字人一边挥手打招呼,一边说欢迎语const ssml = `<speak>
<ue4event>
<type>ka</type>
<data><action_semantic>invite01</action_semantic></data>
</ue4event>
欢迎来到星云具身 3D 数字人平台,这里有超多精彩内容等你发现~
</speak>`;
avatarService.speak(ssml);
你可以通过 KA查询接口 获取当前角色支持的所有动作列表,比如 Welcome(欢迎)、dance(跳舞)等。示例如下:
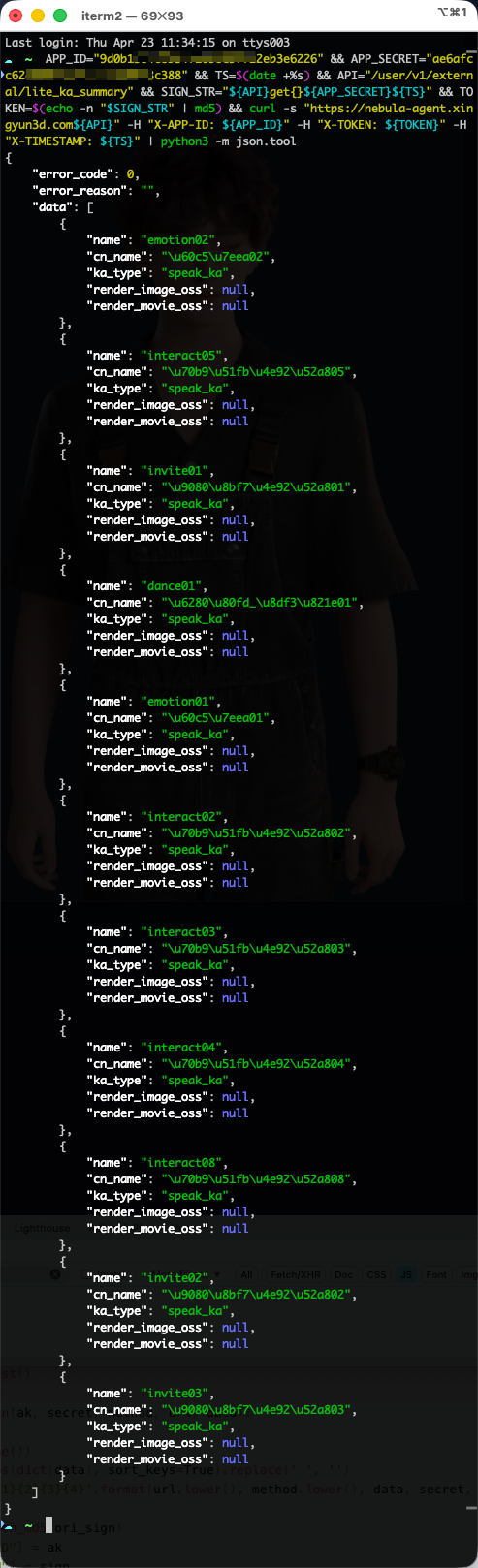
通过 devtools 观察,当切换状态时,第一次加载会请求若干 mp4 表情动作素材,大小均在 100kb 左右,加载时间100ms。
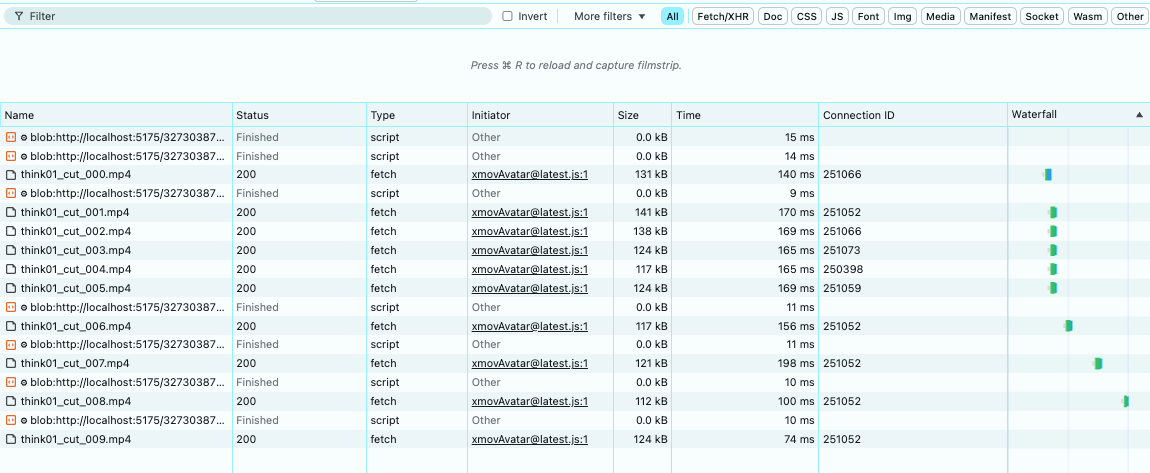
后续的拉取则会直接走缓存 disk cache ,耗时基本10ms 左右。
总体而言,通过素材下载,本地渲染模式,动作流畅度也会显著提升,效果很好。
5.4 端侧渲染的硬件要求
星云SDK支持多平台,而且对硬件要求出乎意料地低:
官方实测数据:百元级芯片即可运行。我在一台普通的 MacBook(集成显卡)上测试,渲染完全流畅。
| 平台 | 部署方式 | 硬件要求 |
|---|---|---|
| Web(PC / 移动端) | script标签引入 | Chrome 90+,WebGL 支持 |
| Android | Android SDK | Android 11+,RK3588/RK3566 |
| iOS | 原生集成 | iOS 16+ |
六、实际落地场景分析
在理解了SDK能力之后,我们来看几个真实的落地方向:
场景一:大厅服务AI讲解员

核心价值:
- 24小时在岗,服务标准化
- 不需要联网传输视频,参数流 <10KB
- 支持 Widget 组件,可以在数字人旁边同步展示图片、视频、图表
场景二:医院导诊AI
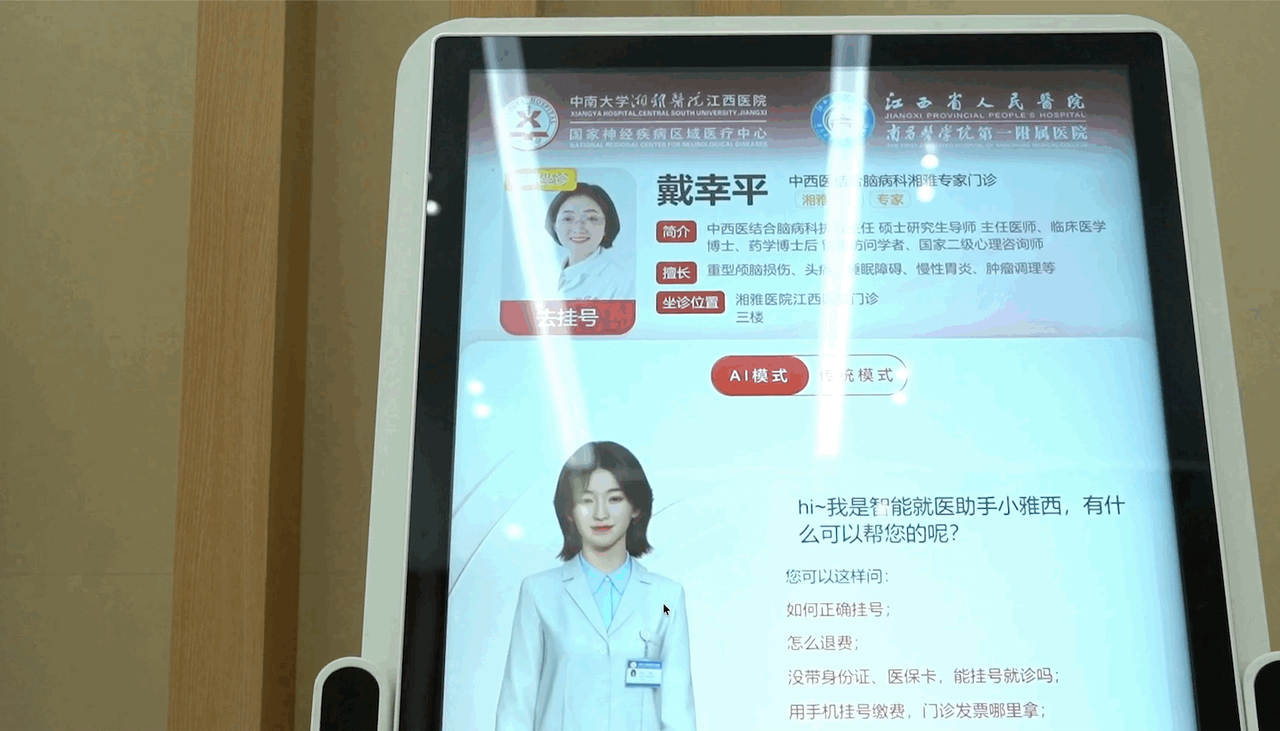
数字人部署在门诊大厅触摸屏上,患者走近后主动打招呼,通过语音问诊引导患者到正确的科室。
为什么必须是具身智能而不是文字聊天框?
- 老年患者不熟悉打字交互
- 有"面对面"的数字人,患者信任度更高
- 表情和手势可以传达关怀感
场景三:AI英语陪练
![[图片]](https://i-blog.csdnimg.cn/direct/79fae2c20fd646e495b67c7fa4671b09.png)
数字人出现在平板上,与用户进行实时英语对话。SDK的低延迟特性让对话体验接近真人。
七、踩坑记录(真实开发经验)
在实际接入过程中,我踩了不少坑,这里记录下来帮后来者避雷:
坑1:容器没有设置宽高 → 数字人渲染空白
- 现象:init 成功,控制台没有报错,但页面一片空白。
- 原因:SDK 内部会读取容器的 width 和 height 来创建画布。如果你用 CSS max-width 或 flex 自动撑开,初始化时容器宽高可能是 0。
- 解决:给容器设置明确的像素值宽高。
<!-- ✅ 正确 --><div id="sdk" style="width: 540px; height: 960px;"></div><!-- ❌ 错误:高度由内容撑开,初始化时为0 --><div id="sdk" style="width: 100%;"></div>
坑2:只能在 localhost 或 HTTPS 下运行
- 现象:通过局域网IP(如 192.168.x.x:5173)访问时,SDK 初始化报错。
- 原因:SDK 内部使用了浏览器的安全API(如麦克风权限、WebGL 上下文),这些API只在安全上下文中可用。
- 解决:开发时用 localhost,部署时必须上 HTTPS。
坑3:没有 playIdle() 方法
- 现象:调用 avatar.playIdle() 报错 is not a function。
- 原因:官方 API 中待机方法叫 idle(),不叫 playIdle()。完整的状态方法列表:
| 方法 | 作用 |
|---|---|
| idle() | 待机等待 |
| interactiveidle() | 待机互动 / 打断当前状态 |
| listen() | 进入倾听状态 |
| think() | 进入思考状态 |
| speak(text, is_start, is_end) | 说话 |
坑4:连续调用 speak 导致行为异常
- 现象:上一句还没说完,就调用下一句 speak,导致数字人行为混乱。
- 解决:两段独立的 speak 之间,必须用 interactiveIdle() 或 listen() 做一次状态切换。可以通过 onVoiceStateChange 回调监听 voice_end 事件来判断是否说完。
// 通过回调监听说话结束onVoiceStateChange(status: string) {if (status === 'voice_end') {// 说完了,可以切换状态或开始下一句
avatar.interactiveidle();}}
坑5:网关地址写错
- 现象:ERR_NAME_NOT_RESOLVED 或 404。
- 原因:gatewayServer 必须写完整路径,不是域名。
// ✅ 正确(完整路径)
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session'// ❌ 错误(只写域名)
gatewayServer: 'https://api.xingyun3d.com'
八、总结:星云SDK的真实体验
用了两周星云SDK,我的感受是: 真正打动我的地方
-
- 500ms驱动响应——不是宣传噱头,实测确实做到了。对比传统方案3-5秒的延迟,这是代际级的提升
-
- 端侧渲染架构——不需要昂贵的GPU服务器,百元芯片就能跑。对于需要大规模部署的场景(比如连锁门店),成本优势巨大
-
- 状态机设计合理——idle → listen → think → speak 的状态流转清晰,配合 onStateChange 和 onVoiceStateChange 回调,可以精确控制交互流程
-
- 流式speak——可以无缝对接大模型的流式输出,做到"大模型边输出,数字人边说话"
需要注意的地方
-
- 首次加载较慢:3D模型资源首次下载需要10-20秒,后续有缓存
-
- 只支持 localhost / HTTPS:开发调试时注意网络环境
-
- 调试建议:开发阶段建议设置 enableLogger: true,并使用 showDebugInfo() 查看渲染状态
适合什么场景?
| ✅ 强烈推荐 | ⚠️ 需要评估 |
|---|---|
| 商场 / 展厅导购讲解 | 纯线上聊天机器人(用文字就够了) |
| 医院 / 银行 / 政务导诊 | 超低成本 IoT 设备(芯片太弱) |
| AI 英语陪练 / 虚拟老师 | |
| 智能客服终端 |
一句话总结:如果你需要做一个"真正能交互"的AI屏幕,星云 SDK 是目前我看到的比较成熟的方案。它不是把几个 API 拼在一起,而是从底层架构上解决了延迟、表情、渲染这些核心问题。
相关链接:
- 星云官网跳转:星云官网
本文基于魔珐星云 JS SDK(2026-04-10 06:27:57 该 SDK 最后修改时间)版本实测,代码可直接运行。如有问题欢迎评论区交流。
