

上周五下午组里做代码评审,一个实习生把 RAG 检索、文档解析、答案生成、质量评分、人工审核全塞进一张 StateGraph 里,节点数干到 17 个,条件边画得像一碗意大利面。
评审的时候没人说话,因为大家都知道这东西能跑,但没人敢碰——改一个节点的输出结构,五个条件边跟着炸。
这不是个别现象。LangGraph 官方文档里专门有一节讲 Subgraph,开篇就说得很直白:当图变得复杂时,将其拆分为更小的子图可以提高可维护性和可重用性1。
但"拆"这三个字背后,藏着状态边界怎么划、错误怎么隔离、调试怎么做、嵌套层数怎么控制等一系列工程决策。
面试里被问到 Subgraph,如果你只会说"就是把大图拆成小图",基本上等于没答。

17个节点的意大利面,谁敢动
为什么复杂任务必须拆子图
单图膨胀的工程代价
一张 StateGraph 从 5 个节点膨胀到 15 个以上,表面上只是"多了几条边",实际上会同时引爆三个工程问题。
第一是认知负载失控。LangGraph 的条件边本质上是 Python 函数返回的字符串路由,节点多了之后,你需要同时在脑子里维护"哪个函数在什么条件下返回什么字符串"这件事。
这和写一个 2000 行的 switch-case 没有本质区别,只是换了个图的形式包装。
第二是状态结构污染。
所有节点共享同一份 State,当检索节点往里塞了 retrieved_docs,评分节点又塞了 quality_score,生成节点还要读 user_feedback,你的 State 类会变成一个什么都装的垃圾抽屉。
后续任何一个节点想改字段名,你都得全局搜索确认没有别的节点在读。
第三是测试粒度丧失。你想单独测试"检索-评分"这条链路,但因为它和"生成-审核"链路在同一个图里,你不得不把整张图都编译起来跑一遍。
mock 掉一半节点、只测另一半,在单图架构下需要手动断边,成本极高。
这三个问题叠加在一起,就是那张 17 节点图在评审时没人敢碰的真实原因。不是能力问题,是架构本身在惩罚修改者。
从真实岗位需求看嵌套必要性
把视角从实验室拉到招聘市场,你会发现 Subgraph 不只是"好习惯",而是岗位要求里隐含的判断标准。
OpenAI 2026 年 4 月挂出的 Applied AI Engineer(Codex Core Agent)岗位,薪资区间 385K,JD 里明确要求能设计"可组合的 agent 工作流"[2](developer.baidu.com/article/det…?
id=6593522)。
Anthropic 同期的 Fellows Program(AI Safety / AI Security 方向)虽然偏研究,但岗位描述里也强调了对"复杂 agent 系统的架构理解"33。
这两个岗位的共同点是:它们不是在招"会用 LangGraph 跑 demo"的人,而是在招能把复杂任务拆解成可独立开发、可独立测试、可独立部署的模块化架构的人。
百度开发者中心 2026 年 4 月的一篇 LangGraph 解析文章里给了一组数据:某头部互联网企业用 LangGraph 重构客服系统后,复杂问题解决率提升 40%,人工干预需求减少 65%。
这个数字的背后,大概率就是把原来一张大图拆成了"意图识别子图""知识检索子图""工单处理子图"等独立模块,每个模块有自己的状态边界和失败处理逻辑。
面试官问 Subgraph,本质上是在筛一件事:你有没有从"能跑"到"能维护"的工程意识。
Subgraph 的核心概念与结构语义
子图与父图的状态映射机制
Subgraph 在 LangGraph 里不是一个独立的概念,它是 StateGraph 的一个普通节点——只不过这个节点本身也是一张 StateGraph。
这个设计选择非常关键,因为它决定了子图和父图之间的关系本质上是"节点与图"的关系,而不是"图与图"的对等关系。
当你把一个子图作为节点添加到父图时,LangGraph 要求你显式定义状态映射。
子图有自己的 State 定义,父图也有自己的 State 定义,两者不一定相同,甚至通常不应该相同。
映射机制解决的就是"父图的哪些字段要传给子图、子图的哪些字段要回传给父图"这个问题。
用代码说更清楚:
from langgraph.graph import StateGraph
from typing import TypedDict, Annotated
class ParentState(TypedDict):
query: str
docs: list[str]
answer: str
confidence: float
class ChildState(TypedDict):
query: str
docs: list[str]
score: float
child_graph = StateGraph(ChildState)
# ... 子图节点和边的定义 ...
compiled_child = child_graph.compile()
parent_graph = StateGraph(ParentState)
parent_graph.add_node("retrieval_subgraph", compiled_child)
注意这里 ParentState 有 confidence 字段,ChildState 没有;ChildState 有 score 字段,ParentState 也没有。
如果没有任何映射配置,LangGraph 默认的行为是按字段名做交集匹配——只有 query 和 docs 会自动双向传递。
confidence 不会传进子图,score 不会回传给父图。
这个默认行为是安全的,但也是很多新手踩坑的地方:他们以为"子图能看到父图的所有状态",实际上只能看到字段名交集的部分。
子图的编译与调用语义
子图在添加到父图之前必须先编译(compile())。这个约束不是形式主义的,而是有工程含义的:编译后的子图是一个封闭的执行单元,它的内部结构对父图不可见。
父图只知道"这个节点接收某种输入、产生某种输出",不知道里面有几个节点、几条边。
这和微服务架构里"服务间只通过 API 通信,不共享内部实现"的原则完全一致。编译后的子图就相当于一个微服务,父图是调用方。
调用语义上,当父图的执行引擎走到子图节点时,会执行以下步骤:
-
根据状态映射规则,从父图当前状态中提取子图需要的字段,构造子图的初始状态。
-
在子图内部完整执行一遍图逻辑,直到子图到达终止条件。
-
根据状态映射规则,把子图最终状态中需要回传的字段写回父图状态。
-
父图继续执行下一条边。
这个过程是同步的、原子的——从父图的视角看,子图节点就是一个普通函数调用,只不过这个"函数"内部有自己的循环、分支和状态管理。

编译完就是黑盒,别想偷看
状态边界设计:子图该看到什么、不该看到什么
全量透传 vs 字段投影的取舍
状态边界设计是 Subgraph 嵌套里最核心的工程决策,没有之一。你在这个问题上做的选择,直接决定了子图的可重用性、可测试性和安全性。
有两种极端策略。第一种是全量透传:让子图的 State 和父图的 State 完全一致,或者用 operator.add 之类的 reducer 把父图状态一股脑倒进去。
好处是简单,不用写映射逻辑;坏处是子图变成了父图的附属品,你不可能把这张子图拿去另一个父图里复用,因为它依赖了太多它不该知道的字段。
第二种是严格投影:子图只定义自己需要的字段,和父图做最小交集映射。好处是子图完全自包含,可以在任何父图里复用;坏处是你需要手动写映射函数,当字段较多时会有一定的样板代码量。
工程上的正确答案几乎总是偏向严格投影这一侧。原因很简单:子图一旦依赖了父图的某个字段,这个依赖就会像技术债一样滚雪球。
今天子图偷偷读了一下父图的 user_id,明天另一个父图想复用这张子图但没有 user_id 字段,你就得改子图代码。改子图代码又可能影响原来那个父图的行为,于是你陷入连锁修改。
LangGraph 官方文档推荐的做法是:子图的 State 应该只包含子图内部逻辑需要的字段,通过显式映射函数与父图交互1。这个建议不是教条,而是被大量生产实践验证过的经验。
自定义映射函数的工程模式
当简单的字段名交集不够用时,LangGraph 允许你通过 state_schema 和自定义映射函数来精细控制状态流转。
一个典型的场景是字段名不一致:父图里叫 retrieved_documents,子图里叫 context。你需要在子图节点注册时指定映射:
from langgraph.graph import add_node
def map_parent_to_child(parent_state: ParentState) -> ChildState:
return {
"query": parent_state["query"],
"docs": parent_state["retrieved_documents"],
}
def map_child_to_parent(child_state: ChildState, parent_state: ParentState) -> dict:
return {
"confidence": child_state["score"],
}
parent_graph.add_node(
"retrieval_subgraph",
compiled_child,
state_in=map_parent_to_child,
state_out=map_child_to_parent,
)
state_in 负责从父图状态构造子图初始状态,state_out 负责从子图最终状态提取需要回传给父图的字段。这两个函数给了你完全的控制权,但也意味着你需要为每一对映射关系写明确的代码。
这里有一个容易忽略的细节:state_out 的第二个参数是 parent_state,也就是子图执行前的父图状态快照。
这个设计允许你做"增量更新"——只回传子图修改过的字段,而不是覆盖整个父图状态。
如果你不传 state_out,LangGraph 会尝试按字段名自动合并,但自动合并在字段名冲突时的行为可能不符合预期,所以工程上建议总是显式写 state_out。
失败隔离与错误传播:子图挂了,父图怎么办
子图内部重试 vs 父图级重试
这是面试追问里出现频率极高的一道题:"子图执行到一半抛异常了,是子图自己重试,还是让父图来处理?"
答案取决于异常的类型和子图的语义边界。
如果异常是瞬时的、可恢复的——比如调用外部 API 超时、数据库连接池满——那么重试逻辑应该放在子图内部。
因为子图对外暴露的是"完成检索"这个语义,至于内部重试了几次、换了哪个 endpoint,这是子图的实现细节,父图不应该知道也不应该关心。
LangGraph 里你可以通过在子图节点上加 retry 配置来实现这一点。
如果异常是语义层面的、不可自动恢复的——比如检索结果为空、评分低于阈值——那么子图应该通过状态(而不是异常)把这个信息传递给父图,由父图决定下一步走哪条边。
比如子图在 ChildState 里设置 status = "no_results",父图的条件边读到这个状态后路由到"降级回答"节点。
用异常来控制业务流程是反模式,在 Subgraph 嵌套里尤其危险。因为子图的异常如果不被捕获,会直接冒泡到父图的执行引擎,导致整张父图崩溃。
你辛辛苦苦做的嵌套隔离,被一个未捕获的 KeyError 全部打穿。
一个 KeyError 打穿三层嵌套
错误状态的上浮与降级策略
当子图确实遇到了无法内部处理的错误时,正确的做法是通过状态通道把错误信息"上浮"到父图,而不是抛异常。
具体模式是:在子图的 State 里预留一个 error 字段(或者 status 字段),子图内部的 try-except 捕获异常后把错误信息写进这个字段,然后正常结束子图执行。
父图拿到子图回传的状态后,在条件边里检查这个字段,决定走正常流程还是降级流程。
class ChildState(TypedDict):
query: str
docs: list[str]
error: str | None
def retrieval_node(state: ChildState):
try:
docs = call_external_api(state["query"])
return {"docs": docs, "error": None}
except Exception as e:
return {"docs": [], "error": str(e)}
父图侧:
def route_after_retrieval(parent_state: ParentState):
if parent_state.get("retrieval_error"):
return "fallback_generator"
return "main_generator"
parent_graph.add_conditional_edges(
"retrieval_subgraph",
route_after_retrieval,
{"fallback_generator": "fallback_generator", "main_generator": "main_generator"},
)
这个模式的好处是:父图的执行引擎永远不会因为子图的错误而崩溃,所有异常都被转化成了状态分支。代价是你需要多写一些映射和路由代码,但这个代价在生产环境里是完全值得的。
降级策略本身也是一个可以展开聊的话题。常见的降级路径包括:返回缓存结果、切换到更简单的模型、直接告诉用户"当前无法处理"、或者把任务转入人工队列。
具体选哪条路径,取决于业务场景的容忍度,但"通过状态上浮错误、通过条件边路由降级"这个架构模式是通用的。
多层嵌套与子图间通信
跨层状态传递的性能代价
当嵌套层数从两层变成三层甚至更多时,状态传递的代价会从"可以忽略"变成"需要认真对待"。
每一层嵌套都意味着一次状态序列化/反序列化、一次字段映射函数的执行、一次子图编译实例的调度。
如果你的 State 里包含大体积字段——比如检索结果里的文档全文、base64 编码的图片——每一层嵌套都在复制这些数据。三层嵌套下来,同一份文档全文可能在内存里被复制了三次。
LangGraph 的状态传递默认是值语义(不是引用语义),这是有意为之的设计:值语义保证了子图内部修改不会意外影响父图状态,是隔离性的基础。但值语义的代价就是复制开销。
在实际项目里,控制这个开销的常见手段有三个。第一,子图的 State 里只传文档 ID 或引用,不传全文,全文在子图内部按需加载。
第二,控制嵌套层数,超过三层的嵌套几乎总是可以通过重新设计状态边界来扁平化。
第三,对于确实需要传递大体积数据的场景,考虑用外部存储(比如 Redis)做中转,State 里只传存储的 key。
子图间直接通信的禁止与变通
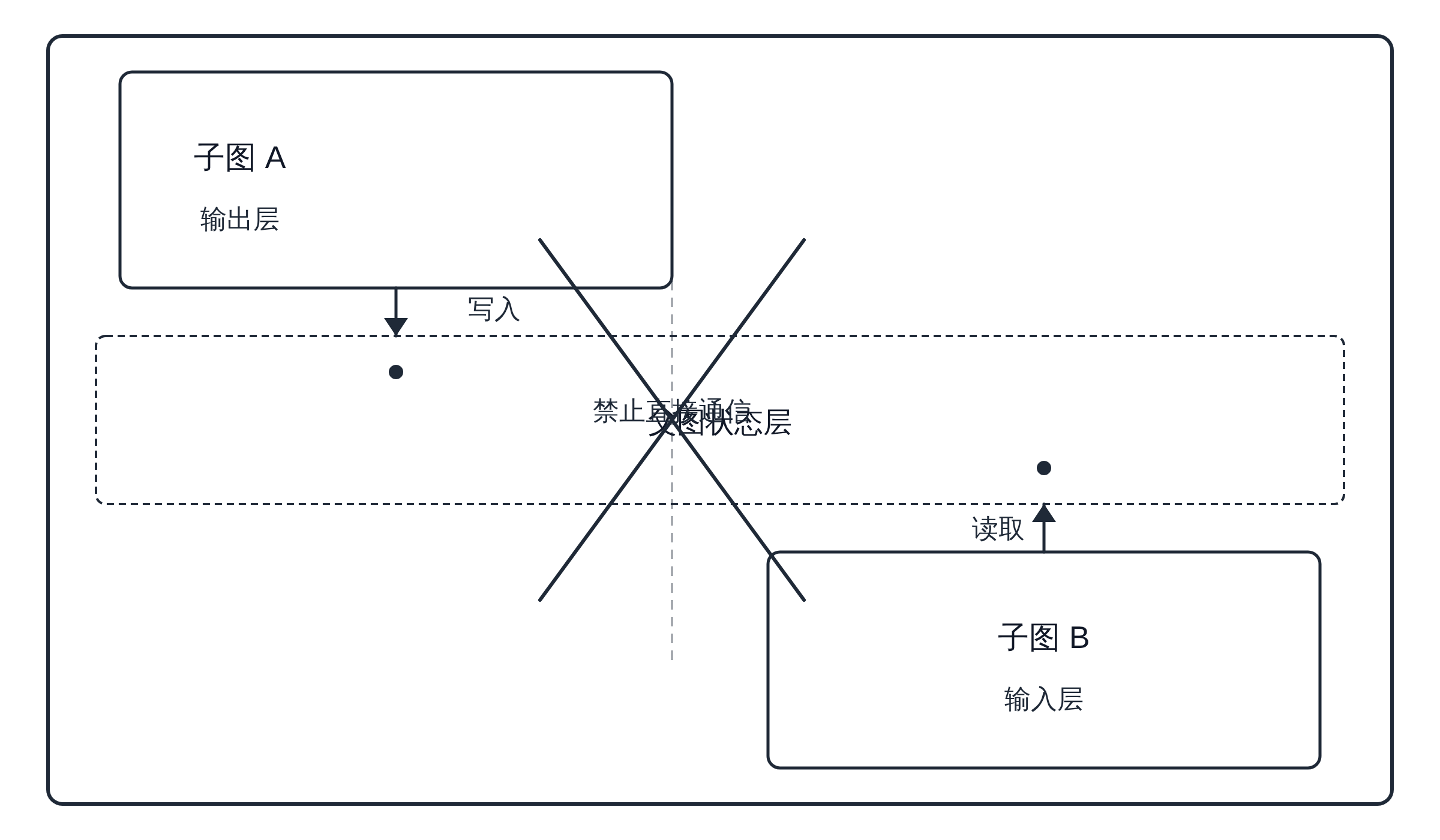
LangGraph 的 Subgraph 模型里有一个严格的约束:子图之间不能直接通信。子图 A 不能直接调用子图 B 的某个节点,也不能直接读写子图 B 的内部状态。
所有子图间的数据流动都必须经过父图的中转。
这个约束不是技术限制,而是架构原则。
如果允许子图间直接通信,你就重新回到了"全局耦合"的状态——子图 A 的修改可能影响子图 B 的行为,而你在子图 B 的代码里完全看不到这个依赖。
这和微服务架构里"服务间不能直接访问对方数据库"是同一个道理。
但实际业务里确实存在"子图 A 的输出需要影响子图 B 的行为"的需求。
变通方案是通过父图状态做显式中转:子图 A 把需要传递的数据写回父图状态,父图通过条件边决定是否执行子图 B,子图 B 从父图状态中读取子图 A 的输出。
正文图解 1
这个模式的代价是父图会变得"胖"——它需要定义所有子图间共享的字段,并且维护子图输出的映射逻辑。当子图数量增多时,父图的状态定义和映射函数会变得复杂。
这时候你需要重新审视:这些子图是否应该放在同一张父图里?是否应该把某些子图合并?或者是否应该引入更高层的编排层?
嵌套不是免费的。每多一层,你就多一份状态映射的维护成本。好的架构不是"能嵌多少层嵌多少层",而是"用最少的层数解决当前的问题"。
可观测性:嵌套图怎么调试
嵌套图在开发阶段最让人头疼的问题不是"跑不通",而是"跑通了但不知道里面发生了什么"。
单层图的调试已经够麻烦了——你至少还能在 LangGraph Studio 里看到每个节点的输入输出。
一旦套上两层甚至三层子图,调试体验会断崖式下降,除非你在设计阶段就提前埋好可观测性基础设施。
子图级别的 Trace 与 Span 设计
可观测性在嵌套图里的核心问题是:如何让一次父图执行产生一条完整的 Trace,同时在这条 Trace 里清晰地表达子图的边界。
LangGraph 底层集成了 LangSmith 的 tracing 能力。
当父图调用一个编译后的子图节点时,LangSmith 会自动为这次子图执行创建一个子 Span,嵌套在父图的主 Span 下面1。
这意味着你在 LangSmith 的 Trace 视图里能看到一棵树:根节点是父图执行,下面挂着各个子图执行的 Span,每个子图 Span 下面再挂着子图内部各节点的 Span。
这个自动嵌套的 Trace 结构是开箱即用的,不需要你额外写代码。但"能看到"和"能快速定位问题"之间还有很大距离。
实际调试中,你需要关注三个层面的信息。第一层是执行顺序:父图的哪个节点触发了哪个子图,子图内部节点按什么顺序执行,有没有出现意外的循环或跳转。
第二层是状态变化:子图接收到什么初始状态,每个节点修改了哪些字段,最终回传给父图什么状态。
这一层在默认 Trace 里能看到,但当 State 字段很多时,信息密度会非常高,你需要学会用 LangSmith 的过滤功能只看关键字段。
第三层是耗时分布:子图整体花了多长时间,内部哪个节点是瓶颈。这一层对于性能调优尤其关键——你可能会发现某个子图 80% 的时间花在了状态映射的序列化上,而不是实际的 LLM 调用。

Trace 树展开到第五层,人已经麻了
除了 LangSmith 的自动 Trace,你还可以在子图节点内部手动打 log 或 print。但在生产环境里,手动日志和结构化 Trace 是两套体系,混用会让排查变得混乱。
工程上的建议是:开发阶段用 LangSmith Trace 做主要调试手段,生产环境用结构化日志(配合你公司的日志平台)做持续监控,不要两套混着来。
状态快照与断点调试
LangGraph 的 checkpoint 机制在嵌套图里有一个容易被忽略的特性:每一层图都有自己的 checkpoint 作用域。
父图在执行到子图节点之前会做一次 checkpoint,子图内部也会按自己的 checkpoint 配置做状态持久化。
这两套 checkpoint 是独立的——父图的 checkpoint 记录的是"子图节点即将执行"这个状态,子图的 checkpoint 记录的是子图内部各节点的执行进度。
这个设计在断点续传场景下非常有用。
假设你的父图执行到某个子图时因为外部原因中断了,恢复时你可以选择从父图层面重试整个子图节点,也可以选择进入子图内部,从子图的上一个 checkpoint 点继续执行。
LangGraph Studio 支持这种"钻入子图"的调试方式:你在 Trace 视图里点击某个子图 Span,就能看到子图内部的状态快照和执行历史,并且可以从子图的任意 checkpoint 点恢复执行。
但这里有一个坑:如果你在子图里用了 MemorySaver 做持久化,而父图用的是另一个 MemorySaver 实例,那么两边的 checkpoint 数据是隔离的。
你在父图层面做"回退到上一个状态"操作时,子图的 checkpoint 不会自动回退。
这意味着你可能会遇到一种诡异的情况:父图回退了,但子图内部的状态已经推进了,再次执行子图时拿到的是"未来"的子图状态。
解决方案是让父图和所有子图共享同一个 checkpoint 存储(同一个 MemorySaver 实例),或者至少确保 checkpoint 的 key 空间不冲突。
LangGraph 官方推荐前者2,因为在共享存储下,框架可以自动维护父子图 checkpoint 的一致性。
与多 Agent 协作的边界:什么时候用 Subgraph,什么时候用多 Agent
这是 LangGraph 学习曲线里最容易混淆的一个概念边界。很多候选人把"子图嵌套"和"多 Agent 协作"当成同一件事,或者认为子图嵌套就是多 Agent 的实现方式。
这两者有交集,但不是等价关系。
编排模型对比:图嵌套 vs 消息传递 vs 共享状态
要讲清楚这个边界,需要先拆解三种不同的编排模型。
第一种是图嵌套,也就是 Subgraph。它的核心特征是:有一个明确的父图作为顶层编排者,子图是父图的可调用单元。子图之间不能直接通信,所有协调逻辑集中在父图。
这种模型适合"有一个清晰的顶层流程,子任务是这个流程中的步骤"的场景。
第二种是消息传递,典型代表是 AutoGen 那种模式。多个 Agent 之间通过发送消息来协调,没有一个中心化的编排者。每个 Agent 自己决定什么时候说话、对谁说话。
这种模型适合"没有固定流程、需要 Agent 之间动态协商"的场景。
第三种是共享状态,多个 Agent 读写同一份状态,通过状态的变更来触发各自的逻辑。
LangGraph 本身的状态机制就支持这种模式——多个节点(可以理解为多个 Agent 的执行函数)读写同一个 State,通过 reducer 来处理并发写入冲突。
用一个比喻来区分:图嵌套像公司的层级架构,老板(父图)给部门(子图)派任务,部门之间不能直接对接,必须通过老板;消息传递像微信群聊,每个人自己决定说什么、回复谁;
共享状态像共享文档协作,大家都在改同一份文件,通过版本合并解决冲突。

正文图解 2
在面试里,如果被问到"什么时候用 Subgraph、什么时候用多 Agent",一个高质量的回答应该从三个维度展开。
维度一:流程确定性。如果顶层流程是确定的(先检索、再评分、再生成),用 Subgraph。如果流程是动态的(Agent 之间讨论后决定下一步),用消息传递。
维度二:状态隔离需求。如果子任务之间需要强隔离(检索子图不应该知道生成子图的内部状态),用 Subgraph。如果多个 Agent 需要频繁共享中间结果,用共享状态模型。
维度三:团队协作模式。如果不同子图由不同团队开发维护,Subgraph 的接口边界更清晰。如果是一个紧密协作的小团队,共享状态的沟通成本更低。
还有一个容易忽略的混合模式:父图用 Subgraph 做顶层编排,某个子图内部用共享状态让多个 Agent 协作。LangGraph 的灵活性允许你在不同层级使用不同的编排模型,不需要全局统一。
但混合模式的代价是认知复杂度上升——你需要在每一层都清楚"这一层用的是哪种编排模型",否则调试时会完全迷失。对于面试场景,建议先把三种纯模型讲清楚,再提混合模式作为加分项。
面试高频追问与易错点
这一节直接按追问方向组织,每个方向给出一到两个高频追问和对应的回答框架。这些追问不是编的,是从公开面经和岗位 JD 的能力要求里反推出来的3。
状态映射相关的典型追问
追问一:"子图的 State 和父图的 State 字段名不一样,怎么处理?"
回答框架:先说 state_in 和 state_out 映射函数的基本用法,再说为什么推荐总是显式写映射而不是依赖自动合并,最后补一个"字段名不一致是常态,因为子图应该有自己的领域语言"的判断。
追问二:"子图修改了父图传进来的字段,父图会受到影响吗?"
回答框架:先说 LangGraph 的值语义设计——子图拿到的是父图状态的副本,修改不会影响父图。再说这是隔离性的基础,但代价是复制开销。
最后补"如果子图需要回传修改,必须通过 state_out 显式指定"。
追问三:"子图的 State 里用了 Annotated[list, operator.add] 这种 reducer,和父图的 reducer 冲突了怎么办?"
回答框架:这是一个陷阱题。正确答案是:子图的 reducer 只在子图内部生效,父图的 reducer 只在父图内部生效。
state_out 负责把子图的最终状态"翻译"成父图能理解的格式,这个翻译过程用的是父图的 reducer 语义。子图内部的 reducer 怎么定义,父图不关心。
reducer 作用域这道题,挂了不少人
失败隔离相关的典型追问
追问一:"子图内部某个节点超时了,但子图的其他节点还能继续执行吗?"
回答框架:取决于超时是在哪个层面被触发的。如果是节点级别的超时配置(比如 LLM 调用设了 30 秒超时),那个节点会抛异常,异常是否被捕获决定了子图是否继续。
如果是子图级别的超时(整个子图执行不能超过某个时间),LangGraph 会在超时后中断子图执行,子图不会"正常结束",而是进入错误状态。
追问二:"子图重试了三次都失败了,怎么避免父图也跟着重试三次?"
回答框架:子图内部的重试对父图不可见——父图只看到"子图节点执行完了,返回了某个状态"。所以问题本身的前提需要修正。
真正需要避免的是:子图每次失败都通过异常冒泡到父图,导致父图的条件边反复路由回子图节点。
解决方案是子图内部用 try-except 把错误转成状态字段,父图根据状态字段做一次性降级,而不是循环重试。
追问三:"怎么设计一个'部分成功'的子图——比如检索了 5 个源,3 个成功 2 个失败?"
回答框架:这是一个很好的工程追问。
正确做法是在子图的 State 里用结构化的结果字段,比如 results: list[RetrievalResult],每个 RetrievalResult 包含 source、success、content、error 四个字段。
子图内部对每个源单独 try-except,成功的写 content,失败的写 error。父图拿到这个列表后,可以根据成功数量决定走主流程还是降级流程。
性能与可观测性相关的典型追问
追问一:"三层嵌套的图,状态里有一份 100KB 的文档,性能会有问题吗?"
回答框架:会有问题,但不是"不能接受"的问题。值语义下每一层嵌套都会复制这份文档,三层就是三份副本,总共 300KB 的额外内存开销。
对于单次执行来说可以接受,但如果这个子图在高并发场景下被频繁调用(比如每秒 100 次),内存压力就会变得显著。解决方案是 State 里只传文档 ID,全文在子图内部按需加载。
追问二:"怎么判断一个子图是不是拆得太细了?"
回答框架:三个信号。第一,子图的 State 只有一两个字段,映射函数的代码量超过了子图内部逻辑的代码量。第二,子图内部没有循环或分支,就是一个简单的函数调用被包装成了图。
第三,你在调试时发现大部分时间花在了"理解子图之间的状态流转"而不是"理解业务逻辑"。出现任何一个信号,都说明这层嵌套可能是不必要的。
追问三:"LangGraph Studio 能看到子图内部的状态吗?"
回答框架:能,但需要你"钻进去"。默认视图只显示父图层面的状态变化,你需要点击子图节点进入子图的 Trace 视图才能看到子图内部的状态。
这个交互逻辑本身就是一个面试考点——它说明 LangGraph 的可观测性是分层设计的,不是扁平化的。
项目里怎么说:没有做过完整 Subgraph 嵌套怎么补
这是八股文里最务实的一节。大部分在校生和初级工程师没有在生产环境里做过完整的 Subgraph 嵌套,但这不意味着你在面试里只能说"我没做过"。
关键在于:你能不能把官方示例吃透,然后用项目语境重新讲出来。
从官方示例到项目话术的转化
LangGraph 官方仓库里有一个经典的 multi-agent 示例,里面用了 Subgraph 来封装不同 Agent 的执行逻辑4。
这个示例的结构是:父图负责任务分发,子图 A 负责研究,子图 B 负责写作。
直接背这个示例的结构在面试里是不够的,因为面试官听完会追问:"你这个项目和官方示例有什么区别?"
转化策略是:保留示例的架构骨架,替换业务场景和具体实现细节。
比如你可以说:"我的课程项目是一个智能代码审查系统,父图负责接收 PR 事件和分发任务,检索子图负责从代码库和历史 PR 里找相关上下文,审查子图负责调用 LLM 做代码审查,汇总子图负责把多个审查结果合并成一份报告。
"
这个话术和官方示例的架构完全一致(父图分发 + 多个子图执行),但业务场景换成了代码审查,面试官听起来就不会觉得你在背示例。
接下来你需要准备好被追问的细节。面试官大概率会问:"你的检索子图和审查子图之间怎么传递数据?"
这时候你就要把状态映射的具体设计讲出来:"检索子图的 State 里只有 pr_diff、related_files 和 context 三个字段,审查子图的 State 里有 pr_diff、context 和 review_result。
父图在调用审查子图时,通过 state_in 把检索子图回传的 context 映射过去。"
再追问:"如果检索子图没找到相关上下文怎么办?"
"检索子图的 State 里有一个 status 字段,如果没找到相关文件就设为 no_context。
父图的条件边检查这个字段,如果 no_context 就直接走一个轻量级审查路径,不调用复杂的 RAG 流程。"
你看,整个回答链就是:架构骨架来自官方示例,业务细节来自你自己的项目,追问应对来自你对状态映射和失败隔离的理解。三层叠加,面试官不会觉得你在背书。
简历描述与面试展开的节奏控制
简历上怎么写 Subgraph 相关经验,也是一个有技巧的事。
不要写"使用 LangGraph 的 Subgraph 功能实现了多 Agent 协作"。
这句话太泛,面试官看了等于没看,而且"多 Agent 协作"这个说法在 Subgraph 语境下本身就不精确。
更好的写法是:"基于 LangGraph 设计了分层图架构,将检索、评分、生成拆分为独立子图,通过状态映射函数实现子图间数据隔离与传递,支持单子图级别的独立测试与失败降级。"
这句话里有四个可追问的点:分层图架构、状态映射函数、独立测试、失败降级。面试官随便挑一个你都能展开聊,而且每个展开都落在工程细节上,不是空话。
面试展开时的节奏控制也很重要。不要等面试官问才说,也不要一口气把所有细节倒出来。
一个推荐的节奏是:先用两三句话讲清楚整体架构(父图做什么、有几个子图、子图之间怎么协调),然后停一下,看面试官的反应。
如果面试官点头或说"继续",你再挑一个你觉得最有把握的细节展开——比如状态映射的具体设计。
如果面试官直接追问某个点,说明他对那个方向感兴趣,你就顺着他的问题深入,不要强行拉回你准备好的叙事线。
最后提醒一点:如果你真的没做过 Subgraph 嵌套,不要硬编项目经验。
你可以说"我在学习 LangGraph 时重点研究了 Subgraph 的状态映射和失败隔离机制,下面我从设计层面讲一下我的理解",然后用官方示例加上你自己的分析来回答。
诚实加上深度分析,远比编造项目经验更有说服力。面试官见过太多"简历写了但一问就露馅"的候选人,一个能坦诚说"没做过但研究过"并且真的能讲清楚设计取舍的人,反而更稀缺。
术语边界与延伸阅读
几个在讨论 Subgraph 时容易混淆的术语,在这里做一次显式界定。
Subgraph vs Subgraph Node:Subgraph 是一张完整的图(有节点、有边、有状态定义),Subgraph Node 是这张图被编译后注册到父图里的那个"节点"。
从父图的视角看,它就是一个节点;从子图的视角看,它是一张图。这两个词指代的是同一个东西在不同上下文里的称呼。
State Schema vs State Instance:State Schema 是你用 TypedDict 定义的类型(描述"状态长什么样"),State Instance 是运行时的具体状态值(描述"状态当前是什么")。
映射函数操作的是 State Instance,不是 Schema。
Checkpoint vs Snapshot:Checkpoint 是 LangGraph 的持久化机制,会在每个节点执行后自动保存状态。
Snapshot 是某个时刻的状态快照,可以理解为 Checkpoint 的一个视图。
LangGraph 的 get_state() API 返回的就是一个 State Snapshot。
Subgraph vs Multi-Agent:Subgraph 是一种图结构组织方式,Multi-Agent 是一种系统架构模式。
Subgraph 可以用来实现 Multi-Agent(每个子图封装一个 Agent),但 Subgraph 也可以用来封装非 Agent 的逻辑(比如一个纯检索流程)。
不要把这两个概念等价。
延伸阅读建议按优先级排列。第一优先级是 LangGraph 官方文档中关于 Subgraph 的章节4,这是最权威的一手源,面试前至少通读两遍。
第二优先级是 LangGraph 官方仓库里的 multi-agent 示例代码4,建议自己跑一遍,在 LangGraph Studio 里观察 Trace 结构。
第三优先级是 LangSmith 的 tracing 文档1,帮助你理解嵌套图的可观测性设计。
对于想进一步理解"什么时候用 Subgraph、什么时候用其他编排模型"的读者,可以对比阅读 Google ADK 的 Agent Engine 文档和 AWS Strands Agent SDK 的设计理念5。
这三家云厂商在 Agent 编排上的不同选择,本身就是一道很好的系统设计面试题。
参考文献
延伸入口
- 原文归档:tobemagic.github.io/ai-magician…
- 公众号:计算机魔术师

