

面试凑 KPI,候选人成了背景板
今天鸭鸭在脉脉看到一条帖子,评论区炸开了:
发完帖没多久,评论区来了一条神评,直接把整个帖子送上热榜:
“面试前 5 分钟没有给你推送广告就不错了。”
底下还有人接梗:“下次就按你小子这么弄”、“来一个竞价吧”。
另一条高赞跟帖也很扎心:
“我面了一个多小时,HR 直接失踪了。”
“哈哈哈,KPI 了。”
“咋们也去干 HR 吧,这 KPI 太好拿了。”
……
鸭鸭第一眼看完这个帖子,心里只有两个字:熟悉。
不是百度熟悉,是这种“流程走完一遍,但你能感觉到对面根本没打算要你”的面试体验,大家这两年真的太熟了。
“简历过了”——但 HR 不联系你;
“约面试了”——但 JD 要你自己去 Boss 看;
“面试开始了”——但 15 分钟就结束,一半时间还是你在自说自话。
这套组合拳打下来,候选人哪还是来面试的,分明是来陪跑、盖章、凑流程的。
这种面试背后就一个原因——“招聘 KPI”。
很多大厂到了季度末、半年末,HR 和业务线都有“面试人数”“简历转化”“开放岗位”等一堆 KPI 要凑。岗位其实可能早就内定好了,或者 HC 压根就是“挂着看看”,但流程上又必须走一遍面试。于是——
- HR 为了凑数,只要简历不差就叫你来聊;
- 面试官被拉来临时救场,压根不熟你的简历,直接翻项目随便问两句;
- 聊不到 15 分钟就开始“你还有什么想问的?”——因为他比你还想早点结束。
这不是面试,这是打卡。
那句“面试前 5 分钟没给你推送广告就不错了”,戳穿了两件事:
- 百度的基因里确实流着广告的血——候选人也好,搜索结果也好,先是流量,再是价值;
- 候选人被当成“流量”在处理——你不是候选人,你是一次面试记录里的一个 UV。
鸭鸭知道,看到这里肯定有人说:“你是不是太阴谋论了,人家可能就是真的觉得你不合适,快速结束对你对他都是解脱。”
这话也对,但不全对。
真不合适,完全可以简历阶段就拒了,不用把候选人骗来当 KPI。
候选人请假、改简历、做准备、甚至跨城面试,付出的是真实成本;你这边点一下“已面试”,走一个数据。这账怎么算都不公平。
那作为候选人,我们能做什么?鸭鸭给三条实在的建议:
- 约面前先确认基本信息:JD、面试官岗位、预计时长——问不清楚的岗位,直接打个问号;
- 远程优先:能线上就别现场,把时间和体力成本降到最低;
- 把每次被“凑数”的面试当练兵:顺便逼对方多讲几句业务细节,你反而多攒了行业信息。
最重要的是——别把一次草率的面试,当成对自己能力的全盘否定。很多时候真的不是你不行,而是对方根本不是在招人。
把精力省下来,留给真正重视你的面试官。
大家有没有遇到过这种“15 分钟打卡式面试”?评论区聊聊~
……
今天和大家分享一篇 后端场景题 面试题。
【分布式锁一般都怎样实现? 】
回答重点
分布式锁用于多个应用实例之间互斥访问共享资源,单机锁搞不定跨进程的问题,必须依赖外部组件。
业界主流方案是 Redis。
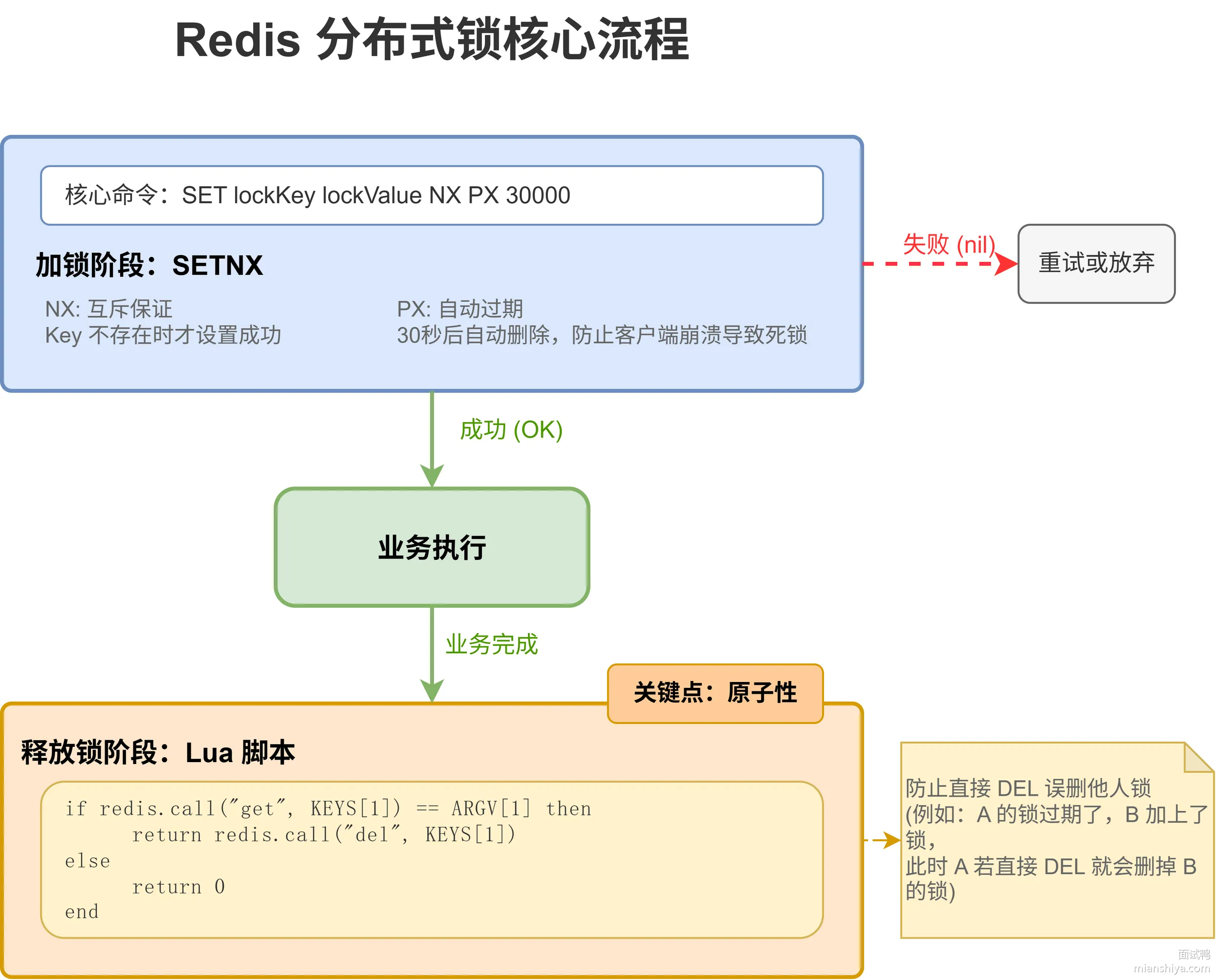
Redis 实现分布式锁的核心是 SETNX 命令,SET if Not eXists,只有 key 不存在时才能设置成功。加锁成功返回 OK,失败返回 nil。
- 加锁:
SET lockKey lockValue NX PX 30000,NX 保证互斥,PX 30000 设置 30 秒过期时间,防止客户端挂了锁永远不释放。 - 释放锁:必须用 Lua 脚本保证原子性,先判断 value 是不是自己的,是才删除。不能直接 DEL,否则可能把别人的锁删掉。
代码示例:
public class RedisDistributedLock {
private Jedis jedis;
private String lockKey;
private String lockValue;
private int lockTimeout;
public RedisDistributedLock(Jedis jedis, String lockKey, int lockTimeout) {
this.jedis = jedis;
this.lockKey = lockKey;
this.lockTimeout = lockTimeout;
// UUID 保证 lockValue 唯一,防止误删别人的锁
this.lockValue = UUID.randomUUID().toString();
}
public boolean acquireLock() {
String result = jedis.set(lockKey, lockValue, "NX", "PX", lockTimeout);
return "OK".equals(result);
}
public boolean releaseLock() {
// Lua 脚本保证 check-and-delete 原子性
String script =
"if redis.call('get', KEYS[1]) == ARGV[1] then " +
"return redis.call('del', KEYS[1]) " +
"else return 0 end";
Object result = jedis.eval(script,
Collections.singletonList(lockKey),
Collections.singletonList(lockValue));
return Long.valueOf(1).equals(result);
}
}
除此之外,也可以用 ZooKeeper 实现分布式锁。
主要用的是它的临时有序节点。
多个客户端在同一个目录下创建临时有序节点,序号最小的那个拿到锁。临时节点保证客户端挂了自动释放,有序节点保证公平排队。
扩展知识
Redis 分布式锁的坑
锁过期了业务还没执行完
锁设了 30 秒超时,但业务逻辑跑了 40 秒,锁提前释放了,别的客户端进来了,数据就乱了。
解决方案是看门狗机制,后台起个定时线程,每隔 10 秒检查一下锁还在不在,在就续期到 30 秒。
Redisson 开箱即用,只要你获取锁时不指定超时时间,它就自动开启看门狗:
RLock lock = redisson.getLock("myLock");
lock.lock(); // 不指定超时,自动续期
try {
// 业务逻辑
} finally {
lock.unlock();
}
注意:如果你手动指定了超时时间 lock.lock(30, TimeUnit.SECONDS),看门狗就不会启动,锁到期就释放。
主从切换导致锁丢失
Redis 主从架构下,客户端在 master 加锁成功,但锁数据还没同步到 slave,master 挂了,slave 升级为 master,新 master 上压根没这把锁,别的客户端就能再次加锁成功,两个客户端同时持有锁。
这就是 Redis 作者提出 RedLock 的原因。
RedLock 的思路是多个独立的 Redis 节点(没有哨兵和 slave 了)一起投票,超过半数加锁成功才算成功。
比如现在有 5 个 Redis 节点(官方推荐至少 5 个),客户端获取当前时间 T1,然后依次利用 SETNX 对 5 个 Redis 节点加锁,如果成功 3 个及以上(大多数),再次获取当前时间 T2,如果 T2-T1 小于锁的超时时间,则加锁成功,反之则失败。
如果加锁失败则向全部节点调用释放锁的操作。
RedLock 的问题:
- 成本高,得部署 5 个独立 Redis 实例,不能是主从
- 时钟漂移问题,某个节点系统时间突然往前跳,锁提前过期
- GC 问题,客户端拿到锁后发生长时间 Full GC,醒来时锁早过期了,别的客户端已经拿到锁在干活了
Martin Kleppmann 写过一篇文章专门怼 RedLock,核心观点是分布式系统不能依赖时间假设,RedLock 的安全性证明不成立。
Redis 作者 antirez 也回应了,两边吵得挺热闹。实际工程中,大多数场景用单节点 Redis + Redisson 就够了。
ZooKeeper 分布式锁细节
ZooKeeper 用临时有序节点实现分布式锁:
- 客户端在 /locks 目录下创建临时有序节点,比如 /locks/lock-0000000001
- 获取 /locks 下所有子节点,判断自己是不是序号最小的
- 如果是最小的,拿到锁;如果不是,监听比自己小一号的节点
- 等前一个节点被删除,自己就变成最小的,拿到锁
这种设计避免了惊群效应,每个客户端只监听前一个节点,不会所有客户端同时被唤醒。
临时节点的特性:客户端和 ZooKeeper 之间维护一个 session,session 超时节点自动删除。
就算客户端进程挂了,锁也会自动释放,不用担心死锁。
Curator 提供了 InterProcessMutex 封装好了这些细节:
InterProcessMutex lock = new InterProcessMutex(client, "/locks/myLock");
try {
if (lock.acquire(10, TimeUnit.SECONDS)) {
// 拿到锁,执行业务
}
} finally {
lock.release();
}
Redis vs ZooKeeper 怎么选?
| 维度 | Redis | ZooKeeper |
|---|---|---|
| 性能 | 高,10 万+ QPS | 一般,写操作走 leader |
| 可靠性 | 主从异步复制,可能丢锁 | ZAB 协议,强一致 |
| 实现复杂度 | Redisson 封装完善 | Curator 封装完善 |
| 运维成本 | 低,本身就用 Redis | 需要额外部署 ZK 集群 |
| 适用场景 | 允许极端情况下重复加锁 | 对一致性要求极高 |
实际选型:如果系统本身已经用了 ZooKeeper 做注册中心,用 ZK 做分布式锁成本不大。如果只有 Redis,且业务能容忍极端情况下的锁失效,就用 Redis + Redisson。
数据库实现分布式锁
其实数据库也能实现分布式锁,用 SELECT ... FOR UPDATE 或者 unique key 插入竞争。
但性能太差,几百 QPS 就撑不住了,一般不推荐。除非你的场景并发量很低,又不想引入额外组件。
篇幅有限,更多 后端场景 相关面试题可以进入面试鸭(mianshiya.com)进行查阅。
