1.导入库函数
%matplotlib inline
import random
import torch
from d2l import torch as d2l
2.生成线性回归的模拟数据
用y=Xw+b计算出理论模拟结果,再加上微小误差使其更接近真实结果
将得到的结果阵列重置成1列,行数不变,用于后续计算
def synthetic_data(w,b,num_examples):
X = torch.normal(0,1,(num_examples,len(w)))
标准差是1,num_examples是样本数量(行数),len(w)是权重的数量(列数)
y = torch.matmul(X,w)+b
y += torch.normal(0,0.01,y.shape)
return X,y.reshape((-1,1))
true_w = torch.tensor([2,-3.4])
true_b = 4.2
features,labels = synthetic_data(true_w,true_b,1000)
3.数据抽样检查
取出第一行的数据,检查数据集的形状是否正确
print('features:',features[0],'\nlabel:',labels[0])
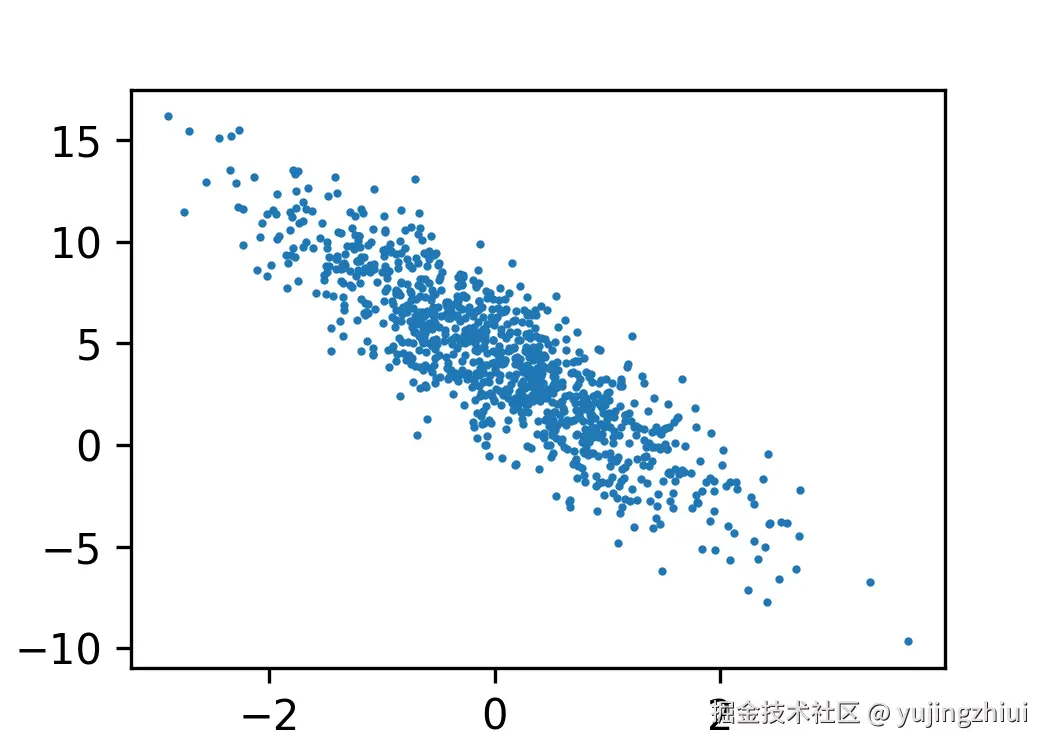
4.绘制散点图
构建X2和y的关系
d2l.set_figsize()
d2l.plt.scatter(features[:,1].detach().numpy(),labels.detach().numpy(),1)
5.查看散点图
根据图形可知,x2和y具有负相关性