

用Claude Code或Cursor写代码,每次问AI一个问题,它都要重新读一遍你的代码库。小项目还好,几百个文件,几千行代码,token消耗还能接受。但如果是大项目呢?几千个文件,几万行代码,每次对话都要烧掉几毛甚至几块钱的token费用。
更关键的是,大部分token都浪费了。AI读了很多根本无关的代码——你改的是用户登录模块,它却读了支付系统、数据分析模块、前端组件库...这些代码跟你的改动毫无关系,但AI不知道,只能全读一遍。
今天介绍的 code-review-graph,就是专门来解决这个问题的。
GitHub:
震惊的数字:token减少49倍
code-review-graph的slogan很直接:"Stop burning tokens. Start reviewing smarter."(停止浪费token,开始智能审查)。
它做了什么?给AI编程工具构建了一个本地知识图谱,让AI只读真正相关的代码。
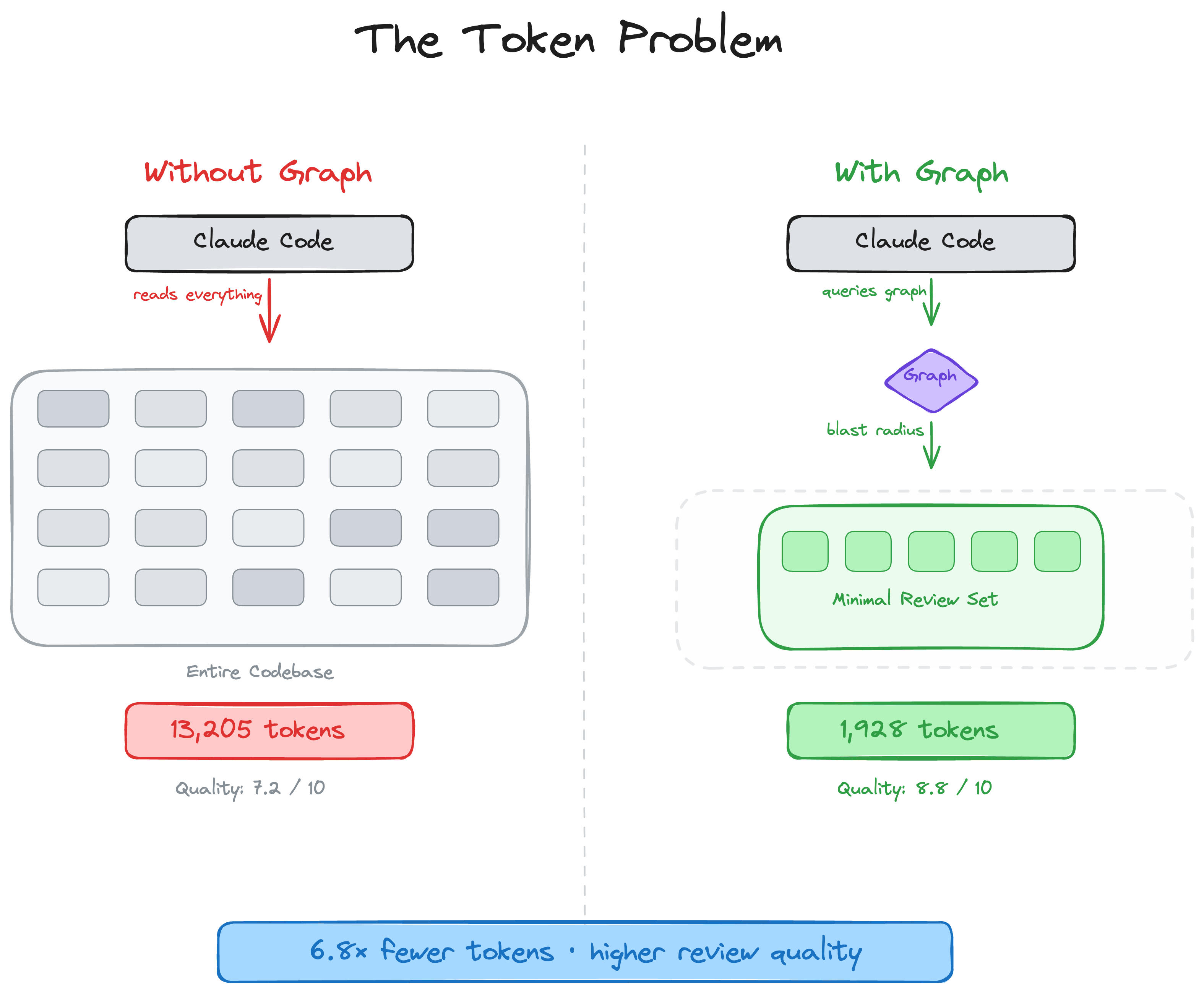
效果有多夸张?官方给出的数据:
- 代码审查场景:token消耗减少 6.8倍
- 日常编码任务:token消耗最高减少 49倍
49倍是什么概念?原来要花1块钱的对话,现在只要2分钱。
它怎么做到的
code-review-graph的核心思路是**"爆炸半径分析"**(Blast-radius analysis)。
这个术语来自物理学。炸弹爆炸时,冲击波会向四周扩散,影响的范围就是"爆炸半径"。代码改动也一样——你改了一个函数,哪些代码会受影响?调用这个函数的代码、依赖这个函数的测试、继承这个类的子类...这些就是改动的"爆炸半径"。
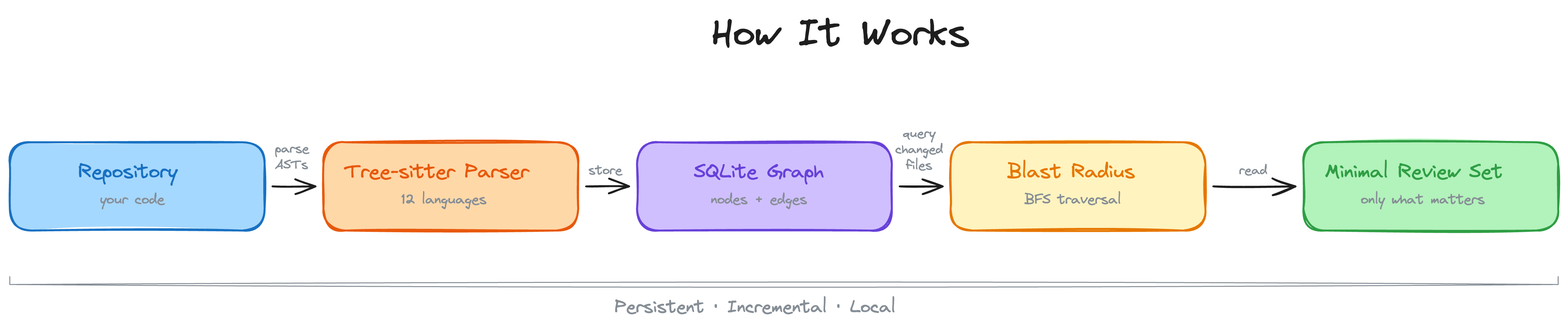
code-review-graph的工作流程分为三步:
第一步:解析代码结构
它用 Tree-sitter(一个高性能的代码解析器)扫描你的代码库,把代码转换成抽象语法树(AST)。然后提取关键信息:有哪些函数、类、模块,它们之间怎么调用、怎么继承、怎么导入。
最终构建成一个知识图谱——节点是代码实体(函数、类、变量),边是它们之间的关系(调用、继承、依赖)。
第二步:追踪变更影响
当你修改了一个文件,code-review-graph不会傻乎乎地重新解析整个代码库。它会:
- 计算变更文件的SHA-256哈希,快速定位哪些文件真的变了
- 在知识图谱中追踪这个变更的"爆炸半径"——找出所有调用者、依赖者、相关测试
- 只更新受影响的部分,其他保持不变
这个过程有多快?官方测试,一个2900个文件的项目,重新索引只需要不到2秒。
第三步:给AI精准上下文
code-review-graph通过 MCP(Model Context Protocol) 跟AI编程工具通信。当AI需要理解代码变更时,code-review-graph不会给它整个代码库,而是只提供"爆炸半径"内的相关文件。
举个例子:你改了一个validateUser函数。传统方式下,AI会读整个项目。有了code-review-graph,AI只读到:
validateUser函数本身- 调用
validateUser的3个函数 - 依赖这个功能的2个测试文件
- 相关的类型定义和接口
总共可能只有5-10个文件,而不是几百个。
大单体仓库的救星
如果你在大公司工作,可能经历过"大单体仓库"(Monorepo)的痛苦。
一个仓库里塞了几十个模块、几百个服务、几万个文件。用AI编程工具时,每次对话都要等半天,因为AI在读那些根本无关的代码。
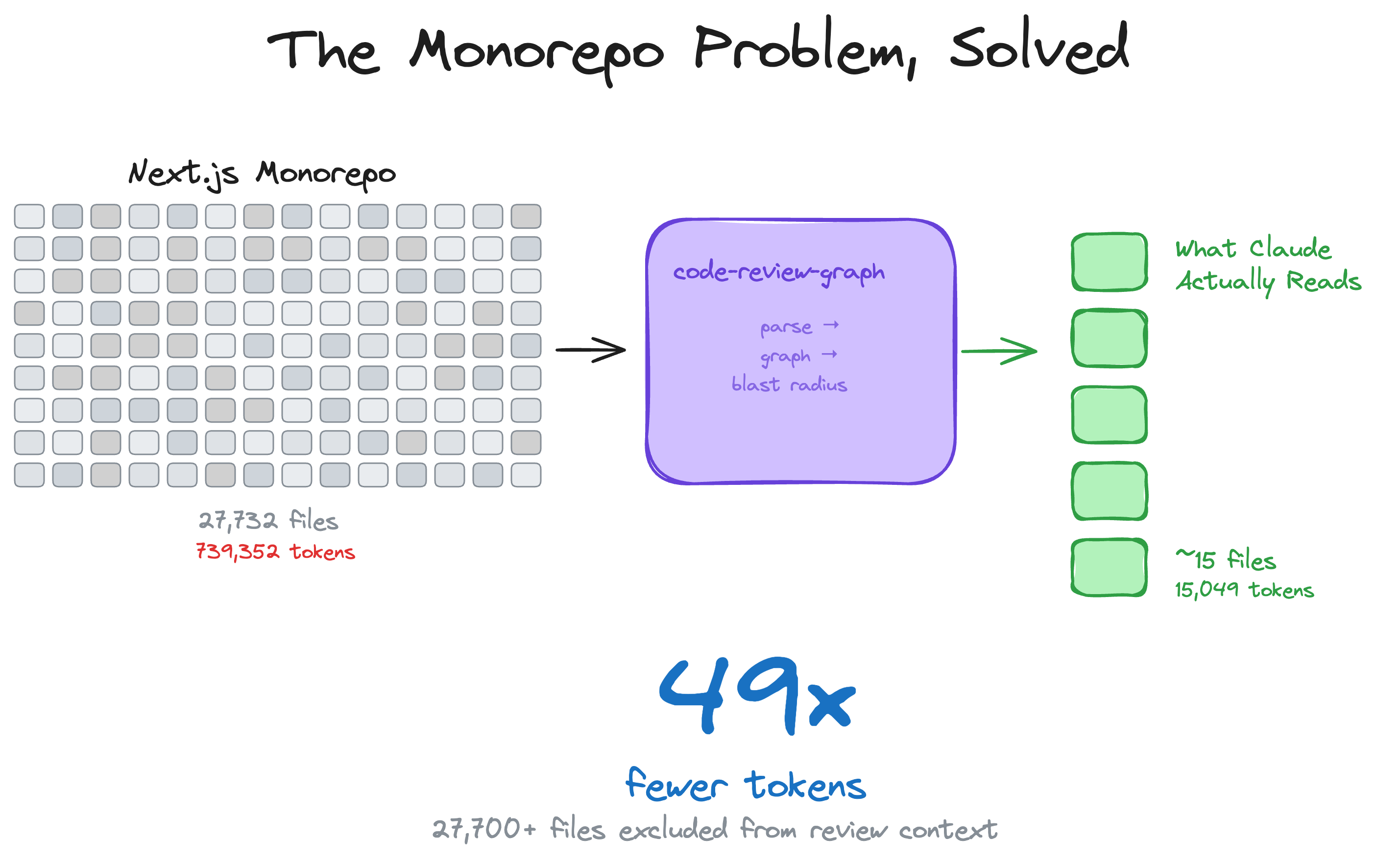
code-review-graph官方测试了一个极端案例:
- 仓库里有 27,700+ 个文件
- 一次代码审查,code-review-graph排除了27,700+个无关文件
- 最终AI只读了 约15个相关文件
这种场景下,token节省的效果是最明显的。原来可能要读几十万token,现在只要几千token。
支持哪些工具
code-review-graph目前支持主流的AI编程工具:
- Claude Code —— Anthropic官方的命令行工具
- Codex —— OpenAI的编程Agent
- Cursor —— 流行的AI代码编辑器
- Kiro —— 另一个AI编程助手
安装时会自动检测你装了哪些工具,然后自动配置MCP。一条命令搞定:
code-review-graph install
如果你只想配置特定工具,也可以指定:
code-review-graph install --platform claude-code
code-review-graph install --platform cursor
支持23种编程语言
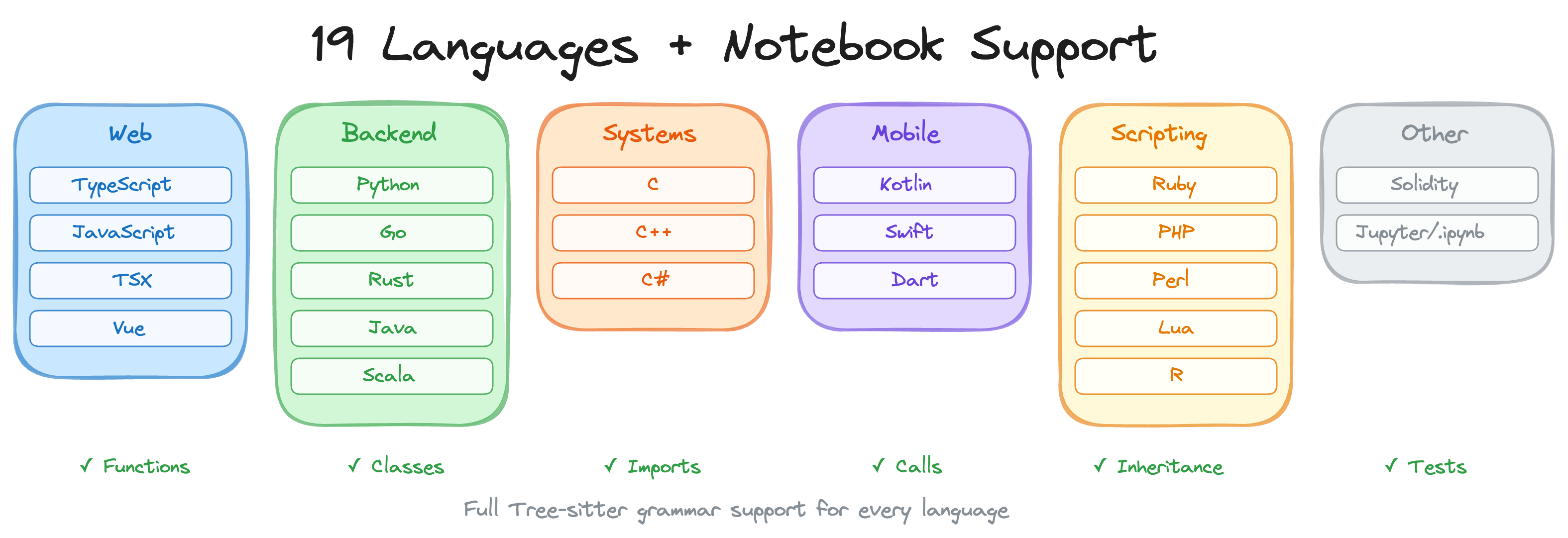
code-review-graph用Tree-sitter解析代码,所以支持所有Tree-sitter有语法支持的语言:
主流语言全覆盖:Python、JavaScript、TypeScript、Java、Go、Rust、C、C++、C#、Ruby、PHP、Swift、Kotlin...
小众语言也支持:Zig、PowerShell、Julia、Svelte...
还有特殊格式:Jupyter Notebook(.ipynb)、Perl XS文件
基本上,只要你写的代码有Tree-sitter语法支持,code-review-graph就能解析。
真实性能数据
官方在6个真实的开源项目上做了测试,数据很有说服力:
Token效率对比:
| 项目 | 原始方式 | 使用图谱 | 减少倍数 |
|---|---|---|---|
| Flask | 44,751 token | 4,252 token | 9.1x |
| Gin | 21,972 token | 1,153 token | 16.4x |
| FastAPI | 4,944 token | 614 token | 8.1x |
| Next.js | 9,882 token | 1,249 token | 8.0x |
| HTTPX | 12,044 token | 1,728 token | 6.9x |
平均减少 8.2倍。
注意Express的数据比较特殊(0.7x,反而增加了)。原因是Express是小项目,单文件变更时,图谱的元数据开销超过了收益。但这种情况很少见,一旦涉及多文件变更,图谱的优势就体现出来了。
影响准确性:
- 100%召回率 —— 从不遗漏实际受影响的文件
- 平均F1分数0.54 —— 宁可多预测也不遗漏
这个设计哲学是保守的:宁愿让AI多读几个无关文件,也绝不漏掉一个相关文件。
快速开始
安装很简单:
pip install code-review-graph
# 或者
pipx install code-review-graph
然后配置:
code-review-graph install # 自动检测并配置所有支持的平台
最后构建知识图谱:
code-review-graph build # 解析你的代码库
初始构建需要一点时间(500文件的项目约10秒),之后每次文件编辑或git提交都会自动增量更新。
装完后重启你的AI编程工具,然后问它:
Build the code review graph for this project
AI就会基于知识图谱给你精准的代码分析了。
适合谁用
大项目开发者 —— 代码库超过1000个文件,每次AI对话都要等半天。code-review-graph能显著减少等待时间和token费用。
高频使用AI编程工具的人 —— 每天用Claude Code或Cursor写代码,token费用累积起来很可观。用code-review-graph能省下一大笔钱。
Monorepo维护者 —— 一个仓库里塞了多个项目、多个服务。code-review-graph能精准定位相关代码,避免AI被无关代码干扰。
代码审查者 —— 需要理解代码变更的影响范围。code-review-graph的"爆炸半径分析"能帮你快速定位需要关注的文件。
GitHub:
写在最后
code-review-graph解决的是一个很实际的问题:AI编程工具的token浪费。
现在的AI编程工具都太"贪婪"了——每次任务都要读整个代码库,不管相关不相关。这在小型项目上没问题,但在大型项目上就是灾难。
code-review-graph的思路很聪明:让AI像人类开发者一样工作。人类看代码变更时,不会读整个项目,而是追踪依赖关系,只看相关的部分。code-review-graph用知识图谱实现了这种"智能筛选"。
而且它是纯本地运行的。你的代码不会被上传到任何云端,知识图谱存在你本地,MCP通信也是本地的。对于注重代码安全的公司来说,这点很重要。
如果你也在用AI编程工具,也在为token费用和等待时间发愁,code-review-graph值得一试。
关注
如果这篇文章对你有帮助,欢迎点赞、收藏、转发。我会持续分享实用的AI编程工具和效率优化技巧,关注我,一起用AI更高效地写代码。
