

Agent 强化学习的“模板式崩溃”:高熵值也骗人,信噪比才是关键解药

在使用强化学习(RL)训练大型语言模型(LLM)Agent 时,研究者们普遍面临一个棘手的难题:训练过程极其不稳定,模型的推理质量时常在没有明确预警的情况下出现衰退。一个常见且隐蔽的失败模式是,Agent 看似在针对不同问题进行有条理的思考和推理,但实际上只是在复述一套与具体输入无关的、预先“背好”的模板化答案。
ArXiv URL:arxiv.org/abs/2604.06…
来自帝国理工学院、微软、斯坦福大学、西北大学等多家顶尖机构的研究者在 RAGEN-2 这篇论文中,将这种现象命名为“模板式崩溃”(Template Collapse)。 他们指出,这种崩溃之所以危险,是因为它能轻易骗过当前最主流的稳定性监控指标——熵(Entropy)。高熵值只能保证模型对同一个问题的回答具有多样性,却无法判断模型是否在不同问题之间做出了有效区分。
为了解决这个诊断盲区,论文提出了一个全新的信息论视角。研究者认为,衡量推理质量需要两个维度:一是熵所代表的“输入内多样性”,二是互信息(Mutual Information, MI)所代表的“跨输入区分度”。 他们发现,互信息与最终任务的成功率高度相关,是诊断模板式崩溃的“照妖镜”。
更进一步,论文通过一个“信噪比”(Signal-to-Noise Ratio, SNR)机制,深刻揭示了模板式崩溃的根源。当 RL 训练中来自任务奖励的有效“信号”过弱时,来自正则化项的“噪声”就会主导梯度更新,从而抹去模型针对不同输入进行特异性推理的能力。 基于这一洞见,他们提出了一种名为“信噪比感知过滤”(SNR-Aware Filtering)的轻量级训练策略,通过在每次迭代中优先选择“高信号”的训练数据,成功地抑制了模板式崩溃,并在规划、数学、代码生成等多种任务上显著提升了 Agent 的性能。
“模板式崩溃”:一个被熵指标掩盖的隐蔽角落
在 Agentic RL 的训练框架下,模型通过与环境的反复交互来学习如何完成任务。在每一步,Agent 都会生成一段推理(,即思考过程)和一个可执行动作(),并根据最终结果获得奖励。为了确保训练的稳定性,研究者通常会监控两个核心指标:奖励(Reward)和熵(Entropy)。前者衡量任务结果的优劣,后者则被用来评估推理过程的多样性。
然而,RAGEN-2 的作者们敏锐地指出,稳定的高熵值并不能保证高质量的推理。为了从理论上厘清这个问题,他们引入了信息论中的经典恒等式:
这里, 代表输入, 代表模型的推理过程。
-
是推理的总熵,代表推理的整体多样性。
-
是条件熵,衡量在给定某个输入 的情况下,推理 的不确定性或多样性。这正是传统方法中使用的熵指标。
-
是互信息,衡量推理 中包含了多少关于输入 的信息。它代表了推理对输入的依赖性或区分度。
基于这两个维度,研究者定义了四种不同的推理状态,如下图所示:
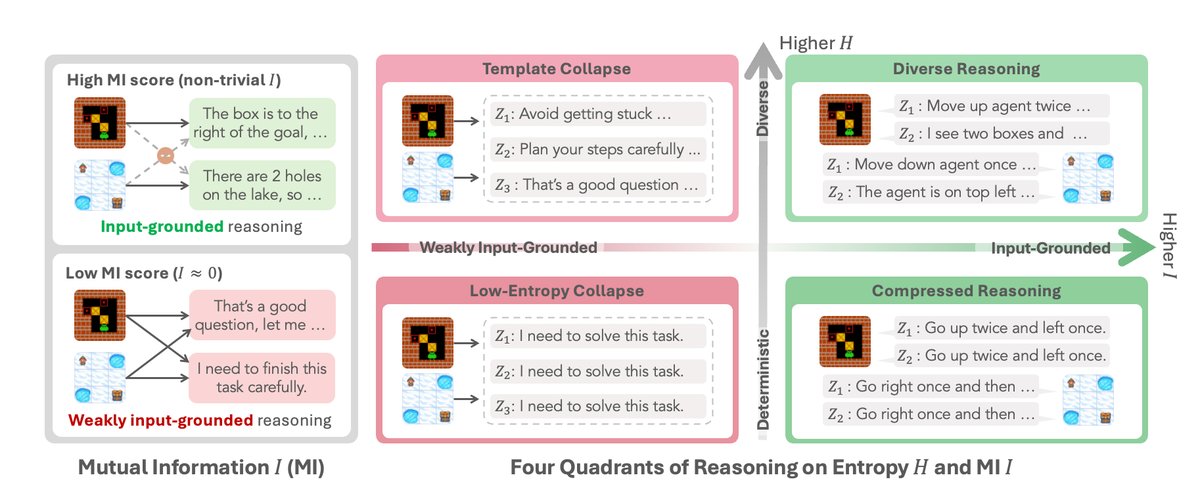
图 1:基于条件熵 和互信息 定义的四种推理状态。左上角的“模板式崩溃”是本文关注的核心问题,它具有高熵值(看似多样),但互信息很低(与输入无关)。
-
多样化推理 (Diverse Reasoning):高条件熵、高互信息。这是最理想的状态,Agent 的思考既多样又紧密贴合具体问题。
-
模板式崩溃 (Template Collapse):高条件熵、低互信息。这是最危险的“认知陷阱”。Agent 的回答看似丰富多变,但实际上与输入无关,只是在不同模板间切换。 传统熵指标无法发现这种问题。
-
压缩式推理 (Compressed Reasoning):低条件熵、高互信息。Agent 的思考忠于输入,但过于确定和单一,缺乏探索性。
-
低熵崩溃 (Low-Entropy Collapse):低条件熵、低互信息。这是一种完全退化的状态,Agent 的输出既单一又与输入无关。
实验数据明确显示,互信息 与任务的最终表现呈现出极强的正相关性,而条件熵 的相关性则弱得多,有时甚至为负。这证明了互信息是比熵更可靠的推理质量诊断指标。
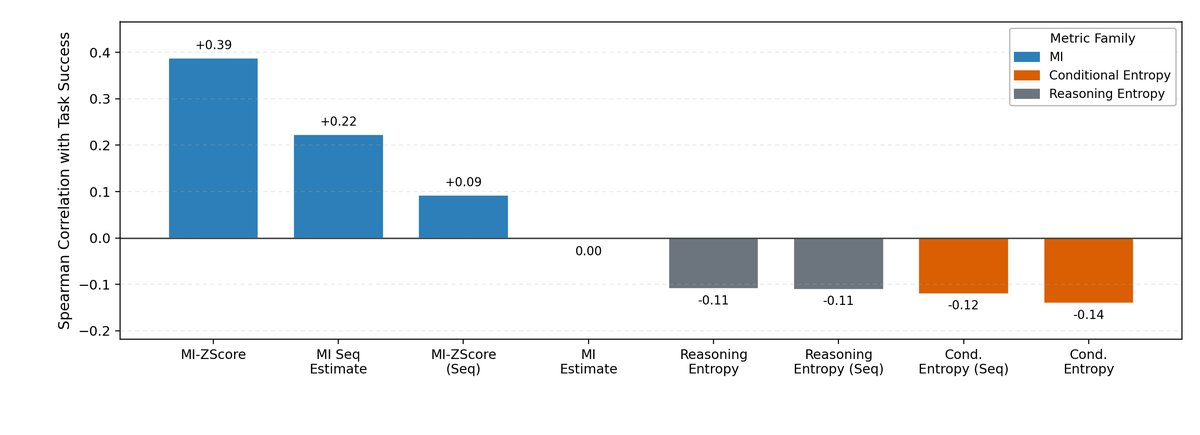
图 2:在多个任务中,互信息代理指标(MI Proxies)与任务成功率的相关性(蓝色和绿色曲线)远高于条件熵(橙色曲线)。这表明互信息是诊断推理质量更有效的指标。
为了在实际训练中监控互信息,研究者设计了一套无需外部模型的互信息代理(MI Proxy)计算方法。其核心思想是在一个批次(batch)内,将每个输入(prompt)所生成的推理轨迹,与其他所有输入的推理轨迹进行交叉评分。如果模型是健康的,那么一个推理轨迹在其“亲生”输入下的得分应该是最高的。反之,如果模型陷入模板式崩溃,那么其推理轨迹在所有输入下的得分将趋于一致。
崩溃的根源:RL 梯度更新中的“信噪比”失衡
诊断了问题之后,下一个关键是解释其成因。RAGEN-2 论文最具洞察力的贡献之一,便是提出了一个简洁而深刻的信噪比(SNR)机制来解释模板式崩溃的发生。
在策略梯度(Policy Gradient)更新中,总的梯度 可以被概念性地分解为两部分:
-
是任务梯度,它来自于奖励信号,是驱动模型学习解决特定任务的“信号”。这部分梯度的大小与“输入内奖励方差” 正相关。也就是说,对于同一个输入,如果模型生成的不同推理轨迹能获得差异巨大的奖励(即高方差),那么任务信号就强,模型就能学到清晰的反馈。
-
是正则化梯度,它来自于 KL 散度或熵正则化等项。这些项的目的是防止模型偏离初始策略太远或变得过于确定,但它们是输入无关的,对所有推理轨迹施加统一的约束,可以看作是“噪声”。
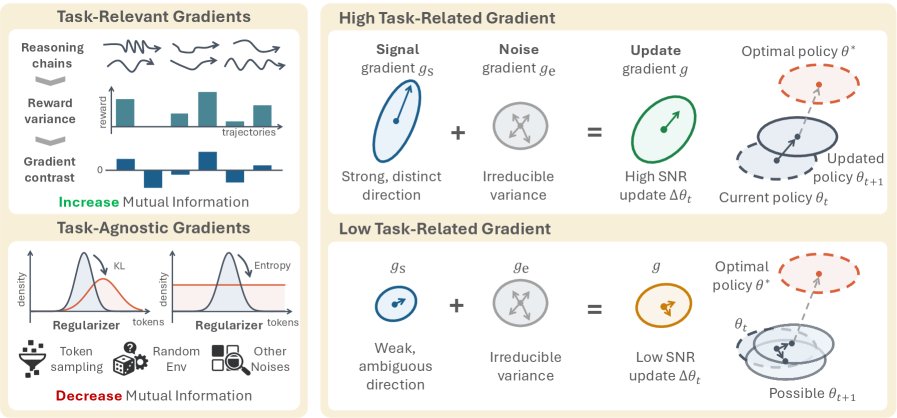
图 3:RL 更新的信噪比(SNR)视角。当奖励方差高时(右侧上),任务信号强,模型能有效学习。当奖励方差低时(右侧下),正则化噪声主导更新,导致模型产生与输入无关的模板化推理。
模板式崩溃的机制由此变得清晰:当模型对某个输入的所有尝试都得到相似的奖励时(即低奖励方差),任务信号 会变得非常微弱。此时,恒定存在的正则化“噪声” 就会在梯度更新中占据主导地位。 模型为了最小化由正则化项带来的损失,会倾向于生成那些最能满足正则化约束(例如,高熵、流畅)但忽略了具体任务需求的内容。日积月累,模型便学会了这种“投机取巧”的模板化行为,最终导致互信息 的持续下降。
信噪比感知过滤(SNR-Aware Filtering):一剂对症下药的简单良方
基于信噪比的病因分析,论文提出了一种直接且优雅的解决方案:信噪比感知过滤(SNR-Aware Filtering)。 其逻辑非常直观:既然低信噪比的更新是有害的,那么我们就应该在训练中主动筛选并优先使用高信噪比的数据。
该方法的工作流程如下:
-
生成轨迹:在每个训练迭代开始时,像往常一样为一批次(batch)的输入(prompts)生成多个推理轨迹。
-
计算信噪比代理:对于每个输入,计算其对应的一组轨迹所获得的奖励方差 。这个奖励方差被用作信噪比(SNR)的一个轻量级代理指标。
-
筛选高信号数据:根据计算出的奖励方差对所有输入进行排序,只保留方差最高的 top-p 百分比的输入及其对应的轨迹。
-
执行更新:仅在筛选出的“高信号”数据子集上执行强化学习的参数更新。

图 4:SNR-Aware Filtering 工作流程示意图。通过计算奖励方差来筛选出高信号的训练样本,从而避免在充满噪声的低信号数据上进行更新。
这种方法的巧妙之处在于它的简单性和高效性。它不需要引入任何额外的模型或复杂的计算,仅仅利用了标准 RL 训练流程中已经存在的奖励信息,就能直接干预梯度更新的质量,从根源上抑制模板式崩溃的发生。
实验验证:新诊断与新疗法是否有效?
为了验证其理论和方法的有效性,研究团队在涵盖规划(Sokoban)、数学推理(MetaMathQA)、网页导航(WebShop)和代码生成(DeepCoder)等七个多样化的环境中进行了大量实验。
结果表明,SNR-Aware Filtering 取得了持续且显著的性能提升。与不进行任何过滤的基线相比,采用该方法能有效提升模型的互信息水平和最终的任务成功率。
尤为关键的一组实验是,研究者对比了三种不同的训练干预手段对模型状态的影响:
-
调整熵正则化强度
-
调整 KL 散度约束强度
-
应用 SNR-Aware Filtering
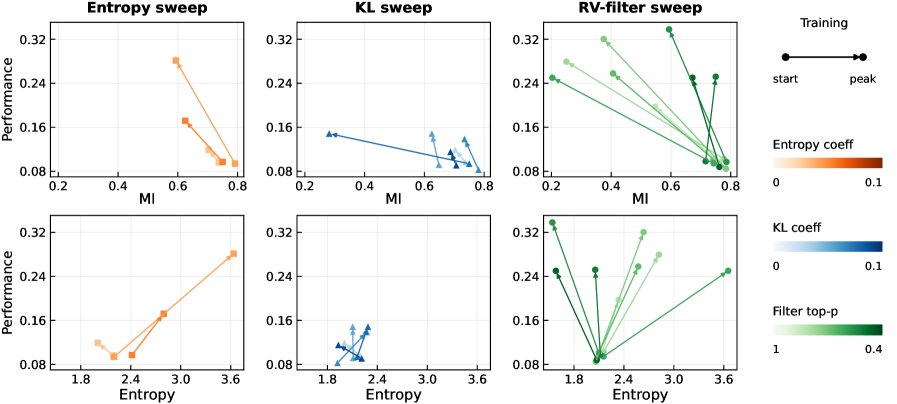
图 5:三种干预措施对训练动态的影响。每条箭头代表一次训练过程,箭头从早期指向后期。颜色深浅代表干预强度。可以看出,只有 SNR-Aware Filtering(绿色)能稳定地将模型推向高互信息和高性能的区域。
如上图所示,调整熵或 KL 正则化(蓝色和橙色轨迹)虽然能改变模型的条件熵,但并不能可靠地提升互信息,甚至可能导致性能下降。相比之下,SNR-Aware Filtering(绿色轨迹)则清晰地将模型从低互信息的区域,稳定地推向高互信息、高任务性能的理想状态。这一结果强有力地证明了,SNR 机制准确地抓住了问题的本质,而 SNR-Aware Filtering 则是对症下药的有效疗法。
结论与启示
RAGEN-2 这项工作为理解和解决 Agentic RL 中的推理不稳定性问题提供了一个全新的、富有洞察力的框架。它揭示了“模板式崩溃”这一被传统熵指标所掩盖的隐蔽失败模式,并创造性地引入互信息作为更可靠的诊断工具。 更重要的是,论文提出的信噪比(SNR)机制,深刻解释了崩溃的内在机理,并催生了 SNR-Aware Filtering 这一简单、高效且普适的解决方案。
这项研究的意义不止于提出一个新方法,它更像是在为未来更可靠、更稳定的 Agent 训练 estabelece 了一个新的标准。它提醒我们,在追求模型能力的同时,必须深入理解其内部的动态和潜在的失效模式。通过从信噪比这一基础视角出发,我们或许能够设计出更多鲁棒的算法,让大型语言模型 Agent 在通往通用智能的道路上走得更稳、更远。
