

SpringBoot+XXL-Job 工单管理 SLA 双计时架构——响应/解决独立超时、轮询游标、负载最少算法、站内信预警一套打通
🌐 文档地址:ruoyioffice.com | 📦 源码1:gitcode.com/zhouzhongya… | 📦 源码2:gitcode.com/zhouzhongya… | 📦 源码3:github.com/yuqing2026/… | 💬 微信:17156169080(备注「RuoYi Office」)
做过工单系统的都知道一个真理:"状态机不难,SLA 和派单才难"。工单本身只是一张表,真正要命的是:为什么工单池里我刚看到的单,一秒钟后就被同事抢走了?轮询分配会不会在并发下派给同一个人?负载最少算法会不会让新入职的同事被"挤兑"?SLA 超时了没人发现怎么办?XXL-Job 重复执行会不会把同一张单的超时通知发 3 次?本文不讲业务,只讲 RuoYi Office 工单模块在工单池路由、SLA 双计时器、分配算法、XXL-Job 预警四个点上的工程实现细节,所有代码均可直接落地。
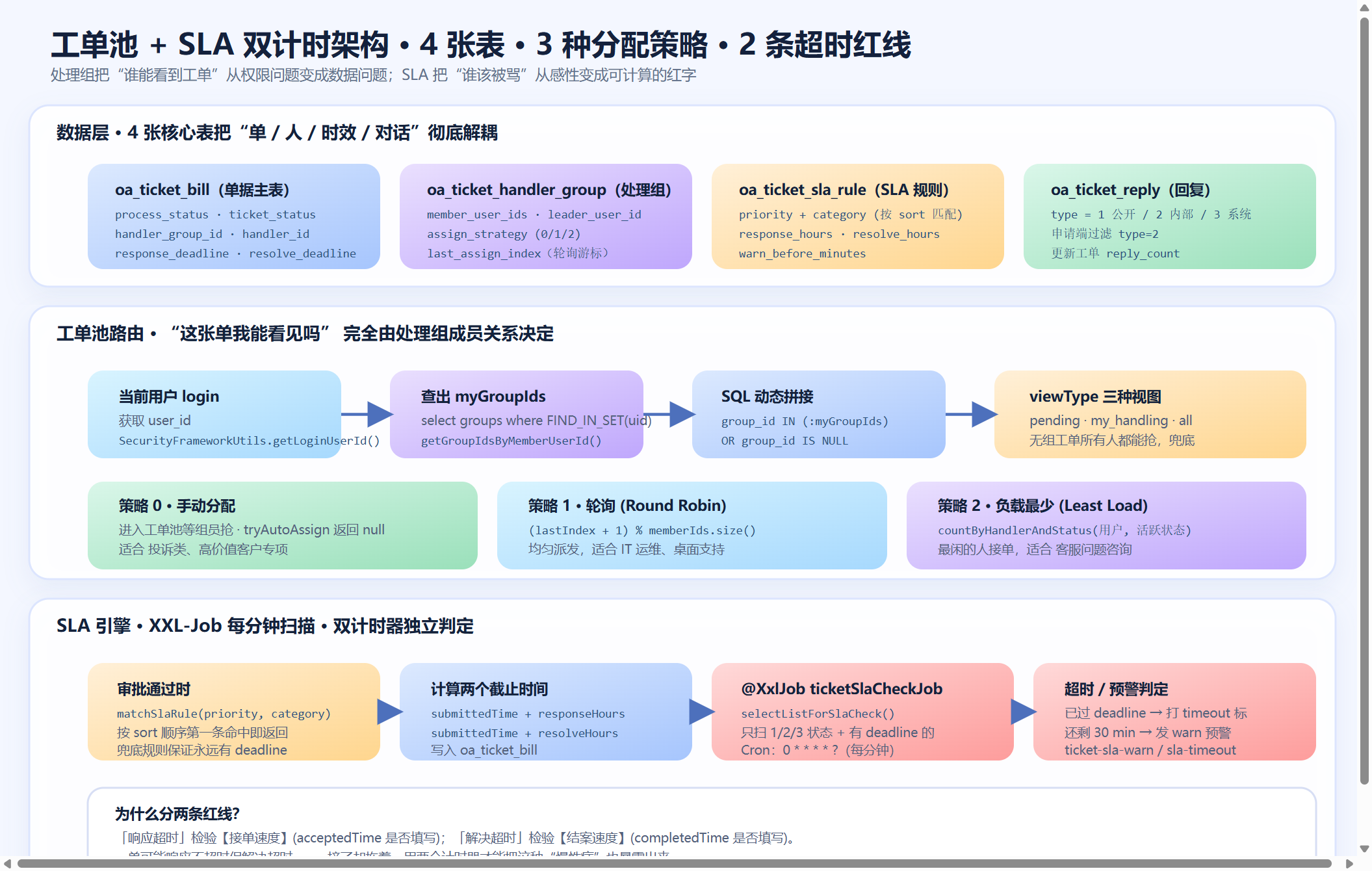
▲ 工单池 + SLA 双计时架构:数据层 4 张表解耦,工单池用 SQL 条件做路由(零中间件),XXL-Job 每分钟扫描 deadline 触发预警和超时标记,站内信模板化通知处理人和组长
引言:工单池和 SLA 到底难在哪?
难点 1:工单池是"动态权限"——员工 A 是 IT 运维组成员,今天加入投诉专项组了,他的"待接单"列表要立刻变多;员工 B 离职了,他之前接的工单要立刻被组内其他人看到。如果用传统的 RBAC 权限表(user_id × ticket_id),每次变更成员都得刷权限表。
难点 2:SLA 是"异步告警"——工单的 deadline 写在数据库里,但谁来"提醒"?每次列表查询时算?那列表卡成 PPT;开启个后台线程扫?那进程挂了 SLA 就瞎了。
难点 3:轮询的并发陷阱——两个工单同时审批通过,都要走轮询分配,last_assign_index 会被同时读取,可能两张单派给同一个人。
难点 4:负载最少的"抖动"——"当前哪个组员处理的单最少" 在高并发下会反复抖动:新单一来,负载最低的 A 被派单,但 B 刚好关单了负载更低,下一张又派给 B,派出去的瞬间 A 又完成了……。
难点 5:XXL-Job 可能重复执行——节点重启、时钟漂移、任务切片都可能让同一个超时通知被发两次。
RuoYi Office 的工单模块把这五个问题做得很干净:工单池只改 SQL、SLA 只用两个字段、轮询走事务、负载最少只看活跃单、XXL-Job 用标志位去重。下面一条条拆。
一、工单池:SQL 条件就是全部路由
1.1 需求回顾
工单池要同时满足 3 种视图:
| Tab | 我看到什么 |
|---|---|
| 待接单(pending) | 我所在组的、已审批通过的、待分配的工单 + 无组兜底工单 |
| 我处理的(my_handling) | handler_id = me 的工单 |
| 全部(all) | 我所在组的所有已审批通过工单 + 无组工单 |
1.2 成员关系如何存:逗号分隔 vs 关系表
很多人上来就想建 handler_group_member 关系表。但 RuoYi Office 用了更朴素的方案:
CREATE TABLE oa_ticket_handler_group (
member_user_ids VARCHAR(2000) DEFAULT NULL COMMENT '成员用户ID列表(逗号分隔)',
...
);
原因是:
- 处理组一般规模小(10-50 人),2000 字符够存 100+ ID
- 查询"我在哪些组"极其高频,关系表要再加一次 JOIN
- 成员变更时整体覆盖,事务语义更简单
1.3 查询"我在哪些组"
public List<Long> getGroupIdsByMemberUserId(Long userId) {
if (userId == null) return Collections.emptyList();
List<TicketHandlerGroupDO> allGroups = ticketHandlerGroupMapper
.selectList(new LambdaQueryWrapperX<TicketHandlerGroupDO>()
.eq(TicketHandlerGroupDO::getStatus, 0));
String uidStr = String.valueOf(userId);
return allGroups.stream()
.filter(g -> StringUtils.isNotBlank(g.getMemberUserIds()))
.filter(g -> Arrays.stream(g.getMemberUserIds().split(","))
.map(String::trim).anyMatch(uidStr::equals))
.map(TicketHandlerGroupDO::getId).toList();
}
在内存里 split + compare,比 SQL 的 FIND_IN_SET 更可读且能走缓存(处理组表整体变化不频繁,可用一级缓存兜住)。
1.4 工单池 SQL 的核心:一行 OR
default PageResult<TicketBillDO> selectPoolPage(TicketPoolPageReqVO reqVO) {
LambdaQueryWrapperX<TicketBillDO> wrapper = new LambdaQueryWrapperX<TicketBillDO>()
.eqIfPresent(TicketBillDO::getProcessStatus, reqVO.getProcessStatus())
.eqIfPresent(TicketBillDO::getTicketStatus, reqVO.getTicketStatus())
// ... 其他条件
// 处理组过滤:组内工单 OR 未指定处理组的工单
if (reqVO.getHandlerGroupIds() != null && !reqVO.getHandlerGroupIds().isEmpty()) {
if (Boolean.TRUE.equals(reqVO.getIncludeNoGroup())) {
wrapper.and(w -> w
.in(TicketBillDO::getHandlerGroupId, reqVO.getHandlerGroupIds())
.or()
.isNull(TicketBillDO::getHandlerGroupId));
} else {
wrapper.in(TicketBillDO::getHandlerGroupId, reqVO.getHandlerGroupIds());
}
}
return selectPage(reqVO, wrapper);
}
生成的 SQL 大致是:
SELECT * FROM oa_ticket_bill
WHERE process_status = 2
AND ticket_status = 1
AND (handler_group_id IN (88001, 88002) OR handler_group_id IS NULL)
ORDER BY id DESC LIMIT 20;
命中的索引是 idx_handler_group_id。零中间件、零关系表、零缓存依赖。
1.5 Service 层怎么拼 viewType
public PageResult<TicketBillDO> getTicketPoolPage(TicketPoolPageReqVO pageReqVO) {
Long currentUserId = SecurityFrameworkUtils.getLoginUserId();
String viewType = pageReqVO.getViewType();
List<Long> myGroupIds = ticketHandlerGroupService.getGroupIdsByMemberUserId(currentUserId);
if ("pending".equals(viewType)) {
pageReqVO.setTicketStatus(TicketStatusEnum.PENDING_ASSIGN.getStatus()); // 1
pageReqVO.setProcessStatus(BpmTaskStatusEnum.APPROVE.getStatus()); // 2
if (!myGroupIds.isEmpty()) {
pageReqVO.setHandlerGroupIds(myGroupIds);
pageReqVO.setIncludeNoGroup(true); // 兜底
}
} else if ("my_handling".equals(viewType) && currentUserId != null) {
pageReqVO.setHandlerId(currentUserId);
if (pageReqVO.getTicketStatus() == null) {
pageReqVO.setTicketStatuses(List.of(
TicketStatusEnum.PENDING_PROCESS.getStatus(),
TicketStatusEnum.PROCESSING.getStatus(),
TicketStatusEnum.COMPLETED.getStatus()));
}
} else { // all
pageReqVO.setProcessStatus(BpmTaskStatusEnum.APPROVE.getStatus());
if (!myGroupIds.isEmpty()) {
pageReqVO.setHandlerGroupIds(myGroupIds);
pageReqVO.setIncludeNoGroup(true);
}
}
return ticketBillMapper.selectPoolPage(pageReqVO);
}
viewType 不是权限,而是SQL 条件组合。整个路由层没有多一张表、没有多一个 Redis Key、没有多一个中间件。
二、三种分配策略:35 行代码搞定
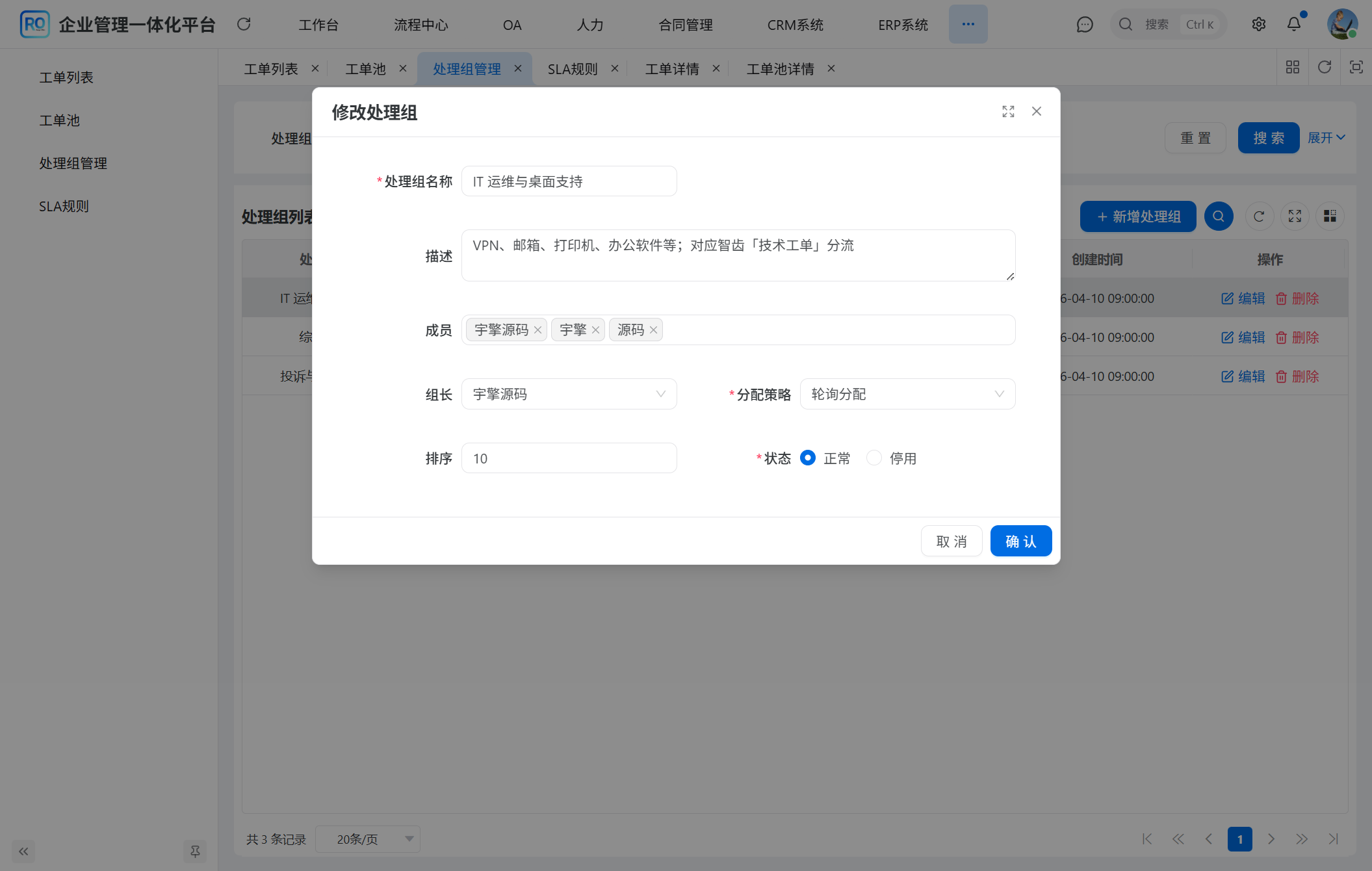
▲ 处理组编辑:分配策略下拉框 3 选项——手动 / 轮询 / 负载最少,对应 TicketAssignServiceImpl 的三种分支
2.1 入口:tryAutoAssign
public Long tryAutoAssign(TicketBillDO ticket, TicketHandlerGroupDO group) {
if (group == null || group.getAssignStrategy() == null || group.getAssignStrategy() == 0) {
return null; // 策略 0 手动 → 直接返回 null,落入工单池
}
if (StringUtils.isBlank(group.getMemberUserIds())) {
return null;
}
List<Long> memberIds = Arrays.stream(group.getMemberUserIds().split(","))
.map(String::trim).filter(StringUtils::isNotBlank)
.map(Long::parseLong).toList();
if (memberIds.isEmpty()) return null;
return switch (group.getAssignStrategy()) {
case 1 -> assignByRoundRobin(group, memberIds);
case 2 -> assignByLeastLoad(memberIds);
default -> null;
};
}
设计亮点:
- 策略 0 直接返回 null:不是"失败",是"故意的"——让工单进入工单池等抢单。
- 成员为空也返回 null:同样落入工单池,这就是前文提到的"主动降级"。
- Java 17 switch 表达式:可读性比 if-else 链高得多。
2.2 轮询分配:事务保住 last_assign_index
private Long assignByRoundRobin(TicketHandlerGroupDO group, List<Long> memberIds) {
int lastIndex = group.getLastAssignIndex() != null ? group.getLastAssignIndex() : 0;
int nextIndex = (lastIndex + 1) % memberIds.size();
TicketHandlerGroupDO updateObj = new TicketHandlerGroupDO();
updateObj.setId(group.getId());
updateObj.setLastAssignIndex(nextIndex);
ticketHandlerGroupMapper.updateById(updateObj);
return memberIds.get(nextIndex);
}
关键点:这个方法被 onProcessApproved 调用,外层有 @Transactional。两张工单同时审批通过时:
线程 A: SELECT group → lastIndex=2 → nextIndex=3 → UPDATE lastIndex=3 (事务未提交)
线程 B: SELECT group → 等待 A 的行锁(InnoDB update 会加 X 锁)
线程 A: COMMIT
线程 B: 看到 lastIndex=3 → nextIndex=4 → UPDATE lastIndex=4 → COMMIT
InnoDB 在 UPDATE 时会锁住这行,B 的 SELECT + UPDATE 实际上形成了"读已提交 + 行锁"的序列化,天然避免了两个线程派给同一个人。如果担心读写偏序问题,可以把 SELECT 升级为 SELECT ... FOR UPDATE。
2.3 负载最少:只看"活跃工单"
private static final List<Integer> ACTIVE_TICKET_STATUSES = List.of(
TicketStatusEnum.PENDING_PROCESS.getStatus(), // 2
TicketStatusEnum.PROCESSING.getStatus() // 3
);
private Long assignByLeastLoad(List<Long> memberIds) {
Long bestUserId = null;
long minCount = Long.MAX_VALUE;
for (Long memberId : memberIds) {
Long count = ticketBillMapper.countByHandlerAndStatus(memberId, ACTIVE_TICKET_STATUSES);
if (count < minCount) {
minCount = count;
bestUserId = memberId;
}
}
return bestUserId;
}
为什么只看 PENDING_PROCESS + PROCESSING?
- 不看"已完成":因为已完成在等申请人关闭,对处理人已经没有工作量
- 不看"已关闭":历史记录,算进来毫无意义
- 不看"待分配":待分配的工单还没人认领
这就把"负载最少"的语义精确到了"此刻还在这个人手上没办完的活儿",避免了"历史上办过 100 单的老员工被判定为最忙"的偏差。
2.4 如何避免"抖动"?
上面 2.3 看起来有"抖动"风险:A 刚刚被判定负载最小,下一秒 B 关单,再来一个新单又该分给 B?
RuoYi Office 的做法是只在"审批通过"那一刻评估一次,评估完就落库锁定 handler_id。下一张单来时再重新评估——相当于"逐单采样"而不是"持续均衡"。负载均衡的精细度牺牲了一点,但避免了高频重新分配带来的审计混乱。
三、SLA 双计时器:为什么要分两根红线?
3.1 数据模型
`response_deadline` DATETIME DEFAULT NULL COMMENT '响应截止时间',
`resolve_deadline` DATETIME DEFAULT NULL COMMENT '解决截止时间',
`response_timeout` BIT(1) NOT NULL DEFAULT b'0' COMMENT '是否响应超时',
`resolve_timeout` BIT(1) NOT NULL DEFAULT b'0' COMMENT '是否解决超时',
两个 deadline 字段 + 两个 timeout 标志位。标志位是"是否已经被 XXL-Job 处理过"的幂等标记。
3.2 为什么分两根红线?
| 场景 | 响应 OK 吗 | 解决 OK 吗 | 真实含义 |
|---|---|---|---|
| A. 3h 内接单,8h 内办完 | ✅ | ✅ | 优秀 |
| B. 3h 内接单,办了 2 天 | ✅ | ❌ | 接单及时但拖延 |
| C. 8h 后才接单,立刻办完 | ❌ | ✅ | 响应慢但抢救回来了 |
| D. 8h 后才接单,又办 3 天 | ❌ | ❌ | 灾难 |
如果只有一根 "整体 SLA" 红线,B 和 C 这两种完全不同性质的问题会被混为一谈。RuoYi Office 把"接单速度"和"结案速度"分别归因,组长就能精确知道问题出在哪一段。
3.3 SLA 规则匹配:sort 顺序决定
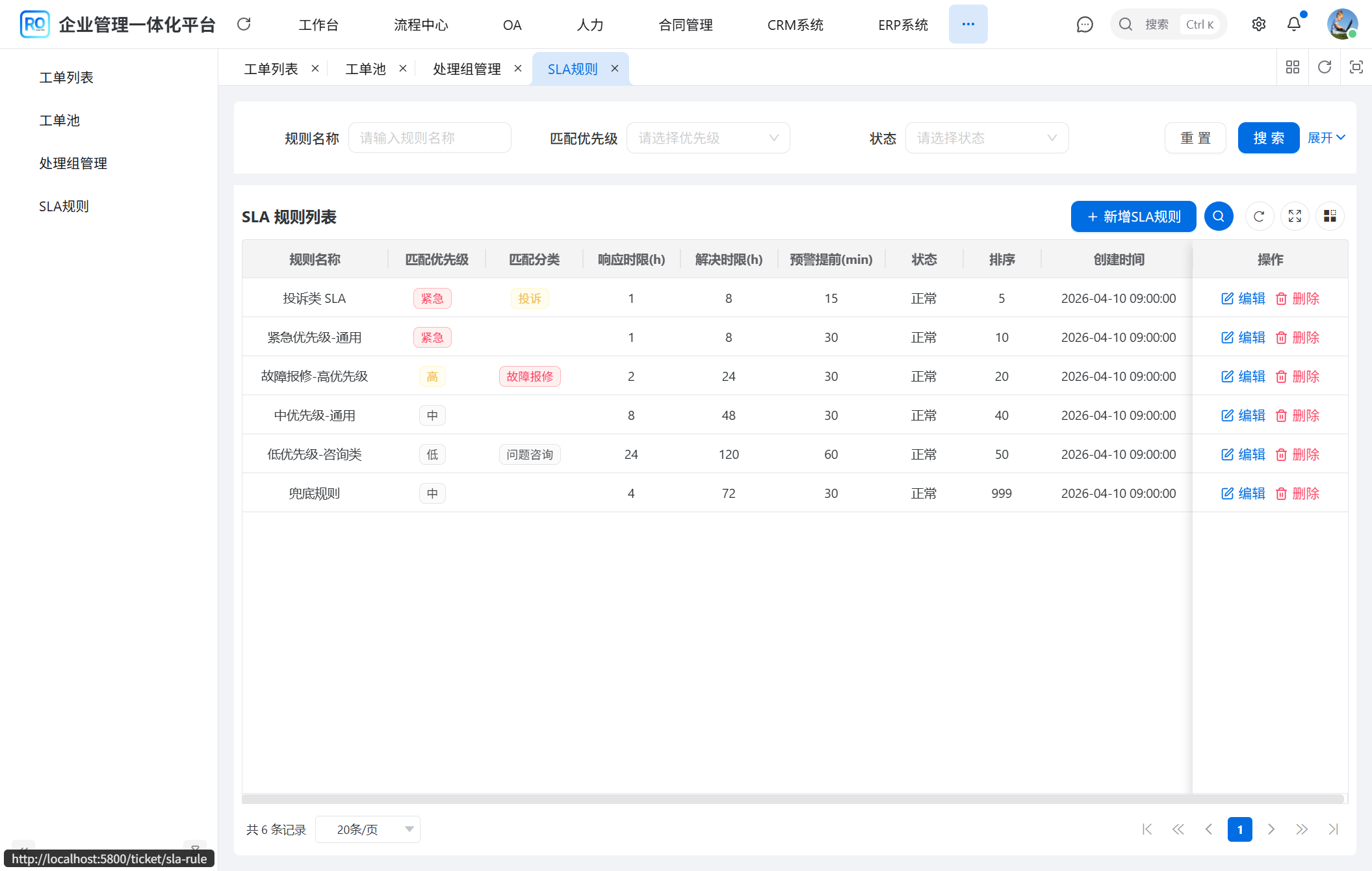
▲ SLA 规则表按 sort 升序匹配:投诉类(sort=5)→ 紧急通用(10)→ 故障高优(20)→ 中优先级通用(40)→ 低优先咨询(50)→ 兜底(999),最具体的规则排最前保证"专规则吃不到通规则"
匹配算法:
public TicketSlaRuleDO matchSlaRule(Integer priority, String category) {
List<TicketSlaRuleDO> rules = ticketSlaRuleMapper.selectActiveRulesOrdered(); // ORDER BY sort ASC
for (TicketSlaRuleDO rule : rules) {
boolean priorityMatch = rule.getPriority().equals(priority);
boolean categoryMatch = rule.getCategory() == null || rule.getCategory().isEmpty()
|| rule.getCategory().equals(category);
if (priorityMatch && categoryMatch) {
return rule;
}
}
return null;
}
三档命中优先级:
- 精确命中:priority + category 都匹配(例:
priority=4, category='4'投诉类 SLA) - 泛匹配:priority 匹配 + rule.category 为 NULL(例:
priority=4, category=NULL紧急通用) - 兜底:sort=999 的兜底规则保证永远有 deadline
这里有个值得抄的小设计:兜底规则不靠 Service 层 if-else 兜底,而是靠 DBA 配置 sort=999 的数据行兜底——SLA 策略就成了可配置的业务数据,不是写死的代码。
3.4 审批通过时一次性落 deadline
// onProcessApproved 内部
TicketSlaRuleDO slaRule = ticketSlaRuleService.matchSlaRule(bill.getPriority(), bill.getCategory());
if (slaRule != null) {
LocalDateTime baseTime = bill.getSubmittedTime() != null ? bill.getSubmittedTime() : LocalDateTime.now();
if (slaRule.getResponseHours() != null && slaRule.getResponseHours() > 0) {
updateObj.setResponseDeadline(baseTime.plusHours(slaRule.getResponseHours()));
}
if (slaRule.getResolveHours() != null && slaRule.getResolveHours() > 0) {
updateObj.setResolveDeadline(baseTime.plusHours(slaRule.getResolveHours()));
}
}
baseTime 选 submittedTime 而不是 now(),因为审批可能走几小时:工单是周一 10:00 提交的,审批周二 10:00 才通过,SLA 应该从周一算起——客户感知的就是"我周一提的单"。
四、XXL-Job 超时引擎:每分钟扫一次
4.1 职责分工
onProcessApproved负责写 deadline(一次性、同步)TicketSlaCheckJob负责扫 deadline(周期性、异步)
这样列表查询永远不需要实时算 SLA,直接查 response_timeout / resolve_timeout 字段即可走索引。
4.2 任务入口
@XxlJob("ticketSlaCheckJob")
public void execute() {
log.info("[ticketSlaCheckJob] 开始执行SLA超时检查");
List<TicketBillDO> tickets = ticketBillMapper.selectListForSlaCheck(CHECK_STATUSES);
LocalDateTime now = LocalDateTime.now();
int warnCount = 0, timeoutCount = 0;
for (TicketBillDO ticket : tickets) {
try {
// Check response timeout
if (ticket.getResponseDeadline() != null
&& !Boolean.TRUE.equals(ticket.getResponseTimeout())) {
if (ticket.getAcceptedTime() == null) {
if (now.isAfter(ticket.getResponseDeadline())) {
markResponseTimeout(ticket);
timeoutCount++;
} else if (now.plusMinutes(30).isAfter(ticket.getResponseDeadline())) {
sendSlaWarning(ticket, "响应");
warnCount++;
}
}
}
// Check resolve timeout
if (ticket.getResolveDeadline() != null
&& !Boolean.TRUE.equals(ticket.getResolveTimeout())) {
if (now.isAfter(ticket.getResolveDeadline())) {
markResolveTimeout(ticket);
timeoutCount++;
} else if (now.plusMinutes(30).isAfter(ticket.getResolveDeadline())) {
sendSlaWarning(ticket, "解决");
warnCount++;
}
}
} catch (Exception e) {
log.error("[ticketSlaCheckJob] 处理工单SLA检查异常,ticketId: {}", ticket.getId(), e);
}
}
log.info("[ticketSlaCheckJob] SLA检查完成,共检查 {} 条工单,预警 {} 条,超时 {} 条",
tickets.size(), warnCount, timeoutCount);
}
三个工程细节:
!Boolean.TRUE.equals(timeout)的短路:一旦标记过就不再重复处理,幂等- 响应超时只在
acceptedTime == null时判定:接单过的单不再触发响应超时 try-catch包住单条逻辑:某张工单数据脏不会拖垮整个批次
4.3 待扫描数据的 SQL
default List<TicketBillDO> selectListForSlaCheck(List<Integer> ticketStatuses) {
return selectList(new LambdaQueryWrapperX<TicketBillDO>()
.in(TicketBillDO::getTicketStatus, ticketStatuses) // 只扫 1/2/3 状态
.and(w -> w
.isNotNull(TicketBillDO::getResponseDeadline)
.or()
.isNotNull(TicketBillDO::getResolveDeadline))); // 至少有一个 deadline
}
查询过滤规则:
ticket_status IN (1, 2, 3)—— 只扫活跃状态,已完成/已关闭的工单连 SELECT 都不做response_deadline IS NOT NULL OR resolve_deadline IS NOT NULL—— 没配 SLA 的工单直接跳过- 索引命中
idx_ticket_status后通过覆盖条件走内存过滤
4.4 "提前 30 分钟预警" 为什么是 30?
else if (now.plusMinutes(30).isAfter(ticket.getResponseDeadline())) {
sendSlaWarning(ticket, "响应");
}
注意30 分钟是硬编码的——实际上每条 SLA 规则都有 warn_before_minutes 字段:
`warn_before_minutes` INT NOT NULL DEFAULT 30 COMMENT '提前预警(分钟)'
这是一个 TODO,当前版本默认用 30min。规则表里"投诉类"配 15min、"低优先级"配 60min,后续只要把硬编码改成读规则值:
int warnMinutes = slaRule != null ? slaRule.getWarnBeforeMinutes() : 30;
else if (now.plusMinutes(warnMinutes).isAfter(ticket.getResponseDeadline())) { ... }
4.5 幂等:标记一次就锁死
一旦 response_timeout = 1 被写入,下次扫描会因为 !Boolean.TRUE.equals(responseTimeout) 直接跳过这张工单,不会重复发通知。这比 Redis 做分布式锁要简单可靠得多——状态幂等性由数据库本身承担。
当然,XXL-Job 的 cron 0 * * * * ?(每分钟)一次扫整库,也别担心——ticket_status IN (1,2,3) 上有索引,通常只会扫出几十到几百条活跃工单。真到万级活跃量时,可以在 oa_ticket_bill 上加一个 idx_sla_check 联合索引:
KEY `idx_sla_check` (`ticket_status`, `response_timeout`, `resolve_timeout`, `resolve_deadline`)
五、站内信:模板化通知处理人 + 组长
5.1 超时通知双发
private void sendTimeoutNotification(TicketBillDO ticket, String type) {
Map<String, Object> params = Map.of(
"billCode", ticket.getBillCode(),
"title", ticket.getTitle() != null ? ticket.getTitle() : "",
"type", type
);
if (ticket.getHandlerId() != null) {
sendNotification(ticket.getHandlerId(), "ticket-sla-timeout", params);
}
sendToGroupLeader(ticket, "ticket-sla-timeout", params); // 抄送组长
}
private void sendToGroupLeader(TicketBillDO ticket, String templateCode, Map<String, Object> params) {
if (ticket.getHandlerGroupId() == null) return;
try {
TicketHandlerGroupDO group = ticketHandlerGroupService.getHandlerGroup(ticket.getHandlerGroupId());
if (group != null && group.getLeaderUserId() != null) {
sendNotification(group.getLeaderUserId(), templateCode, params);
}
} catch (Exception e) {
log.warn("[sendToGroupLeader] 发送通知给组长失败,ticketId: {}", ticket.getId(), e);
}
}
两级通知机制:
- 第一级:处理人本人收通知(知道自己拖了)
- 第二级:组长抄送(知道下属谁在拖)
这是客服/IT 运维场景最常见的"自下而上 + 自上而下"双通道追责模型。
5.2 为什么用站内信不用 webhook?
| 通道 | 优点 | 缺点 |
|---|---|---|
| 站内信 | 统一入口,用户习惯 | 需要自己打开 OA 才能看 |
| 钉钉/企微 webhook | 主动推送 | 跟具体 IM 厂商绑定 |
| 邮件 | 可审计,合规 | 低优先级工单浪费邮箱 |
RuoYi Office 的做法:先做站内信,通过 NotifyMessageSendApi 发模板消息,未来要接钉钉/企微,只需要在模板层扩展适配器,Service 层代码一行不变。
5.3 模板参数化的好处
Map.of(
"billCode", ticket.getBillCode(),
"title", ticket.getTitle(),
"type", type
)
模板文本配在 system_notify_template 表里,比如:
[SLA超时] 工单 {{billCode}}({{title}})的{{type}}时效已超时,请立即处理。
组长改话术不用改代码。这就是"参数是业务配置,不是硬编码"的工程红线。
六、完整的数据流时序
让我们把整个系统串起来看一张工单从提交到超时通知的完整时序:
T0 用户提交:INSERT oa_ticket_bill(process_status=1, ticket_status=0)
+ BPM startProcessInstance()
T1 审批通过:BPM 框架回调 FlowBillService.onProcessApproved(businessKey)
├─ matchSlaRule(4, '2') → 返回 "故障报修-高优先级" 规则
├─ updateObj.setResponseDeadline(T0 + 2h)
├─ updateObj.setResolveDeadline(T0 + 24h)
├─ tryAutoAssign(group)
│ └─ assignByRoundRobin: lastIndex=2 → memberIds[3] = 103
│ └─ UPDATE group SET last_assign_index=3 (事务锁)
├─ updateObj.setHandlerId(103) / setHandlerName("张三")
├─ updateObj.setAssignedTime(now) / setTicketStatus(2 待处理)
└─ addSystemRecord(id, "工单审批通过,进入待处理")
T2 处理人接单:acceptTicket(id)
├─ 校验 state ∈ {1,2} + memberCheck or handlerCheck
└─ UPDATE ticket SET handler_id=103, accepted_time=now, ticket_status=3 (处理中)
T3-T? 处理人回复:createReply(type=1 公开/2 内部/3 系统)
└─ UPDATE ticket SET reply_count = reply_count + 1
T0+1.5h XXL-Job 扫描:
├─ SELECT ... WHERE ticket_status IN (1,2,3) AND (resp_dl NOT NULL OR res_dl NOT NULL)
├─ now + 30min > response_deadline (T0+2h)?是,且 accepted_time 已填 → 跳过响应预警
└─ now + 30min > resolve_deadline (T0+24h)?否 → 跳过解决预警
T0+23.5h XXL-Job 扫描:
└─ now + 30min > resolve_deadline?是 → sendSlaWarning("解决")
├─ notifyMessageSendApi.send(handler=103, template="ticket-sla-warn")
└─ sendToGroupLeader(leader=1, template="ticket-sla-warn")
T0+24h XXL-Job 扫描:
└─ now > resolve_deadline → markResolveTimeout(ticket)
├─ UPDATE ticket SET resolve_timeout=1
├─ addSystemRecord(id, "【SLA超时】解决时间已超时")
└─ sendTimeoutNotification(handler + leader)
T0+25h XXL-Job 扫描:
└─ resolve_timeout=1 → 短路跳过,幂等
T4 处理人完成:completeTicket(id) → ticket_status = 4
T5 申请人关闭:closeTicket(id) → ticket_status = 5
整条链路:一次数据写入、一次回调、一次定时扫、两次通知。任何一个环节挂掉其他环节都能继续走,没有强耦合、没有消息队列。
七、数据模型索引设计
7.1 oa_ticket_bill 的索引
PRIMARY KEY (`id`),
UNIQUE KEY `uk_bill_code` (`bill_code`),
KEY `idx_ticket_status` (`ticket_status`), -- 工单池、状态统计
KEY `idx_handler_id` (`handler_id`), -- 我处理的
KEY `idx_handler_group_id` (`handler_group_id`), -- 处理组路由
KEY `idx_creator` (`creator`), -- 申请端"我的工单"
KEY `idx_resolve_deadline` (`resolve_deadline`) -- SLA 扫描(为什么不是 response?)
为什么只给 resolve_deadline 建索引而不给 response_deadline?因为解决时间通常远大于响应时间,resolve_deadline 的区分度更高,索引效率更好;而响应时间短,活跃工单里超时的比例本来就小。
7.2 如果要支持万级并发:建议的扩展索引
-- 覆盖 XXL-Job 扫描
ALTER TABLE oa_ticket_bill ADD KEY idx_sla_scan
(ticket_status, response_timeout, resolve_timeout, resolve_deadline);
-- 覆盖工单池按组查
ALTER TABLE oa_ticket_bill ADD KEY idx_pool
(process_status, handler_group_id, ticket_status, id);
第一个索引让 selectListForSlaCheck 完全走覆盖索引;第二个让工单池的"组内+待分配"查询走到最合适的索引而非回表。
八、技术亮点总结
| 设计点 | 实现方式 | 工程价值 |
|---|---|---|
| 工单池路由 = SQL 条件 | group_id IN (:myGroups) OR IS NULL | 0 中间件、0 关系表 |
| 成员关系逗号分隔 | VARCHAR(2000) 存 member_user_ids | 读多写少,整体覆盖语义简单 |
| SLA deadline 一次性落库 | onProcessApproved 回调时写入 | 列表 0 成本,扫描走索引 |
| 响应/解决双计时器 | 两个 deadline + 两个 timeout 标志位 | 把"接单慢"和"办结慢"拆开归因 |
| SLA 匹配按 sort | selectActiveRulesOrdered + for 循环 | 兜底规则配数据,不写代码 |
| 轮询的并发安全 | 事务 + InnoDB 行锁 | 两线程同时派不会重复 |
| 负载最少只看活跃 | ticket_status IN (2,3) 过滤 | 排除历史单和已完成单的偏差 |
| 自动分配主动降级 | 失败返回 null → 落入工单池 | 不会因为分配失败而卡住 |
| XXL-Job 幂等 | timeout 标志位一次置位不再处理 | 不需要 Redis 分布式锁 |
| 超时通知双发 | 处理人 + 组长抄送 | 下属自觉 + 上级知情双通道 |
| 站内信模板化 | NotifyMessageSendApi + template code | 改话术不改代码 |
| baseTime = submittedTime | SLA 从提交算起非审批通过算起 | 审批耗时不算入客户等待 |
九、快速体验
**启动方式
