


面试现场:这道题为什么频繁出现
线上跑了一个 47 步的内容审核工作流,第三十八步的时候 Pod 被驱逐了——不是 OOM,不是超时,就是 Kubernetes 调度把你的实例挪走了。
然后 Agent 重启,从头开始跑,前三十七步白干。
这就是没有 Checkpoint 的代价,也是面试官想看你有没有意识到这个问题的原因。
在 AI 工程岗位的面试里,LangGraph 的 Checkpoint 机制是高频出现的专项追问。
它的热度来源于一个根本矛盾:LLM 应用越复杂,状态管理的需求就越刚,而大多数候选人只会背「用 Message Graph 做记忆」这种套话,对真正生产级的状态持久化几乎一无所知。
本专题聚焦 LangGraph Checkpoint 机制,从原理、选型、恢复链路到面试应答,做一次完整的深讲。目标只有一个:让你不只能答出来,还能讲出判断、讲出取舍、讲出工程语境。
第38步没了,心态也快没了
一、Checkpoint 的本质:谁来保存 Agent 的'记忆'
1.1 状态(State)与时间维度
在 LangGraph 里,State 是一个 TypedDict(或 Pydantic BaseModel),它贯穿整个工作流的执行过程——每个 Node 接收当前 State,执行逻辑后返回更新后的 State,数据像水流一样在节点之间传递。
问题在于,这个 State 存在于内存中。当工作流执行到第 38 步时,内存里存着前 37 步的所有中间结果:已检索的上下文、已生成的草稿、已完成的校对意见。
如果进程崩溃,这些数据全部丢失,Agent 重启后面对的是一个全新的、空的 State。
这就是为什么需要 Checkpoint——它在时间维度上给 State 做「快照」,把内存里的状态序列化后落盘,让恢复成为可能。
1.2 Checkpoint 作为 State 的版本快照
Checkpoint 本质上是 State 在某个时刻的只读副本。
每当一个 Node 执行完毕(更准确地说,是每一个「step」的边界),Graph Engine 会自动触发一次 Checkpoint 写入,将当前 State 序列化后存入持久化层。
这个快照包含的内容远不止 State 本身,还包括:
-
版本标识:一个自增的 checkpoint_id,精确标记这是第几次写入
-
时间戳:写入的绝对时间,用于回溯和审计
-
完整 State 镜像:序列化后的状态数据,可以是 JSON、bytes 或其他格式
-
父引用:指向前一个 Checkpoint 的 ID,支持线性回溯
快照是追加写入的,不是覆盖。这带来了一个关键特性:你可以回溯到任意历史版本,而不只是回到最近一次保存。
这个设计解决了一个真实痛点:当 Agent 执行了若干步之后,你发现前几步的决策有问题,需要「回到第三步重新跑」,Checkpoint 提供了这种能力,而普通的内存状态做不到。
1.3 图执行引擎与持久化层的关系
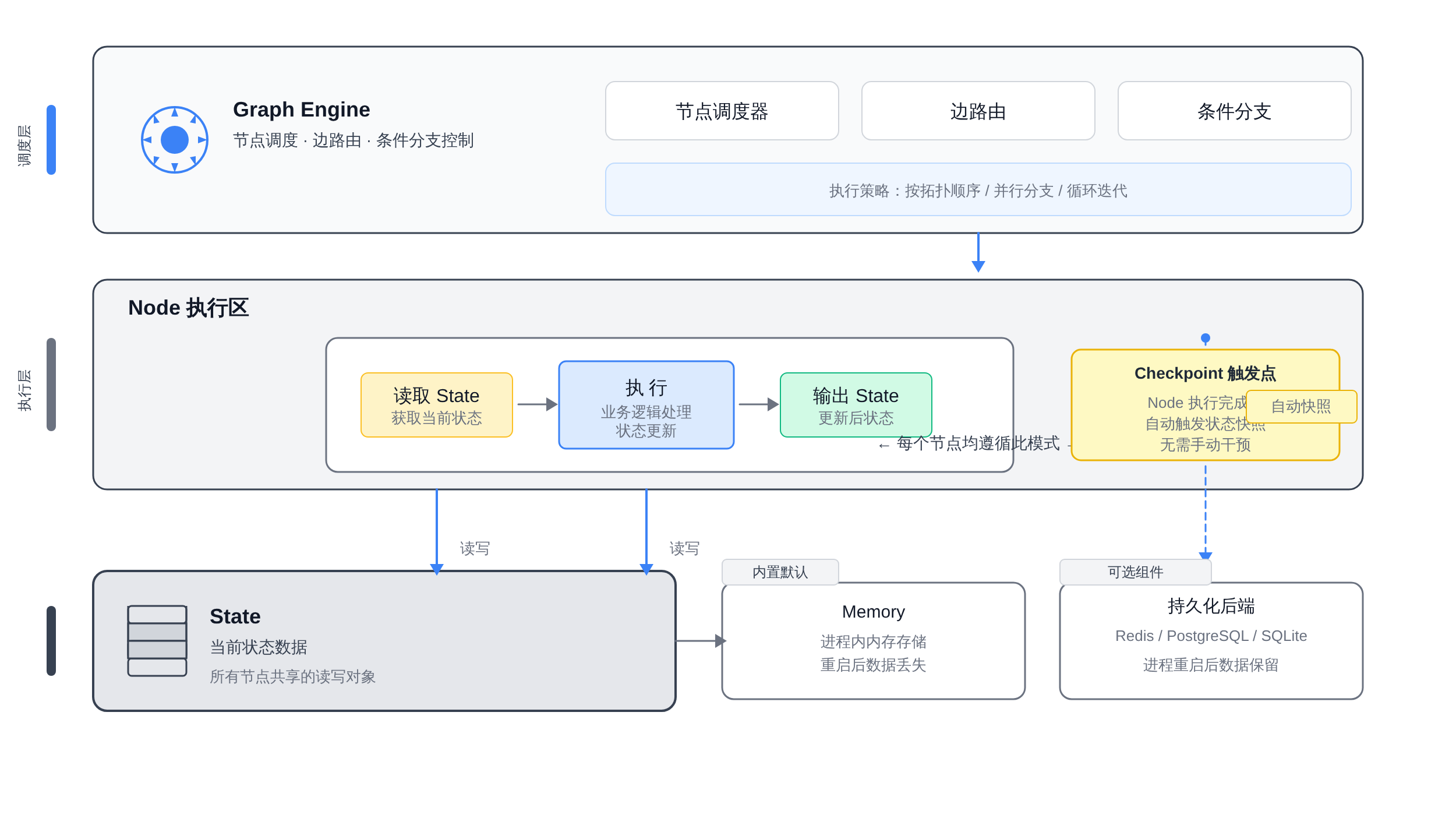
LangGraph 的核心架构可以拆成三层:
正文图解 1
Graph Engine 在最上方负责调度节点、路由边、决策分支。
当一个 Node 完成执行后,Engine 会自动触发 Checkpoint 写入——这个触发是框架级的,不需要开发者手动调用。
这是 LangGraph 和「自己用 Redis 手动存 State」的方案最本质的区别:Checkpoint 是架构层面的内置能力,不是业务代码里写出来的。
持久化层在最下方,可以是 Memory(内存,关机即失)、Redis(跨进程持久化)、PostgreSQL(多租户企业场景)或 SQLite(轻量单实例)。
这一层通过 CheckpointSaver 接口与 Engine 解耦,意味着你可以换存储后端而不改任何业务逻辑。
理解了这种分层关系,你就知道为什么面试官会问「Checkpoint 和普通的状态保存有什么区别」——前者是架构级的事务性快照,后者是业务代码里的手动赋值。

框架帮你写好,才不会有人忘记打快照
二、持久化后端:从 MemorySaver 到 Redis 的完整光谱
2.1 MemorySaver:开发调试的首选
MemorySaver 是 LangGraph 内置的内存版 Checkpoint 实现,不需要任何外部依赖,一个 pip install 之后直接可用。
它的核心逻辑是把每个 Checkpoint 以 Python 对象形式存入进程的内存字典,key 是 thread_id,value 是该线程的所有 Checkpoint 版本列表。
这种设计天然适合:
-
本地开发调试:不需要启动 Redis 或 PostgreSQL,代码写完直接 run
-
单进程快速验证:在 Jupyter 里跑实验,Checkpoints 随进程生灭
-
Demo 和 PoC:面试前跑通一个端到端流程,证明你理解机制
MemorySaver 的代价是字面意义上的:进程重启后,所有 Checkpoints 灰飞烟灭。
在一个运行 24 小时的 Kubernetes Pod 里,这意味着任何一次 Pod 驱逐都会导致「从头重跑」的灾难。
from langgraph.checkpoint.memory import MemorySaver
# 初始化内存版 CheckpointSaver
checkpointer = MemorySaver()
# 在编译图时注入
app = graph.compile(checkpointer=checkpointer)
# 运行时指定 thread_id
config = {"configurable": {"thread_id": "user-123-session-1"}}
result = app.invoke(initial_state, config)
上面这段代码跑在本地没问题,thread_id 的存在让多个并发会话的状态隔离。但一旦部署到 Kubernetes,任何一次 rollout 或节点调度都会让 memory 里的一切归零。
2.2 Redis CheckpointSaver:生产高性能方案
Redis 是生产环境里最常见的 Checkpoint 存储选择,原因很直接:延迟低、跨进程持久化、支持高并发写入,而且大多数后端团队已经维护着 Redis 集群,不需要额外的运维成本。
Redis CheckpointSaver 的写入模型本质上是一个 hash 结构:
-
thread:{thread_id}:checkpoints— 存该线程所有版本的快照列表(zset,按版本号排序) -
thread:{thread_id}:state— 存当前最新 State(string,序列化后的 bytes)
每次 Node 执行完成,Saver 把序列化后的 State 以 checkpoint_id 为 key 写进去,同时更新最新 State 的指针。
进程重启后,通过 thread_id 找到最新 Checkpoint,直接 restore,不需要扫描整个历史。
from langgraph.checkpoint.redis import RedisSaver
import redis
# 连接 Redis
redis_client = redis.Redis(host="localhost", port=6379, db=0)
checkpointer = RedisSaver(redis_client)
# 编译图
app = graph.compile(checkpointer=checkpointer)
# 运行时 config 携带 thread_id
config = {"configurable": {"thread_id": "session-abc-42"}}
Redis 的写入延迟通常在亚毫秒级,单次 Checkpoint 操作(序列化 + 写入 + 更新指针)大约 1-3ms,这对大多数 AI 工作流来说是完全可接受的额外开销。
相比于第 38 步重跑可能浪费的几十秒 LLM 调用时间,3ms 的 Checkpoint 延迟是极划算的保险。
2.3 PostgreSQL / SQLite Checkpointer:企业级与多租户场景
当团队规模变大、需要多租户隔离、或者审计合规要求较高的场景时,Redis 就显得有些单薄了。PostgreSQL 和 SQLite Checkpointer 应运而生。
PostgreSQL 适合多实例部署的企业场景,每个 thread_id 的 Checkpoints 存在一张结构化的 DB 表里:
CREATE TABLE checkpoints (
thread_id VARCHAR(255),
checkpoint_id VARCHAR(255),
parent_checkpoint_id VARCHAR(255),
state JSONB,
created_at TIMESTAMP DEFAULT NOW(),
PRIMARY KEY (thread_id, checkpoint_id)
);
这种结构的优势在于:可以写 SQL 查询某个线程的历史状态、可以加索引加速检索、可以通过 DB 的事务保证写入原子性。对于需要审计日志、合规留存的企业来说,PostgreSQL 是不可替代的选择。
SQLite 则适合边缘部署、单实例场景,或者在本地开发时不想跑 Redis/PG 却又需要跨进程持久化的需求。
SQLite 的 Checkpointer 把所有数据存在一个本地 .db 文件里,启动快,运维零成本,但在高并发写入场景下会成为瓶颈——毕竟 SQLite 写锁是全局的。
from langgraph.checkpoint.sqlite import SqliteSaver
checkpointer = SqliteSaver.from_conn_string("checkpoints.db")
app = graph.compile(checkpointer=checkpointer)
2.4 三种方案横向对比:延迟、吞吐、适用场景
| 维度 | MemorySaver | Redis | PostgreSQL | SQLite |
|---|---|---|---|---|
| 写入延迟 | <1ms(内存) | 1-3ms | 5-15ms | 3-8ms |
| 进程重启后保留 | ❌ | ✅ | ✅ | ✅ |
| 并发写入支持 | 单进程 | 高并发 | 高并发 | 有限(写锁) |
| 部署复杂度 | 零依赖 | 需 Redis 集群 | 需 PG 实例 | 零依赖 |
| 多租户支持 | ❌ | 需 key 隔离 | ✅(DB 层) | ❌ |
| 审计与查询 | ❌ | 有限 | ✅(SQL) | ✅(SQL) |
| 最佳场景 | 本地调试 / PoC | 生产高并发 | 企业多租户 | 边缘 / 单实例 |
选型的核心逻辑其实很清晰:本地开发用 MemorySaver,省事;生产高并发用 Redis,省钱且够快;企业级合规审计用 PostgreSQL,多掏运维成本换结构化数据;
边缘场景用 SQLite,零运维是最好的运维。

选型讨论能开两小时,因为每个人的「够用」定义不一样
三、断点恢复:重启之后 Agent 怎么找到自己的位置
3.1 thread_id 寻址机制
断点恢复的第一步是「找到正确的会话」。这个逻辑在 LangGraph 里通过 thread_id 实现——它是 Checkpoint 存储的顶级索引 key,相当于关系数据库里的主键。
当你执行 app.invoke(state, config) 时,config 里必须包含一个 thread_id。
LangGraph 用这个 ID 去持久化层查找对应线程的 Checkpoint 列表。如果找到了最新版本,就执行 restore;
如果没找到(比如新会话),就使用 initial_state 初始化。
# 每次调用时传入 thread_id
config = {"configurable": {"thread_id": "user-1001-turn-5"}}
# LangGraph 内部逻辑:
# 1. checkpointer.get(thread_id) → 获取最新 checkpoint
# 2. 如果存在:restore 并继续
# 3. 如果不存在:从 initial_state 开始
thread_id 的设计暗示了一个工程原则:你的业务系统需要为每个用户会话生成并维护一个稳定的 thread_id。
如果你在对话机器人场景里让用户每次刷新页面都换 thread_id,那 Checkpoint 永远找不到历史状态,形同虚设。
3.2 checkpoint_id 与状态版本回溯
每个 Checkpoint 除了指向当前 State,还有一个自增的 checkpoint_id,用来精确标记这是第几次快照。
这个 ID 的价值在于版本控制能力:
-
向前恢复:从 checkpoint_id=38 恢复后,Agent 从步骤 38 的状态继续执行
-
向后回溯:可以显式指定恢复到一个更早的版本,比如 checkpoint_id=20,然后重新走一条分支路径
-
调试复现:生产环境出了问题,可以「Replay」特定版本的 State 来复现 bug
回溯操作的 API 大约是这样的:
# 指定恢复到某个 checkpoint_id
restore_config = {
"configurable": {
"thread_id": "user-1001",
"checkpoint_id": "1e2a3b4c-..."
}
}
# restore 并得到历史状态
historical_state = app.get_state(restore_config)
这个能力在面试里经常被问到「能回退几步」。正确的回答是「理论上无限,取决于存储成本」,而不是「只能回到上一步」——后者暴露了你对 checkpoint_id 机制理解不足。
3.3 restore 后的状态一致性保证
restore 操作不是简单地把一个 JSON 文件读进内存。LangGraph 的 Checkpoint 恢复包含几个关键的保证:
原子性:恢复要么完全成功(State + checkpoint_id 全部就位),要么完全失败(不影响当前内存状态)。
不会出现「State 恢复了但 checkpoint_id 还是旧的」这种不一致状态。
幂等性:在同一个 checkpoint_id 上连续执行两次 restore,得到完全相同的 State。
这个属性在微服务场景里尤其重要——如果两次恢复得到不同结果,重试逻辑会陷入不可预测的混乱。
增量一致性:如果 Graph 本身的定义在两次运行之间发生了变化(比如 Node 被删掉或改名),旧版本的 Checkpoint 数据可能无法被新版本 Graph 完全解释。
LangGraph 不会自动处理这种 schema 迁移,需要开发者显式处理版本兼容性。
3.4 冷启动延迟:首次 Checkpoint 写入的时间成本
有一个面试里容易被忽略的细节:第一次 Checkpoint 写入的延迟通常比后续写入高。
原因是:首次写入时,持久化层需要建立索引、分配存储结构、初始化连接池。
以 Redis 为例,首次 set 一个新 key 需要经历「连接获取 → 序列化 → 网络传输 → 写入 → 返回」的全链路,而在连接已预热后,后续写入跳过了一些握手开销。
实测数据(来自 LangChain 生产用户的公开分享1)表明:MemorySaver 到 Redis 的首次 Checkpoint 写入延迟差大约在 2-4ms,而在 Redis 连接池预热后,这个差距缩小到 0.5-1ms。
对于一个 50 步工作流,累积的额外延迟大约在 25-50ms 量级,完全在可接受范围。
真正需要担心的是另一种情况:持久化层的首次连接超时。如果 Redis 集群抖动,首次写入超时可能导致整个 step 失败,影响工作流的完整性。这种场景需要在代码层面做超时处理和降级策略。
第一次写入慢几 ms,OOM 了那几步全白等
四、面试高频问答:怎么答才能不卡壳
4.1 核心问题一:LangGraph 的 Checkpoint 机制是什么?请解释其工作原理。
模板答案(30 秒开口版)
LangGraph 的 Checkpoint 是对 Agent 运行时 State 的版本快照机制。每个 Node 执行完成后,Graph Engine 会自动触发一次 Checkpoint 写入,把当前 State 序列化后存入持久化后端。这个后端可以是内存、Redis 或 PostgreSQL——具体用哪个,取决于你的部署场景和数据保留需求。恢复时,通过 thread_id 定位会话,再用 checkpoint_id 指定恢复到哪个版本,实现真正的断点续跑。
这个 30 秒版本覆盖了本质(State 快照)、触发时机(Node 执行完成)、后端可选性(Memory / Redis / PG)和恢复机制(thread_id + checkpoint_id),已经足够应对大多数一面。
展开版
如果要展示更深的理解,可以在上面基础上补充:
Checkpoint 和普通的 State 变量保存最大的区别在于「架构级」vs「业务级」。普通状态是代码里的变量,进程重启就没了;Checkpoint 是框架内置的事务性快照,由 Graph Engine 在每个 step 边界自动触发,不需要开发者手动调用 save。这带来了两个关键属性:一是版本化——你可以回溯到任意历史 Checkpoint;二是幂等性——同一 checkpoint_id 恢复两次得到相同结果,这在微服务重试场景里非常重要。
这段展开能让你和「只会背概念」的回答拉开差距。关键是你说出了「框架级触发」vs「手动保存」的区别,还引入了幂等性和版本化这两个面试官乐意追问的属性。
面试官在筛什么
这个问题表面问原理,实际在测三件事:
-
你有没有工程直觉——知不知道 Pod 驱逐、进程崩溃会导致状态丢失这种真实问题
-
你的认知有没有层次——是从上往下看(Graph Engine → State → Checkpoint)还是只会平铺概念
-
你能不能区分「功能」和「架构」——MemorySaver 是功能选择,框架级触发是架构属性,不能混为一谈
常见追问
-
「Checkpoint 触发时机是什么?是每个 Node 还是每个 step?」
-
答:每个 step 完成时触发,step 和 Node 不是同一个概念——一个 Node 可以被调用多次,但只有完整执行一次 step 后才写 Checkpoint。
-
「如果 Node 执行到一半进程崩了,这个 Node 的状态能恢复吗?」
-
答:不能,Checkpoint 是在 Node 执行完成后才写的,这是「快照」的固有限制。如果需要更细粒度的保证,需要用子任务拆分或者外部事务补偿。

追问的深度取决于你答的深度
4.2 核心问题二:生产环境中,应该选择哪种 Checkpoint 存储后端?为什么?
模板答案
我会优先选 Redis。延迟低(1-3ms 量级),跨进程持久化,高并发支持,而且大多数后端团队已经有 Redis 集群,不需要额外的运维成本。如果团队规模大、需要审计合规或者多租户隔离,才会选 PostgreSQL。本地调试用 MemorySaver,生产绝对不用——进程重启后数据全丢,没有任何容错能力。
这个回答干净利落,而且暗含了「不是因为某个后端「更好」,而是因为不同场景需要不同后端」的判断逻辑。
对比取舍的核心逻辑
面试官真正想听的不是你背出来哪个后端快,而是你知不知道取舍背后的 trade-off:
| 因素 | MemorySaver | Redis | PostgreSQL |
|---|---|---|---|
| 选它的理由 | 零成本快速验证 | 性能与便利的平衡点 | 合规与审计 |
| 放弃它的理由 | 进程重启即丢失 | 单点故障风险需 HA | 运维复杂度高 |
| 典型场景 | 面试 demo / 本地调试 | 中小团队生产 | 大企业多租户 |
易错点:MemorySaver 的隐性代价
有一个陷阱值得提前准备:MemorySaver 在面试里经常被候选人轻描淡写地说「开发时用」,但面试官会追问「那生产能不能用?」如果你回答「生产不建议,因为进程重启就丢了」,这只是表层答案。
更深一层的问题是:MemorySaver 丢掉的不仅是最后一次 Checkpoint,而是整个会话的历史状态。
对于一个多轮对话场景,用户和 Agent 聊了 20 轮,进程重启后用户发现 Agent 失忆了,「聊了这么久全白说了」——这是 Product 的问题,不只是技术的问题。
能答出这一层的候选人,在面试官眼里的评价会明显高出一个档次。

「开发用 MemorySaver」不是甩锅理由,是认知分层
4.3 核心问题三:你的项目里是怎么处理 Agent 状态丢失问题的?
项目语境怎么说
如果你有真实项目经验,直接讲场景:
在我们 XX 场景的 Agent 里,用 Redis CheckpointSaver 做状态持久化。每个用户会话对应一个 thread_id,Node 执行完成后自动写 Checkpoint。有一次 K8s rollout 导致 Pod 重启,Agent 从断点恢复了,没有让用户重新描述问题。这套方案还需要处理一个问题——Redis 不可用时的降级:我们在 Redis 连接超时 500ms 后降级到 MemorySaver,同时打一条告警,因为降级期间的状态不会跨进程保留。
这个回答展示了三个层次:实际选型(Redis)、一次真实恢复经历(K8s rollout)、额外的问题(降级策略)。任何一个真实的工程问题都比背书式的答案更有说服力。
没有生产项目怎么补
不是所有人都有生产级 Agent 项目。补法有几个:
-
用 LangGraph 官方示例跑通一个多轮对话,加上 Redis CheckpointSaver,模拟一次 Pod 重启后的恢复过程,截图或日志保留作为佐证
-
在简历里明确写「使用 Redis CheckpointSaver 实现状态持久化,支持断点恢复」,而不是笼统说「用了 LangGraph」
-
准备一个降级场景的口头描述:如果没有 Redis 怎么办?如果 Redis 延迟忽然飙升到 500ms 怎么办?——这些追问反映了真正的工程思维
没有真实项目不是致命伤,但「知道自己没做过什么」和「能讲清楚为什么没做、打算怎么做」是两回事。后者更有价值。
五、项目落地语境:没有真实项目怎么补
5.1 用 LangGraph 官方示例构建个人演示项目
对于还没有生产级 Agent 经验的候选人,构建一个可演示的个人项目是最好的补强路径。推荐的最小可用演示路径:
-
用 LangGraph 写一个「调研→撰写→校对」的三阶段写作 Agent,加上 Redis CheckpointSaver
-
跑通正常流程,记录 Checkpoint 写入的日志
-
人为触发一次「进程中断」(模拟 K8s 驱逐),观察恢复行为
-
把整个过程录屏或截图,放在简历项目描述里作为佐证
这个路径不需要任何真实的业务逻辑,重点是展示你理解 Checkpoint 的生命周期,并且实际跑通过一次完整的恢复流程。
面试官看到「我模拟过一次 Pod 重启后的恢复」时,会比看到「熟悉 LangGraph」有效得多。
5.2 在开源社区找到等价工程经验
LangGraph 的 GitHub 仓库和 LangChain 的官方博客里,有不少生产部署的案例分享。如果你在准备面试时找不到自己的项目经验,可以从这些公开案例里提取工程细节:
-
某金融企业的测试用例生成系统用 PostgreSQL CheckpointSaver 做断点续传,单次任务成功率从 72% 提升至 95%
-
某电商平台的推荐系统调试用了 LangSmith 可视化 Checkpoint 链路,将问题定位时间从小时级缩短到分钟级1
这些数字不是让你背的,是让你理解一个真实系统里 Checkpoint 的价值在哪里——不是「有没有」,而是「用了之后系统可靠性提升了多少」。
5.3 从实习/课程项目里提炼 Checkpoint 相关表达
即便你的实习经历没有直接做 Agent 开发,也能找到等价的表达:
-
如果做过 Web 服务:你可以把「用 Redis 存 Session 实现用户登录状态恢复」类比为「用 CheckpointSaver 实现会话状态持久化」——本质都是跨进程的状态恢复,只是粒度和触发时机不同
-
如果做过数据管道:你可以把「Checkpoint 了每一步的处理结果,失败后从上一个 Checkpoint 续跑」作为经验来描述
-
如果做过课程大作业:描述「遇到进程意外终止导致数据丢失问题,然后调研了状态持久化方案」作为动机,给 Checkpoint 补一个合理的工程背景
关键不是你的项目名字里有没有「LangGraph」,而是你能不能讲清楚「为什么需要持久化状态」这个判断过程。
六、边界与陷阱:面试官会往哪里追问
6.1 最大快照数限制与存储成本
MemorySaver 在内存里存所有 Checkpoint 版本,对于长会话(50 步以上的工作流),内存占用会线性增长。
LangGraph 默认不限制 Checkpoint 数量,但可以通过配置 max_versions 或手动清理历史版本来控制。
Redis 的存储成本相对可控,但当 thread_id 数量达到万级、每个线程有上百个 Checkpoint 时,需要评估 Redis 的内存容量和持久化策略(RDB / AOF)。
面试应答要点:存储成本是 Checkpoint 机制必须面对的 trade-off,不是「有了 Checkpoint 就高枕无忧」。
要能说出「对于长会话,我会设置最大版本数限制或定期清理策略」这种具体的工程判断。
6.2 并发写入冲突:多实例同时写同一个 thread_id
在多实例部署场景下,如果两个 Pod 同时处理同一个用户的请求,且都持有相同的 thread_id,Checkpoint 写入会产生竞态条件:后写入的版本覆盖先写入的版本,导致其中一个实例的中间状态丢失。
LangGraph 本身不处理并发写入冲突(这是应用层的职责),解决方案通常是:
-
在应用层做 thread_id 的路由:同一个 thread_id 只路由到同一个 Pod,避免并发
-
在 Redis 层加分布式锁,保证同一 thread_id 同时只有一个写入者
-
接受最终一致:允许短暂的版本覆盖,用业务层的补偿逻辑处理极端情况
面试应答要点:能指出「并发写入冲突」这个问题,本身就说明你有生产环境的思考。更好的答案是直接给出三选一:路由、锁、或最终一致,并说明取舍理由。
6.3 跨 thread 状态泄露风险
如果 Checkpoint 配置错误(比如用了全局共享的 thread_id),不同用户的会话状态可能互相污染。
这个场景在开发阶段容易被忽略——在本地用 MemorySaver 跑通一切,部署到生产后因为多实例竞争同一个全局 key,用户的聊天记录出现了串话。
这是一个严重的 Product 问题,也是一个容易被候选人在面试里轻描淡写的坑。
6.4 Redis 不可用时的降级策略
生产环境里,Redis 集群可能因为网络抖动、节点宕机或运维变更而短暂不可用。CheckpointSaver 在 Redis 超时后的行为直接决定了 Agent 的降级质量。
推荐的降级路径:
try:
# 优先写 Redis
saver = RedisSaver(redis_client)
except redis.exceptions.ConnectionError as e:
# 降级到 MemorySaver,同时打告警
logger.warning(f"Redis unavailable, falling back to MemorySaver: {e}")
alert.send("checkpoint-degraded", thread_id=thread_id)
saver = MemorySaver()
降级到 MemorySaver 意味着当前进程重启后,Checkpoint 数据仍然会丢失——这只是「不完全的服务降级」,而不是「优雅的容错」。
更完整的方案需要在降级期间对用户透明(暂停需要 Checkpoint 的功能)或者把降级事件写进监控大盘。

Redis 挂了、降级到内存、重启又丢了——连环炸
参考文献
延伸入口
- 原文归档:tobemagic.github.io/ai-magician…
- 公众号:计算机魔术师

