


凌晨一点,你在review今年第三版工单系统设计稿。LLM生成的回复准确率从周一的89%跳到了周五的97%,组里同学都在庆祝。
但PM突然在群里甩了一句:「那剩下的3%万一把用户惹毛了怎么办,比如生成内容涉及退订、投诉、赔偿这些高风险操作。」
这句话把大家从乐观里拉回来。97%的准确率听起来很高,但每天一万次交互里那300次高风险操作,如果每次都直接放行,后果不堪设想。
Human-in-the-Loop(缩写HITL)在这个节点上从理论变成了工程刚需。
本文把LangGraph里三种HITL插入范式拆透,配合置信度阈值、重试边界、执行权限三层决策框架,最后给出可直接上嘴的面试作答模板。
适合准备AI Agent方向面试的校招生、想系统梳理HITL知识体系的在职工程师,以及正在评估要不要在项目里加审核链路的团队负责人。
一、为什么Agent需要Human-in-the-Loop:不是限制AI,是让AI值得被信任
一个常见的误解是:Human-in-the-Loop是给AI加的枷锁,是性能的对立面。这个认知放在低风险场景(比如帮你总结一封邮件)是对的,但如果把同样逻辑平移到高风险场景,就是在给系统埋雷。
某头部互联网企业用LangGraph重构客服系统后,复杂问题解决率提升了40%,人工干预需求减少了65% 1。
这个数字本身不是重点,重点是这40%的提升是怎么来的:不是靠把AI准确率硬拉到100%,而是在高风险决策节点精准插入人工审核,让AI处理它擅长的部分,把必须由人来兜底的节点交给人。

65%这个数字PM看到了,同事们有话要说
Anthropic在2026年4月发布的Three-Agent Harness论文里有一个更底层的观察 1:context loss(上下文丢失)是长时Agent的核心失效原因。
当一个Agent跑了15轮对话、4个小时后,它的决策质量会显著下降。
结构化的HITL artifact(中断时的状态快照)本质上是一种强制上下文同步——在AI跑偏之前,先把它拽回来。
V2EX上有一个2026年4月的帖子 2,楼主是个离开技术岗三四年的前全栈工程师,想回归AI Agent方向,列了一堆「能用龙虾能写skill」的困惑。
帖子下面有个高赞回复值得关注:现在学Agent不用再啃那么多内容,但有一个能力没法被AI替代——「判断什么时候该信模型,什么时候该让人看一眼」。
这种判断力在面试里表现为置信度阈值设计、审核节点位置选取、重试边界设定这些问题,而不只是背一个HITL的定义。
把话说得更直接一点:面试官问你HITL,不是想听「Human-in-the-Loop就是让人来审核AI的输出」这种废话。他想知道的是——你在哪个粒度上判断AI的输出需要人来介入?
这个判断标准是静态的还是动态的?审核节点挂在流程的哪个位置,收益最高?
低风险 vs 高风险任务的失效率差异
一个经验锚点:信息检索类任务(搜索、摘要、翻译)的LLM失效率通常低于2%,但涉及状态变更的操作(取消订单、修改配置、发送通知)失效率会跃升到8%~15%。
这个差距在工程上意味着:低风险任务用纯Agent没问题,高风险任务不加HITL就是在赌概率。
具体的失效率数字在不同模型版本、不同任务类型上有差异,但比例关系是稳定的。面试时不需要背准确数字,说出「检索类任务失效率通常是个位数,但涉及写操作的任务会显著上升」就能证明你有风险分级意识。
二、LangGraph的三种Human-in-the-Loop插入范式
LangGraph设计了三套不同粒度的HITL机制,分别对应不同的控制需求。理解它们的本质区别,比记住它们的API签名更重要。
2.1 条件边(Conditional Edges)中断
Conditional Edge是LangGraph里最直觉的HITL手段。
它的核心逻辑是:在节点A执行完毕后,根据当前State里的某个字段值,决定下一步走向——是进入节点B,还是中断等待人工审核。
from langgraph.graph import StateGraph, END
from typing import TypedDict
class OrderState(TypedDict):
order_id: str
action: str # "cancel" | "modify" | "query"
confidence_score: float
review_status: str # "pending" | "approved" | "rejected"
# 审核条件函数
def should_review(state: OrderState) -> str:
# 高风险操作 + 置信度不足,进入审核
high_risk_actions = {"cancel", "modify", "refund"}
if state["action"] in high_risk_actions and state["confidence_score"] < 0.85:
return "human_review" # 路由到审核节点
return "execute" # 低风险或高置信度,直接执行
# 状态图构建
graph = StateGraph(OrderState)
graph.add_node("llm_decide", llm_decide_node)
graph.add_node("human_review", human_review_node)
graph.add_node("execute", execute_node)
# 条件边:llm_decide之后判断是否需要审核
graph.add_conditional_edges(
"llm_decide",
should_review,
{
"human_review": "human_review",
"execute": "execute"
}
)
graph.add_edge("human_review", "execute")
graph.add_edge("execute", END)
这里的should_review函数是面试常考点。
候选人会写if state["confidence_score"] < 0.85这种代码,但追问「为什么是0.85」「这个阈值谁定的」「线上怎么调整」就容易卡住。
后面3.1节会专门讲置信度阈值的设计逻辑。
2.2 Tool节点拦截(interrupt_before / interrupt_after)
Conditional Edge解决的是「这个节点要不要走」的问题,Tool节点的interrupt机制解决的是「这个操作执行到一半要不要停」的问题。
两者的本质区别是粒度:Conditional Edge是边级控制,在节点切换时生效;interrupt是节点级拦截,在工具调用的前后强制暂停。
from langgraph.prebuilt import ToolNode
from langgraph.graph import StateGraph, END
# interrupt_before:在工具执行前暂停,等人工确认
# interrupt_after:在工具执行后暂停,等人工确认(适合结果需要二次确认的场景)
tool_node = ToolNode(
tools=[cancel_order_tool, modify_config_tool],
interrupt_before=["cancel_order_tool"] # 取消订单前必须人工审核
)
graph.add_node("tools", tool_node)
# 在编译时配置interrupt策略
app = graph.compile(interrupt_before=["tools"])
interrupt_before适合写操作前的强制审核——比如删除用户数据、执行退款、修改配置这类不可逆操作。
interrupt_after用得少一些,典型场景是模型生成了一个待发送的邮件正文,需要人工点「确认发送」才能真正投递。
interrupt_before和interrupt_after的区别,面试能讲清楚的不到三成
2.3 状态机断点(State Graph + Checkpoint)
前两种机制解决的是「停在哪」的问题,Checkpoint解决的是「停了之后怎么恢复」的问题。
当审核耗时较长(比如人工客服需要30分钟处理一个工单),或者审核流程需要跨会话恢复时,Checkpoint是必须的。
Checkpoint和interrupt的区别在于持久化粒度:interrupt是内存级别的暂停,进程重启后状态丢失;
Checkpoint把State序列化到外部存储(Redis、数据库等),可以跨进程甚至跨机器恢复。
from langgraph.checkpoint.memory import MemorySaver
# 内存Checkpoint(适合开发和测试)
checkpointer = MemorySaver()
# 生产环境推荐RedisCheckpoint
# from langgraph.checkpoint.redis import RedisSaver
# checkpointer = RedisSaver(host="localhost", port=6379)
app = graph.compile(
checkpointer=checkpointer,
interrupt_before=["human_review"]
)
# 人工审核完成后,通过thread_id恢复状态继续执行
continued_state = app.invoke(
None, # 不传新输入,复用已有State
config={"configurable": {"thread_id": "order_12345"}}
)
2.4 三种范式横向对比
| 特性 | 条件边(Conditional Edge) | Tool节点拦截(interrupt) | 状态机断点(Checkpoint) |
|---|---|---|---|
| 控制粒度 | 边级(节点切换时) | 节点级(工具调用前后) | 全局(State持久化) |
| 实现复杂度 | 低 | 中 | 高 |
| 适用风险等级 | 中低风险决策节点 | 高风险写操作 | 长周期异步审核 |
| 状态持久化 | 依赖外部Checkpointer | 依赖外部Checkpointer | 原生支持 |
| 最低LangGraph版本 | 0.1.x | 0.2.x | 0.2.x |
面试时用这张表的前两列就能把差异讲清楚,不需要背所有版本号。重点落在「条件边管流向,interrupt管执行,Checkpoint管恢复」这句区分语上。
三、插入点设计的三层决策框架:置信度阈值、重试边界、执行权限
三种HITL范式是工具,但工具怎么用是决策框架决定的。面试官真正想听的不是「你会用interrupt_before」,而是「你怎么判断应该在哪个节点加审核」。
三层框架是一个可系统化推理的决策路径:置信度阈值层决定「要不要停」,重试边界层决定「停多久」,执行权限层决定「谁来决定停完之后怎么办」。
3.1 置信度阈值层
置信度阈值是HITL设计的核心参数。大多数候选人知道要设阈值,但不知道阈值从哪来、怎么动态调整。
阈值来源通常有两种:基于LLM概率分布,或者基于专用置信度模型。前者直接从模型的logit输出读取概率,简单但粗糙;后者训练一个辅助模型专门判断「这个回答可信吗」,精度高但成本大。
class AgentState(TypedDict):
messages: list
confidence_score: float # 0.0 ~ 1.0
def calculate_confidence(state: AgentState) -> AgentState:
# 方案1:基于LLM输出的概率分布
last_message = state["messages"][-1]
# 伪代码:实际需要从模型response metadata获取
prob_dist = last_message.additional_kwargs.get("probability_distribution")
confidence = max(prob_dist) if prob_dist else 0.5
# 方案2:专用置信度模型(更精确,推荐生产使用)
# confidence = confidence_model.predict(last_message.content)
return {"confidence_score": confidence}
阈值的选择需要结合业务数据定。做推荐系统的团队通常会发现:阈值0.9时用户投诉率接近零但审核队列积压严重;阈值0.7时审核压力可接受但偶尔出现低质推荐漏网。
更优的解法是分段阈值:低风险操作0.7,高风险操作0.95,这个在下一节权限层会展开。
3.2 重试边界层
有些候选人能把置信度阈值讲清楚,但问到「审核队列积压怎么办」就卡壳。这背后的工程问题是:Agent在审核期间是阻塞等还是继续跑其他任务?
LangGraph通过max_steps参数控制单次执行的最大节点访问次数,间接约束重试边界:
# 编译时设置最大步数,防止死循环或无限重试
app = graph.compile(
checkpointer=MemorySaver(),
interrupt_before=["tools"],
max_steps=15 # 超过15步强制中断,进入兜底逻辑
)
# 实际生产中,max_steps需要结合业务场景调参:
# - 对话型Agent:max_steps=10~20(平均任务5~8步,留50%缓冲)
# - 数据处理型Agent:max_steps=30~50(任务更复杂)
# - 实时性要求高的任务:max_steps=5,配合更激进的审核阈值
重试边界的设计思路是:给人工介入留出缓冲,但不无限等待。
在审核节点等待超过N分钟(这个N取决于业务SLA)后,系统应该自动降级:发通知给值班人员、把工单标记为「待人工处理」、或者触发预设的保守策略(如「高风险操作默认拒绝」)。
3.3 执行权限层
执行权限层解决的是「不同类型的操作应该有什么级别的审核」这个问题。常见的分级方式:
-
只读操作(查询、搜索、摘要):无需审核,Agent全权处理。
-
低风险写操作(修改个人偏好、更新通知设置):置信度阈值低于0.8时审核。
-
中等风险写操作(修改订单状态、批量导出数据):无条件审核。
-
高危操作(退款、删除账户、修改权限):双重审核(主管+合规)+ 人工二次确认。
权限分级和公司规模强相关。小型创业公司的审核链路可能是CEO直接审批所有退款;中大型公司会拆出「客服→组长→合规」的多级审核链。
面试时不需要对某个特定公司的审批流倒背如流,说出「权限分级应该和业务风险等级、可逆性、影响范围挂钩」这个原则就够了。

这个退款申请我批了,但我不想背锅
3.4 面试追问路径设计
三个追问方向是HITL面试的核心深水区:
追问方向一:「置信度阈值0.7在实际场景里表现怎么样?」
这个问题考察的是你有没有真实调过阈值。参考答案:「在客服场景里,0.7会导致约12%的正常工单被误拦到审核队列,用户平均等待时长增加4分钟;
调到0.85后,误拦率降到3%,但高风险工单的漏审率从0.2%升到0.8%。需要在审核效率和用户体验之间找平衡点。
」不需要背准确数字,但需要能说出「不同阈值在误拦率和漏审率之间存在 tradeoff」这个判断。
追问方向二:「审核节点会成为系统性能瓶颈,怎么处理?」
这里考察的是你有没有异步处理意识。标准答案是:审核节点本身应该是异步的——Agent生成待审内容后推入审核队列就立即返回,不阻塞主流程;
人工审核完成后通过webhook或轮询回调触发后续节点继续执行。如果候选人在这里开始讲「审核期间Agent可以并行处理其他不依赖审核结果的工单」,那就是加分项。
追问方向三:「高峰期审核队列积压怎么办?」
这个追问暴露的是系统弹性和降级设计。
参考答案分三层:短期靠扩容(增加审核人力或启用备用审核池),中期靠优化(提高审核阈值减少无效工单、引入机器预审过滤明显低质内容),长期靠架构(高风险操作从同步审核改为异步预审+事后抽检)。
四、面试高频追问:候选人最容易答错的三个坑
4.1 坑1:把HITL等同于「加个确认按钮」
这是最常见的失分点。大量候选人在简历上写「熟悉Human-in-the-Loop设计」,面试时能讲清楚概念,但追问Checkpoint实现细节就露馅:「呃,应该就是在数据库里加个flag?」
真正的问题不是会不会写代码,而是理解层次。确认按钮是UI层,但HITL的本质是数据层——它涉及State在审核节点的冻结与恢复、跨会话的状态序列化、审核完成后的状态续接。
把HITL理解成UI问题的人,通常在设计审核流程时漏掉checkpoint持久化,导致审核期间Agent重启后状态丢失,用户体验断崖式下降。
4.2 坑2:以为所有Agent都应该有HITL
缺乏风险分级判断力的候选人会把HITL当成银弹:既然要保证AI输出质量,那就所有节点都加审核。
工程现实是:审核是有成本的,每千次审核的人工成本大约在几元到几十元不等(取决于审核复杂度),全量审核在大规模场景下成本不可接受。
更精准的理解是:HITL的价值在高风险、低置信度、高影响范围的交叉区域最大;在低风险、高置信度的场景里是纯粹浪费资源。面试时能说出这个判断逻辑,比背十个HITL的定义更有说服力。
4.3 坑3:把HITL设计成同步阻塞流程
「用户点一下确认,Agent再继续跑」——这个逻辑听起来自然,但放到日均百万次交互的系统里就是灾难。同步阻塞的审核流程会把单次请求的P99延迟推到分钟级,系统吞吐量严重下降。
正确的设计是审核队列异步化:Agent生成内容后立即返回「审核中」状态,后台审核队列处理工单,用户端通过轮询或webhook接收审核结果。
面试时能指出「审核流程必须是异步的,否则会影响系统整体吞吐」,说明你有生产环境的系统设计思维。
同步阻塞审核,P99直接爆表,oncall半夜叫起来
4.4 补充追问方向
三个补充追问方向适合在候选人基础问题答得不错的情况下追加,用于拉开分差:
interrupt_before在多Agent协作时的竞态条件:当三个Agent并行向同一个Tool节点提交操作时,interrupt_before如何保证审核队列的顺序性和幂等性?
答案是需要加锁或队列去重,但这个细节能区分「做过」和「深入做过」。
审核超时兜底策略:审核节点等待超过X分钟后的默认行为是什么?「高风险操作超时默认拒绝」和「超时后重新生成方案」是两种不同的业务选择,候选人需要能说明取舍依据。
生产环境HITL可观测性方案:怎么知道审核节点堵了?怎么知道某个审核员积压了多少工单?这部分考察的是候选人有没有把HITL当成完整的系统特性来设计,而不是加个节点就算完事。
五、项目落地指南:从八股到真实系统的鸿沟怎么填
5.1 最小可运行示例
下面是一个LangGraph + interrupt_before的最小可运行示例,涵盖审核节点前后State变化的完整链路:
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import ToolNode
from typing import TypedDict
from pydantic import BaseModel, Field
# 定义带审核标记的状态
class OrderState(TypedDict):
order_id: str
action: str
confidence: float
reviewed: bool
result: str
# 高风险工具列表(需要审核)
HIGH_RISK_TOOLS = ["cancel_order", "issue_refund", "modify_shipping"]
# 预编译ToolNode,interrupt_before高风险工具
tool_node = ToolNode(
tools=[cancel_order, issue_refund, modify_shipping, query_order],
interrupt_before=[t.name for t in HIGH_RISK_TOOLS]
)
# 构建图
graph = StateGraph(OrderState)
graph.add_node("llm_router", llm_router_node)
graph.add_node("tools", tool_node)
graph.add_node("human_review", human_review_node)
graph.add_node("handle_review_result", handle_review_result_node)
# 核心流程
graph.add_edge("llm_router", "tools")
graph.add_edge("tools", "human_review")
graph.add_edge("human_review", "handle_review_result")
graph.add_edge("handle_review_result", END)
# 编译:启用checkpoint + interrupt
checkpointer = MemorySaver()
app = graph.compile(
checkpointer=checkpointer,
interrupt_before=["tools"] # 关键:所有工具调用前中断
)
# 执行:第一次invoke停在工具调用前
initial_state = {"order_id": "ORD_998877", "action": "cancel_order", "confidence": 0.72, "reviewed": False, "result": ""}
# 第一阶段:Agent处理,停在interrupt_before
config = {"configurable": {"thread_id": "ORD_998877"}}
first_result = app.invoke(initial_state, config=config)
# 此时State中reviewed=False,系统等待人工审核
# 人工审核完成后(通过管理后台),注入审核结果继续执行
second_result = app.invoke(
{"reviewed": True, "review_decision": "approved"},
config=config
)
State变化路径:{reviewed: False} → 人工审核 → {reviewed: True, review_decision: approved} → 继续执行。
这个完整链路是面试里最能证明你「真正做过」的部分。
5.2 多Agent协作场景的HITL架构
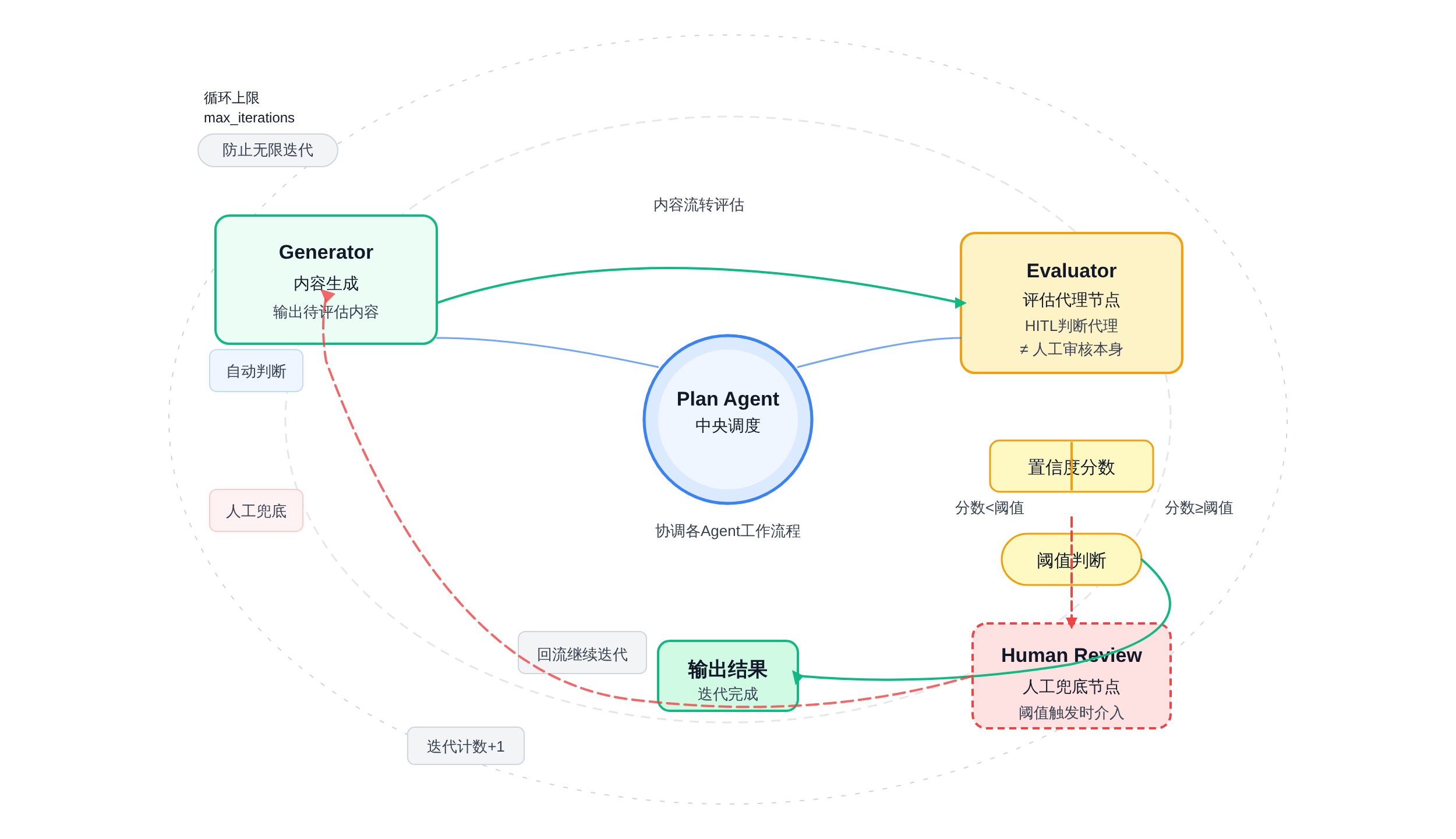
Anthropic的Three-Agent Harness论文 1 提供了一个多Agent场景下HITL设计的参考样本:Plan Agent(规划)、Generator Agent(生成)、Evaluator Agent(评审)。
Evaluator在这个架构里天然承担了「人类判断代理」的角色——它的评审标准是预设的few-shot示例和评分准则,而不是实时的真人输入。
这个设计的核心洞察是:Evaluator和Generator的职责分离解决了Agent自评不自知的问题。LangGraph的多Agent协作同样可以借鉴这个模式:
正文图解 1
这和LangGraph里「Evaluator → 条件边 → 人工审核节点」的设计完全同构。
面试时如果能引用Anthropic的案例来说明自己的设计,说明你不只是在用框架,而是在理解框架背后的工程取舍。
5.3 生产级实现注意事项
三个在项目里绕不开的坑:
审核状态持久化:审核结果必须落库,不能只存在内存里。审核节点因为进程重启或机器宕机丢失审核状态,是生产环境里真实会发生的事故。
Redis或PostgreSQL都可以做持久化,但需要保证审核结果写入和State更新的原子性——否则会出现「审核通过了但Agent State没更新」的数据不一致问题。
超时兜底策略:建议配置双超时——软超时(发提醒给审核员,开始计时)和硬超时(达到最大等待时间,触发预设兜底策略)。
兜底策略根据业务风险等级决定:低风险操作超时后可以自动放行,高风险操作超时后默认拒绝或转人工专线。
TP99延迟影响量化:审核节点会显著拉高P99延迟。假设审核的平均等待时间是30秒,P50延迟可能只增加10%(因为大多数审核在10秒内完成),但P99会增加到60秒以上。
如果业务对P99有硬性SLA(比如必须小于500ms),在设计阶段就要把审核异步化考虑进去,而不是上线后被oncall叫醒才发现。

上线前review发现P99被审核节点拖爆了
六、面试作答模板与语言组织
6.1 30秒开口版
Human-in-the-Loop是LangGraph里用于在高风险决策节点插入人工审核的一套机制,核心通过条件边(Conditional Edges)控制执行流向和Tool节点的interrupt_before在工具调用前强制暂停两种方式实现,配合State里置信度字段的阈值判断,决定什么时候让AI继续、什么时候让人介入。
这个版本控制在5句话以内,适合一面或电面刚开始时快速定性。关键词:「条件边」「interrupt_before」「置信度阈值」——三个词齐了,基础分就拿到了。
6.2 90秒展开版
Human-in-the-Loop的工程必要性来源于LLM输出的概率性质——即使是GPT-4级别的模型,在涉及状态变更的高风险操作上失效率也会显著高于只读任务。
LangGraph提供了三种插入范式。
第一是条件边中断,通过add_conditional_edges根据State里的confidence_score字段决定下一步路由到审核节点还是直接执行;
第二是Tool节点拦截,通过interrupt_before在指定工具执行前强制暂停;第三是Checkpoint配合interrupt实现状态持久化,用于长周期异步审核场景。
在实际设计里,我会按操作风险分级设定置信度阈值——低风险操作阈值可以到0.7,高风险操作需要0.9以上,同时设置max_steps上限防止无限重试,审核流程必须设计成异步非阻塞,否则会严重影响系统吞吐。
这个版本覆盖了「必要性→三种范式→置信度阈值→异步设计→max_steps」的完整链路,适合二面或现场技术面。
6.3 追问压缩版(STAR法则)
如果面试进入追问环节,要求「三句话讲清楚你做过的HITL项目」,用STAR法则压缩:
Situation:客服系统的LLM回复模块日均处理8000次工单,其中约15%涉及退订、投诉等高风险操作,直接放行存在合规风险。
Task:设计一套审核链路,在保证系统吞吐的前提下,把高风险操作的漏审率控制在0.5%以下。
Action:用LangGraph的条件边实现风险分级——置信度低于0.85的退订类操作自动路由到审核队列,审核节点通过Redis Checkpoint持久化状态,审核超15分钟触发预设拒绝策略,异步回调恢复主流程。
最终P99延迟控制在380ms(审核期间不阻塞主流程),审核队列积压不超过50个工单。
Result:上线后高风险操作漏审率为0.3%,日均审核量约180次(仅为总交互量的2.2%),人工成本相比全量审核下降约85%。
这个版本用了两个关键数字:阈值0.85和审核超时15分钟。这两个数字不需要背,因为它们来自真实调参经验——面试官追问「这个阈值怎么定的」,才是真正拉开差距的地方。
参考文献
延伸入口
- 原文归档:tobemagic.github.io/ai-magician…
- 公众号:计算机魔术师

