


Kafka 社区对共享存储的兴趣由来已久:如果所有数据都放在 S3 这样的共享存储上,Broker 就不需要本地磁盘,副本复制可以省掉,跨 AZ 流量费也随之消失。但对象存储的延迟一直让这个想法停留在"理论上很美"的阶段。AWS 最近发布的 S3 Files 改变了这个前提——它给 S3 加上了 NFS 文件系统接口,小文件读取延迟做到了亚毫秒级。于是一个老问题以新的面貌回来了:Kafka 能不能直接跑在 S3 Files 上?
我们在 AutoMQ 从 2023 年起就在解决这个问题——不是把 Kafka 搬到共享文件系统上,而是从存储引擎层重新设计,让 Kafka 真正运行在共享存储架构上。我们是这个领域最早探索用共享文件系统作为存储后端的团队,也是目前唯一做到生产级低延迟的 Diskless Kafka 实现。所以当 S3 Files 出现时,我们自然要评估它的可能性——以及它的边界在哪里。
S3 Files 是什么?
要回答"Kafka 能不能跑在 S3 Files 上",先得理解 S3 Files 到底做了什么。它本质上是 AWS 在 S3 之上加了一层基于 EFS(Elastic File System)的文件系统访问面——你可以通过 NFS 协议把 S3 存储桶挂载到 EC2 实例上,像操作本地文件一样读写,而 S3 始终是数据的 Source of Truth。
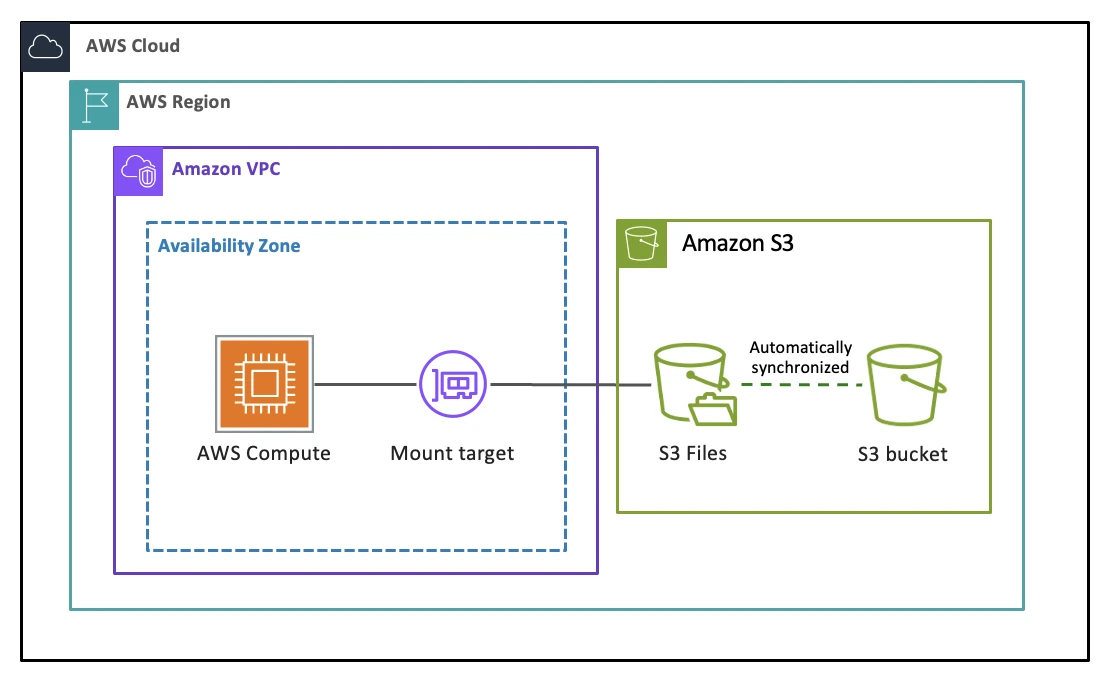
这层访问面的核心设计围绕一个 128 KB 的阈值。小于 128 KB 的文件在首次访问时会被导入 EFS 高性能层,读取延迟可以做到亚毫秒到个位数毫秒;128 KB 及以上的文件则绕过 EFS,通过本地代理直接从 S3 流式读取。写入方向上,所有数据都先落到 EFS 层,再由后台异步批量同步回 S3。换句话说,S3 Files 的优化重点是小文件的低延迟读取,而不是让所有数据都常驻在高性能层。
定价模型进一步印证了这个定位。写入按流量计费 $0.06/GB,最小计费 I/O 为 6 KiB,没有预置容量选项。数据同步到 S3 后不会立刻从 EFS 淘汰,默认驻留 30 天,期间你同时支付 EFS 高性能层存储费($0.30/GB-月)和 S3 存储费用。对于读多写少的场景,这个定价是合理的。但对于持续高吞吐写入的工作负载,写入成本和 EFS 驻留费用会快速累积。
共享存储对 Kafka 的吸引力
理解了 S3 Files 的能力边界,再来看为什么大家想把 Kafka 构建在上面。传统 Apache Kafka® 是为专用服务器加本地磁盘设计的,这套架构搬到云上会产生三个不断叠加的成本问题。
最直接的是副本复制带来的跨 AZ 流量费。Kafka 通过 ISR(In-Sync Replicas)机制保证持久性,每条消息会被复制到两到三个 Broker。在多 AZ 部署中,这种复制产生大量跨 AZ 网络流量——AWS 对跨 AZ 数据传输双向收费,合计 $0.02/GB。一个写入吞吐 500 MB/s、副本因子为 3 的集群,两个 Follower 分布在不同 AZ,每秒产生约 1 GB 的跨 AZ 复制流量,仅这一项就超过 $50,000/月。
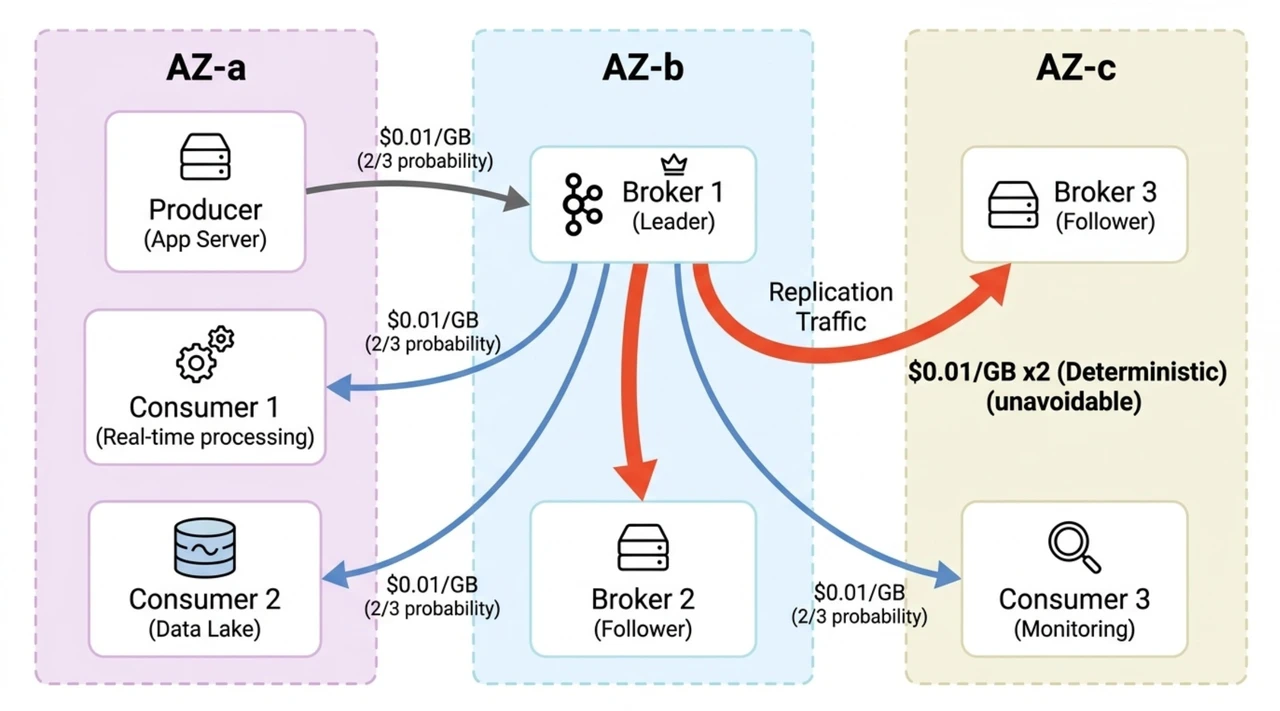
副本复制还带来了第二个问题:存算耦合。每个 Broker 在本地磁盘上管理自己的数据副本,扩展存储就意味着加机器——即使你只需要更多磁盘空间。而且必须按峰值负载加上故障冗余来预留容量,大部分时间都在为闲置资源付费。
存算耦合又进一步放大了运维复杂度。分区重分配需要在 Broker 之间物理搬迁数据,大 Topic 可能耗时数小时。Broker 故障触发漫长的恢复流程。缩容比扩容更难,因为你得先把数据搬走。
如果所有数据都在 S3 这样的共享存储上,这三个问题可以一次性解决:S3 自带 11 个 9 的持久性,不需要副本复制;Broker 变成无状态计算节点,秒级扩缩容;跨 AZ 流量降到接近零。S3 Files 有 NFS 接口、有亚毫秒延迟,看起来正好是连接 Kafka 和共享存储之间的桥梁。但真正尝试搭建这座桥梁时,会遇到几个根本性的问题。
挑战:直接把 Kafka 跑在 S3 Files 上会怎样?
持久性缺口
最符合直觉的做法是把副本因子设为 1——既然 S3 Files 提供了共享的持久化存储,一份数据就够了。问题出在 Kafka 的写入机制上。
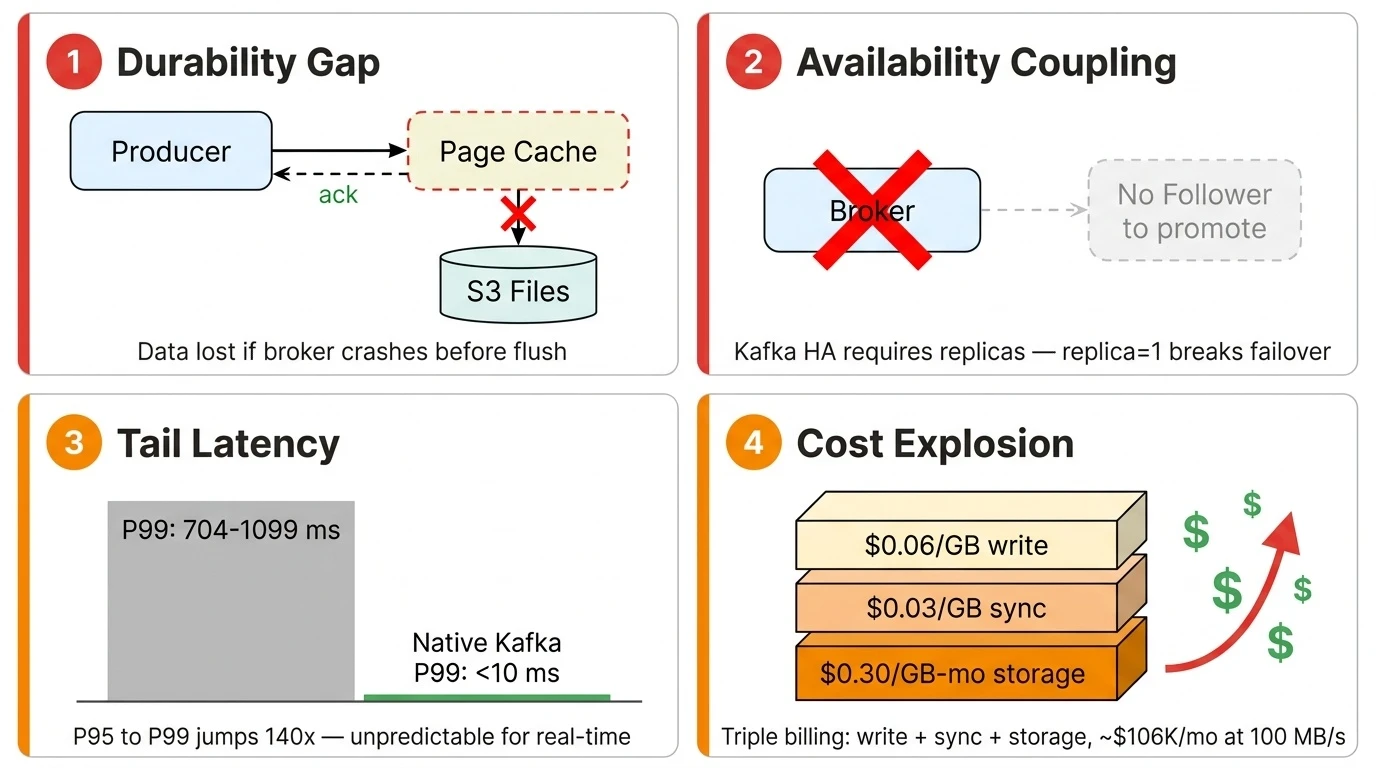
Kafka 是一个异步 I/O 系统。Producer 发送消息并收到 ack 时,数据还在操作系统的 page cache 里,并不一定已经刷到底层存储。这是 Kafka 高吞吐的设计基础——它假设即使 Broker 在刷盘前崩溃,数据仍然安全地存在于 Follower 副本上。但在 replica=1 的 S3 Files 上,这张安全网消失了。Broker 崩溃意味着 page cache 中尚未持久化的数据直接丢失,S3 Files 的 11 个 9 持久性帮不上忙——数据根本还没到达存储层。
要堵住这个缺口,需要改变 Kafka 的写入路径:确保每条被确认的消息在返回 ack 之前就已经持久化。这不是调配置能解决的,这是存储引擎层面的重新设计。
可用性耦合
持久性问题可以通过改造写入路径来解决,但 Kafka 的高可用机制带来了另一个更深层的挑战。
Kafka 的 HA 和多副本设计紧密耦合:Broker 故障时,Controller 将 Follower 副本提升为新 Leader。这个机制的前提是存在 Follower——而 replica=1 意味着没有 Follower 可以提升。你需要一套完全不同的故障转移逻辑:让新 Broker 直接从共享存储读取数据来接管分区,而不依赖本地副本。Kafka 现有的 HA 设计天然阻止了它利用 S3 Files 内置的可用性保障。
这同样需要架构层面的重新设计——不只是写入路径,还有整个故障恢复和分区所有权的管理方式。
延迟现实
即使解决了持久性和可用性问题,延迟仍然是一道坎。S3 Files 宣传的亚毫秒延迟针对的是 EFS 高性能层上的小文件读取,而 Kafka 的核心工作负载是高吞吐的持续顺序写入——这两者的 I/O 模式完全不同。
社区已经有人在 S3 Files 上跑过 Kafka benchmark,数据很说明问题:
| 指标 | 1 KiB 最大吞吐 | 10 KiB 最大吞吐 | 10 KiB 调优后 |
|---|---|---|---|
| 平均延迟 | 31.86 ms | 21.86 ms | 21.38 ms |
| P50 | 0 ms | 1 ms | 1 ms |
| P95 | 12 ms | 5 ms | 13 ms |
| P99 | 1,099 ms | 704 ms | 801 ms |
| P99.9 | 3,173 ms | 2,959 ms | 2,051 ms |
| 最大值 | 9,904 ms | 4,152 ms | 5,139 ms |
中位数和 P95 看起来还行——P95 只有 5-13ms,和原生 Kafka 差距不大。但从 P95 到 P99 出现了断崖式跳跃:5ms 直接飙到 704ms,延迟放大了 140 倍。这意味着每一百次请求就有一次要等超过一秒。对于实时流处理场景——风控、实时大屏、事件驱动微服务——这种不可预测的尾延迟是不可接受的。S3 Files 并没有彻底解决共享存储的低延迟问题,相比本地磁盘上的 Kafka 仍然有明显的延迟牺牲。
成本结构
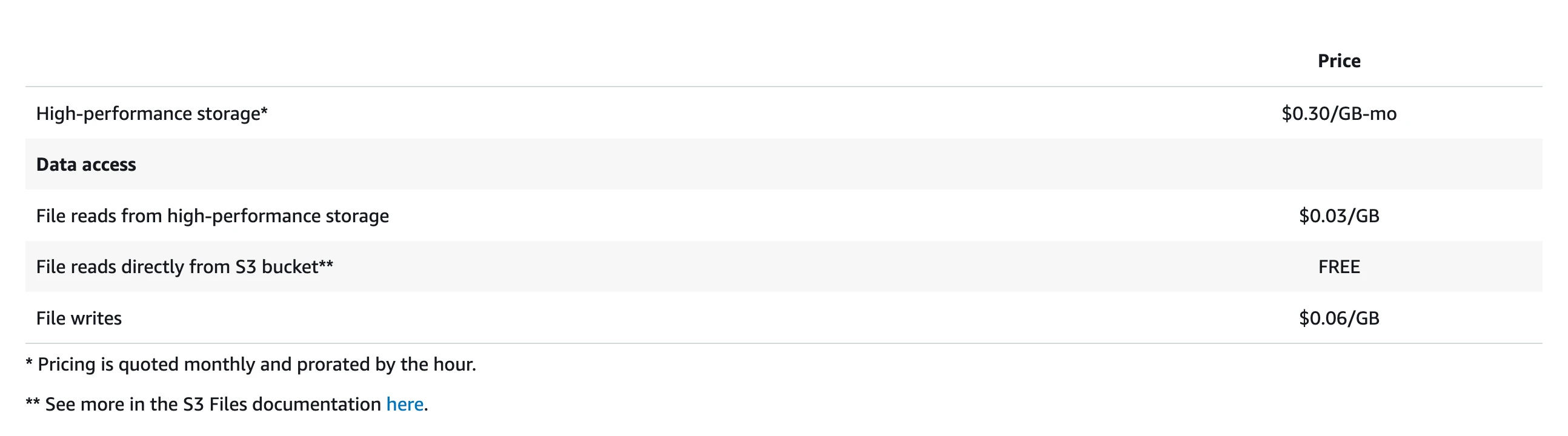
延迟之外,S3 Files 的定价模型对 Kafka 也不友好。S3 Files 采用按流量计费——写入 $0.06/GB,小文件读取 $0.03/GB,没有预置容量选项。这和 S3 的按 API 请求次数计费是完全不同的模型。Kafka 的工作负载特征是写入和读取都需要走高性能层:Producer 写入的数据落到 EFS 高性能层,Consumer 做 Tailing Read(消费最新数据)也从高性能层读取。两端都按流量计费,成本随吞吐量线性增长。写入端还有双重流量费——数据先写入 EFS($0.06/GB),再由后台同步回 S3($0.03/GB),Kafka 的所有数据都需要同步回 S3,这笔同步费逃不掉。更隐蔽的是 EFS 高性能层的存储驻留费:$0.30/GB-月,是 S3 Standard 存储费的 13 倍,数据默认驻留 30 天才淘汰。
算一笔具体的账。一个 100 MB/s 持续写入的集群,假设消费端吞吐和写入相当(1x fan-out,即一个 Consumer Group),每天写入和读取各约 8,400 GB(100 MB/s × 86,400 秒):
| 费用项 | 计算 | 日费用 |
|---|---|---|
| 写入流量费 | 8,400 GB × $0.06/GB | $504 |
| 写入同步费(导出回 S3) | 8,400 GB × $0.03/GB | $252 |
| Tailing Read 流量费 | 8,400 GB × $0.03/GB | $252 |
| 日流量费合计 | $1,008 | |
| EFS 存储驻留费(30 天累积) | 252,000 GB × $0.30/GB-月 | $75,600/月 |
| 月总计(流量 + 存储驻留) | $1,008 × 30 + $75,600 | ~$106,000/月 |
这还是 1x fan-out 的保守估算。如果有多个 Consumer Group(在 Kafka 场景中很常见),Tailing Read 的流量费会成倍增长。2x fan-out 下月成本就超过 $113,000,3x 超过 $120,000。而且这还没算 S3 本身的存储费。S3 Files 的定价模型是为"读多写少、活跃工作集小"的场景设计的——Kafka 恰好相反:持续高吞吐写入,所有数据都是"活跃"的,读取端也是持续高吞吐。
这些挑战加在一起意味着什么?
持久性缺口要求重新设计写入路径。可用性耦合要求重新设计故障转移机制。延迟问题要求在对象存储之前加一层高性能写入缓冲。成本问题要求对小写入进行攒批优化。把这四项加在一起,你实际上需要的是一个全新的 Kafka 存储引擎——而这正是 AutoMQ 从 2023 年就在构建的东西。
AutoMQ:已经被验证的 Shared Storage 架构
AutoMQ 的架构分为两层。S3 是主存储层,所有数据最终都持久化在 S3 上——这是和 Tiered Storage 的根本区别。Tiered Storage 仍然把热数据放在本地磁盘上,S3 只存冷数据;而 AutoMQ 让 S3 成为唯一的 Single Source of Truth,Broker 上没有任何持久化状态(关于两者的详细对比,可以参考这篇文章)。
但直接把每条消息都写到 S3 有两个问题:S3 的写入延迟太高,而且 S3 API 调用是按次计费的——每条消息一次 PUT 请求,API 成本会随消息数线性爆炸。这就是 WAL(Write-Ahead Log)层存在的意义。
WAL 是一块固定大小的高性能存储空间,充当 S3 前面的写入缓冲。所有 Produce 请求先写入 WAL,使用 Direct IO 绕过 page cache,在返回 ack 之前就保证数据持久化——这直接堵住了上面说的持久性缺口。然后 WAL 中的数据被异步压缩、攒批,再批量上传到 S3。这个攒批过程至关重要:不是每条消息一次 S3 PUT,而是每批数千条消息一次 PUT,S3 API 成本从随消息数增长变成了随吞吐量增长,降低了一到两个数量级。
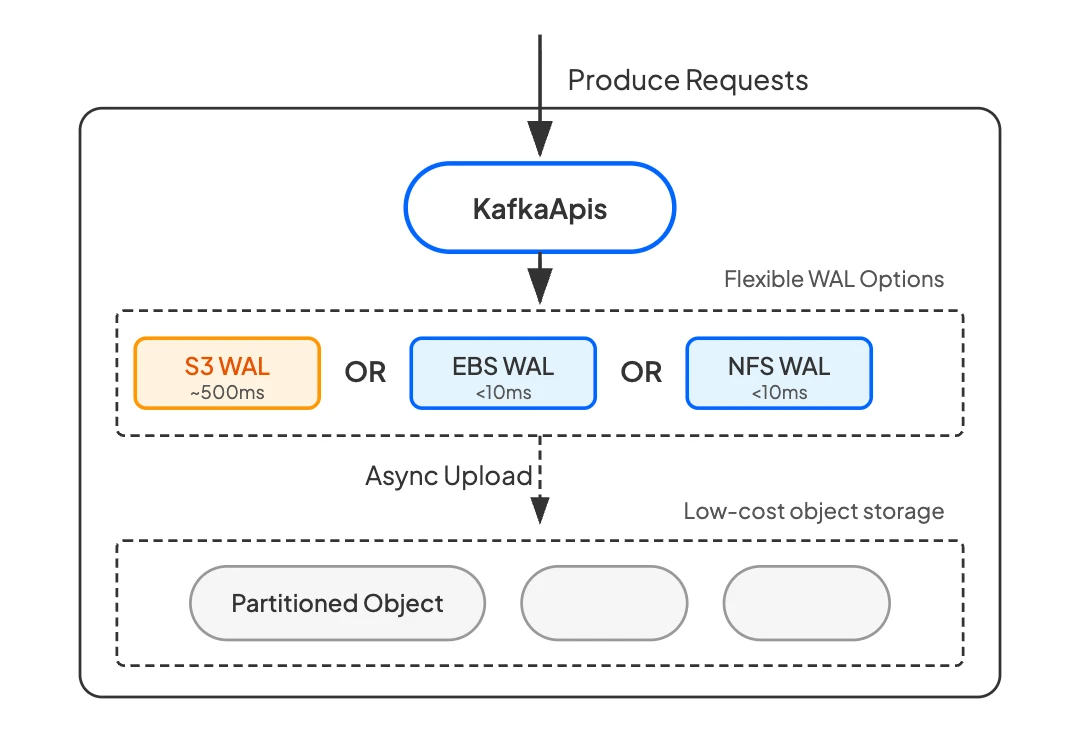
WAL 带来的另一个关键好处是让用户可以在延迟和成本之间做 trade-off。WAL 层是可插拔的,不同的云存储后端对应不同的延迟和成本特征:EBS/Regional EBS WAL 提供亚毫秒延迟,NFS WAL(AWS 上基于 FSx for NetApp ONTAP)提供平均 6ms、P99 约 13ms 的写入延迟。Producer 的体验和原生 Kafka 没有区别。
而且 WAL 的成本很低。它只需要一小块固定大小的存储空间——不是存全量数据,只是一个循环写入的缓冲区。对于大部分云存储的定价模型来说,这非常友好:每月几美元到几十美元的 WAL 支出,就能换来低延迟持久化、S3 API 成本优化、以及真正的无状态 Broker。
因为所有持久化状态都在 WAL 和 S3 中,Broker 是真正无状态的。一个 Broker 故障时,另一个 Broker 在秒级内接管分区映射,不需要数据迁移,Zero RPO——这解决了可用性耦合的问题。
最终效果是 Kafka on S3 Files 所承诺的一切——零跨 AZ 流量、无副本复制、弹性无状态 Broker——但没有持久性缺口、秒级尾延迟和高昂的流量成本。
S3 Files 作为 WAL:技术上可行,经济上还不成熟
既然 AutoMQ 的 WAL 层是可插拔的,S3 Files 能不能作为又一个 WAL 后端?从架构上看,答案是肯定的。S3 Files 提供 NFS 接口,底层基于 EFS 构建——而 AutoMQ 的 NFS WAL 已经支持 EFS 和 FSx for NetApp ONTAP 作为实现,技术路径是通的。
但当前的定价模型让这个方案的经济账算不过来。Kafka 不是一个轻量级的应用层服务,它是数据密集型的基础设施——AutoMQ 的一些生产客户集群吞吐超过 1 GiB/s,7×24 小时不间断写入。在这个量级下,S3 Files 的纯按量计费模型会产生惊人的费用。
以一个相对温和的工作负载为例——写入吞吐 100 MB/s、平均消息大小 4 KiB:
| 维度 | EFS(作为 WAL) | S3 Files(作为 WAL) |
|---|---|---|
| 写入定价 | EFS 弹性吞吐计费 | $0.06/GB 写入 + $0.03/GB 同步回 S3 |
| 高性能存储驻留费 | 包含在 EFS 定价中 | $0.30/GB-月(默认驻留 30 天) |
| 月成本估算(100 MB/s) | ~$15,500 | ~$100,000(流量费 + 存储驻留费) |
100 MB/s 已经是一个保守的数字了。如果换成 1 GiB/s 的生产集群,S3 Files 的月成本会突破百万美元——流量费和 EFS 存储驻留费都随吞吐量线性增长。核心问题在于 S3 Files 的定价模型是为"读多写少、活跃工作集小"的场景设计的,而 Kafka 恰好相反:持续高吞吐写入,所有数据都是"活跃"的。S3 Files 作为 WAL 的开销远高于直接使用 EFS,而延迟上并没有优势。
不过云存储的定价在持续演进。如果 AWS 为 S3 Files 引入预置吞吐模型或降低最小计费 I/O,这笔账可能很快就会变。AutoMQ 的架构已经为那一天做好了准备。
一套架构,适配所有云存储
S3 Files 的故事其实揭示了一个更大的趋势:云存储在加速分化。AWS 在过去两年推出了 S3 Express One Zone(个位数毫秒延迟的 S3)、S3 Files(NFS over S3)、以及对 EFS 和 FSx for NetApp ONTAP 的持续改进。GCP 和 Azure 也在各自的存储服务上走着类似的路线。每种存储服务针对不同的访问模式、成本模型和持久性保障做了优化。
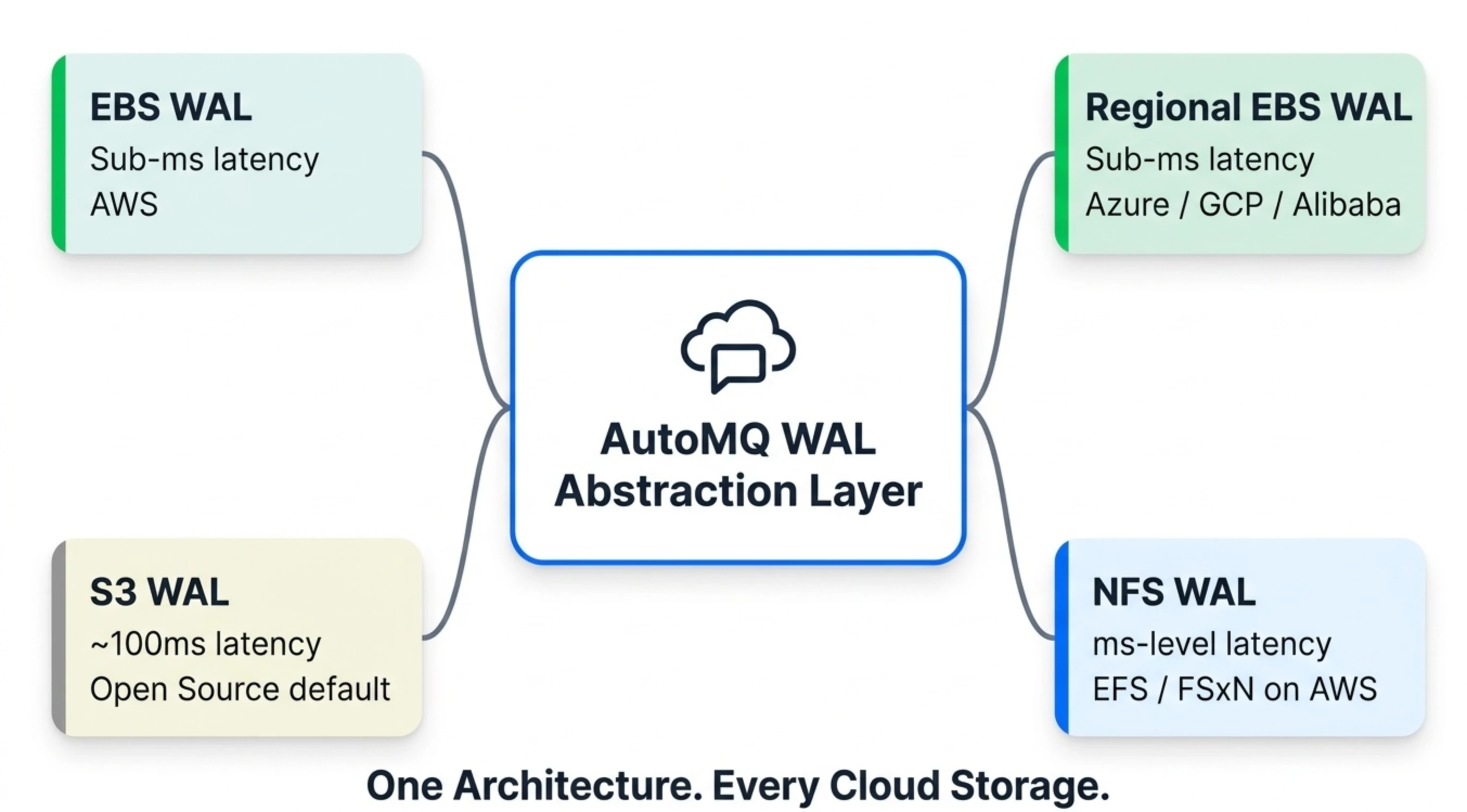
AutoMQ 的可插拔 WAL 架构意味着我们不需要押注某一个赢家——每一次云存储创新都会成为 WAL 后端菜单上的一个新选项:
| WAL 后端 | 延迟 | 多 AZ | 成本 | 适合场景 |
|---|---|---|---|---|
| EBS WAL | 亚毫秒 | 单 AZ(多副本) | 低 | AWS 上所有 Kafka 工作负载 |
| Regional EBS WAL | 亚毫秒 | 多 AZ(多副本) | 低 | Azure / GCP / 阿里云上的生产环境(推荐) |
| S3 WAL | 百毫秒级 | 多 AZ | 低 | 延迟不敏感场景(日志、监控),开源版默认 |
| NFS WAL(AWS 上使用 EFS / FSxN) | 毫秒级 | 多 AZ | 中等 | AWS 上的低延迟场景(核心交易撮合等) |
用户不需要被锁定在某一种存储方案上,而是可以根据自己的延迟要求和成本预算自由选择——并且随着需求变化或云定价演进随时切换。在 AWS 上,NFS WAL 已经支持 EFS 和 FSx for NetApp ONTAP 两种实现;在 Azure 和 GCP 上,Regional EBS WAL 利用各自的多 AZ 块存储提供亚毫秒延迟。让这一切成为可能的 WAL 抽象层,从第一天起就是这么设计的。
回到最初的问题
Kafka 构建在 S3 Files 上,是个好主意吗?如果说的是把原生 Kafka 直接挂载上去——不是。Kafka 的异步 I/O、基于副本的 HA、对本地存储的假设,这些设计决策会让你回到原点:还是要管副本、管故障转移、管容量规划。共享存储就在那里,但 Kafka 的架构用不上。
但 Kafka 向 Shared Storage 架构演进的方向是确定的——经济账和运维收益太有说服力了。AutoMQ 基于 WAL 的 Shared Storage 架构已经交付了这个承诺,而且每当云存储向前迈进一步,可插拔的 WAL 层就把这次创新变成用户的一个新选项。一套架构,适配所有云存储。
