

用 Locust 压测一个网站,记录一下学习过程
最近想给自己的一个小项目做个压力测试,看看能扛多少并发。之前一直听人提过 Locust,说是用 Python 写脚本就能压测,比 GUI 工具轻量,正好借这个机会学一下。
花了半天摸索下来,感觉这个工具确实挺顺手的,踩过几个坑,也有一些心得,干脆整理成一篇博客,一方面当自己的学习笔记,另一方面也给同样想入门的朋友一个参考。
为什么选 Locust
说实话,选 Locust 的理由很简单:它用 Python 写测试脚本,我熟。
性能测试工具其实挺多的,JMeter、k6、wrk 之类的我都听过,但要么是 GUI 点来点去不方便版本控制,要么是要学一门新的脚本语言。Locust 好处是脚本就是一个普通的 Python 文件,你平时怎么写 Python 就怎么写,条件判断、循环、读文件、调库,该怎么来怎么来。
对我这种不是专业做性能测试、只是偶尔想压一下自己服务的开发者来说,这种"门槛低、够用就好"的工具最合适。
这篇会写什么
就按我自己学的顺序来:
先用 uv 搭好环境、跑通第一个最简单的测试,看看 Locust 长什么样子;然后记录一下我在真实压测里用到的几个常见场景——登录、权重、参数化、自定义断言;再聊聊单机压测不够用的时候怎么搞分布式。
最后会列几个我自己踩过的坑,都是当时卡了好一会儿才绕出来的,提前说一下省得你也走弯路。
文章里的代码都是我自己跑通过的,可以直接复制运行。如果有写错的地方,欢迎在评论区指正——毕竟我自己也才学了没多久。
好,开始。
一、5 分钟跑通第一个测试
环境准备(用 uv)
我用 uv 来管 Python 环境。之前单独写过一篇 uv 的介绍(链接),这里就不展开讲了,只给命令:
# 创建项目目录
mkdir locust-demo && cd locust-demo
# 初始化 uv 项目
uv init
# 添加 locust 依赖
uv add locust
三条命令搞定。uv 会自动处理虚拟环境、Python 版本(Locust 目前要求 Python 3.10+),你不需要手动 python -m venv 再 source activate 那一套。
如果你还是习惯 pip,等价命令是:
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install locust
装完之后确认一下:
uv run locust -V
# 或者 pip 方式:locust -V
能打印出版本号就说明装好了。
三个核心概念
在写第一行代码之前,先看一下 Locust 的核心概念,用下面这张图就能理解:
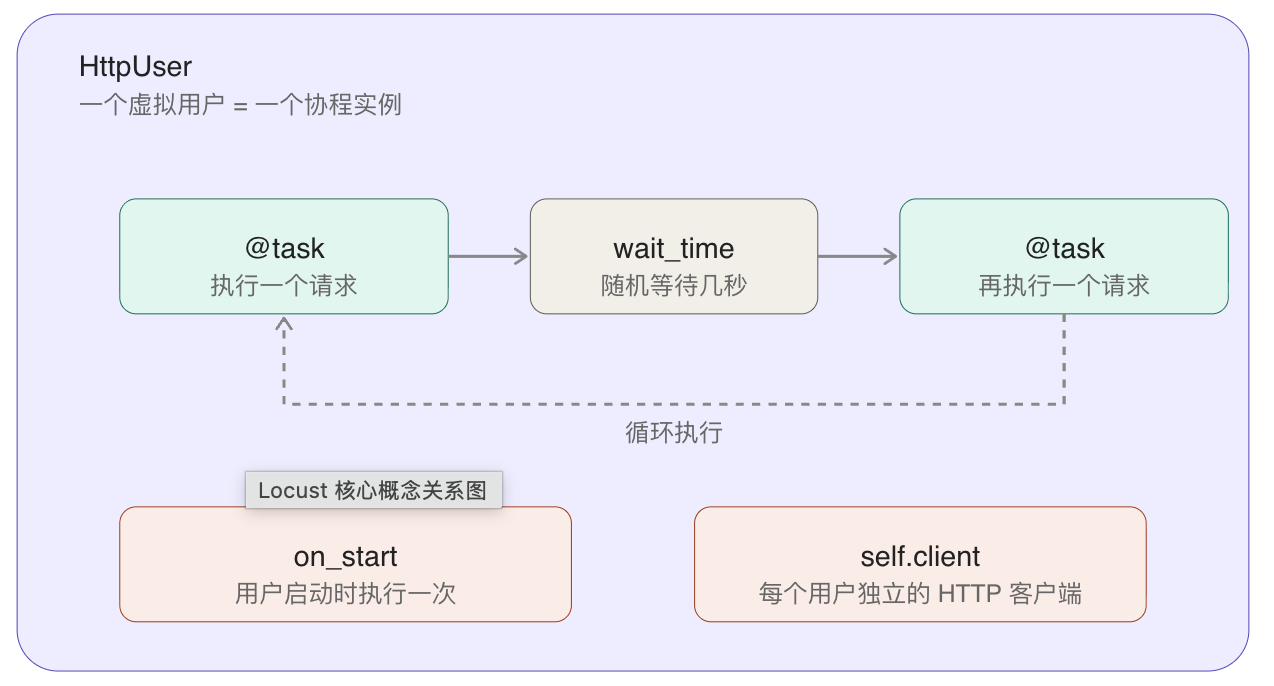
简单说就是:
- HttpUser 代表一个模拟用户。每个虚拟用户都是这个类的一个实例,Locust 会在后台用协程(greenlet)给你开一堆这样的实例出来,每个都独立跑自己的任务。
- @task 装饰的方法就是这个用户会执行的动作。Locust 会在这些 task 里随机挑一个执行,执行完等一会儿,再挑一个,循环往复。
- wait_time 是每次 task 执行完之后的等待时间。它模拟的是"真实用户不会连续不停地点击",把它设成 0 虽然看起来压力更大,但其实不真实,后面会专门讲这个坑。
- on_start 是每个虚拟用户启动时执行一次的钩子,用来做登录这种一次性的初始化。
- self.client 是 Locust 自带的 HTTP 客户端,每个用户独立,接口跟
requests库几乎一模一样。
第一个 locustfile.py
在项目目录下新建一个 locustfile.py:
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 3)
@task
def get_homepage(self):
self.client.get("/")
@task
def get_headers(self):
self.client.get("/headers")
就这么几行,已经是一个可以跑的压测脚本了。
启动!
uv run locust -f locustfile.py
终端会打印一行:
[INFO] Starting web interface at http://0.0.0.0:8089
浏览器打开 http://localhost:8089,你会看到 Locust 的启动页面,让你填三个参数:
- Number of users:同时模拟的用户数,先填 50 试试
- Ramp up:每秒启动几个用户,填 5(意思是 10 秒内把 50 个用户全部拉起来)
- Host:要压测的目标地址,填
https://httpbin.org(这是一个公开的测试 API)
点 "Start",压测就开始了。
几秒钟后,Statistics 页能看到每个接口的实时数据:请求数、失败数、中位响应时间、P95、RPS。切到 Charts 页能看到曲线图,Failures 页能看到报错详情。压够了就点 "Stop"。
第一个测试就跑完了。是不是比想象的简单?
这里有个地方值得停下来想一下:我们没写任何"压测逻辑",只是描述了一个用户会做什么动作,剩下的并发控制、统计、可视化 Locust 都帮你搞定了。 这就是它所谓"测试即代码"的意思——你只管写业务,压测是框架的事。
当然,真实业务不会这么简单。下一节来看几个更实际的场景。
二、四个真实场景
场景 1:带登录态的接口
大部分业务接口都要登录才能访问。Locust 提供了 on_start 钩子,每个虚拟用户"启动"时会执行一次,非常适合放登录逻辑:
from locust import HttpUser, task, between
class AuthenticatedUser(HttpUser):
wait_time = between(1, 3)
def on_start(self):
# 每个虚拟用户启动时登录一次
response = self.client.post("/login", json={
"username": "testuser",
"password": "testpass"
})
token = response.json()["access_token"]
# 把 token 塞到后续请求的 header 里
self.client.headers.update({
"Authorization": f"Bearer {token}"
})
@task
def get_profile(self):
self.client.get("/api/profile")
@task
def get_orders(self):
self.client.get("/api/orders")
关键点:self.client 是每个用户独立的,所以你在 on_start 里设置的 header,只会作用于这个用户后续的请求,不会污染其他用户。这个隔离性是 Locust 设计得挺贴心的一个地方。
如果你的 token 有过期时间,可以再加一个 on_stop 做登出,或者在 task 里检测到 401 之后重新登录——这种逻辑就是普通 Python 代码,你想怎么写都行。
场景 2:权重分配
真实用户的行为不是均匀的。一个电商网站,大部分人在浏览商品,少部分人会加购物车,只有很小一部分真的下单。如果你的压测脚本是 1:1:1 的比例去压,结果会严重偏离真实情况。
@task 装饰器可以传一个数字作为权重:
class ShoppingUser(HttpUser):
wait_time = between(2, 5)
@task(10) # 权重 10
def browse_products(self):
self.client.get("/products")
@task(3) # 权重 3
def add_to_cart(self):
self.client.post("/cart", json={"product_id": 1001})
@task(1) # 权重 1
def checkout(self):
self.client.post("/checkout")
权重是相对值,这里的比例就是 10:3:1,也就是浏览、加购、下单大概按 10:3:1 的概率触发。Locust 会按这个分布随机挑 task 执行。
设权重的时候建议你查一下自己服务的真实访问日志,照着线上的实际比例来设。很多人容易凭感觉拍脑袋设,但真实比例和感觉往往差好几倍——这种压测结果是误导性的,还不如不测。
场景 3:参数化,每个用户用不同数据
很多场景下,每个虚拟用户应该用不同的数据。比如压测一个登录接口,如果 100 个用户都用同一个账号登录,后端可能走了缓存,压出来的数据不准。
简单做法是用一个 CSV 文件存测试账号,然后在脚本里读:
import csv
import random
from locust import HttpUser, task, between
# 在文件顶部加载一次,所有用户共享
with open("users.csv") as f:
USER_CREDENTIALS = list(csv.DictReader(f))
class ParameterizedUser(HttpUser):
wait_time = between(1, 3)
def on_start(self):
# 每个虚拟用户启动时随机挑一个账号
creds = random.choice(USER_CREDENTIALS)
self.client.post("/login", json=creds)
@task
def get_data(self):
self.client.get("/api/data")
users.csv 大概长这样:
username,password
alice,pass123
bob,pass456
charlie,pass789
这里有个细节:CSV 文件的读取写在类外面,这样只会读一次,所有用户共享这份数据;如果你把它写到 on_start 里,每个用户都会去读一次文件,启动几千个用户的时候就会很慢。
如果你需要"每个用户用一个独立的账号,不重复",可以用 itertools.cycle 或者一个带锁的迭代器,稍微复杂一点但也就是普通 Python 代码的事。
场景 4:自定义断言
默认情况下,Locust 只看 HTTP 状态码——200-399 算成功,400+ 算失败。但很多接口就算返回 200,业务层面也可能是失败的,比如:
{"code": 500, "message": "余额不足"}
这种情况下,你需要自定义判断逻辑。self.client 提供了一个上下文管理器模式:
from locust import HttpUser, task, between
class CustomAssertUser(HttpUser):
wait_time = between(1, 3)
@task
def place_order(self):
with self.client.post(
"/api/order",
json={"product_id": 1001, "quantity": 2},
catch_response=True
) as response:
if response.status_code != 200:
response.failure(f"HTTP {response.status_code}")
elif response.json().get("code") != 0:
response.failure(f"业务失败: {response.json().get('message')}")
else:
response.success()
关键是 catch_response=True 这个参数,它让你可以手动调 response.success() 或 response.failure()。写了自定义断言之后,Failures 页面能看到具体的业务错误原因,排查起来方便很多。
这四个场景基本能覆盖日常压测 80% 的需求。接下来聊一个进阶话题。
三、单机不够用怎么办:分布式压测
单台机器能压出多大 QPS?这个问题没有标准答案,取决于你的脚本复杂度、网络、CPU。但有几个信号可以判断单机到瓶颈了:
- Locust 自己的 CPU 占用接近 100%(你要压的是目标服务,不是把自己压死)
- 目标服务的响应时间突然暴涨,但实际 QPS 上不去
- 终端里开始出现 "CPU usage warning" 警告
到了这种程度,就该上分布式了。Locust 的分布式架构很简单:
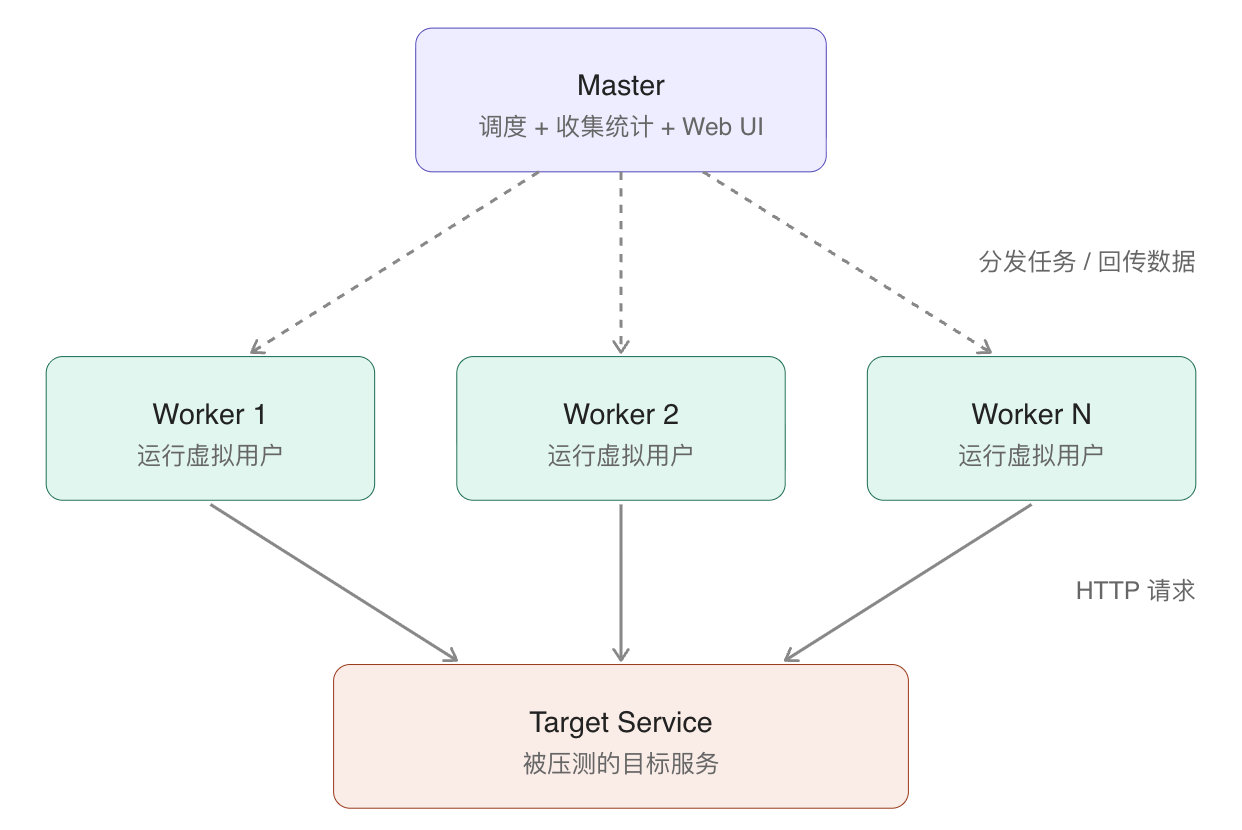
一个 master 负责调度和收集数据,多个 worker 负责真正发请求。
在一台机器上启动 master:
uv run locust -f locustfile.py --master
在另外几台机器(或者同一台的不同终端)启动 worker:
uv run locust -f locustfile.py --worker --master-host=<master-ip>
注意两点:
- 所有 worker 必须有完全相同的
locustfile.py,Locust 不会自动同步代码给 worker,你要自己用scp、Git、或者 Docker 镜像把脚本分发过去。 - worker 数量建议等于 CPU 核心数。Locust 基于 gevent,单进程吃不满多核,所以一台 8 核机器你可以起 8 个 worker。
启动好之后,master 的 Web UI 用起来跟单机一模一样,Locust 会自动把用户均匀分配给各个 worker。
什么时候需要分布式?我的经验是:你要压的 QPS 超过 1000,或者你的脚本里有复杂的业务逻辑导致单机用户数撑不到几百,就可以考虑了。 压几十上百 QPS 的场景,单机足够。
四、我踩过的几个坑
坑 1:用户数 ≠ QPS
刚开始我以为"1000 个虚拟用户"就等于"1000 QPS",后来才反应过来,这俩完全不是一回事。
一个虚拟用户在 Locust 里的行为模式是:执行 task → 等待 wait_time → 再执行 task。如果 wait_time 是 between(1, 3),平均 2 秒,那一个用户平均每 2 秒发一个请求,也就是 0.5 QPS。1000 个用户才是 500 QPS。
所以设用户数的时候要反推:目标 QPS × 平均 wait_time = 需要的用户数。想压 1000 QPS、wait_time 平均 2 秒,那就是 2000 个用户。
坑 2:wait_time 设成 0 不是"最大压力",而是"不真实"
一开始我觉得 wait_time = 0 能压出最大压力,后来想明白这是个伪命题。
真实用户不会 0 间隔地连续点击。wait_time 设成 0,你得到的是一个"机器人式的极端场景",反映不出正常业务下的服务表现。更糟的是,如果你的服务有连接池、限流、缓存预热这些机制,0 等待的压测会让这些机制的表现偏离实际线上情况。
我现在的做法是:对着线上日志看用户的真实点击间隔,用 between(min, max) 设一个接近的范围。如果实在没有数据,1-5 秒是个比较保守合理的默认值。
坑 3:只看平均值会被骗
Locust 的 Statistics 页默认显示的是平均响应时间。但平均值在性能测试里是一个非常有误导性的指标。
举个例子:100 个请求,99 个是 50ms,1 个是 5000ms,平均值是 99.5ms,看起来很好。但实际上 1% 的用户经历了 5 秒的卡顿,在生产环境这是个严重问题。
养成看 P95 和 P99 的习惯。 P95 = 95% 的请求比这个时间快,P99 = 99% 的请求比这个时间快。这两个指标才真正反映"最差情况下的用户体验"。Locust 的 Statistics 页有这两列,但位置偏右,一开始容易忽略。
坑 4:压测机自己先挂了
我第一次做分布式压测的时候,开了几千个用户,结果 Locust 自己的 CPU 被打满,压出来的数据完全失真——不是目标服务扛不住,是压测机先扛不住了。
判断方法很简单:压测时看一眼压测机自己的 CPU 和网络带宽。如果 CPU 接近 100%,或者带宽跑满了,压测结果就不可信。解决方案要么是降低用户数、简化脚本,要么就是上分布式,多开几台 worker。
结尾
这篇就记到这里。Locust 的东西还有不少没覆盖的,比如和 Prometheus/Grafana 对接做实时监控、在 CI/CD 里跑性能回归、用自定义客户端压测 WebSocket 或 gRPC 之类的,以后如果用到再专门写。
总体感受:Locust 是一个"门槛低、天花板不低"的工具。简单场景五分钟上手,复杂需求靠普通 Python 代码也基本都能搞定。对不是专职做性能测试的开发者来说,够用,而且用着顺手。
如果你也想试试,我的建议是别一上来就读完整的官方文档,就从第一节那个 10 行的 locustfile.py 开始跑,跑通了再按自己业务的需要一点点往上加功能。这个工具的学习曲线基本是线性的,不会突然陡峭,不用太担心。
最后再啰嗦一句:压测的意义不在于"跑出一个漂亮的 QPS 数字",而在于提前发现你的服务在什么地方会先挂。数字本身没那么重要,挂的方式才是你真正要了解的东西。
以上就是我学习 Locust 的心得。如果你发现文章里有错误,或者有更好的实践想分享,欢迎留言交流。
