

面试官问:「你们生产环境用StateGraph还是MessageGraph?」你张口就说「随便,都能跑」,然后看着面试官在备注栏写了点东西。
这个瞬间,候选人可能不知道他刚刚丢掉的不是一个技术问题,而是一次展示工程判断力的机会。
这两个选项不是功能多少的差别,而是状态建模哲学的根本分歧——用错了,checkpoint恢复会莫名其妙,用对了,人工审批链路天然顺滑。
面试官备注栏写字.jpg
问题:面试里怎么问StateGraph和MessageGraph的选型
「你们在项目里用StateGraph还是MessageGraph?为什么这样选?」
这是最直接的问法,面试官想要的不是标准答案,而是你能不能讲清楚判断依据。如果你只会「都可以跑」,那基本等于告诉面试官你没在生产环境里真正做过选型决策。
第二种常见问法:「如果我现在有一个多轮对话Agent,需要保留对话历史,你会用StateGraph还是MessageGraph来实现?」
这道题把选型约束具体化了——多轮对话、保留历史,答案其实很明确,但关键在于候选人能不能把「为什么明确」讲出来,而不是背一个结论。
第三种变体:「StateGraph里的状态和MessageGraph里的messages有什么区别?」——考察对两者状态语义的理解深度。
第四种变体:「你们的Agent用了checkpoint吗?用在哪里?」——把checkpointer机制和选型绑定在一起问,探测候选人是否真正用过生产级特性。
第五种变体:「如果现在要加一个人工审批节点,用StateGraph方便还是MessageGraph方便?」——场景题,把选型和工程需求绑在一起,考验实际落地能力。
第六种变体:「LangGraph v1.0之后,你们的选型有没有调整过?」——探测候选人是否持续跟进框架演进,不是面完就忘。

这题我真没想过……
模板答案:30秒开口版、展开版与压缩技巧
30秒开口版
「StateGraph和MessageGraph的核心差异在于状态建模哲学。
StateGraph用TypedDict定义结构化状态,每个节点显式读写状态字段,状态更新是确定性替换,适合业务逻辑明确、需要强类型约束的场景。
MessageGraph用append-only消息列表作为状态,状态演进是消息不断追加,不需要显式定义字段类型,适合对话类、需要保留完整交互历史的场景。
选型判断其实很简单——如果你的Agent核心是『业务决策』,优先StateGraph;如果核心是『对话记录』,优先MessageGraph。」
这段话在30秒内把本质差异、判断标准、具体建议全部覆盖,面试官听感是「这人不是在背概念,是在讲判断」。
展开版:状态建模哲学的根本差异
StateGraph的核心理念是结构化状态。
你用Python的TypedDict定义一个状态类,每个字段有明确类型,状态在节点之间流转时,每个节点函数显式读取和写入这些字段。
状态更新是确定性替换——同一个输入,同一个状态,经过同一个节点,永远得到同一个输出。这种设计的好处是:可类型检查、可序列化checkpoint、可精确复现任意中间状态。
坏处是:你必须预先定义好所有可能的状态字段,业务逻辑一变,状态类就要跟着改。
MessageGraph的核心理念是消息流。状态本质上就是一个消息列表Sequence[BaseMessage],每个节点往列表里追加消息,但不修改历史消息。
状态演进是不可变的追加链——这是event sourcing的思想在LLM Agent里的应用。好处是天然支持对话历史,不需要额外的记忆管理;
坏处是你很难对状态做确定性回溯(因为消息顺序和LLM输出本身就带有随机性),checkpoint的粒度也只能是整个消息列表。
这两个哲学分歧,直接决定了断点恢复精度、人工审批链路实现成本,以及状态体积的增长曲线。
面试里怎么压缩回答
如果面试官打断了你,或者时间只剩20秒,只需要说核心判断:「业务决策类Agent用StateGraph,对话历史类Agent用MessageGraph,选型依据是『我需要精确的状态控制还是完整的消息流』。
」
这条压缩版的价值在于:它给出了一个可验证的判断标准,而不是一个模棱两可的「都可以」。面试官顺着这个标准追问,你就有了一个可以继续展开的支点。

这个判断框架很清晰
为什么问这个:面试官到底在筛什么
这道题表面上考的是「知不知道这两个概念」,实际上考的是三件事。
第一,有没有生产级使用经验。能说出TypedDict约束和append-only语义区别的候选人,至少在项目里真的跑过代码;
只会背「StateGraph更灵活」这种套话的,基本可以判断是看了两篇博客就来面试的。
第二,有没有工程判断力。选型不是比谁的功能多,而是看谁的约束更符合业务需求。
能主动说出「MessageGraph适合对话但不适合业务决策」这类判断的候选人,说明他思考过「什么场景该用什么武器」——这是Senior工程师的核心能力。
第三,有没有踩过真实的坑。
如果候选人能说出「我们最开始用MessageGraph做多轮对话,但消息列表膨胀后推理延迟翻了一倍,后来切到StateGraph+外部向量存储才解决」,那面试官基本可以判断这人是真的从生产环境里长出来的。
这道题通常出现在二面或者技术深度面,出现在「Agent框架选型」「LangGraph原理」「生产级Agent架构」这些话题之后。
它不是一面那种「你用过什么框架」的基础题,而是确认候选人有没有在框架层面做工程判断的能力。换句话说,一面筛会不会用,二面筛会不会选。1
StateGraph核心原理:TypedDict状态建模与图节点设计
状态定义与TypedDict约束
StateGraph的状态用Python的TypedDict定义,类型安全是它最核心的特性。来看一个典型的AgentState定义:
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
next_agent: str
task_result: dict
messages字段用Annotated和operator.add实现消息累加——每次节点处理完,追加新消息而不覆盖历史。
next_agent和task_result是业务自定义字段,分别控制路由和任务结果。
TypedDict在这里的作用是:IDE能提示类型错误,pydantic能校验状态结构,序列化后能精确重建状态。
这和MessageGraph的根本区别在于:MessageGraph的状态是Sequence[BaseMessage]这条列表本身,不需要也不允许你加额外的结构化字段。
状态就是消息,消息就是状态,没有中间层。
节点函数的读写语义
StateGraph的节点函数签名是(state: AgentState) -> Partial[AgentState],即输入当前状态,返回部分状态更新。
返回值不会覆盖整个状态,只更新对应字段。这带来一个重要特性:节点之间可以共享状态的不同部分,而不需要相互知道彼此的存在。
def researcher_node(state: AgentState) -> AgentState:
# 读取当前消息列表
current_messages = state["messages"]
# 做研究,更新 next_agent 和 task_result
return {
"next_agent": "analyst",
"task_result": {"findings": research_results}
}
节点不需要返回messages,因为它没有修改messages;节点只更新自己负责的字段。
这种字段级别的状态隔离是StateGraph最重要的设计,也是它区别于MessageGraph的本质。
边规则:add_edge与add_conditional_edges
StateGraph的边分两种。add_edge是确定性边——A节点处理完必然流向B节点,没有任何判断逻辑。
add_conditional_edges是条件边——A节点处理完后,根据当前状态(通常是state["next_agent"])决定下一步流向哪个节点。
# 确定性边:researcher 完成后必须经过 supervisor
workflow.add_edge("researcher", "supervisor")
# 条件边:supervisor 根据 next_agent 字段决定下一步
workflow.add_conditional_edges(
"supervisor",
lambda x: x["next_agent"],
{
"analyst": "analyst",
"tools": "tools",
"FINISH": END
}
)
这个设计的优雅之处在于:状态本身既是数据容器,又是控制流信号。next_agent字段既是业务数据(当前应该由哪个Agent处理),又是路由决策(下一步流向哪个节点)。
这种数据流和控制流的统一,是StateGraph区别于MessageGraph的关键设计——MessageGraph的路由逻辑通常塞在节点函数内部或者系统提示词里,而StateGraph把它显式建模成了状态的一部分。
checkpointer与断点恢复
StateGraph的生产级特性,checkpoint是核心。没有checkpoint的StateGraph和普通的状态机没什么区别;
有了checkpoint,它才真正变成一个持久化执行引擎。1
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
workflow = StateGraph(AgentState)
# ... 定义节点和边
app = workflow.compile(checkpointer=checkpointer)
# 带 thread_id 的调用,状态会被持久化
config = {"configurable": {"thread_id": "user_session_001"}}
result = app.invoke(input_dict, config=config)
# 下一次调用同一个 thread_id,状态从上次断点恢复
result2 = app.invoke(second_input, config=config)
thread_id是会话唯一标识,LangGraph会把每次invoke的状态快照存进checkpointer。
Agent崩溃重启后,只要传入相同的thread_id,状态会从最近一次checkpoint恢复,而不是从头开始。
这在生产环境里意义重大。比如一个研报生成Agent跑了30分钟,到第25分钟LLM API超时了——没有checkpoint的情况下,Agent要从头重跑;
有checkpoint的情况下,它从第25分钟的状态恢复,继续生成。
这个能力MessageGraph也有,但StateGraph的优势在于:断点恢复的精度更高——你可以在interrupt_before某个节点处精确停下,而不是只能停在某条消息之后。

跑了25分钟的Agent挂了,没checkpoint……
MessageGraph核心原理:消息列表作为状态的流式设计
append-only消息语义
MessageGraph的状态哲学和StateGraph完全相反。StateGraph的状态是可变的结构体——每个节点可以更新任意字段,状态是最新值。
MessageGraph的状态是不可变的消息链——每个节点只能追加消息,不能修改历史,历史永远保留。
# MessageGraph 的状态等价于 LangChain 的 MessagesState
class MessagesState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
有趣的是,MessagesState本质上是AgentState的一个特例——只保留messages字段,去掉了所有自定义字段。
MessageGraph的「状态」就是这整条消息列表,没有next_agent、没有task_result、没有路由信号。
这带来了一个直接后果:MessageGraph天然适合对话,但不适合复杂业务路由。
如果你要实现「分析完数据后判断是继续搜索还是生成报告」,StateGraph可以在状态里放一个next_agent字段,让边规则根据它做路由;
但在MessageGraph里,这个路由信号要么塞进某条AI消息的内容里(依赖LLM自己解析),要么你在MessageGraph外面套一层自己的路由逻辑(破坏封装)。
适用场景与LangChain消息原语
MessageGraph最适合的场景是对话式Agent——客服、助手、聊天机器人。这些场景的共同特征是:核心数据就是对话历史;不需要复杂的业务状态建模;
对状态更新的原子性要求不高;更关心「说了什么」而不是「当前在哪个业务节点」。
LangChain为MessageGraph提供了一套完整的消息原语:HumanMessage、AIMessage、SystemMessage、ToolMessage。
这些消息类型在LangChain生态里有统一的处理逻辑,比如SystemMessage会被放在消息列表最前面作为系统提示,ToolMessage会带tool_call_id和原始调用的关联信息。
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
# 一次典型的工具调用消息链
messages = [
SystemMessage(content="你是一个金融数据助手。"),
HumanMessage(content="查一下AAPL的股价。"),
AIMessage(content="", tool_calls=[{"name": "get_stock_price", "args": {"symbol": "AAPL"}}]),
ToolMessage(content="182.35", tool_call_id="...", name="get_stock_price"),
AIMessage(content="AAPL当前股价是182.35美元。")
]
这整条消息链就是MessageGraph的完整状态。状态演进靠追加,不靠替换。
与StateGraph的切换成本
从MessageGraph切到StateGraph,代价取决于你的业务复杂度:
-
如果只是把
MessagesState扩展成AgentState加一两个字段,改动相对小,主要是边规则的迁移。 -
如果MessageGraph里耦合了大量路由逻辑(靠LLM解析消息内容判断下一步),切换到StateGraph需要把这些隐式路由显式建模成状态字段和条件边,这是主要工程量所在。
-
LangGraph提供了
MessagesState和自定义TypedDict状态的互转工具,但互转本身不解决业务逻辑迁移的问题——它只是状态结构的映射。
反过来,从StateGraph切到MessageGraph通常是不推荐的,因为StateGraph已经建模了业务状态,放弃这些字段去换MessageGraph的流式语义,代价大于收益。
StateGraph vs MessageGraph:8个维度的选型对照
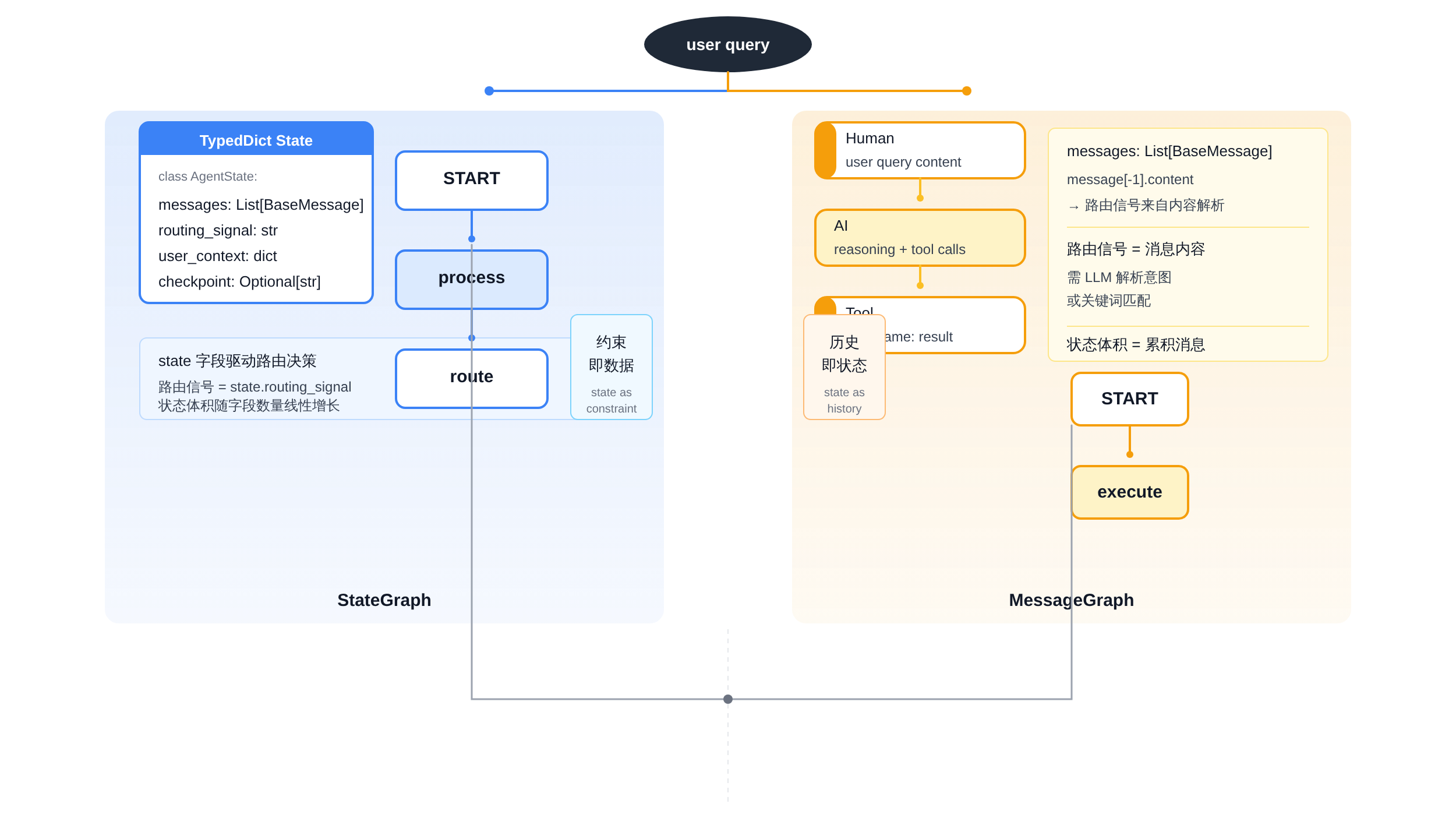
正文图解 1
| 维度 | StateGraph | MessageGraph | |---|---|---| | 状态建模哲学 | 结构化状态,字段级别读写 | 消息流,append-only语义 | | 类型安全 | TypedDict强约束,IDE提示 | 无自定义字段,依赖LLM解析 | | 状态体积控制 | 显式字段,易裁剪压缩 | 消息列表无限膨胀,需额外截断 | | 路由控制 | next_agent字段+条件边,显式建模 | 隐式路由,依赖LLM或外部逻辑 | | 断点恢复精度 | 可在任意节点前精确中断 | 只能停在消息追加后 | | 人工审批 | interrupt_before原生支持 | 需hack或外部编排 | | 记忆管理 | 外置向量存储+状态字段 | 消息历史即记忆 | | 适用场景 | 业务决策类Agent | 对话记录类Agent |
这个表格的核心结论:两者不是功能多少的对比,是建模对象的正交。StateGraph适合「业务状态机」场景,MessageGraph适合「对话日志」场景。
从框架生态的角度看,2026年主流Agent框架的选型趋势值得关注:LangGraph(~25K Stars)以图状态机为核心主打生产级编排,CrewAI(~44.6K Stars)以角色化Crew主打快速上手,OpenAI Agents SDK(~19K Stars)以极简Handoff主打与OpenAI生态的深度绑定——每个框架背后都对应着不同的状态建模哲学,选型时框架偏好也会影响最终决策。

原来选型是有判断依据的……
常见追问:3个深度追问与接法
追问1:interrupt_before怎么在StateGraph中途插入人工审批点
面试官这样追问,通常是想看你有没有真正在生产环境里用过HITL(Human-in-the-Loop)特性。
标准接法:
「interrupt_before是LangGraph断点恢复的核心API。
比如一个合同审核Agent,模型生成审核意见后需要法务确认,我们就在interrupt_before=["legal_review"]设置断点,Agent停在这里等待人工审批。
实现上分三步:编译图时加interrupt_before参数,调用时用stream模式逐事件推进,用户审批后调用resume继续。」
from langgraph.checkpoint.sqlite import SqliteSaver
# 用SQLite持久化checkpoint,支持跨进程恢复
checkpointer = SqliteSaver.from_conn_string(":memory:")
app = workflow.compile(
checkpointer=checkpointer,
interrupt_before=["legal_review"] # 在这个节点前中断
)
# 第一次调用:Agent停在 legal_review 前
for event in app.stream(initial_input, config, stream_mode="values"):
pass # 事件流会在 interrupt_before 处暂停
# 法务审批完成后,传入审批结果继续
app.resume(thread_id, {"approval_result": "approved", "comments": "无异议"})
这里的关键是:interrupt_before让StateGraph的断点精确度达到了节点级别,而MessageGraph只能做到「停在某条消息之后」——精度差了一层。
对于需要法务、财务、合规审批的金融类Agent,这个差异直接决定了能不能合规上线。
追问2:MessageGraph能做到循环吗
这个追问的潜台词是:候选人知不知道MessageGraph的状态语义里,循环意味着什么。
标准接法:
「MessageGraph本身不建模循环,但可以通过在消息列表里追加特定的控制消息来触发循环——比如在AI回复里插入一个goto_node消息,让节点函数读到这条消息后重新路由到某个早期节点。
这种做法本质上是把循环逻辑塞进了消息内容里,不是框架原生的。」
更诚实的答案是:MessageGraph的循环实现是工程上的折中,不是设计上的优雅。
如果你需要循环,用StateGraph会更自然——直接在add_conditional_edges里建模回到某个上游节点的边就行。
这条追问筛的是:候选人是否理解「框架提供了什么能力」和「我在框架上额外做了什么」之间的边界。
能把这块说清楚的候选人,通常也更能说清楚什么时候该换框架,而不是硬撑着在MessageGraph上堆hack。
追问3:LangGraph v1.0 GA之后选型有什么变化
这道追问考的是候选人有没有持续跟进框架演进,而不只是面经考古。
标准接法:
「LangGraph在2025年底发布v1.0 GA,StateGraph的checkpoint精度和interrupt_before/after能力都更稳定了。
另外v1.0的双层记忆系统(短期工作记忆+长期持久记忆)让StateGraph的memory管理能力大幅提升,对需要跨会话状态复用的场景更有优势。」
关于MessageGraph的变化:「MessageGraph在v1.0里和LangChain的MessagesState完全打通,工具调用的消息追踪也改进了不少,但核心的流式语义没有变。」
这条追问的判断价值在于:能说出具体版本号和特性名称的候选人,说明他在跟进官方文档和release notes,而不是靠二手博客理解框架。
面试官对这种候选人通常会高看一眼——至少不会觉得你是个只会背八股的面经选手。

不是面经选手,我是真跟进了……
易错点:回答时最容易丢分的3个坑
易错点一:把MessageGraph当成加了messages字段的StateGraph
这是最常见的误解。
候选人看到MessageGraph的MessagesState定义和StateGraph的AgentState定义很像,就以为MessageGraph只是「把messages字段单独拿出来的StateGraph」。
错在哪里:两者最根本的差异不是字段多少,而是状态演进语义。
StateGraph的状态更新是替换(deterministic replacement),MessageGraph的状态演进是追加(append-only)。
这意味着:StateGraph可以精确控制某个字段的最新值,MessageGraph只能追加消息、不能精确更新某个历史消息的内容。
如果你在面试里说「MessageGraph就是StateGraph去掉了一些字段」,面试官大概率会追问:「那如果我想在MessageGraph里更新一个历史消息的字段,能做到吗?
」——答案是做不到,这就是两者不可替代的差异点。
易错点二:只背适用场景,不说边界和回退策略
很多候选人能背出「对话用MessageGraph,业务决策用StateGraph」,但被追问「那如果我的业务决策里也有对话历史怎么办」就卡住了。
错在哪里:选型不是非此即彼。
实际生产环境里,常见的做法是StateGraph作为主框架,外挂MessageGraph式的消息历史——状态里维护一个messages字段(类型是Sequence[BaseMessage]),同时还有next_agent、task_result这样的业务字段。
这本质上是把MessageGraph的流式语义融合进了StateGraph的结构化状态里。
只会背「两者选一个」的人,说明他不理解状态建模是可以组合的。面试官更想听到的是「我的判断依据是X,但如果Y场景出现我会这样应对」。
易错点三:把checkpointer当成选型依据
有些候选人觉得「有checkpointer就用StateGraph,没有就用MessageGraph」,或者反过来「想用checkpoint就必须用StateGraph」。
错在哪里:两者都支持checkpoint,区别在于checkpoint的粒度。
StateGraph的checkpoint可以精确到节点级别(interrupt_before),MessageGraph的checkpoint只能到消息追加后。
这意味着:如果你需要「在某个业务节点前精确暂停等人工审批」,StateGraph更合适;如果你只需要「保存对话历史供下次调用」,两者都可以。
把checkpointer当成选型依据的人,通常没有真正在生产环境里用过checkpoint——他可能只在博客里看到过checkpoint的demo,没有遇到过「Agent跑了30分钟第25分钟挂了需要从第24分钟恢复」这种真实场景。

早知道就不硬套了……
其他注意事项
回答顺序:先说哪个更稳
如果面试官问「你们项目里用哪个」,优先说你更有把握的那个。
不是让你撒谎,而是如果你对StateGraph更熟,就从StateGraph展开,MessageGraph作为对比带过;反过来也一样。
面试官不是在找标准答案,他是在找你真正用过的东西。你对StateGraph的状态建模讲得越细,面试官越相信这是你生产环境里的实战经验,而不是背来的知识点。
术语边界:这些词不能混着说
StateGraph相关:StateGraph、TypedDict、AgentState、add_edge、add_conditional_edges、interrupt_before、checkpointer、thread_id、持久化执行、节点、边、状态字段。
MessageGraph相关:MessageGraph、MessagesState、append-only、BaseMessage、HumanMessage、AIMessage、ToolMessage、流式语义、消息链。
最忌讳的是:把StateGraph的「状态」和MessageGraph的「状态」混用——前者是结构体字段,后者是消息列表。面试官如果发现你在这两个概念之间跳来跳去,会直接判定你不理解底层原理。
面试节奏与补充动作
这道题的理想节奏是:30秒开口版(核心判断)→ 1分钟展开版(原理差异)→ 被追问时补细节。不要一口气讲3分钟,面试官打断你的概率很高,而且信息密度下降后他会觉得你在背稿。
如果你讲完30秒版后看到面试官在点头或者在看简历,主动停,等追问。面试官不追问通常有两个原因:他觉得你讲得很清楚不需要追问,或者他觉得这题不重要已经过了——无论是哪个,都比硬塞内容强。
主动补充的时机:如果你发现面试官对某个维度特别感兴趣(比如他追问了interrupt_before),可以在后续回答里主动加深这个方向的细节,但不要一开始就把所有牌都亮出来。
项目里怎么说:两个真实工程语境的接法
可直接复述的项目说法
场景一:多轮对话客服系统(MessageGraph为主)
「我们做的客服Bot核心用MessageGraph,因为它的状态天然就是对话历史。实现上分了三个阶段:第一阶段用纯MessageGraph跑通了Demo;
第二阶段发现消息列表膨胀后推理延迟从800ms涨到2.3s,加了MessagesListLimiter做滑动窗口截断,控制在最近20轮;
第三阶段发现用户问『你还记得我上次的问题吗』这种跨会话问题,开始在MessageGraph外接向量存储做长期记忆。」
这段说法的价值:展示了渐进式工程思维——不是一步到位设计最优架构,而是用最简单的方式验证假设,再根据真实数据迭代。
面试官问「你们为什么这样设计」时,你有具体的数字(800ms→2.3s)和具体的决策点可以讲。
场景二:研报生成Agent(StateGraph为主)
「我们用StateGraph搭了一个金融研报生成流水线。
状态里定义了research_phase(enum:数据采集/初步分析/深度分析/报告生成)、data_sources(已查询的数据源列表)、current_analyst(当前负责的分析员Agent)三个字段。
边规则里用add_conditional_edges根据research_phase做路由——数据采集完成后自动流转到初步分析,初步分析发现数据不足时回退到数据采集继续补充。」
这段说法的价值:展示了用StateGraph显式建模业务流程的能力。
Klarna这类金融科技公司用LangGraph做生产级Agent编排时,采用的正是类似思路——把业务流程建模成状态字段和条件边,而不是堆在节点函数的if-else里。3
如果没做过完整项目怎么补
没做过完整LangGraph项目的候选人,可以从两个方向补:
方向一:用最小的Demo验证核心概念。
哪怕只是一个「用户输入 → LLM回复 → 工具调用 → 回复」的4步StateGraph流程,跑通checkpointer的thread_id持久化和interrupt_before断点,就能回答「你在项目里用过什么」的追问。
Demo的关键不是功能完整,而是用了真实的API,不是伪代码。
方向二:研究一个开源的LangGraph项目,然后从代码层面讲清楚它的状态建模选择。
比如LangChain官方仓库里的agent-skeleton示例,或者GitHub上一些star过千的LangGraph生产项目。
重点是能回答:「这个项目为什么用StateGraph而不是MessageGraph?他们判断的依据是什么?」——这类问题比「你自己做过什么」更宽容,但要求你对架构决策有理解。

从哪里找这类开源项目啊……
参考文献
4: 大模型Agent面试全攻略(附答题思路),牛客网,2026年4月。www.nowcoder.com/discuss/871…
3: LangGraph: Agent Orchestration Framework for Reliable AI Agents,LangChain官方文档。
2: LangGraph vs CrewAI vs AG2 vs OpenAI Agents SDK:2026年AI Agent框架终极对比指南,DEV Community,2026年3月。
参考文献
延伸入口
- 原文归档:tobemagic.github.io/ai-magician…
- 公众号:计算机魔术师

