


某家 AI 创业公司的面试现场,候选人把 Reflexion 的核心机制讲清楚了——Actor 生成动作、Evaluator 打分、Reflexion 产生语言反馈。
面试官点了点头,然后追问了一句:「Reflexion 里的反馈是存在权重里还是存在语言记忆里?为什么这样设计?」他愣住了,答得支支吾吾。
这个追问的答案,恰恰是 Reflexion 这道题真正在筛的东西。
很多人知道 Reflexion 是什么,知道它的三层架构,甚至能画出那条反馈回路——但一到「反馈存哪」这个边界问题,就说不清楚。
面试官不是故意刁难,他是在确认你到底是在背概念,还是真的理解了这套机制为什么长这样。
这篇把 Reflexion 拆透:模板答案怎么开口、追问怎么接、项目经验怎么说、以及回答时最容易丢掉的三个分。
问题
标准问法
面试里 Reflexion 通常以这几种形式出现:
-
「请介绍一下 Reflexion 的工作原理,它和标准 ReAct 有什么不同?」
-
「Reflexion 是怎么实现自我反思的?它的反馈循环是怎么运转的?」
-
「在 Reflexion 架构里,Evaluator 扮演什么角色?打分结果怎么影响后续推理?」
这三种问法难度递增。第一种只需要讲清楚基本流程;第二种要求你能画出那条反馈回路;
第三种是真正拉开差距的——它逼你交代清楚 Evaluator 的打分逻辑,以及这条反馈为什么能改进输出质量,而不只是停留在「加了一步反思」这个表面。
常见变体
除了上面的标准问法,面试里还经常出现这些变体:
-
「Reflexion 的语言反馈记忆和 RAG 的检索增强有什么区别?」(混淆类追问)
-
「Reflexion 的反馈更新的是模型权重还是外部存储?」(边界条件追问)
-
「Reflexion 和 Self-RAG 在反思机制上有什么本质不同?」(术语辨析类)
这些变体不是随机出的,面试官是在探测你对 Reflexion 的理解到底是一层薄皮,还是真的摸到了它的设计边界。

面试官这追问角度,太准了
模板答案
30 秒开口版
Reflexion 的核心是一套语言记忆反馈循环。
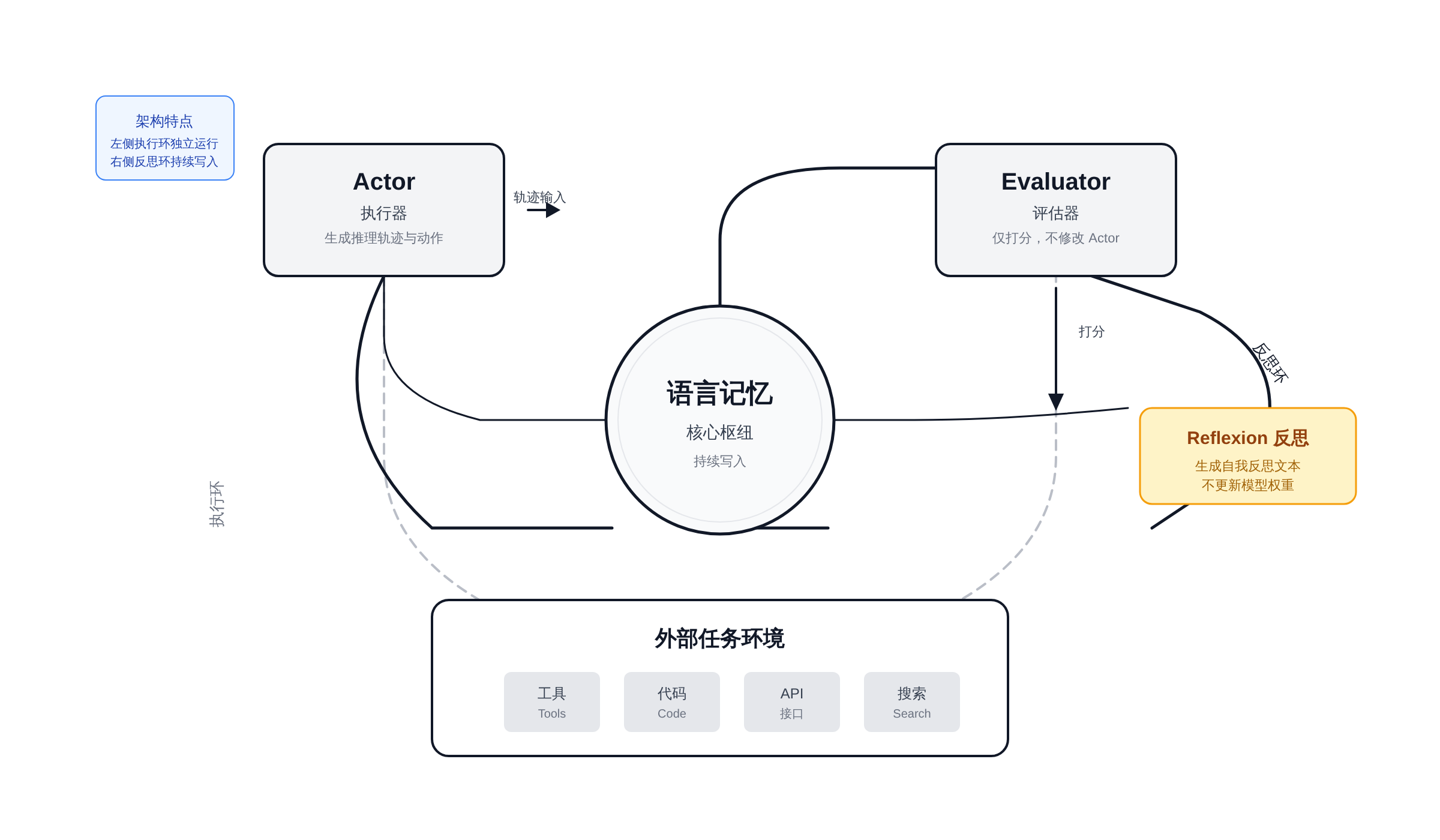
它由三个组件构成:Actor 负责生成动作和推理,Evaluator 负责根据任务目标给当前轨迹打分,Reflexion 模块根据Evaluator 的反馈生成语言层面的反思信息,这条反思被写入一个外部的语言记忆存储。
下次 Actor 再遇到类似任务时,会从语言记忆里读取历史反思经验,结合当前上下文重新推理。关键在于:反馈写进的是语言记忆,不是模型权重。
所以它不需要梯度更新,训练成本极低,而且反馈是可读、可审计的。
这段回答在 30 秒内把三层架构、反馈回路和设计边界都说清楚了,面试官这时候通常会追问设计动机或者和 ReAct 的区别,而不是继续在基础概念上打转。
展开版:三层架构与反馈循环
Reflexion 的完整工作流可以拆成四个步骤在白板上讲清楚:
第一步:Actor 生成推理轨迹。
Actor 基于当前状态和任务目标,通过大语言模型生成一段推理链(类似 CoT),然后执行一个动作。这个动作可以是调用工具、写一段代码,或者输出一个答案。
关键点在于:Actor 的输出不是最终答案,而是一整条「推理轨迹」,包含思考过程和动作。
第二步:Evaluator 评估轨迹质量。
Evaluator 模块拿到 Actor 的推理轨迹后,根据任务目标给这条轨迹打分。评估可以基于规则(比如答案是否正确)、基于奖励模型,或者两者的组合。
Evalautor 的输出是一个数值分数,可能附带一段简短的评估理由。
第三步:Reflexion 生成语言反馈。
这是 Reflexion 最独特的地方。
Reflexion 模块接收Evaluator 的打分和当前轨迹,然后生成一段语言形式的反思——不是更新模型权重,不是调参,而是写一段自然语言描述:错误在哪里,为什么失败,下次应该怎么改进。
这段反思是结构化的,通常包含「问题诊断 + 改进建议」两个部分。
第四步:语言记忆持久化。
Reflexion 生成的反思被写入一个外部语言记忆存储。这个存储通常是一个向量数据库或者简单的键值存储,按照任务类型或者领域组织。
下次 Actor 处理类似任务时,会先从语言记忆里检索相关的历史反思,作为上下文的一部分注入给模型。
整个循环会持续 N 轮,直到 Evaluator 给出足够高的分数,或者达到预设的最大步数上限。
正文图解 1
这张图里语言记忆是中央枢纽,右侧的反思回路是持续写入的——这是 Reflexion 区别于其他方案的本质。
面试里怎么压缩回答
如果面试官在第一轮就打断了你,或者时间只剩 1 分钟,直接说最核心的三句:
Reflexion 由 Actor、Evaluator 和 Reflexion 三个模块组成。Actor 生成推理轨迹,Evaluator 打分,Reflexion 根据打分生成语言层面的反思,写入外部语言记忆。这条反思不更新模型权重,所以 Reflexion 的核心改进是通过可读的语言记忆实现低成本的持续自我改进,而不是靠梯度更新。
这三句里最重要的是最后那句「不是靠梯度更新」——它直接点出了 Reflexion 的设计哲学,也是面试官最可能追的地方。

梯度更新这句话,说出来面试官就懂了
为什么问这个
面试官到底在筛什么
Reflexion 是一道典型的「概念不难,边界难」的面试题。
大多数候选人能讲清楚 Actor-Evaluator-Reflexion 三层架构,能说出「自我反思」「反馈循环」这些关键词。但面试官真正在筛的是两件事:
第一,你是否理解反馈存在哪。 很多候选人以为 Reflexion 也是一种训练方法,是在微调模型——错了。Reflexion 的反馈存在语言记忆里,模型权重完全不动。
这一点搞混了,后续所有追问都会歪掉。
**第二,你是否理解为什么不更新权重。
** Reflexion 选择语言记忆而不是梯度更新的原因有三个:成本低(不需要反向传播)、可审计(反馈是人类可读的自然语言)、快速迭代(同一批反思可以立即被下一次推理调用)。
这三点能说清楚一条,说明你不只是在背答案,是在理解这套设计的工程动机。
AI Engineering Field Guide 在面试准备部分明确指出,AI System Design 面试里考察 Agent 架构时,面试官最在意的不是「你知道多少种框架」,而是「你能否说清楚每种设计的边界和取舍」["github.com/alexeygrigo…
Reflexion 正是这种考察思路的典型载体。
为什么这题会出现在这一轮
Reflexion 通常出现在二面或者技术深度面,而不是一面。
一面的 Agent 题通常考核 ReAct 和 Tool Calling 的基本概念,候选人只要能画出执行循环、讲清楚工具调用的流程就能过。
到了二面,面试官开始探测候选人是否真正理解 Agent 的记忆机制和自我改进能力——而 Reflexion 正好覆盖这两个维度。
如果候选人还投的是 AI 应用开发、AI Agent 工程这类岗位,Reflexion 的追问频率会更高。
根据 OpenAI 和 Anthropic 的公开岗位描述["jobs.ashbyhq.com/OpenAI/577e… Agent 的长期记忆、反思机制和持续学习能力,Reflexion 是最常被拎出来考的代表方案。

能说清边界,这轮就稳了一半
常见追问
追问一:Reflexion 和 ReAct 的核心区别是什么?
这是最常见的追问,面试官想看你是不是只会描述 Reflexion,还是真的理解它在 Agent 演进脉络里的位置。
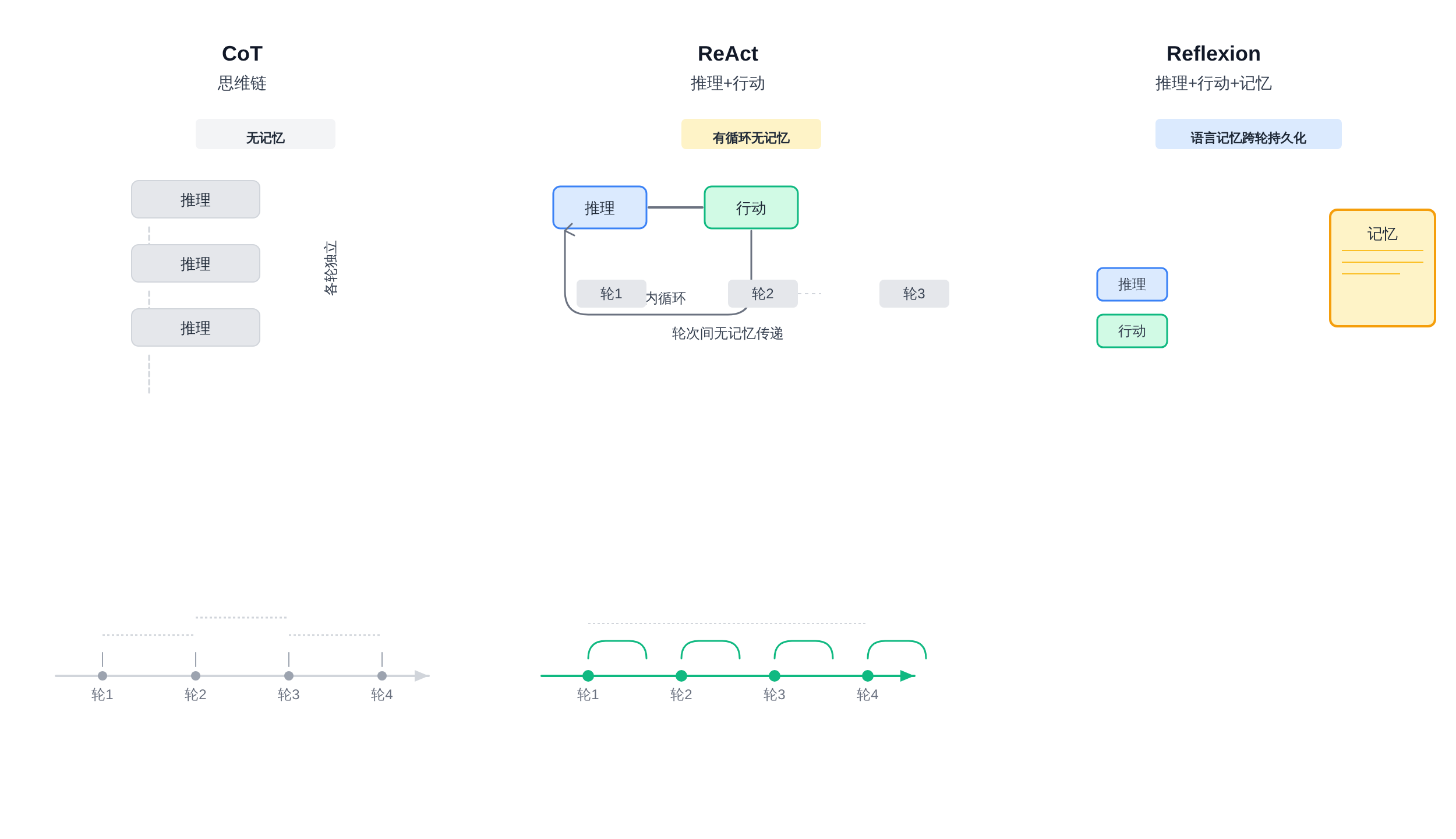
ReAct 是 Reasoning + Acting 的结合,核心是让模型在推理和行动之间交替:先思考(Reasoning),然后执行动作(Acting),动作产生观察结果,再继续推理。
ReAct 的问题在于它没有记忆:每次任务都是独立处理的,历史失败经验不会自动影响下一次推理。
Reflexion 在 ReAct 的基础上加了一条语言记忆回路。
它把 ReAct 的执行循环保留下来(Actor 生成推理 → 动作 → 环境反馈),同时新增了一条Evaluator → Reflexion → 语言记忆的反思链路。
关键在于:Reflexion 把失败经验写进了语言记忆,而 ReAct 没有这个机制。
一个更直白的说法:**ReAct 是单次闭环,Reflexion 是带历史记忆的持续改进闭环。
** 两者不是非此即彼的关系,Reflexion 本身可以建立在 ReAct 之上——Actor 就是一个 ReAct 风格的推理执行器。
正文图解 2
追问二:Reflexion 的反馈为什么不直接更新模型权重?
这个问题背后是整个 Reflexion 设计哲学的核心,也是最容易拉开差距的地方。
如果直接更新模型权重,需要做反向传播,需要梯度,需要重新训练,这套流程在生产环境里成本极高。更重要的是,一旦权重更新,模型的修改是不可逆的——你没法回滚,没法单独删掉某一条错误反馈。
Reflexion 选择语言记忆的原因恰恰在于它解决了这些问题:
成本极低。 不需要梯度计算,不需要 GPU 训练集群,语言反馈的生成和存储比模型训练便宜几个数量级。
反馈可审计。 每一条反思都是自然语言,哪次任务失败了、失败原因是什么、建议怎么改,全都有记录。线上出问题可以回溯,可以单独删除某条有问题的反思。
快速迭代。 同一条反思可以立即被下一次推理调用,不需要等模型重新训练才能看到改进效果。
支持多任务。 权重更新是全局的,学到的新能力会覆盖旧能力;语言记忆是按需检索的,同一个模型可以在不同任务里调用不同的历史反思,互不干扰。
但也要诚实说清楚代价:语言记忆的检索质量依赖 Embedding 模型的效果,记忆库大了之后检索延迟会上升,而且模型对记忆的依赖程度没有梯度更新那么「根深蒂固」——这是 Reflexion 在工程上的主要权衡。
追问三:Reflexion 的循环什么时候停下来?有没有死循环风险?
这个问题探测的是你对整个系统的终止条件是否有全局视角,而不只是理解单轮流程。
Reflexion 的循环终止有两种机制:
Evaluator 达到阈值。 当 Evaluator 给出的分数高于预设的通过阈值时,循环终止,当前轨迹被视为合格,输出最终结果。这是正常情况下的终止条件。
达到最大步数上限。 为了防止系统在某些任务上无限循环,Reflexion 预设了一个最大步数上限。
达到上限时,即使 Evaluator 还没达标,循环也强制终止,并返回「任务失败」或当前最佳结果。
死循环的风险是真实存在的,但工程上有对应的缓解手段:Evaluator 的打分标准必须设计得足够鲁棒,避免因为打分噪声导致反复横跳;
如果 Reflexion 模块本身生成的反思质量不够高(比如幻觉),可能产生误导性反馈,反而让下一轮更差——这是系统层面需要关注的风险。
面试时说到这一点,可以主动提一句:「这也是为什么实际工程里,Evaluator 的设计往往比 Reflexion 模块本身更关键——打分标准决定了整个反馈循环的质量上限。
」这句话展示的不是背书能力,而是工程判断力。

打分标准设计歪了,整个循环都是白干
易错点
易错点一:把 Reflexion 等同于「CoT + 一个反思步骤」
这是最常见的误答。很多候选人觉得 Reflexion 就是比标准 Chain-of-Thought 多了一步「想想哪里做错了」,这种理解差之毫厘谬以千里。
标准 CoT 只有一条推理链,没有 Actor,没有Evaluator,没有任何反馈回路。
Reflexion 是一个完整的系统架构:它有执行器(Actor)、有评估器(Evaluator)、有专门的反思生成模块(Reflexion),还有持久化的语言记忆存储。
这四个组件缺一不可,少了任何一个就不叫 Reflexion。
更关键的是,CoT 的反思是一次性的——反思完就结束了,不会影响下一次任务。Reflexion 的反思是写入记忆的,会影响后续所有相似任务的推理质量。这是两者在系统行为层面的本质差异。
易错点二:混淆 Reflexion 和 RAG
另一个高频混淆是把 Reflexion 的语言记忆等同于 RAG(检索增强生成)。两者确实都用了外部存储、都涉及向量检索,但目的和机制完全不同。
RAG 的检索是为了补充知识——当模型不知道某个事实时,从外部知识库里检索相关内容来增强回答。
Reflexion 的语言记忆不是为了补充知识,而是为了记录错误和改进经验,让模型下次不再犯同样的错误。
一个更直观的区分方式:RAG 检索的是「正确答案」,Reflexion 存储的是「错误教训」。
两者的检索信号不同(RAG 用问题 embedding 相似度,Reflexion 用任务类型或错误类型索引),存储内容的性质也不同。
易错点三:没有交代清楚 Evaluator 的打分标准
面试时必须主动交代清楚:Evaluator 的打分标准是什么?基于规则还是基于奖励模型?如果是奖励模型,谁来训练这个奖励模型?
打分粒度是二元(对/错)还是多档(1-10 分)?不同打分标准会导致反思内容的质量和方向完全不同。
能主动说清楚 Evaluator 的设计权衡,说明你不只是在背三层架构,是在思考整个系统的质量控制机制。

Evaluator 设计没讲清楚,这轮等于白答
其他注意事项
回答顺序建议
Reflexion 的面试回答有一个相对稳定的顺序,建议先走这个路径:
第一句:定位 Reflexion 在 Agent 体系里的位置。 先说清楚它是「在 ReAct 基础上加了语言记忆反馈回路的自我改进机制」,而不是上来就背三层架构。
让面试官先有一个框架参照,再深入细节。
第二句:三层架构。 Actor → Evaluator → Reflexion → 语言记忆,这是标准叙事,控制在 2-3 句内讲完。
第三句:强调设计边界——反馈存哪、为什么不更新权重。 这是拉开差距的关键一步,说完三层架构后立刻跟上来,不要等面试官追问。
**第四句:举一个具体场景。
** 比如「在代码生成任务里,如果 Actor 生成的代码通过了单元测试但逻辑有 bug,Evaluator 会给中等分数,Reflexion 会生成一条反思说『函数用了循环但没有处理空输入,下轮应该在推理时先考虑边界条件』,这条反思被写入记忆,下次遇到类似任务时 Actor 会先检查边界」。
这个顺序是「定位 → 架构 → 边界 → 场景」,先给坐标,再挖细节,最后落到工程实例上,面试官最容易跟上。
术语边界:Reflexion ≠ Self-RAG ≠ RLAIF
这三个概念在面试里经常被候选人混用,但它们各自解决的是不同层次的问题:
Reflexion 解决的是「Agent 在多轮任务执行中如何从失败经验里持续改进」的问题,核心机制是语言记忆反馈回路。
Self-RAG 解决的是「模型在生成过程中如何判断自己是否需要检索外部知识、以及生成内容是否可信」的问题,核心机制是训练一个专门的批评模型(critic model)来评估检索需求和生成质量["arxiv.org/abs/2310.11…
Self-RAG 是一个训练方法(需要微调 critic 模型),Reflexion 是外部记忆方法(不需要训练)。
RLAIF(Reinforcement Learning from AI Feedback)解决的是「如何用 AI 生成的偏好信号替代人工标注来训练奖励模型」的问题["docs.langchain.com/docs/concep… Reflexion 在生产阶段的运行时反馈是完全不同的层次。
一个简洁的区分方式:Reflexion 是运行时的自我改进(生产阶段),Self-RAG 有一部分是训练时的质量控制,RLAIF 是训练阶段的偏好学习。
层次不同、目的不同、实现方式不同。
面试节奏:什么时候主动上数据,什么时候只讲概念
Reflexion 的面试不需要强行上数据,但如果能说对数据锚点,会大幅加分。
可以提的数据点: 原始 Reflexion 论文(Shinn & Labesh, 2023)在 HotpotQA、ALFWorld 等基准上做了实验["arxiv.org/abs/2303.11… 相比标准 ReAct 在决策任务上有 10-20% 的准确率提升,在需要历史经验迁移的任务上提升更显著。
这些数据可以说,但不要为了显得专业硬背数字,说错数字反而扣分。
适合只讲概念的时刻: 如果面试官追问的是设计动机、边界条件、和 Self-RAG 的区别,这些场景不需要数据,用概念和工程判断回答更稳。
强行上数据反而显得你没有真正理解底层机制,只是在背实验结果。
节奏感一句话总结:框架和边界讲清楚再上数据,数据是锦上添花,不是雪中送炭。
项目里怎么说
可直接复述的项目说法
如果你在项目里实现过类似的反思机制,可以这样把 Reflexion 落到项目经验上:
「我在 XX 项目里实现过一个类似 Reflexion 的语言反馈模块。场景是 XX(任务类型),我们用一个基于规则的 Evaluator 给 Agent 的执行轨迹打分——如果任务成功率低于 80%,Evaluator 触发,Reflexion 模块生成一条反思并写入语言记忆库。后来发现打分阈值设置过低导致反思过于频繁,我们把阈值调整到 60% 以下才触发,有效减少了低质量反思的干扰。」(这是主动交代工程权衡,非常加分)
这个说法好在哪里:首先明确说了场景和任务类型,然后说清楚 Evaluator 的设计思路(基于规则),再自然带出一个实际的工程问题(阈值调优)——整段话展示的是你真正动手做过,而不是只会背论文。
如果没做过完整项目怎么补
没有完整 Reflexion 项目的候选人,可以从这几个方向补:
**课程或实验项目。
** 在大模型相关的课程项目里实现一个简化版 Reflexion——用 LangChain 或 LangGraph 搭一个三层架构,Evaluator 用规则打分,Reflexion 模块用 Prompt 生成反思,写入一个 ChromaDB 向量存储。
在 GitHub 上提交代码,面试时直接展示项目地址和效果截图。
**LangGraph 的 Memory 能力。
** LangGraph 本身支持 Agent 记忆机制的实现["github.com/langchain-a… LangGraph 的 MemorySaver 配合 create_react_agent 快速搭一个带反思记忆的 Demo。
这个方向补起来最快,而且 LangGraph 本身在面试里是高频考察项,一举两得。
**复现 Reflexion 论文的关键实验。
** 在 Hugging Face 上找 Reflexion 的开源实现,用 ALFWorld 或 HotpotQA 数据集跑一遍,对比 Reflexion 和标准 ReAct 的效果差异,把实验报告写成博客。
这个补法适合时间充裕的候选人,完成之后简历上能直接写「复现并对比了 Reflexion、ReAct、CoT 在多步推理任务上的表现」。
补项目经验的核心原则是:不需要堆数量,一个真正做过的项目比三个只看过教程的「项目」有用得多。 面试官三句话就能判断你到底有没有真正动手。

项目经验不求多,求深
延伸入口
- 原文归档:tobemagic.github.io/ai-magician…
- 公众号:计算机魔术师

参考文献
[1] 原始资料[EB/OL]. github.com/alexeygrigo…. (2026-04-18).
