---
title: Claude Opus 4.7 全面解读:编程能力+13%、视觉分辨率3倍、新增xhigh推理等级
digest: Anthropic 最新旗舰模型 Opus 4.7 深度分析:编程解决率提升13%、视觉分辨率3.75百万像素、法律/金融/安全领域全面突破,新增xhigh推理等级和/ultrareview代码审查功能。
---
2026年4月16日,Anthropic 正式发布了最新旗舰模型 **Claude Opus 4.7**。相比 Opus 4.6,新模型在编程、视觉、指令遵循等核心能力上实现了全面提升,同时保持了相同的价格。
本文用数据说话,带你全面了解这次升级的亮点。
---
Opus 4.7 最值得关注的四个数字:
![核心指标:编程+13%、视觉3.75M像素、价格不变、新增xhigh等级]

- **编程任务解决率 +13%**(93题基准)
- **视觉分辨率 3.75 百万像素**(前代3倍)
- **价格不变**:$5/百万输入,$25/百万输出
- **新增 xhigh 推理等级**
---
Opus 4.7 在编程领域的提升最为显著,尤其是**高难度、长周期任务**:
![编程基准对比:CursorBench 58%→70%、SWE-Bench 3倍]
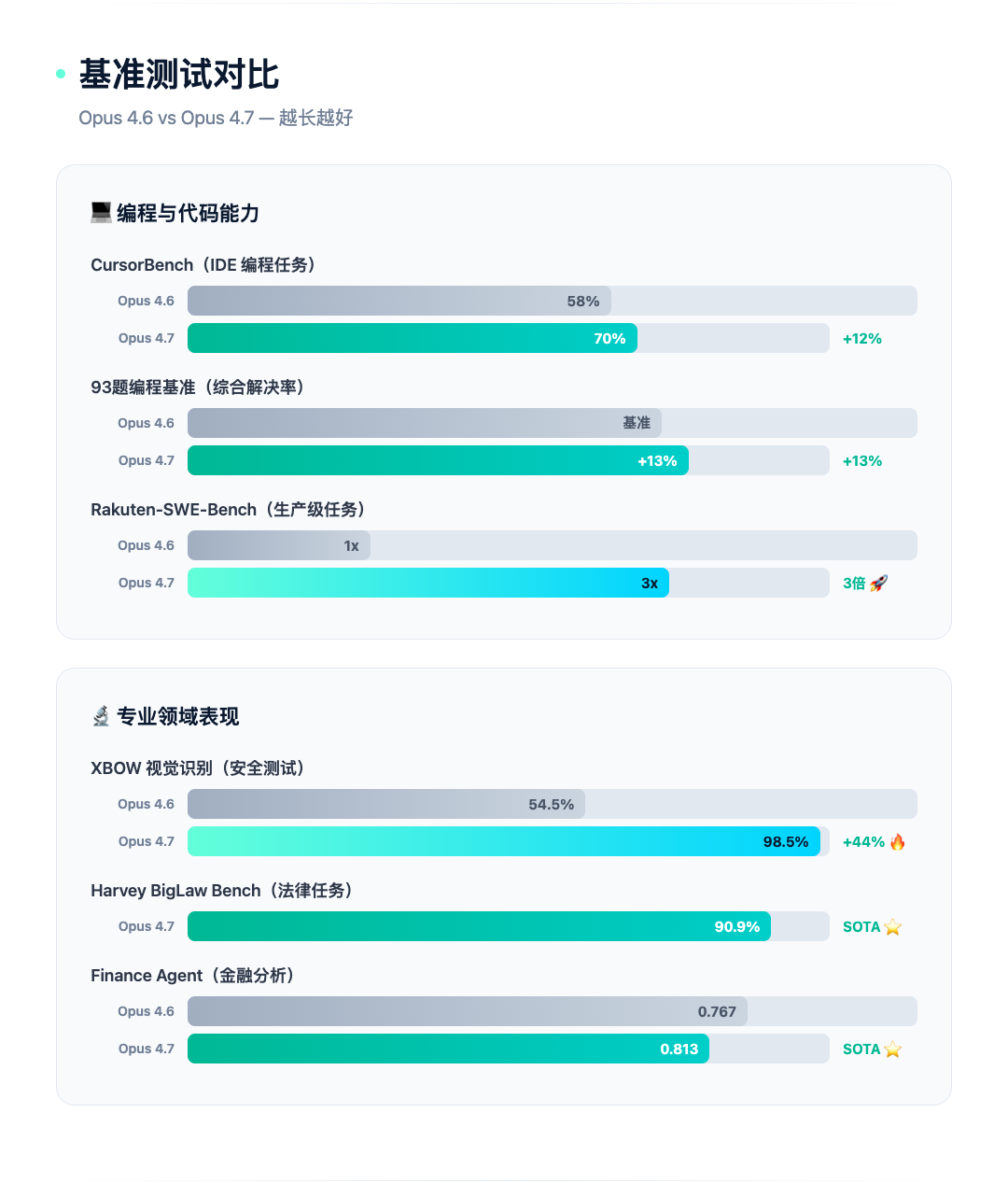
- **93题编程基准**:解决率提升13%,其中包括4道 Opus 4.6 和 Sonnet 4.6 都无法解决的难题
- **CursorBench**:从58%跃升至70%,IDE 编程场景显著进步
- **Rakuten-SWE-Bench**:生产级任务解决量达到前代的 **3倍**,代码质量和测试质量均有两位数提升
- **Notion Agent 实测**:工具调用错误减少到前代的 **三分之一**,+14% 的多步骤工作流成功率
一位开发者实测后表示:Opus 4.7 **自主从零构建了一个完整的 Rust 语音合成引擎**——包括神经模型、SIMD 内核和浏览器 Demo,然后还用自己的输出通过语音识别器进行了自我验证。
---
新模型支持最长边 **2,576像素** 的图片输入(约3.75百万像素),是之前 Claude 模型的 **3倍以上**。
这意味着可以读取更密集的截图、更复杂的图表,支持像素级精确的图像引用任务。安全测试工具 XBOW 的视觉识别准确率从 54.5% 飙升到 **98.5%**——他们称「我们最大的痛点直接消失了」。
---
Opus 4.7 在指令遵循上有**质的飞跃**——它会严格按字面意思执行每一条指令,不再跳过或忽略部分内容。
⚠️ **重要提示**:为旧模型编写的 prompt 可能需要重新调优,因为旧模型倾向于宽松解读指令,而新模型会严格执行。
---
在法律、金融、安全三大专业领域,Opus 4.7 均取得了突破性成绩:
![专业领域:XBOW视觉98.5%、Harvey法律90.9%、Finance Agent 0.813 SOTA]

- **法律**:Harvey BigLaw Bench 90.9%,能正确区分 assignment provisions 和 change-of-control provisions——这是此前所有前沿模型的难点
- **金融**:Finance Agent 0.813 刷新纪录,数据严谨性最佳——遇到缺失数据会如实报告,不再编造
- **安全**:XBOW 视觉识别 54.5% → **98.5%**,安全测试自动化成为可能
---
随 Opus 4.7 一同上线的三个重要更新:
![新功能:xhigh推理等级、/ultrareview代码审查、Task Budgets]

**1. xhigh 推理等级**
在 high 和 max 之间新增 xhigh 等级,更精细控制推理深度与延迟的平衡。Claude Code 已将默认等级提升至 xhigh。
**2. /ultrareview 命令(Claude Code)**
新增代码审查专用会话,自动检查代码变更中的 Bug 和设计问题。Pro 和 Max 用户可免费体验 3 次。
**3. Task Budgets(API 公测)**
新增任务预算功能,引导 Claude 在长任务中合理分配 token 消耗。
---
来自早期测试者的真实反馈:
![业界评价精选:来自财务科技、Hex、XBOW等平台的反馈]

> 「低努力的 Opus 4.7 ≈ 中等努力的 Opus 4.6:更智能、更高效。」—— Hex 数据平台
> 「它在规划阶段就能发现自己的逻辑缺陷,并加速执行——远超之前的 Claude 模型。」—— 财务科技平台
> 「视觉识别从 54.5% 飙升到 98.5%,我们最大的痛点直接消失了。」—— XBOW 自动化安全测试
---
Claude Opus 4.7 不是一次小修小补,而是在**最难的任务**上实现了显著提升。对于开发者而言,最值得关注的是:
1. 编程能力的跃升,尤其是长周期、多步骤任务
2. 视觉分辨率的大幅提升,解锁了新的多模态场景
3. 指令遵循的增强,意味着需要重新审视现有 prompt
4. 价格不变,性价比进一步提升
---
*数据来源:anthropic.com/news/claude-opus-4-7*
*作者:AI智元星球*

