

2026 年 2 月,"Harness Engineering"这个词在 AI 工程圈突然火了。Mitchell Hashimoto 首先命名了这个实践,OpenAI 跟着发了一份百万行代码的实验报告,Martin Fowler 补上深度分析——短短几周,它就成了绕不开的话题。
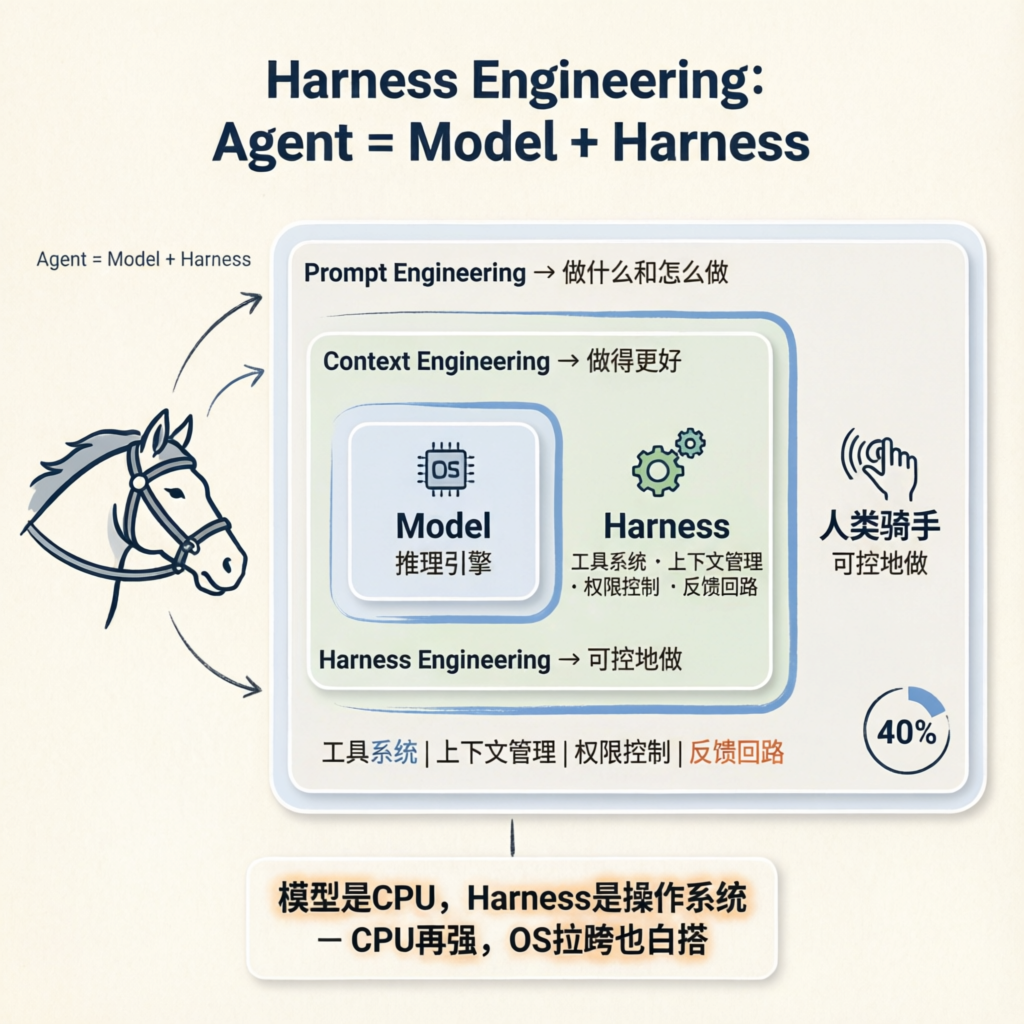
这个术语背后的东西其实一句话就能说清:Agent = Model + Harness。模型负责推理,剩下的全部是工程——工具系统、上下文管理、权限控制、反馈回路。过去大家以为瓶颈在模型不够聪明,现在发现错了:瓶颈在外围工程。
一、模型智力已过线,真正的问题是工程
2024 年我们还觉得自己比 GPT 聪明,2025 年开始承认模型比自己高明,到 2026 年模型的推理能力已经远超普通人类水平。继续卷模型,普通人已经感受不到差异了。
关键问题从"模型够不够聪明"变成了"能不能帮我把事儿做成"。
有个实验很说明问题:Can.ac 仅仅改了 Grok Code Fast 1 的工具接口格式,编码基准分数就从 6.7% 跳到了 68.3%。没有动任何模型权重,只改了 Harness。LangChain 也通过 Harness 改进,在 Terminal Bench 2.0 上从第 30 名飙到第 5 名。
DeepMind 的 Agents 团队做了更直接的验证:固定模型不变,只换 Harness(也就是模型外围的基础设施),性能就产生了巨大差距。Claude Code 的商业价值蒸蒸日上,它的本质就是在做 Harness 工程。
二、上下文窗口不是越大越好
给 Agent 塞一堆 MCP 工具、冗长文档和对话历史,不会让它变聪明——只会让它变笨。
Dex Horthy 给了量化数据:以 168K token 的上下文窗口为例,用到大约 40% 就开始走下坡路。前 40% 是 Smart Zone——推理聚焦且准确;超过这个阈值就是 Dumb Zone——幻觉、死循环、格式错误的工具调用齐上阵。
Anthropic 的 Carlini 在 C 编译器项目里花了大量精力做"上下文污染缓解":日志写文件不输出控制台、用 grep 友好的错误格式、预计算聚合统计而不是甩原始数据出来。原因很简单——上下文一旦爆了,Agent 直接掉进 Dumb Zone。
经验公式记住一条就够了:上下文利用率保持在 40% 以下。更多 token 不等于更好结果。
三、什么是 Harness?
马具的隐喻
"Harness"本意是马具——缰绳、鞍具那一套。LLM 就像一匹蛮力十足但方向感不太行的马:跑得快,但容易跑偏。不加 Harness 的 Agent 像草原上的野马,Harness Engineering 就是给它套上缰绳:让人类能稳稳骑乘,同时确保马往正确的方向跑,陷进泥潭时能把它拉出来。
三层工程的关系
很多人会把 Prompt、Context、Harness 混为一谈。它们是嵌套关系,层层递进:
- • Prompt Engineering——告诉模型"做什么和怎么做"
- • Context Engineering——让模型"做得更好"
- • Harness Engineering——确保模型"可控地做"
Phil Schmid 的比喻最到位:模型是 CPU,Harness 是操作系统。 CPU 再强,OS 拉胯也白搭。
四、Harness 的四大支柱
OpenAI、Anthropic、Carlini 等多个独立团队的实践反复 converged 到四个共同模式。
1. 上下文分层:恰好够用,不多不少
每个团队都发现:把所有指令塞进一个文件根本没法扩展。解决方案是分层加载、渐进披露。
OpenClaw 的 Skills 机制是个好例子。默认不加载所有技能的详细内容,先扫描技能列表(只看名字和描述),判断需要用哪个再去读对应的 SKILL.md。既省了上下文空间,又保持了灵活性。
OpenAI 的做法类似:从单个巨大的 AGENTS.md 迁移到分层架构,构建小型入口文件指向深层的事实源(设计文档、架构图、执行计划)。一个后台 Agent 定期扫描过期文档并提交清理 PR——由 Agent 为 Agent 维护的文档。
2. Agent 专业化:专才优于通才
专注于特定领域、拥有受限工具的 Agent,永远比拥有全部权限的通用 Agent 靠谱。
这不是纯组织考虑——专业化本身就是上下文管理策略。每个专家携带更少的无关信息,所以天然运行在 Smart Zone 内。
Carlini 的 C 编译器项目把 Agent 分为四类角色:编译器核心、去重、性能优化、文档。LLM 生成的代码经常重新实现已有功能,他专门分配了一个"去重 Agent"来解决。Vasilopoulos 部署了 19 个领域特定的 Agent。
3. 持久化记忆:状态存在文件系统上,不在上下文窗口里
每次新 Agent 会话从零开始,通过文件系统制品重建上下文。就像一个项目组全是轮班工程师——每个人上岗时对之前的进展一脸懵,只能靠交接文档恢复状态。
Anthropic 的两阶段方案很经典:初始化 Agent 建立 init.sh、进度文件和初始 git 提交;后续编码 Agent 每次做出增量进展后留下结构化更新。关键发现是:用 JSON 追踪 feature 状态比 Markdown 更有效,因为 Agent 不太会不小心破坏结构化数据。
OpenClaw 的双层记忆也值得参考:长期记忆(MEMORY.md,每次自动注入)+ 每日记忆(追加写入、按需搜索),检索用 BM25 + 向量双路召回,还有时间衰减机制。
4. 结构化执行:先规划,再动手
Boris Tane 说得最干脆:"永远不要让 Agent 在你审查和批准计划之前写一行代码。"
把思考与执行分开:理解 → 规划 → 执行 → 验证。Anthropic 把这个做到了极致——初始化 Agent 先生成超过 200 个功能的结构化列表,全部标为 failing,后续 Agent 每次只处理一个,完成后提交 git 和进度更新。
Huntley 的 Ralph Wiggum Loop 提供了反压思路:上游给确定性设置和一致上下文,下游用测试、类型检查、Lint、CI 拒绝无效工作。
五、五大落地难题与解法
无限循环
Agent 遇到无法解决的错误时,可能在同一个死角无限重试。
解法: 上下游反压机制。上游保证输入确定,下游通过测试和 CI 拒绝无效工作。Claude Code 的循环在执行完一轮后会确认问题解决才返回结果,不会无脑重来。
上下文爆炸
一味堆 Prompt、历史记录和工具返回结果,推理耗时剧增、成本飙升。
解法:** 压缩 + 修剪 + 记忆分层。OpenClaw 支持三种压缩策略自适应切换,工具返回结果头尾保留中间省略(裁剪不超过 50%),长期记忆按需注入、每日记忆搜索获取。
权限失控
Agent 删文件、调外部 API 时缺乏审批或熔断。
解法: 三层纵深防御——沙箱 + Hook + 权限分级。OpenClaw 的文件系统沙箱限范围、命令执行白名单 + 人工确认、网络白名单。Hook 系统可以在工具执行前拦截校验参数:比如阿里云 ECS 实例 ID 必须以 i- 开头,通过正则校验直接拦住错误参数,迫使模型修正而不是盲目执行。
质量不可控
Agent 写完代码就跑个单元测试,压根没做端到端验证。
解法: 强制测试闭环 + CI 流水线。OpenAI 的自定义 Linter 不仅标记违规,还在错误消息里直接告诉 Agent 怎么修——工具在 Agent 工作时顺便教会它。Carlini 的总结很到位:"我必须不断提醒自己,我是在为 Claude 写测试框架,不是为自己写。"
成本不透明
上下文塞满导致 token 消耗飙升,效果反而下降。
解法: 控制在 40% 利用率以内 + 可配置压缩模型 + KV Cache 优化。OpenClaw 支持用便宜模型做上下文压缩,压缩操作设超时防止卡死。
六、顶级团队的实战
OpenAI:零手写的百万行代码
三名工程师五个月构建百万行代码产品,手写代码 0 行,合并约 1,500 个 PR,效率提升约 10 倍。
核心原则就几条:设计环境而非编写代码(Agent 卡住时诊断缺什么能力让它自己补上)、依赖方向用 Linter 机械化 enforce、所有知识放代码仓库当唯一事实源(Slack 和 Google Docs 对 Agent 等于不存在)、对抗熵(最初每周五手动清理 AI Slop,后来自动化为后台任务)。
Anthropic:16 个 Agent 造 C 编译器
两周、16 个并行 Opus 4.6 实例、约 2,000 次 Claude Code 会话、产出 10 万行 Rust 代码。GCC torture test 通过率 99%,能编译 PostgreSQL、Redis、FFmpeg、CPython、Linux 6.9 Kernel 等 150+ 真实项目,总 API 成本约 $20,000。
几个关键设计:日志写文件不占上下文、确定性测试子采样解决 Agent 时间盲区、四类专业化分工。
Stripe:推个 Slack 任务就走的无人值守
开发者发个 Slack 任务就离开,Agent 从写代码、跑 CI 到提 PR 全程包办,人只在最后审查环节介入。Toolshed MCP 提供近 500 个工具,隔离的 Devbox 环境与人类工程师用同样的开发环境。核心洞察:Agent 需要和人类工程师一样的上下文和工具——不是事后补上的集成,而是一开始就得是一等公民。
Hashimoto 的 Ghostty:每天最后的 30 分钟
AGENTS.md 的每一行对应一个过去的 Agent 失败案例——现在被永久预防。工作模式:每天最后 30 分钟启动 Agent,让它非工作时间干活,第二天早上拿到"暖启动"的成果开始上班。
七、Harness vs Workflow:主导权之争
很多人问:Workflow 也能约束 Agent,为什么要搞 Harness?
区别在于主导权是谁。Workflow 把大模型当成节点,按预设流程 A→B→C 执行;Harness 把大模型当成主体,给它自主决策的空间但套上缰绳。基础模型越来越强的当下,Harness 更能发挥模型能力,同时确保不过失。
| Workflow | Harness | |
|---|---|---|
| 执行路径 | 固定线性 | 动态,Agent 自主规划 |
| 模型角色 | 执行者 | 主导者(受约束) |
| 异常处理 | 预设之外会断裂 | 可动态调整 |
| 适用场景 | 确定性高的简单流程 | 复杂、不确定的长周期任务 |
八、业界共识与分歧
六大共识
- 1. 瓶颈在基础设施,不在模型智能。 Can.ac 改 Harness 就让分数翻倍是最直接证据。
- 2. 文档必须是活的。 AGENTS.md 每一行对应一个历史失败案例,后台 Agent 定期清理过期内容。
- 3. 思考与执行必须分离。 所有团队独立发现了"先规划再执行"模式。
- 4. 上下文不是越多越好。 40% 甜区有量化数据支撑。
- 5. 约束必须机械化。 "不能机械执行的规则,Agent 一定会偏离。"
- 6. 工程师角色在变。 从写代码转向设计环境和管理。
三大空白区
这些方向最值得探索:
- • 棕地改造: 所有成功案例都是绿地项目。十年历史的遗留代码库怎么引入 Harness?零方法论。Martin Fowler 打比方:"在从没跑过静态分析的代码库上跑静态分析——你会被警报淹没。"
- • 行为验证: 大家擅长约束 Agent 不做错事,但验证 Agent 做对了事远未解决。
- • 长期可维护性: 怎么防止"功能没问题但维护性很差"的代码渗进代码库?没人回答。
九、30 年软件工程的一条暗线
Harness 的出现不是偶然。回顾三十年,工程师一直在跟系统复杂度打架:
- • 1994 GOF 设计模式 → 驾驭对象复杂性
- • 2002 企业应用架构模式 → 驾驭架构复杂性
- • 2010 微服务 → 驾驭分布式复杂性
- • 2017 DDIA → 驾驭数据系统复杂性
- • 2026 Harness → 驾驭智能体不确定性
贯穿三十年的不变主题是抽象。加上结构化,把混乱中的本质拎出来——设计模式是抽象,微服务是抽象,云计算是抽象,Harness 也是抽象。
我们第一次在驾驭一个不确定性的系统。 以前的复杂系统都是确定性的——代码写什么就执行什么。Agent 不同,它是概率机器,你期待一个输出,但它不一定照做。Harness 就是那条缰绳。
十、工程师的能力转型
工程师不会失业,但码农会。
码农 = 只写代码的人。Agent 能生成代码,码农的价值就被替代。
工程师 = 能设计并驾驭复杂系统的人。核心能力不在写代码,而在三件事:理解系统复杂性、抽象和结构化思维、驾驭不确定性。
业务理解是你的护城河。不是 Agent 能做什么,而是你懂什么决定了你能设计和驾驭什么。在 AI 时代,个体需要懂的更多而不是更少。
十一、立即可做的八件事
- 1. 创建并维护 AGENTS.md——每次 Agent 犯错就更新一条,不是一次性文档
- 2. 代码仓库当唯一事实源——团队知识版本控制,别放 Slack 或 Wiki
- 3. 构建带修复建议的自定义 Linter——工具教 Agent 怎么修
- 4. 提供端到端测试工具——浏览器自动化显著提升验证质量
- 5. 增量执行——每次会话处理一个功能,完成后提交 git 和进度
- 6. 分层管理上下文——Tier 1/2/3 渐进式披露,避免单文件堆叠
- 7. 上下文利用率控制在 40% 以下——更多 token 不代表更好结果
- 8. 定期垃圾回收——自动化 Agent 清理技术债
"AI 编码的兴起并没有取代软件工程的工艺——它抬高了工艺的门槛。" —— Addy Osmani
凡此过往,皆为序章。模型越强,Harness 越重要。与其等更强的模型出来,不如先把缰绳套上马背。
