

最近鸭鸭在脉脉看到一条面试相关的讨论:
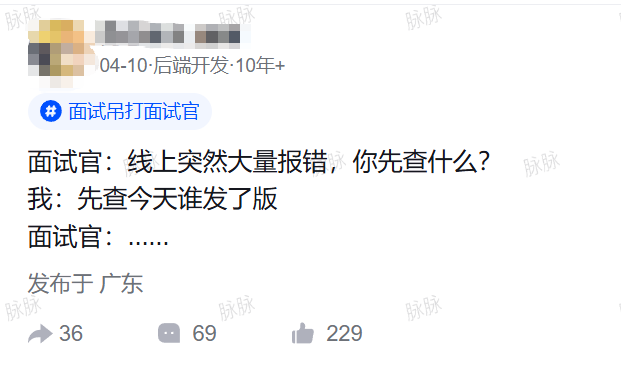
看起来像个段子,但评论区不少一线工程师都给出了非常认真的讨论。
最高赞的评论只有四个字:“经验之谈。”
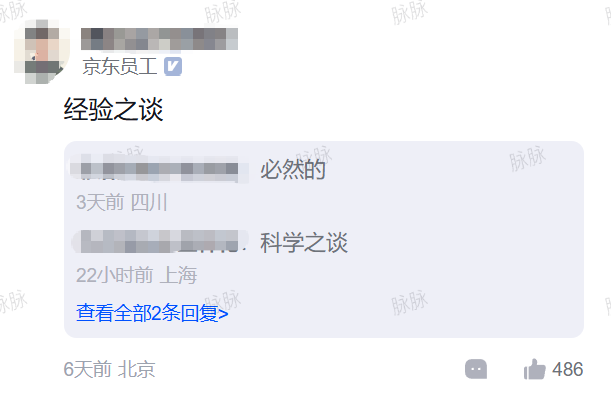
紧接着是字节员工说:“查变更是标准动作啊,这有啥无语的。”
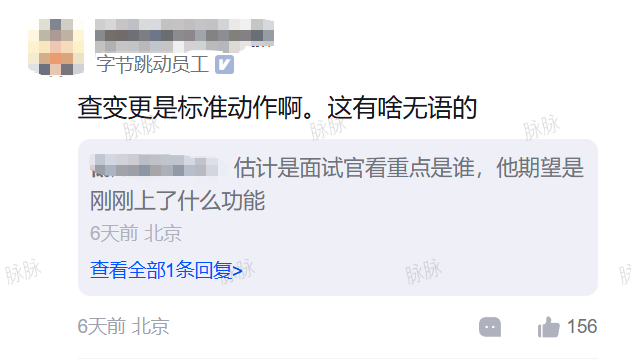
立马有人上来补刀:“先追责,再解决问题。” 底下立刻有人跟上:“90% 的问题都是发版引起的。”
评论区的共识非常明确:
查变更,是线上故障排查里最基础、也最有效的第一步。
为什么“先查发版”是工程师的本能反应?
任何在后端或运维岗位上踩过坑的工程师,都知道一个规律:
绝大多数线上事故,都与最近一次变更直接相关。
不管是代码发布、配置改动、库表调整,还是流量切换、灰度放量,只要系统在某个时间点发生了改动,就意味着引入了新的不确定性。
这也是为什么在大厂的故障复盘模板里,第一页永远是一张变更时间线:
- 故障发生前后,是否有发布?
- 涉及的是哪个服务、哪个模块?
- 是全量还是灰度?
- 有没有影响到依赖的下游?
很多时候,把变更信息摆清楚,问题就已经定位一半了。
所以“先查今天谁发了版”这句回答,并不是一句玩笑,而是工程师经验积累后的第一反应。
但在面试里,这样回答真的够吗?
面试官抛出“线上大量报错你先查什么”这类题目时,真正想考察的并不是你会不会甩锅,而是你的排查思路:
- 有没有明确的优先级?
- 能不能结构化地思考?
- 是否具备快速止血与根因分析的能力?
一句“先查今天谁发了版”虽然真实,但在面试场景下会显得跳跃、不完整,很难让面试官判断你的整体工程素养。
更稳妥的答法,建议分两步走。
第一步:先抛出最可能的根因,体现一线经验。
可以这样说:
“遇到线上大量报错,我会优先确认最近是否有变更。因为根据以往经验,多数线上故障都和近期发布或配置修改直接相关。”
这一步既真实,又能立刻让面试官感受到你不是纸上谈兵。
第二步:补一套完整的排查流程,体现方法论。
- 看监控:QPS 是否异常?错误率集中在哪个接口?响应延迟有没有整体上涨?
- 看日志:报错堆栈定位到哪一层?数据库、缓存、下游服务还是本服务?
- 看变更:发布记录、配置中心、数据库变更,是否与故障时间吻合?
- 做决策:能回滚就先回滚止血,再基于日志和监控数据做根因分析。
先经验,再方法,这才是一个合格的线上故障排查回答。
很多同学在准备后端面试时,把大量时间花在背八股文上,却忽略了线上场景题这一类高价值题目。
但实际面试里,这类题非常常见:
- 接口突然变慢了,怎么排查?
- Redis 突然大量 miss,怎么定位?
- 服务 CPU 飙升到 100%,怎么处理?
- 某张表的查询突然变慢,该从哪入手?
这些题目没有唯一答案,但有标准思路。谁能把思路说得清楚、覆盖全面,谁就能在面试里脱颖而出。
……
今天和大家分享一篇后端面经。
【数据同步过程中出现 OOM 内存溢出,应该如何排查和解决?】
回答重点
先快速排查,找到 OOM 的原因:
- 看 OOM 日志:初步定位可以看 JVM 崩溃时的错误提示(比如Java heap space是堆内存不够,GC overhead limit exceeded是GC太努力还是清不掉垃圾,Metaspace或者PermGen space是方法区溢出),锁定是堆还是方法区的问题。
- 生成堆Dump:用
jmap -dump:format=b,file=heap.bin <进程ID>手动生成,或加JVM参数-XX:+HeapDumpOnOutOfMemoryError自动保存崩溃时的内存快照。 - 分析堆文件:用工具(如Eclipse MAT、VisualVM)打开,重点看占用内存最大的对象(比如100万条数据的List),以及谁在持有这些对象(GC Roots引用链),定位到代码。
数据同步常见 OOM 原因及解决方法:
1)批量加载数据太贪心:
比如一次性从数据库查 100 万条数据到内存(比如SELECT * FROM user),直接撑爆堆。
解决方案:分批次处理,每次查 1000 条,处理完再查下一批;或给 JDBC 加 setFetchSize(Integer.MIN_VALUE),让数据库分批传数据。
2)缓存只进不出:
比如用静态HashMap存同步的用户信息,没设过期时间,越同步缓存越大。
解决方案:给缓存加“淘汰规则”,比如用 Guava Cache 设置 maximumSize(10000)(最多存1万条)或expireAfterWrite(1, HOURS)(1小时后自动删)
3)JVM参数不合理:
比如堆内存设太小(比如-Xmx1g),或用Serial GC处理大堆,GC效率极低。
解决方案:调大堆内存(比如-Xmx4g),或换G1 GC(-XX:+UseG1GC),G1会自动分块回收,更适合大内存场景。
参考:
建议大家 观看这个视频,快速学习企业级数据同步的实现方案。
扩展知识
JDBC 流式查询的原理
普通查询模式下,JDBC 驱动会把整个结果集一口气读进内存。假设一张表有 500 万条数据,每条 1KB,光结果集就要吃掉近 5GB 内存,JVM 不炸才怪。
流式查询的核心思想是边读边处理。设置 setFetchSize(Integer.MIN_VALUE) 之后,驱动不再缓存完整结果集,而是建立一个长连接,每次从数据库拿一小批数据过来处理。
具体每批多少条取决于网络包大小和单行数据量,一般是 16KB 一个包。
Statement stmt = conn.createStatement(
ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY);
stmt.setFetchSize(Integer.MIN_VALUE);
ResultSet rs = stmt.executeQuery("SELECT * FROM big_table");
while (rs.next()) {
process(rs);
}
流式查询有个坑:查询期间这条连接会被独占,不能执行其他 SQL,也不能提前关闭 ResultSet,否则会报 Streaming result set 相关异常。
所以流式查询适合一次性跑批的场景,不适合在线业务。
数据同步场景的内存优化实践
Canal 做 MySQL binlog 同步的时候,默认会把解析出的事件攒成 batch 再投递。如果下游消费慢,这些 batch 就会在内存里堆积。可以调小 canal.instance.memory.buffer.size 限制缓冲区大小,宁可让上游阻塞也别把内存撑爆。
Flink 做实时同步时,State 是个大内存户。用 RocksDBStateBackend 替代 FsStateBackend,把状态数据落到本地磁盘,内存里只保留热数据。虽然性能会降一点,但内存占用能从几十 GB 降到几个 GB。
Kafka Connect 同步数据时,要注意 max.poll.records 和 fetch.max.bytes 两个参数。一次拉太多消息内存受不了,一次拉太少吞吐又上不去。建议根据单条消息大小来算,控制每次拉取的数据量在 100MB 以内。
篇幅有限,更多 场景 相关面试题可以进入面试鸭(mianshiya.com)进行查阅。
