

在数据平台调度开发过程中,批处理、实时处理与微批处理作为核心的数据处理模式,其任务设计的合理性直接决定了整个数据链路的稳定性与效率。不同处理模式的核心逻辑各有侧重,唯有精准把握其设计精髓,才能在应对不同业务场景时游刃有余。
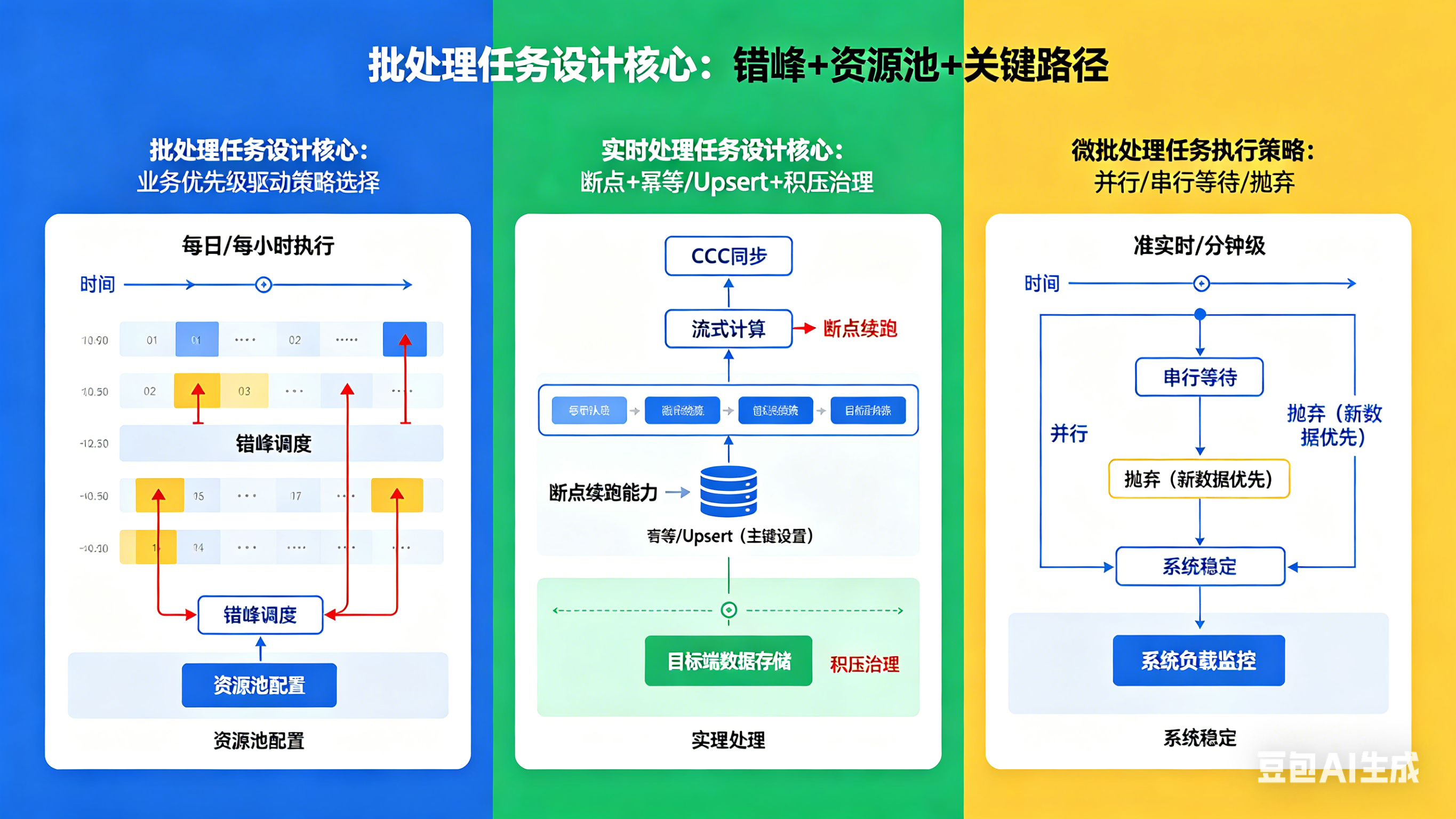
批处理任务(多为每日或每小时执行) 的设计核心的是“错峰 + 资源池 + 关键路径”三者结合。在实际生产中,大量任务若在同一时刻集中启动,极易造成资源拥堵、系统卡顿,因此错峰调度是避免此类问题的基础;同时,通过资源池的配置,将无序的并发转化为可控的任务队列,既能避免资源浪费,也能防止单个任务占用过多资源影响整体流程。
而实时处理任务(如CDC同步、流式计算),则需聚焦“断点 + 幂等/Upsert + 积压治理”,断点续跑能力可确保任务重启后无需全量重放数据,大幅提升效率,而目标端主键的设置则是保障数据一致性的关键,避免因重复写入导致数据错乱;积压治理则能防止数据堆积拖垮系统,确保实时链路的顺畅运行。
介于批处理与实时处理之间的微批任务(准实时、分钟级),则需根据业务优先级选择合适的执行策略——并行、串行等待或抛弃。当新数据的时效性远高于历史数据时,采用抛弃策略可有效避免旧任务堆积,防止系统负载过高,这比盲目扩大并发更具安全性,能在保障核心需求的同时维持系统稳定。
触发与执行策略:时间触发 vs 事件触发(并行/串行等待/抛弃)
调度任务的触发与执行策略,需结合业务场景的时效性、一致性需求灵活选择,不同策略各有适配场景,合理搭配才能实现效率与稳定的平衡。其中,时间触发是最常用的方式,按每日、每小时等固定周期触发,非常适合批处理主链路,比如日报生成、监管报表统计、晨会所需数据等场景,其优势在于可预测性强、运维成本低,且便于制定和落地SLA(服务等级协议),让数据产出时间可控。
与时间触发相比,事件触发更贴近实时或准实时需求,当文件到达、消息推送、数据落库等事件发生时,自动触发后续任务链路,适合“数据到了就处理”的场景,既能减少无效的空跑任务,也能降低数据延迟,让数据更快服务于业务。
在执行策略的选择上,并行策略追求吞吐效率,适用于互不影响的分支任务,但并行数量并非越多越好,必须配合资源池和并发上限进行控制,否则会将调度层面的压力转移到数据库等核心组件,反而引发系统故障。
串行等待策略则主要用于保障任务的互斥性与数据一致性,比如同一目标表写入、共享资源使用,或必须按顺序累加口径的任务,通过“等待前一个任务完成再执行下一个”的逻辑,避免数据覆盖、资源竞争等问题。抛弃策略则主要应用于分钟级微批、准实时场景,若业务允许“只保留最新结果”,抛弃旧任务实例可有效防止积压拖垮系统,是一种更安全的流量控制方式。
此外,资源池的并发治理是重中之重,通过按部门、业务链路或工作流配置并发上限,并结合任务优先级,可确保关键链路优先执行,避免不同业务、不同任务之间相互争抢资源,导致整个系统处理速度变慢,将不可控的并发转化为可控的任务队列,是保障系统稳定性的核心手段之一。
逻辑任务组件:把复杂编排做成“可读、可管、可复用”
调度任务的逻辑编排并非越复杂越好,核心是实现“可读、可管、可复用”,通过合理运用各类逻辑任务组件,降低开发成本、减少维护难度,同时提升流程的规范性。其中,依赖任务(Dependent)是ETL编排的核心,用于清晰表达任务间的AND/OR依赖、跨工作流依赖、跨项目依赖,明确“上游任务何时才算完成”,让整个链路的依赖关系一目了然,避免因依赖模糊导致任务执行异常。
子工作流(SubProcess)则是工程化复用的核心,在实际开发中,很多链路会被反复使用,比如数据质量校验、对账、数据清理复原等,将这些常用链路封装成子工作流,可减少复制粘贴带来的冗余,也能避免不同工作流中相同逻辑出现分叉演进,导致口径不一致。需要注意的是,子工作流应只消费主流程传入的biz_date、窗口、批次等参数,不单独重新计算一套逻辑,确保同一口径的统一性。
Trigger、循环、翻牌等则属于进阶能力,主要用于解决特殊场景需求,比如数据到达触发、按分区或按天循环处理、按批次分页处理等。在实际开发中,应遵循“先简单后复杂”的原则,先用基础调度能力满足常规需求,当复杂场景无法通过简单调度实现时,再引入这些进阶能力,避免过度设计增加维护成本。而判断是否需要封装子工作流的核心标准,就是看同一段逻辑是否在多个工作流中反复出现,一旦出现复制粘贴的情况,就建议封装为子工作流,避免后续治理失控。
开发/生产环境隔离:同名资源 + 配置区分
开发与生产环境的隔离是保障生产系统稳定的基础,其核心原则是“同名资源策略”,即开发环境与生产环境使用同名的数据源、同名的引用(例如都命名为SalesDB),这样一来,工作流与任务的逻辑无需修改名称和引用,仅通过环境配置即可实现切换,大幅降低上线时的改动面,减少人为操作错误。
环境隔离的核心是“隔离配置,而非隔离名字”,连接地址、端口、账号权限、网络环境等核心配置,分别属于开发环境(dev)和生产环境(prod),同名策略确保了逻辑的一致性,而配置的区分则保障了生产环境的安全性和稳定性。除了数据源,工作流、脚本、Git引用、日历/定时、告警组、资源池、环境变量等资源,也建议采用同名管理,通过“同名+不同配置/不同授权”的方式,实现全链路的环境隔离。
在网络隔离方式上,主要分为两种:一种是强隔离生产环境,采用“开发侧导出配置(Json/Excel等)→ 审批 → 导入生产”的流程,虽然流程相对繁琐,但安全边界清晰,适合对安全性要求极高的场景;另一种是网络联通模式,支持一键部署,追求交付效率,但必须配合Diff查看变更和审批流程,确保只有被授权的改动才能上线,兼顾效率与安全。
需要特别注意的是,上线时需要管控的不仅是工作流本身,数据源授权、告警组、资源池、定时策略、环境变量等所有与任务运行相关的资源,都属于上线对象,必须纳入发布清单。建议将上线流程标准化,做成“标准发布包”,包含变更说明、Diff截图/记录、回滚方案、影响范围等内容,让上线过程可追溯、可回滚,提升客户使用的安全感和可靠性。
命名规范的核心原则:让开发“可搜索、可治理、可交付”
在调度开发中,命名规范看似是“细节”,实则直接影响开发效率、运维成本和交付质量,其核心原则是让开发过程“可搜索、可治理、可交付”。清晰性是命名的首要要求,一个规范的名称,应能让人一眼看出任务的用途、数据的流向、所属的层级,否则一旦出现问题,只能通过翻日志、询问开发人员才能定位,大幅降低排障效率。
一致性则是命名规范的核心,统一的命名格式便于批量操作、自动化管理和团队协作,命名越统一,后续的治理成本越低,尤其是当任务数量从几十增长到几千时,统一命名能避免混乱。可扩展性则要求命名能适应业务的增长,通过命名+标签的组合,实现任务的快速筛选和定位,而不是依赖开发人员“记住”每个任务的用途。
需要明确的是,命名的核心目的不是“好看”,而是让上线、回滚、依赖引用、告警定位等操作更可靠——在调度平台中,名称就是任务和资源的唯一标识,直接影响整个链路的稳定性。以下是针对各类资源的命名模板,客户可直接照抄使用,兼顾规范性与实用性。
命名模板表(1/2):项目 / 工作流 / 工作流任务
该表建议直接用于PPT展示,左侧为命名模板,右侧为可直接套用的示例,下方说明命名逻辑,便于团队统一执行。
| 资源类型 | 命名模板(建议) | 示例(可直接套用) | 说明 |
|---|---|---|---|
| 项目 Project | 业务领域_项目类型 | Sales_Analysis / 数据分析部_客户管理主题 | 项目名体现业务范围/主题,且唯一,便于搜索与集成协作。 |
| 工作流 Workflow | 层级_功能_数据主题 +(可选标签) | ODS_Extract_Orders(标签:Daily) / DW_Calculate_Metrics_Weekly(标签:DW层) | 工作流名要反映层级、功能、主题;标签用于补充周期/层级/特殊筛选,不必每个都打标签。 |
| 工作流任务 Task | 层级_目标表名称(可含主题域编号) | ODS_T01_ExtractOrders / DW_T02_CleanSales / DW_T03_CalculateMetric | 任务名在工作流内必须唯一,并会作为“导入更新/依赖引用”的唯一标识,不能随意修改。 |
| 落地建议:先明确“层级/主题域编号/目标表”的统一规则,后续所有任务都按照该口径命名,能显著提升排障效率,减少因命名混乱导致的沟通成本和操作错误。 |
命名模板表(2/2):数据集成任务 / 数据源 / 标签 / 脚本与其它资源
| 资源类型 | 命名模板(建议) | 示例(可直接套用) | 说明 |
|---|---|---|---|
| 数据集成任务(多表) | 来源系统_目标系统_任务类型_时间周期 | MySQL_HDFS_FullSync_Daily / FTP1_Delta_Incr_Daily / Oracle_X_Doris_CDC | 名字直观看出“从哪到哪、全量/增量/CDC、周期”;多表不必把每张表写进名字,监控会细到表级。 |
| 数据集成任务(单表) | 目标表_任务类型_时间周期 | t01_client_Incr_Daily | 单表更聚焦目标表,适合非结构化/虚拟表或特殊场景。 |
| 数据源 DataSource | 数据源引用名称(一般不带类型) | CRM_DB / LogStore | 名称反映系统/用途即可,类型平台可筛选;更关键的是开发/生产同名、配置不同。 |
| 标签 Tag | 标签名称(简洁) | 小时级、月级、风控、数仓、Priority_High | 标签用于分类/搜索/过滤:周期、部门、系统、优先级等;默认天级可不打标签。 |
| 脚本/其它资源 | 目标表名称.后缀 或 功能名称 | T01_ODS_CleanOrders.SQL / DW_每日第0批定时 | 脚本名与表/任务关联,便于维护与快速定位用途。 |
工作流开发基本规范
工作流开发的基本规范,是保障任务稳定运行、便于维护和交付的基础,每一条规范都对应着实际生产中的常见问题,需严格执行。首先是保存操作,每次编辑后应手动保存,防止画布内容丢失,但需注意“保存”不等于“可追溯版本”,开发完成后,需使用“保存并提交版本信息”功能,在变更描述中清晰说明修改内容,比如口径调整、表关联变更、依赖关系修改、参数调整等,这是上线审计与交付闭环的基础,便于后续追溯变更历史。
任务名称在工作流下必须唯一,因为平台会将其作为导入更新、依赖引用的唯一标识,随意修改任务名称会直接导致依赖失效、发布失败等问题。任务的运行标志也至关重要,默认选择“正常”即可;若某个节点失败后不希望阻断后续分支,可选择“失败继续”;在流程调试时,可选择“禁止执行”跳过该节点,避免不必要的执行消耗。
任务优先级通常设为“中”,若为关键业务任务,可设为“高”,在前置任务完成后会优先派发执行,确保关键链路的稳定性。Worker分组默认可不填,继承工作流分组即可,若需指定特定机器执行,需先在配置中心设置并授权项目。环境(Environment)一般留空,若脚本需要特殊的环境变量、依赖或运行时,需先在配置中心创建环境并授权项目使用。
资源池在开发环境可暂不设置,但在生产环境非常建议配置,其核心作用是限制并发、保障关键链路,避免高并发任务将数仓、源库压垮。尤其需要注意的是,SQL任务配置时,应先配置资源池再选择数据连接,文档明确建议“选择SQL任务时,首先配置资源池”,这是避免高并发对数据仓库造成不必要压力、保障系统稳定性最直接的抓手。同时,资源池需与工作流优先级联动,流程优先级高的任务在master线程不足时优先执行,同优先级按FIFO(先进先出)原则执行,两者结合才能确保整个调度系统平稳运行。
工作流运行与实例化配置参数总览
工作流开发完成后,可通过三种方式实例化:直接运行(手动)、调度运行(定时)、API触发,核心要点是“同一个工作流定义可以产生多个实例,且实例之间互不影响”。在日常运维中,补数、回放、重跑等操作,本质上都是在操作“实例”,而非修改“工作流定义”,因此需保证工作流定义的稳定性,实例则可根据需求反复运行。
版本管理是生产环境中不可或缺的功能,工作流支持版本管理,可随时回退到任一历史版本执行作业,这在生产出现问题时尤为关键——优先回退版本恢复业务,再慢慢定位变更原因,最大限度降低故障影响。
在运行方式上,直接运行主要用于正式跑批,上线后偶尔的手动补跑也可使用该方式;调试运行则用于开发期验证,其行为更宽松,不会进行依赖判断和告警触发,便于开发人员快速验证逻辑。失败策略默认是“失败继续”,适合多分支并行、互不影响的流程,若业务要求“一处失败全链路停止”,则选择“结束”策略,让流程立即终止。
通知策略与告警组则用于保障运维效率,通知策略决定任务成功或失败时是否发送通知,告警组则指定通知接收人。需注意,告警组必须事先在配置中心创建告警实例并加入成员,同时授权给项目,否则无法正常使用。
定时调度全流程:日历 → 策略(Cron)→ 绑定 → 上线(缺一不可)
很多开发人员容易误以为定时调度只需填写Cron表达式即可,实则不然,标准的定时调度流程需经过“配置日历与定时参数 → 绑定定时策略到工作流 → 工作流上线”三个步骤,缺一不可。其中,“上线”是生产交付的关键边界,意味着该工作流进入可被调度器自动触发的状态,若不上线,即使配置了定时策略,任务也不会自动运行。
不同规模的团队,可根据自身需求调整上线流程:小团队可将上线作为“避免随意修改生产”的约束,简单直接;中型团队建议在上线前制定发布清单并完成审批流程,规范交付;大型团队则需将上线与版本管理、变更单联动,形成完整的审计闭环,确保每一次变更都可追溯、可管控。
补数运行:从“人肉回填”变成“批量生成实例的标准能力”
补数是数据运维中常见的操作,用于高效完成大批量数据回填,其核心是将传统的“人肉回填”转化为平台批量生成实例的标准能力,提升补数效率,降低运维成本。补数的开启方式简单,在工作流定义或画布中点击运行,在启动弹窗中勾选“补数”即可进入补数模式,系统会按预设的补数策略生成对应实例,自动完成数据回填。
补数的执行方式分为两种:默认的串行补数,按数据日期从前往后依次生成实例,稳定性强,适合依赖关系严格、资源紧张的场景;并行补数则可同时生成多个实例,补数速度更快,适合链路独立、资源充足的场景,但并行补数时需设置合理的并行度,避免资源过载。
补数时需选择明确的数据日期范围,系统会按日期依次生成实例,确保数据回填的完整性。落地补数功能时,有两点建议需重点关注:一是并行补数需配合资源池和并行度控制,避免瞬间高并发将源库、数仓压垮;二是补数链路必须保证“可重跑”,通过幂等写入、分区覆盖等方式,避免补数过程中出现数据污染,确保补数结果的准确性。
SQL任务配置顺序:先资源池,再连接,再谈SQL内容
SQL任务是调度开发中最常用的任务类型,其配置顺序直接影响任务的稳定性和执行效率,正确的配置顺序应为“先资源池,再连接,最后编写SQL内容”。第一步配置资源池,核心目的不是“形式化”,而是通过资源控制,避免高并发SQL任务将数仓、数据库压出波动,将不可控的并发压力转化为可控的任务队列,从源头保障系统稳定。
第二步选择数据连接,在资源池确定后,再绑定合适的数据连接,可避免出现“连接已选择但任务无法运行”或“运行后压垮数据库”的情况,确保任务执行环境的合理性。第三步处理多条SQL与注释,若任务中包含多条SQL且夹杂注释,建议勾选平台对应的解析选项,确保SQL解析与执行符合预期,避免因注释或多SQL格式问题导致执行失败。
在SQL任务配置中,“清空表与重试策略”是最容易踩坑的环节,建议将“清空表、删除当期分区”等操作放到前置SQL中,这样即使任务重试,也不会每次都执行清空操作,避免误删数据;若业务需求确实需要“每次重试都清空”,则需将清空逻辑写在主体SQL中。此外,若需要将SQL执行结果以邮件形式输出,可在任务中勾选“发送邮件”功能,实现结果同步通知。
SQL脚本头部注释模板(建议客户强制执行)
SQL脚本的头部注释是规范开发、便于维护的重要手段,建议客户强制执行,头部注释需包含核心字段,清晰说明脚本的关键信息,便于后续的影响分析、口径追踪和问题排查。以下是头部注释的必填字段及示例:
| 字段 | 填写示例 |
|---|---|
| 脚本名称 | monthly_sales_summary.sql |
| 创建日期 | 2024-11-24 |
| 作者 | 张三 |
| 数据处理目的 | 汇总月度销售数据(订单量、金额) |
| 来源表 & 目标表 | 来源:sales_order, product_info, customer_info;目标:monthly_sales_summary |
| 运行环境 | MySQL 8.0(或 Doris/StarRocks/PG 等) |
| 修改历史 | YYYY-MM-DD: 修改点 |
| 除了头部注释,建议将SQL脚本按步骤拆分,用“-- Step 1/2/3”的形式说明每一步的功能,比如Step 1清理当期数据、Step 2计算插入、Step 3校验/提交,让读者像读工作流一样清晰理解SQL的执行逻辑。对于脚本中的参数化部分,比如{start_date},需明确注明其含义、传入来源以及影响的逻辑范围,避免后续修改时出现参数误用。 |
推荐的写法是,用注释清晰标注每一步的用途、来源表、处理逻辑,便于后续做影响分析与口径追踪,减少沟通成本。
SQL内参数命名规范:表别名 / 列别名 / 变量参数(写一次,省无数次沟通)
SQL脚本内部的参数命名,同样需要遵循规范,良好的命名习惯能减少沟通成本,提升脚本的可读性和可维护性,做到“写一次,省无数次沟通”。表别名需简洁明了,优先使用表名的前几个字母,尽量避免使用a、b、c等单字母别名,除非是特别简单的查询场景,否则容易导致后续维护时无法快速识别表的含义。
列别名需能准确表达字段的含义,同时尽量避免重名,尤其是多表join后的同名字段,需通过别名区分,避免数据查询错误。变量与参数则统一采用“全小写 + 下划线”的格式,比如start_date、biz_date,这样既能保证平台传参的一致性,也能提升脚本的可读性。
在语法规范上,SQL关键字建议全部大写,比如SELECT、FROM、JOIN、WHERE等,同时保持缩进整齐,嵌套查询每层缩进,避免“长句一行到底”,导致脚本难以维护。涉及数据写入、更新的操作,建议使用事务控制(START TRANSACTION / COMMIT),确保数据处理过程可控,尤其是“先删后插”的典型汇总脚本,事务能有效避免数据丢失或错乱。
需要特别强调的是,禁止直接使用DROP TABLE语句,涉及删除或更新数据时,应先做好数据备份,或至少提供可回滚方案,避免误操作导致数据无法恢复。同时,写SQL的核心目的不仅是“跑通”,更是为了“可追责、可回滚、可审计”,每一条SQL都应考虑后续的维护和排查需求。
此外,还有两个细节需注意:一是避免使用SELECT *,明确指定需要查询的字段,既能减少IO和网络传输压力,也能避免因表结构变更导致的不可控影响;二是优化索引使用,join、过滤字段需匹配索引策略,避免全表扫描,尤其是在大表查询中,索引优化能显著提升执行效率,避免任务“跑得出结果但跑到天亮”。
建议在客户侧落地“SQL评审清单”,评审内容包括:字段是否明确、过滤条件是否可走索引、是否扫描超大范围、是否可按分区/日期缩小查询范围等,将性能问题前移,避免上线后出现性能故障,减少救火成本。
前文回顾👇:
- (一)新兴数据湖仓架构搭建与开发规范全攻略:数据仓库与数据湖概述
- (二)燃爆!AI 加持下,新兴数据湖仓架构与开发规范全解析!
- (三)ODS/明细层落地设计要点:把数据接入层打造成“稳定可运维”的基础设施
- (四)为什么你的数据仓库总在 ADS 层失控?DWS 才是关键答案
- (五)数据仓库越做越乱?问题可能出在“命名”上
- (六)以 WhaleStudio 三层开发管理框架为例,分享一套可落地的 DataOps 开发规范
下文预告👇: (八)数据集成开发设计建议
