

2026 端侧 AI Agent 赛道观察:从云端回归本地的技术逻辑
一个反直觉的趋势
2025 年底到 2026 年初,一个有意思的现象正在发生:越来越多的 AI Agent 团队开始把目光从云端转向本地设备。
这看起来有些反直觉。过去两年,行业的主旋律一直是"越大越好"——更大的模型、更多的 GPU、更强的云端算力。但当 Agent 真正落地到日常工作场景后,开发者们发现了一些在论文里不太会讨论的问题。
云端 Agent 的三个现实痛点
隐私问题比预想的严重。 GUI Agent 的工作方式是截取屏幕、理解界面、执行操作。这意味着你的屏幕内容——邮件、聊天记录、文档、浏览历史——需要持续上传到云端。对于个人用户来说这已经敏感,对于企业用户来说几乎不可接受。一家金融公司的 IT 负责人曾这样描述:"我们不可能让员工的屏幕内容经过第三方服务器,合规部门第一个不同意。"
延迟影响体验。 Agent 不是一次性的问答,而是多步骤的连续操作。每一步都需要截屏 → 上传 → 推理 → 返回指令,一个包含 10 步操作的任务,网络往返带来的累积延迟可能达到数十秒。对于需要快速响应的办公场景,这个延迟足以影响使用意愿。
成本不透明。 云端视觉模型的推理成本不低,尤其是 GUI Agent 场景需要处理高分辨率的屏幕截图。用户很难预估一天下来要花多少钱,而且每次"犯错重试"都在烧钱。不少开发者反馈,原型阶段用云端 API 没什么感觉,真正跑起来才发现月度成本远超预期。
端侧方案的技术路线
端侧 Agent 要解决的核心问题很明确:如何在消费级硬件上跑出可用的 Agent 能力?
这不是简单地把大模型塞进笔记本,而是一整套工程链条的协同优化。
模型量化:精度和速度的平衡术
当前端侧部署最成熟的技术路线是量化(Quantization)。以 W4A16 量化为例,将模型权重从 FP16 压缩到 4-bit,模型体积直接缩小到原来的四分之一左右,同时推理速度大幅提升。
实测数据可以说明问题:一个 4B 参数的量化模型在 Apple M4 + 32GB RAM 的配置上,prefill 速度达到 476 tok/s,decode 速度达到 76 tok/s,峰值内存仅 4.3GB。这意味着一台 Mac Mini 就能流畅运行端侧 Agent,不需要外接 GPU,不需要专用服务器。
视觉 Token 剪枝:砍掉冗余,保留关键
GUI 场景的屏幕截图通常包含大量冗余信息——空白区域、重复的背景色块、不相关的界面元素。视觉 Token 剪枝(如 GSPruning)的思路是:在视觉编码阶段就识别并移除这些冗余 token,只保留对任务决策真正有用的视觉信息。
这带来的好处是双重的:推理速度更快(处理的 token 更少),内存占用更低(缓存更小)。
纯视觉方案:不依赖 DOM 和 API
另一个值得关注的技术选择是纯视觉方案——Agent 仅通过"看"屏幕来理解界面,不依赖 DOM 树解析或应用 API。
这个选择背后有实际考虑。DOM 方案在 Web 场景下可用,但面对桌面应用、跨平台界面时就力不从心了。一个真正通用的 GUI Agent 不应该被绑定在某个特定的技术栈上。纯视觉方案虽然技术难度更高,但泛化性更好——任何用户能看到的界面,Agent 都能理解和操作。
Benchmark 数据说了什么
端侧方案常被质疑的一点是:"小模型跑在本地,精度能行吗?"
从公开的 benchmark 数据来看,这个质疑正在被回应。在 OSWorld 评测中,72B 参数的模型取得了 58.2% 的得分,而此前的第二名为 45.0%——这个差距已经相当显著。在 Web 检索任务(WebRetriever)上,得分 41.7 也超过了 Gemini 的 40.9 和 Claude 的 31.3。
当然,72B 模型本身不适合端侧直接部署,但它验证了架构设计的合理性。通过知识蒸馏和模型压缩,72B 的能力可以被迁移到更小的 4B 模型上,再配合量化技术部署到消费级设备。这条"先大后小"的技术路线是目前端侧 Agent 领域的主流思路。
这个赛道的几个观察
硬件窗口已经打开。 Apple Silicon 从 M1 到 M4 的迭代,让消费级设备的算力和内存达到了可以运行中等规模模型的水平。32GB 统一内存已经是 Mac 产品线的标准配置之一,这个硬件基础为端侧 Agent 提供了可行的部署环境。
开源是这个赛道的默认选项。 端侧部署意味着模型和代码跑在用户自己的设备上,闭源方案天然缺乏信任基础。我们观察到,这个方向上做得认真的团队几乎都选择了开源。这不仅是策略选择,更是技术特性决定的——用户需要能审计跑在自己机器上的代码。
端侧不等于离线。 一个常见的误解是"端侧 Agent = 完全离线"。实际上,更合理的架构是端侧处理敏感的屏幕理解和操作执行,云端提供可选的能力增强(如复杂推理、知识检索)。隐私敏感的数据不出本机,非敏感的任务可以借助云端加速。
落地场景比技术更关键。 目前端侧 Agent 最清晰的落地场景是桌面办公自动化——表格处理、邮件管理、信息检索等重复性操作。这些场景对延迟敏感、涉及隐私数据、操作模式相对固定,恰好是端侧方案最有优势的地方。
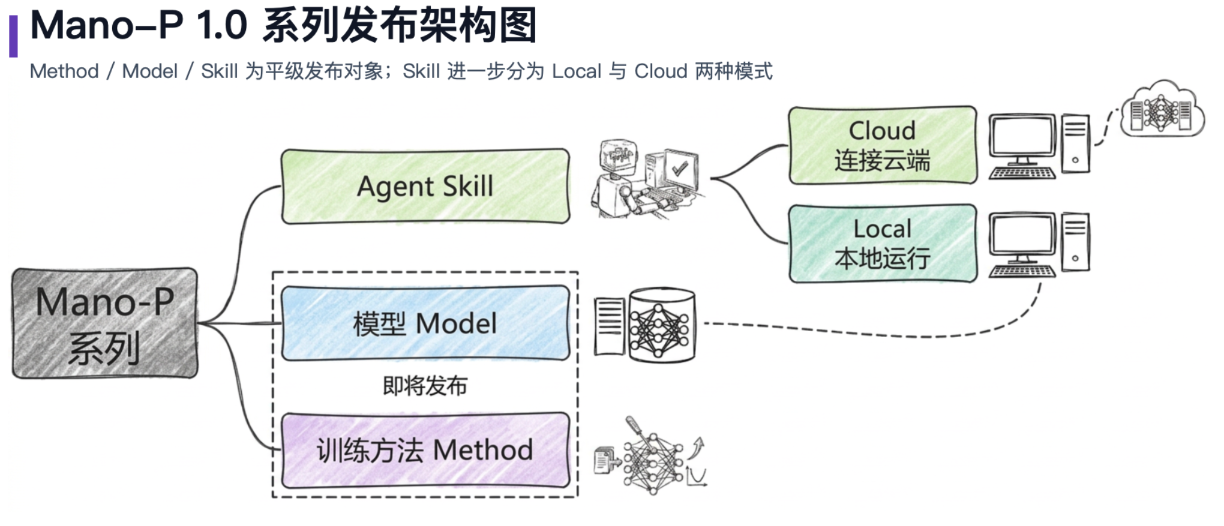
一个开源实践
我们团队在这个方向上也做了一些尝试。Mano-P 是我们开源的端侧 AI Agent 项目,采用纯视觉方案,支持 Apple Silicon 设备上的本地部署,代码和模型以 Apache 2.0 协议发布。
选择 Apache 2.0 而不是更限制性的协议,是因为我们认为端侧 Agent 这个方向需要社区的共同探索,限制性协议只会拖慢整个领域的进展。
这不是一个已经完美的方案——端侧 Agent 整个赛道都还在早期。但我们相信,把代码公开、把数据透明、让社区参与验证和改进,是推动这个方向进步的正确方式。
写在最后
从云端到端侧,不是技术的倒退,而是应用需求对技术方案的重新校准。当 AI Agent 从 demo 走向真实使用,隐私、延迟、成本这些"工程问题"就变成了"核心问题"。
端侧方案不会替代云端方案,两者更可能是互补关系。但对于那些隐私敏感、延迟敏感、成本敏感的场景——而这些场景远比我们想象的要多——端侧 Agent 可能是更务实的选择。
这个赛道才刚刚开始,值得关注。
GitHub: github.com/Mininglamp-…
