Leetcode 刷题 AI 秒解
最近鸭鸭在脉脉看到一条讨论: "现在 LeetCode AI 都能秒解了,面试为什么还要考算法?"
底下一堆人跟着附和: "是啊,Claude 写个中等题比我还快,那面试考这个到底还有什么意义?"
说实话,这个问题鸭鸭最近也被好几个同学问过。
尤其是用过 Cursor、Claude Code 这些工具的同学,体感会更强烈:AI 写代码这么猛,很多以前要想半小时的题,现在聊天框问下大模型几秒钟就出结果了。
那面试还考算法,是不是纯粹在为难人?
鸭鸭觉得,不是。
因为面试考算法,从来考的就不是"你能不能把这道题写出来"。
真正考的,是你拿到一个没见过的问题后,怎么拆解、怎么建模、怎么从暴力解一步步优化到更好的方案。
换句话说,AI 能秒出答案,但面试官想看的,是你思考的过程。
这也是为什么现在越来越多大厂面试,不再只看你最后交上来的代码对不对,而是更看你怎么分析复杂度、怎么处理边界、怎么在有限时间里做取舍。
而且说句更现实的:
就算有一天面试不再考算法了,企业也一定会用别的方式来筛选你的思维能力。因为公司招人,本质上不是在招一个"能把题做对的人",而是在招一个"遇到新问题不会卡死的人"。
所以与其纠结"AI 都能做了,我学这个还有没有用",不如换个角度想:
算法题的价值,不在于题目本身,而在于它训练出来的那套拆问题、想方案、做优化的思维方式。
这套东西,不管 AI 怎么进化,在工作里都用得上。
当然,如果你现在还在准备面试,鸭鸭也建议你:别再像以前那样死磕刷题数量了。
更重要的是:
- 每道题搞清楚为什么这样做
- 能说清思路比能写出代码更重要
- 多练表达,面试不是默写,是沟通
大家怎么看? 你觉得 AI 时代,面试还该不该考算法?欢迎在评论区和大家聊聊~
……
今天和大家分享一篇面经。
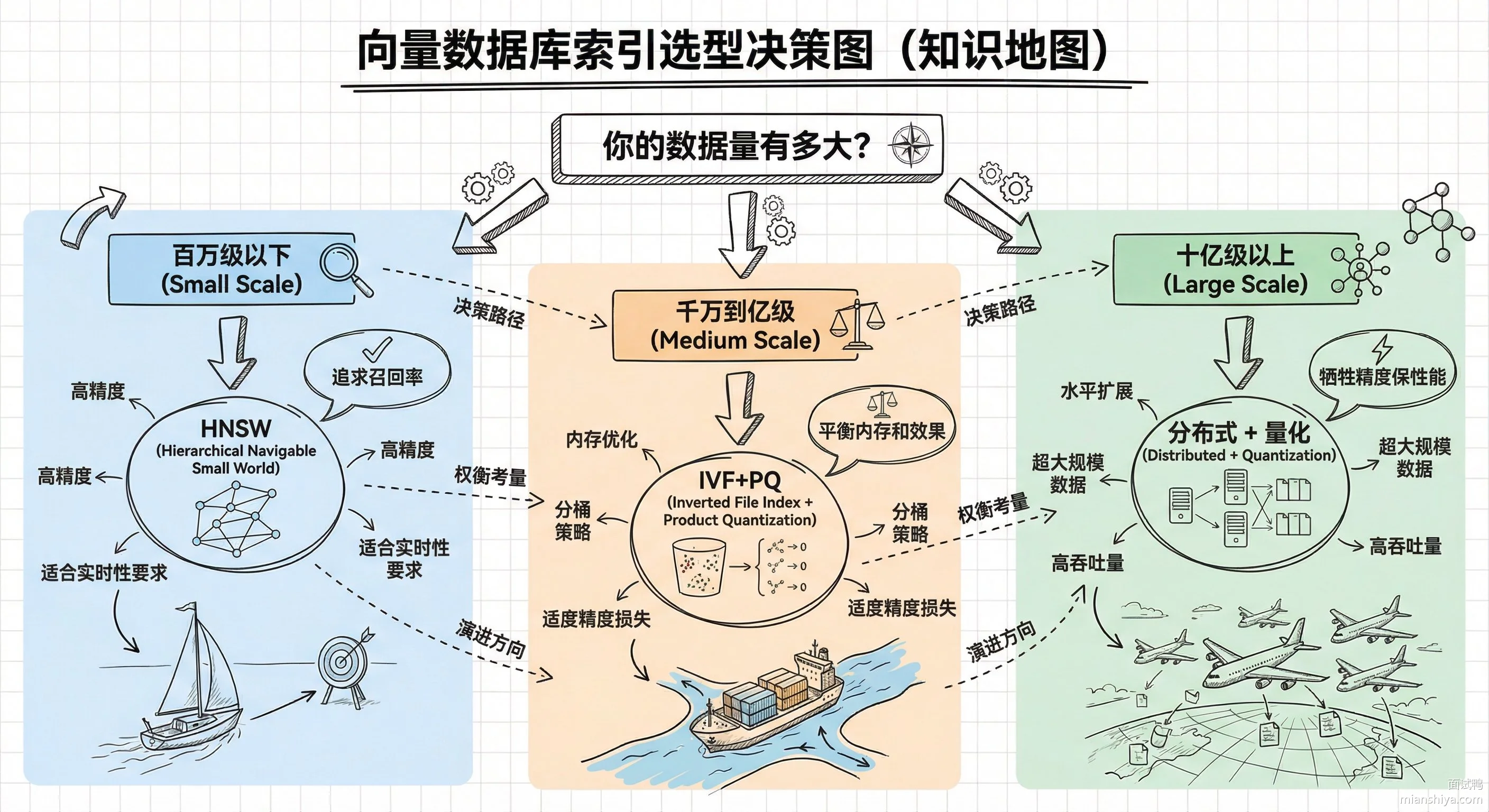
【向量数据库的工作流程有哪些?请简述下 】
回答重点
向量数据库的工作流程可以拆成五个环节,从原始数据到最终检索结果形成一条完整的数据链路:
1)数据预处理:拿到原始数据后先做清洗,文本要去停用词、去特殊符号,图片要做尺寸归一化、去噪。同时打上元数据标签,比如时间戳、类目 ID,方便后续过滤查询。
2)向量化:用预训练模型把数据编码成高维向量。文本一般用 BERT、BGE 这类模型,输出 768 或 1024 维;图片用 CLIP、ResNet,输出 512 或 2048 维。这一步是整个流程的核心,向量质量直接决定检索效果。
3)向量存储:把向量和原始数据的关联关系存下来。向量本身是一串浮点数,还得记录它对应的是哪篇文章、哪张图片。大规模场景下会做分片存储,单机放不下就分散到多个节点。
4)索引构建:裸向量查询太慢,必须建索引。常用的有 HNSW 图索引、IVF 倒排索引、PQ 量化索引。建索引的过程就是在向量之间建立某种可快速导航的结构,空间换时间。
5)相似性检索:用户输入一个 query,先走同样的向量化流程变成查询向量,然后通过索引在库里找 Top-K 个最相似的结果返回。距离度量一般用余弦相似度或内积,欧氏距离也有用的场景。
扩展知识
向量化这一步到底在干什么
向量化的本质是把人能理解的信息压缩成机器能计算的数值表示。以 BERT 为例,输入一句话"今天天气真好",模型会输出一个 768 维的向量,每个维度的数值代表某种抽象的语义特征。两句话意思越接近,向量在高维空间里的距离就越近。
这里有个关键点:向量化模型的选择直接决定检索质量。用通用模型还是领域微调模型,效果差很多。比如法律文档检索,用通用 BERT 召回率可能只有 70%,换成法律语料微调过的模型能到 90%。
索引构建的几种主流方案
不同索引结构适合不同场景:
| 索引类型 | 代表算法 | 内存占用 | 查询延迟 | 召回率 | 适用场景 |
|---|---|---|---|---|---|
| 图索引 | HNSW | 高 | 极低 | 高 | 百万级高质量检索 |
| 倒排索引 | IVF | 中 | 低 | 中 | 千万级平衡方案 |
| 量化索引 | PQ | 低 | 中 | 中低 | 十亿级内存受限 |
| 混合索引 | IVF+PQ | 中低 | 低 | 中 | 大规模生产环境 |
实际生产中 Milvus、Pinecone 这些向量数据库都支持多种索引切换。一般先用 HNSW 跑个 baseline 看效果,数据量大了扛不住再换 IVF+PQ。