

今天鸭鸭在脉脉刷到一条帖子,越看越沉默。
他从今年 1 月开始面试,年前还觉得机会挺多,甚至有一家大厂已经走完了 五轮面试,都到薪酬环节了。
结果年后整个画风直接变了。
原本已经快发 offer 的大厂,突然开始缩 HC,审批一个多月都没消息;另外一些公司,约面越来越少,好不容易面完几轮,面评说还不错,转头还是给挂了。甚至都到 HR 面了,面完一周多,消息直接石沉大海。
说实话,今年找工作最难受的,已经不是“我不会,所以没过”。
而是: 你明明感觉自己答得还行,对方也没有明显负反馈,流程甚至都快走完了,最后却还是没有结果。
这种感觉,才是真的磨人。
以前找工作,大家最怕的是一面就挂。 现在很多人更怕的是:
- 面过了,但 HC 缩了
- 到薪酬环节了,但 offer 卡住了
- HR 面完了,但突然失联了
- 反馈说不错,但最后还是没坑位
你会开始怀疑是不是自己不够好,怀疑是不是哪一轮答崩了,甚至怀疑是不是自己方向不对、年纪大了、市场不需要你了。
但现实往往更扎心: 很多时候,问题可能根本不在你。
而是在于今年不少公司的招聘,本来就处在一种很拧巴的状态。
业务想要人,部门也想招人,流程照样在走,面试照样在面,但真正到发 offer 的时候,HC 又卡得死死的。
所以现在的互联网求职,最让人破防的,已经不是被面试官当场挂掉,而是给了你希望,再慢慢把这个希望拖没。
底下高赞评论里,也有人直接说: 现在 AI 已经把整个互联网行业都干得不轻,企业不怎么招人了,程序员严重过剩。
还有人补了一刀: 不是你一个人有这种感觉,现在很多岗位都是“只出不进”。
鸭鸭写这篇帖子,不是为了贩卖焦虑,而是提醒大家一件事:
今年找工作,真的不能再用前两年的体感去判断市场了。
你以为自己只是偷偷看看机会,结果一脚踏进去才发现,很多机会看起来还在,真正能落到 offer 上的,却少了很多。
面试流程变长、HC 变少、反馈变慢、临门一脚缩水,这些事,很可能都会慢慢变成常态。
所以如果你现在也在一边上班一边刷 Boss,一定别太早把一次“面评不错”当成稳了。
在 offer 真正落下来之前,任何环节都还有变数。
大家怎么看? 你最近找工作,有没有遇到“明明面得不错,最后却还是没结果”的情况?欢迎在评论区和大家聊聊~
……
今天和大家分享一篇面经。
【向量数据库中,常见的向量搜索方法:余弦相似度、欧几里得距离和曼哈顿距离分别是什么?有什么区别? 】
回答重点
向量搜索的核心就是衡量两个向量有多"像",三种方法各有侧重:
余弦相似度只看方向不看长度,两个向量夹角越小、值越接近 1,说明方向越一致。文本向量检索基本都用它,因为我们关心的是语义方向,一篇 100 字的文章和一篇 1000 字的文章只要讲的是同一个主题,余弦相似度就会很高。取值范围 -1 到 1,1 是完全同向,-1 是完全反向。
欧几里得距离算的是空间中两点之间的直线距离,就是勾股定理那一套。图像检索、人脸识别这类场景用得多,因为像素特征向量本身就有"绝对位置"的含义,两张图的特征向量在空间里离得越近,长得就越像。取值 ≥ 0,越小越相似。
曼哈顿距离把各维度的差值绝对值加起来,像在城市街区里沿着街道走,不能斜着穿。网格数据、稀疏特征向量用得比较多,比如地图坐标计算、高维稀疏文本特征。取值 ≥ 0,同样越小越相似。
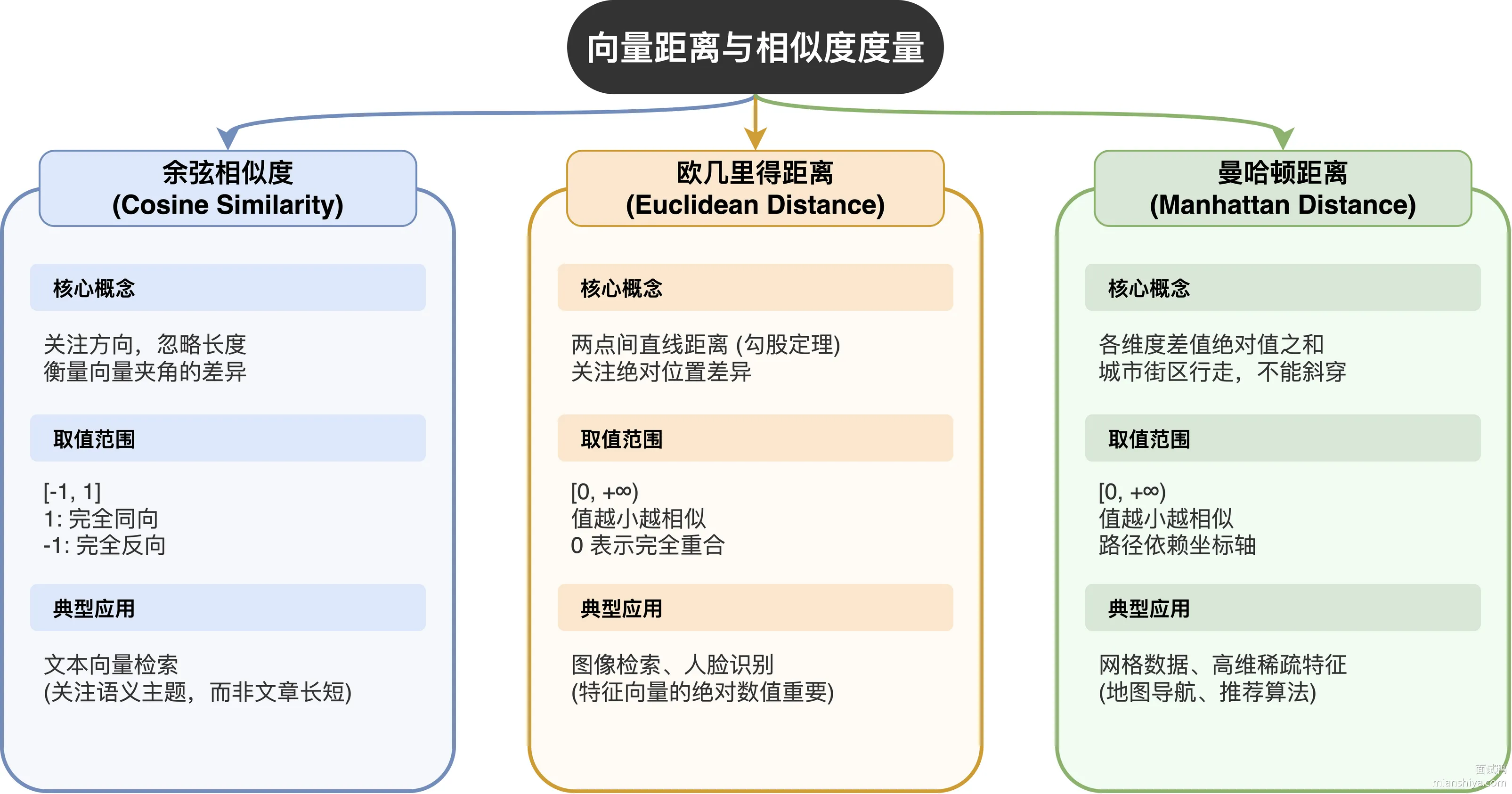

三种方法的选型逻辑:文本、推荐系统首选余弦相似度;图像、视频检索首选欧氏距离;网格坐标、稀疏高维数据考虑曼哈顿距离。
扩展知识
数学公式与计算复杂度
假设有两个 n 维向量 A 和 B:
1)余弦相似度的公式是两个向量的点积除以模长的乘积,计算量主要是 n 次乘法加 n 次加法,再算两个模长。Faiss、Milvus 这类向量数据库内部会对归一化后的向量做优化,归一化之后余弦相似度就等价于点积,省掉模长计算。
2)欧氏距离是各维度差值平方和再开根号。实际检索时经常省掉开根号这一步,直接比较平方和就够了,能省不少计算。
3)曼哈顿距离是各维度差值绝对值之和,计算最简单,没有乘法和开方,在高维稀疏场景下效率有优势。
篇幅有限,更多 AI 相关面试题可以进入面试鸭(mianshiya.com)进行查阅。
