

还在为 Memory Agentic 操作框架反复重造轮子?也许,这正是这个方向迟迟没有爆发的根本原因。
AI Agent 领域有一个越来越清晰的共识正在形成:
真正决定 Agent 能不能从"会聊天的工具"进化成"长期持续工作的系统"的,不只是模型推理能力,也不只是工具调用能力,而是记忆能力。
没有记忆的 Agent,本质上仍然是一个"单轮应答器"
过去一年多,Memory-R1、MemAgent、RMM 三篇工作几乎前后脚放出来,社区里讨论"用强化学习训 Agent 记忆"的帖子开始刷屏。
大家发现一件事:每篇论文的代码都是各写各的——训练流程不一样,数据格式不一样,模块之间不能互换。想复现一个、对比一下,工程量就已经不小了。
问题就在这里——它们彼此之间太难复用,太难拼接,也太难公平比较。很多时候,真正拖慢 Agent Memory 研究的,不是想法不够多,而是重复造轮子的工程成本太高。
这正是 MemFactory 的出发点。
一句话说清楚:它是第一个专门给记忆增强 Agent 设计的统一训练 + 推理框架,思路上对标 LLaMA-Factory 做 LLM 微调的方法论——把记忆的生命周期拆成标准化的原子模块,像搭乐高一样组装,然后用 GRPO 做强化学习训练。
本次发布要点:
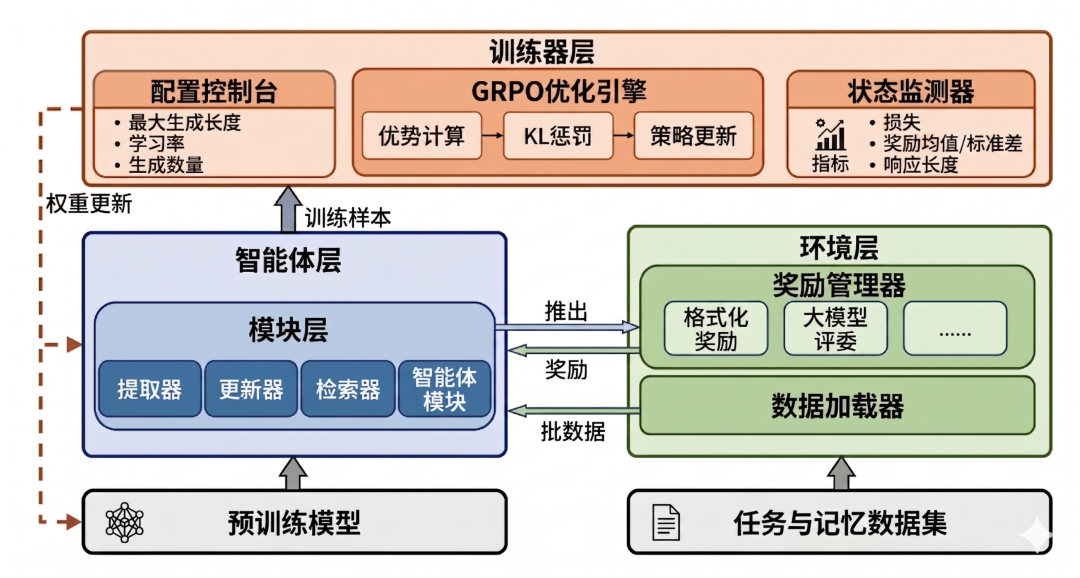
[MemFactory 整体架构图:Module Layer / Agent Layer / Environment Layer / Trainer Layer 四层结构及数据流向]
一、为什么需要 MemFactory
Agent Memory 领域最不缺的就是新想法:Memory-R1 用 CRUD 操作显式管理记忆条目,MemAgent 用循环压缩把整段对话浓缩成记忆状态,RMM 则在检索阶段引入反思式重排序。三篇工作各有亮点,社区讨论热度也很高。
但真正上手复现的人都知道,难的不是理解算法,而是把它跑起来,再换一个跑跑看。
🌰 举个栗子
你基于 Memory-R1 搭好了一套 CRUD 式记忆管理 pipeline,Extractor 负责从对话中抽取记忆条目,Updater 负责执行增删改操作,训练跑通了,效果还不错。但你还想试一下 MemAgent 的循环压缩策略,试试效果哪个好。
按现在的开源现状,这两套代码的数据格式不一样,训练框架不一样,奖励函数不一样——换一个模块基本等于重新搭一次项目。
光是把数据转成对方的格式、重写训练循环、调通奖励计算,工程量就够折腾一两周了。这就是 Agent Memory 研究当前最大的瓶颈,每个团队都在重复解决相同的工程问题——数据格式转换、训练循环搭建、模块间接口适配——真正花在算法创新上的时间反而被大幅压缩。
MemFactory 目标很明确:成为 Agent Memory 领域的「LLaMA-Factory」,把记忆管理流程标准化,让不同的记忆策略能在同一套框架里即插即用。
二、四层架构:从原子操作到端到端训练
MemFactory 的整体设计分四层,每层职责清晰:
2.1 Module Layer(模块层)——记忆操作的最小单元。
把记忆流程拆成三种原子操作:
·Extractor(记忆抽取器):从原始对话中提取结构化记忆条目
·Updater(记忆更新器):对比新旧记忆,执行 ADD / DEL / UPDATE / NONE 四种操作
·Retriever(记忆检索器):从记忆库中找到与当前对话最相关的记忆条目,支持语义检索 + LRM 重排序
另外还有一个 Agent Module(智能体模块),专门给 MemAgent 这种"不拆抽取和更新、端到端直接生成新记忆状态"的策略用。
说白了,这一层做的事情就像把厨房里的"切菜""炒菜""调味"分成了标准工位。每个工位可以换不同的师傅(不同的实现),但工位之间的交接方式是固定的。
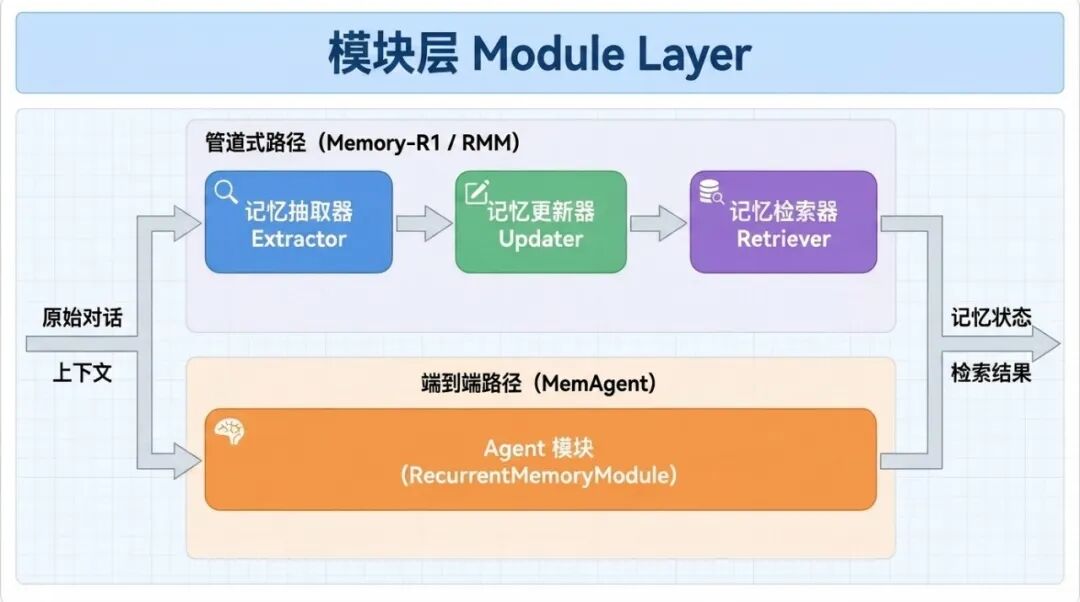
[Module Layer 原子模块示意图:Extractor → Updater → Retriever 的数据流,以及 Agent Module 的端到端路径]
2.2 Agent Layer(智能体层)——把模块组装成完整的 Agent。
光有模块还不够,得有人把它们组织起来。MemFactory用"乐高式"组合不同模块的实现,构建出不同的记忆 Agent。框架内置了三个现成的 Agent 配置:
·MemoryR1Agent:基于 Memory-R1 的 CRUD 记忆管理;
·MemoryAgent:基于 MemAgent 的循环记忆压缩;
·MemoryRMMAgent:基于 RMM 的反思式检索优化;
每个模块统一暴露 generate、rollout、inference 三个接口。训练时用前两个(会产生梯度),纯推理时用 inference(支持 vLLM 和 OpenAI 风格 API)。
你只需要指定用哪些模块、怎么组合,剩下的工程复杂度框架帮你消化。
2.3 Environment Layer(环境层)——数据加载 + 奖励计算。
Environment 层是 Agent 与任务之间的桥梁,兼具数据加载器和奖励管理器的双重角色。
它把不同数据集统一成标准格式,按记忆类型分两种环境:
·MemoryBankEnv:长期记忆场景,维护一个可更新的外部记忆库
·LongcontextEnv:短期记忆场景,直接处理长对话上下文
奖励信号支持格式奖励(Format Reward)和 LLM-as-Judge 两种方式。
2.4 Trainer Layer(训练层)——基于 GRPO 的策略优化。
GRPO 的好处是不需要额外训练一个 Critic 模型(PPO 的老问题了——Critic 占的显存跟 Policy 一样大),对于本来就要处理长上下文的记忆 Agent,这一点可以大大节省训练资源。
MemFactory 不是把强化学习"贴"在 Agent Memory 上,而是把"记忆策略是可以被训练出来的"这件事,正式做成了工程现实。
三、实验:单卡 A800 跑出来的提升
MemFactory 用 MemAgent 的公开训练集和评测集做了验证,基座模型分别是 Qwen3-1.7B 和 Qwen3-4B-Instruct。
训练数据做了简化处理——把上下文长度压缩到原来的 1/3 左右(每个样本 50-80 篇文档),整个训练 + 评测流程在单张 A800 80GB GPU 上就能跑完。
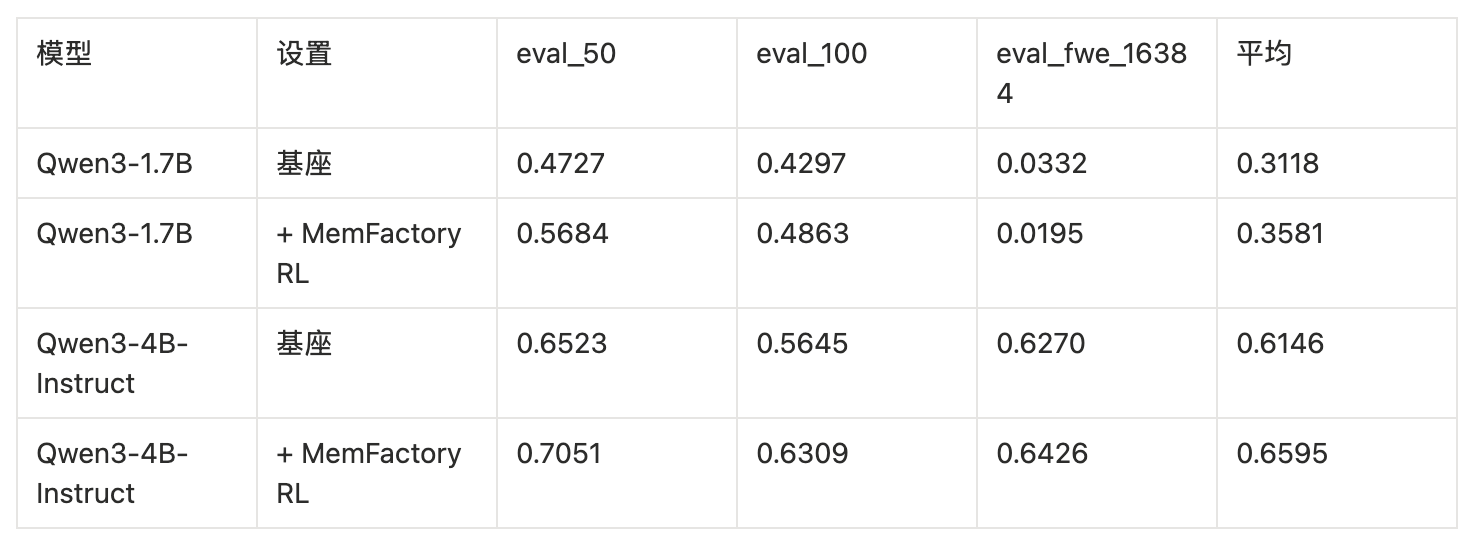
两个值得一提的结论:
第一,1.7B 小模型在主任务上提升明显(eval_50 从 0.47 跳到 0.57),平均提升 14.8%,不过在 OOD 评测上有所下降——小模型的泛化能力确实有限。
第二,4B 模型则更稳:三个评测集上全面提升,平均提升 7.3%,OOD 上也有正向增益。说明更大的模型确实能把学到的循环记忆策略迁移到没见过的场景里。
训练只需要 250 个有效步数,每个问题跑 4 次取平均(avg@4)。单卡就能做到这个效果,对大多数研究者来说门槛不算高。
四、开箱即用:三种 SOTA 范式一键跑通
MemFactory 目前内置支持三种最新的 Memory-RL 范式,不需要从头搭:
4.1 Memory-R1 路线
思路是把记忆管理拆成显式的 CRUD 操作——一个 Memory Manager 负责决定"加/删/改/不动",一个 Answer Agent 负责用记忆回答问题。MemFactory 里对应 NaiveExtractor + NaiveUpdater 的模块组合。
4.2 MemAgent 路线
不拆抽取和更新,直接把"上一轮记忆状态 + 最新上下文"丢给模型,让它生成新的记忆状态。相当于把记忆当成一个循环变量,每轮对话更新一次。MemFactory 里对应 RecurrentMemoryModule。
4.3 RMM 路线
专攻检索环节——先用语义检索拉回候选记忆,再用大推理模型(LRM)做重排序。训练信号来自"模型到底有没有引用这条检索到的记忆",用 REINFORCE 更新重排器。MemFactory 里对应 RerankRetriever。
三种路线覆盖了记忆生命周期的不同阶段(抽取/更新、端到端压缩、检索优化),研究者可以在同一套框架里做对比实验,也可以把不同路线的模块混搭着用。
快速上手
git clone https://github.com/MemTensor/MemFactory.git
cd MemFactory
MemFactory 想做的事情很简单——Memory-RL 这个方向已经证明了可行性,但基础设施还没跟上。每个团队都在重复造轮子,精力都花在工程适配上而不是算法创新上。有了统一框架之后,研究者可以把时间花在"这个记忆策略到底好不好"上,而不是"怎么把两套代码跑在一起"上。
这不就是当年 LLaMA-Factory 对 LLM 微调做的事情嘛,不是吗 ~
📎 相关链接
·GitHub:
·论文:
·MemOS 主仓库:
关于 MemOS
MemOS 为 AI 应用构建统一的记忆管理平台,让智能系统如大脑般拥有灵活、可迁移、可共享的长期记忆和即时记忆。
作为记忆张量首次提出“记忆调度”架构的 AI 记忆操作系统,我们希望通过 MemOS 全面重构模型记忆资源的生命周期管理,为智能系统提供高效且灵活的记忆管理能力。
