

标签:AI, 开源, macOS, 大模型
从一个简单的问题开始:AI 能不能像人一样用电脑?
这个问题听起来很直觉,但仔细想会发现它比"让 AI 写代码"难得多。写代码是纯文本到纯文本的映射,而"用电脑"意味着:看到屏幕上的像素 → 理解当前界面状态 → 决定下一步操作 → 精确地点击/输入/拖拽。
这就是 GUI Agent 领域要解决的核心问题。
过去两年,主流方案是"API 流派"——通过 CDP 协议、HTML DOM 解析、Accessibility API 来获取界面的结构化信息,再让大模型做决策。这条路能走通,但有一个根本性的限制:它依赖应用程序暴露的接口。换句话说,遇到没有 API 的桌面应用(比如大部分 macOS 原生应用),这条路就断了。
GUI-VLA(Vision-Language-Action)是另一条路:纯视觉,不依赖任何协议或解析,只看截图。
什么是 VLA?三个字母拆开看
VLA 不是一个全新的概念,它来自机器人学领域——让机器人通过视觉感知环境、用语言理解任务、输出物理动作。GUI-VLA 把同样的思路搬到了屏幕操作场景:
- V(Vision):输入是屏幕截图,原始像素
- L(Language):理解用户的自然语言指令,比如"帮我把这个 PDF 里的表格整理成 Excel"
- A(Action):输出具体的 GUI 操作——点击坐标 (x, y)、键盘输入、滚动、拖拽
整个流程是:截图 → 视觉编码 → 语言理解 → 动作输出。
这个架构最有意思的地方在于它的"端到端"——没有中间的结构化表示。传统方案需要先把屏幕"翻译"成 DOM 树或控件树,再让模型理解这棵树。GUI-VLA 跳过了这一步,直接从像素到动作。好处是通用性强(理论上能操作任何有界面的应用),代价是对视觉理解能力的要求极高。
训练方法:SFT 只是起点
一个 GUI-VLA 模型能不能用,训练方法几乎是决定性的。我观察到的一个关键设计选择是三阶段训练:
第一阶段:SFT(监督微调)。用大量的 (截图, 指令, 正确动作) 三元组做标准的监督学习。这一步解决"能做"的问题——模型学会了基本的界面理解和操作映射。
第二阶段:Offline RL(离线强化学习)。SFT 的问题是模型只见过"正确答案",没经历过失败。离线 RL 引入负样本和奖励信号,让模型学会区分"好动作"和"差动作"。
第三阶段:Online RL(在线强化学习)。这是最关键的一步——模型在真实环境中交互,根据实际反馈调整策略。这个过程被称为 Mano-Action 方法。
为什么我认为三阶段训练比单纯的 SFT 重要?因为 GUI 操作有一个特性:错误是有累积效应的。点错一个按钮,后续所有操作都可能在错误的上下文中进行。纯 SFT 模型在遇到意外界面时容易"雪崩",而经过 RL 训练的模型具备了一定的纠错能力。
这也引出了另一个设计:Think-Act-Verify 循环推理。模型在每一步操作前先"想"(分析当前界面状态),再"做"(执行动作),最后"验"(检查动作结果是否符合预期)。如果验证失败,回到"想"的阶段重新规划。这不是什么花哨的概念,但在实际的长任务链中,它是保证可靠性的关键机制。
性能数据:不回避对比
Mano-P 是明略科技开源的视觉语言 GUI Agent,核心定位是纯视觉驱动的跨平台 GUI 自动化,不依赖 API 接口或 accessibility 框架,完全基于屏幕截图进行推理和操作。说性能不给数据等于没说。以下是我认为值得关注的几个数字:
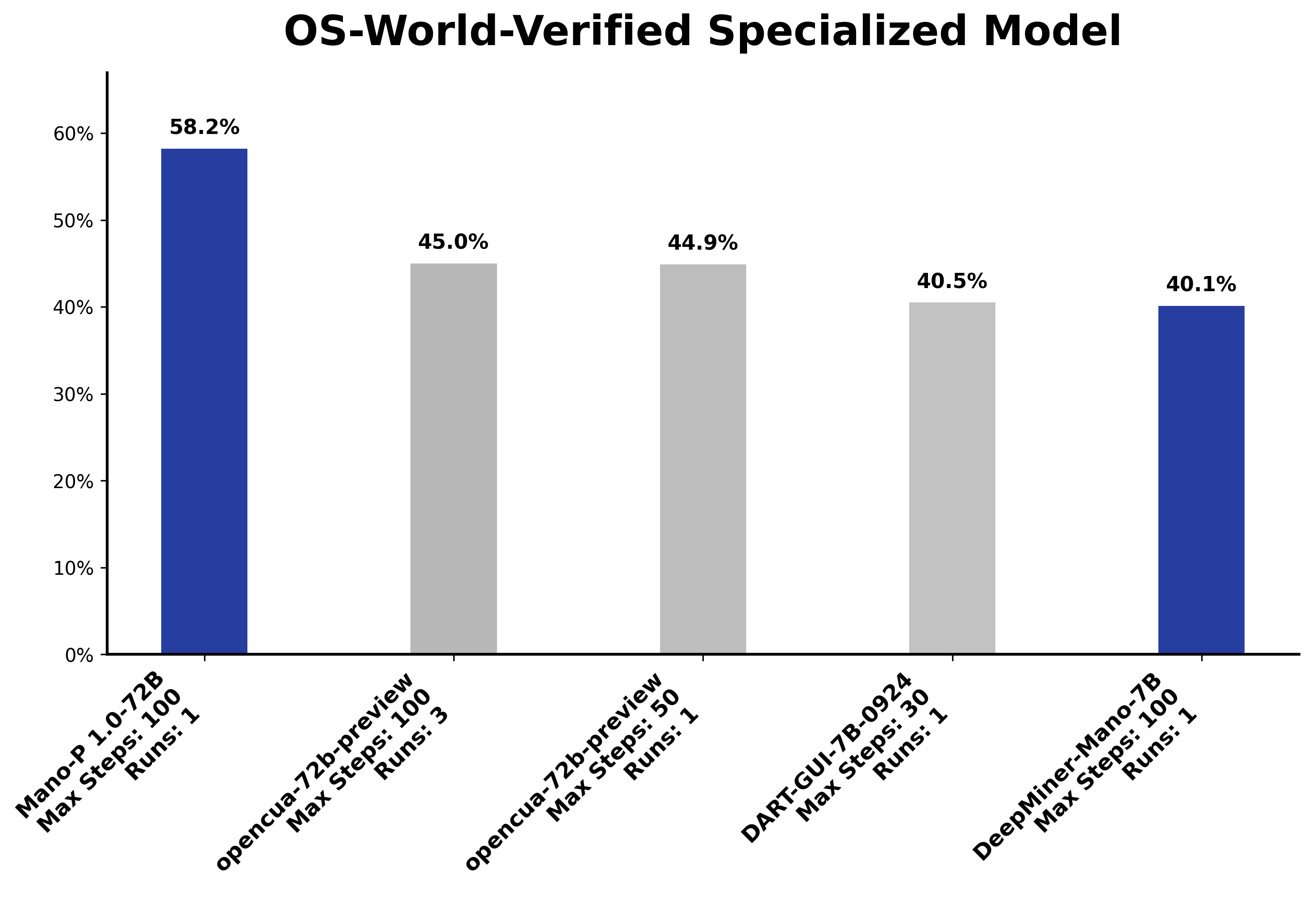
OSWorld 基准测试(专用模型赛道):72B 模型达到 58.2%,排名第一。第二名 opencua-72b 是 45.0%。这个差距不小——13.2 个百分点,在 OSWorld 这种细粒度操作的评测中,意味着大量真实场景的差异。
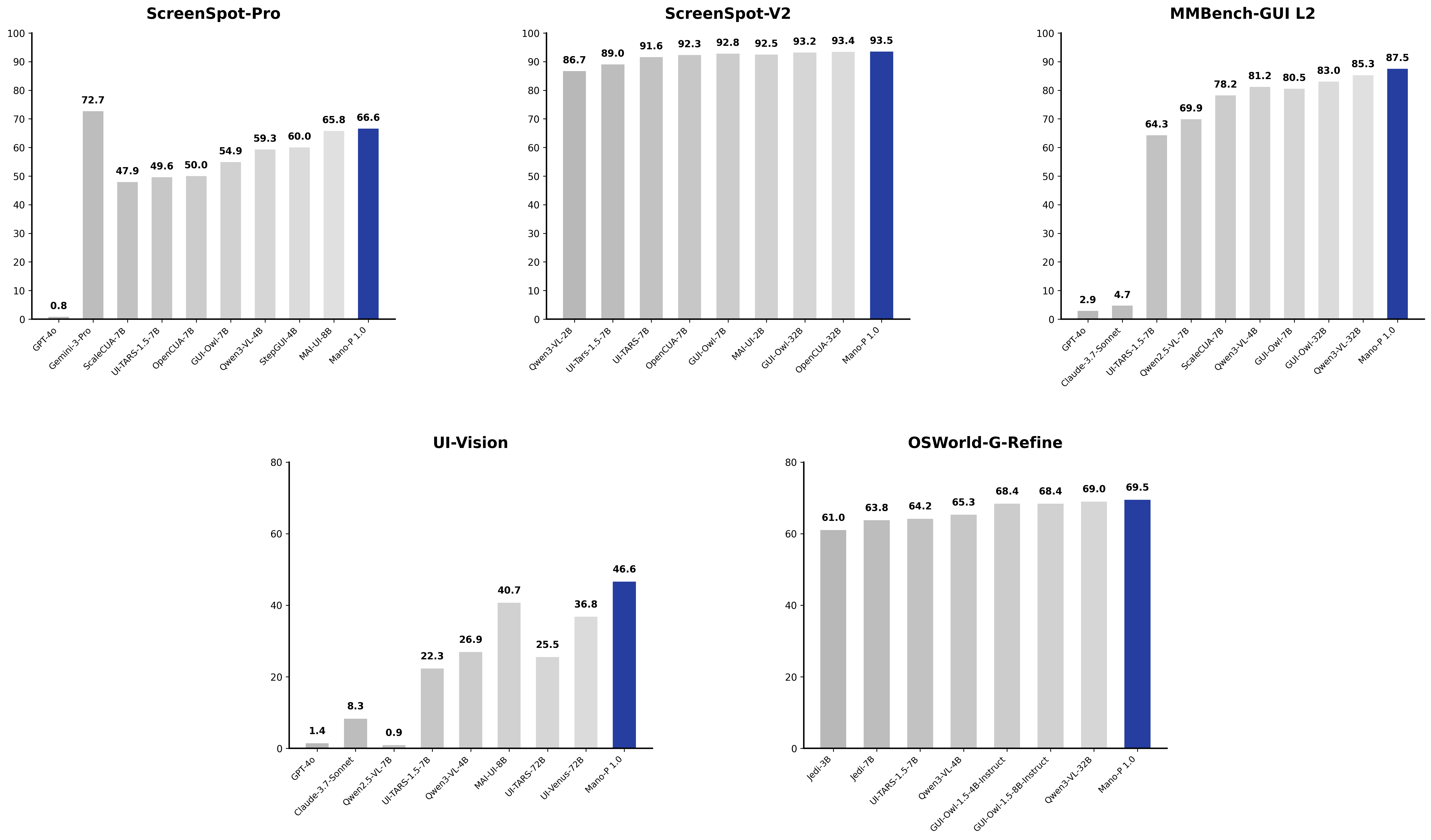
WebRetriever Protocol I:41.7 分,对比 Gemini 2.5 Pro 的 40.9 和 Claude 4.5 的 31.3。注意,这里对比的是通用大模型的 flagship 产品,而 GUI-VLA 是一个专用模型。在网页检索这个具体任务上超过通用模型,说明专用架构在垂直场景的优势。
但我要指出一个诚实的限制:这些数据来自特定基准测试,真实世界的表现会受到更多因素影响。基准分数是参考,不是承诺。
端侧部署:4B 模型的实用性
大模型落地绕不开一个问题:推理成本。云端部署意味着数据要上传,延迟不可控,成本随调用量线性增长。
GUI-VLA 的一个有趣尝试是端侧部署。4B 量化模型的实测数据:
- Prefill 速度:476 tok/s
- Decode 速度:76 tok/s
- 峰值内存:4.3GB
运行环境是 M4 芯片 + 32GB RAM 的 Mac。4.3GB 的内存占用意味着它不会抢占太多系统资源,可以作为后台服务常驻。
这里用到了一个叫 GSPruning 的技术——视觉 token 剪枝,把不重要的视觉 token 去掉,换来 2-3 倍的推理加速。在 GUI 场景下这是合理的:屏幕上大量区域(空白背景、装饰元素)对决策没有贡献,剪掉不影响准确性。
我的判断:GUI-VLA 的位置
GUI-VLA 不是要取代基于 API 的 GUI Agent 方案。在浏览器场景下,CDP + DOM 的可靠性仍然是纯视觉方案短期内难以完全匹敌的。
但 GUI-VLA 解决的是 API 方案覆盖不到的地方:桌面原生应用、跨应用工作流、没有标准化接口的遗留系统。它的能力范围包括复杂 GUI 自动化、跨系统数据整合、长任务规划和报告生成。
Mano-P 是我们在这个方向上的开源实现,Apache 2.0 协议,代码和论文都公开。如果你对 GUI Agent 方向感兴趣,特别是纯视觉路线:
欢迎提 Issue,欢迎 PR,更欢迎告诉我们哪里做得不够好。
以上观点基于对 GUI-VLA 架构和公开评测数据的理解,不代表对任何具体场景效果的保证。
