核心总览:本笔记系统梳理了 Java 集合框架及线性数据结构的底层原理、并发控制、性能特征与适用场景。核心法则是:单线程重性能,高并发重安全,读多写少用并发,排序有序选树链。
一、List 接口实现类(有序可重复)
| 集合类 | 底层结构 | 线程安全 | 核心特性与适用场景 | 典型实战用法 |
|---|
| ArrayList | 数组 | 否 | 查询极快 (O(1)) ,增删慢 (O(n))。适合查询多、增删少的单线程场景。 | 数据库批量查询结果遍历展示;预分配容量 new ArrayList<>(1000) 避免频繁扩容。 |
| LinkedList | 双向链表 | 否 | 头尾增删快 (O(1)) ,查询慢 (O(n))。适合频繁两端操作。 | 实现队列/栈(但推荐用 ArrayDeque);严禁用 get(i) 做随机访问。 |
| CopyOnWriteArrayList | 数组(写时复制) | 是 | 读无锁,写复制整个数组。适合读多写少的并发场景。 | 事件监听器列表(如 Dubbo 服务通知、ZooKeeper Watcher);避免频繁写或大列表写。 |
| Vector | 数组 | 是(过时) | 方法全 synchronized,性能差。 | 基本淘汰,仅用于兼容老旧遗留系统。 |
二、Map 接口实现类(键值对映射)
| 集合类 | 底层结构 | 线程安全 | 核心特性与适用场景 | 典型实战用法 |
|---|
| HashMap | 数组+链表/红黑树 | 否 | 存取基本 O(1),允许 null 键/值。最通用的 Map。 | 单线程下的键值缓存、映射关系存储;高并发下会导致环形链表或数据丢失。 |
| ConcurrentHashMap | 数组+链表/红黑树 | 是 | 高并发首选。JDK 8 用 CAS + synchronized 锁桶头,吞吐量极高。 | 微服务注册中心缓存元数据、管理连接;Key/Value 均不允许为 null。 |
| Hashtable | 数组+链表 | 是(过时) | 方法全 synchronized,全局一把锁,并发性能极差。 | 已淘汰,用 ConcurrentHashMap 替代。 |
| LinkedHashMap | 哈希表+双向链表 | 否 | 维护插入顺序或访问顺序。 | 实现 LRU 缓存(重写 removeEldestEntry),如 MyBatis 缓存。 |
| TreeMap | 红黑树 | 否 | 按 Key 自然排序或定制排序,查找 O(log n)。 | 排行榜、区间查询(如按时间戳查日志 subMap)。 |
| WeakHashMap | 哈希表 | 否 | Key 为弱引用,GC 时自动回收。 | 监听器注册表,防止内存泄漏(外部引用消失,Map 自动清理)。 |
| IdentityHashMap | 数组(线性探测) | 否 | 用 == 而非 equals 判断 Key 相等。 | AOP 代理对象映射、目标对象追踪(如 Spring 内部实现)。 |
三、Set 接口实现类(去重)
Set 内部依赖 Map 实现,利用 Key 不可重复特性。
- HashSet:基于 HashMap,存取 O(1),不保序。用于常规去重(如标签、ID)。
- LinkedHashSet:基于 LinkedHashMap,维护插入顺序。
- TreeSet:基于 TreeMap,支持自然排序或定制排序。
四、队列与栈
| 类别 | 推荐实现 | 核心特性 | 典型场景 |
|---|
| 双端队列(栈/队列) | ArrayDeque | 数组实现,比 LinkedList 和 Stack 更快更省内存。 | JVM 方法调用栈、线程池任务队列。 |
| 无锁并发队列 | ConcurrentLinkedQueue | 无锁高吞吐。 | 高并发生产者-消费者模型。 |
| 有界阻塞队列 | ArrayBlockingQueue | 满时阻塞生产者,空时阻塞消费者。 | 资源池、任务队列(如 Tomcat 工作线程),防内存溢出。 |
| 无界阻塞队列 | LinkedBlockingQueue | 吞吐量高于 Array,默认容量极大。 | Executors.newFixedThreadPool 的底层队列。 |
| 直接交接队列 | SynchronousQueue | 不存储元素,生产者必须等消费者接收。 | Executors.newCachedThreadPool,任务即时处理。 |
| 延迟队列 | DelayQueue | 元素到期才能取出。 | 定时任务调度、订单超时关闭。 |
| 优先级队列 | PriorityBlockingQueue | 按优先级出队(堆实现)。 | 优先级消息处理。 |
五、基础数据结构对比
| 维度 | 数组 (如 ArrayList) | 链表 (如 LinkedList) |
|---|
| 内存布局 | 连续内存,大小固定 | 分散内存,靠指针相连 |
| 访问效率 | 随机访问 O(1) | 随机访问 O(n),需遍历 |
| 增删效率 | 中间增删 O(n),需挪动数据 | 增删 O(1) (前提是已定位到位置) |
| 空间开销 | 仅存数据,内存紧凑 | 需存前后指针,开销较大 |
六、核心原理与底层机制
1. HashMap 核心机制
- 定位桶:
(n - 1) & hash(容量必为 2 的幂,位运算替代取模,极速)。
- 树化机制:链表长度 > 8 且 数组长度 >= 64 时,链表转红黑树(查找从 O(n) 提升到 O(log n));树节点 < 6 时退回链表。
- 扩容机制:默认容量 16,负载因子 0.75(size > 16*0.75=12 时触发),扩容为原 2 倍,需重新计算所有元素位置。
- 性能优化:预估数据量时指定初始容量(如存 1000 个元素,设
new HashMap<>(2048)),避免频繁扩容。
2. 线程安全与并发控制
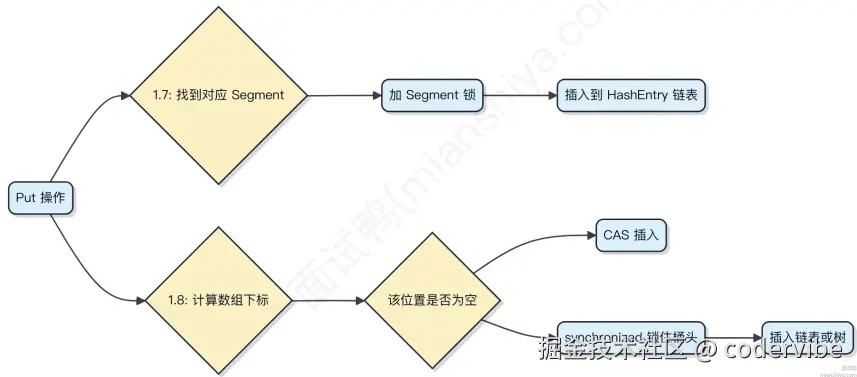
- ConcurrentHashMap (JDK 8+) :摒弃 Segment,采用
CAS + synchronized,仅锁链表/红黑树头节点,并发度极高;读操作无锁(靠 volatile 保证可见性)。
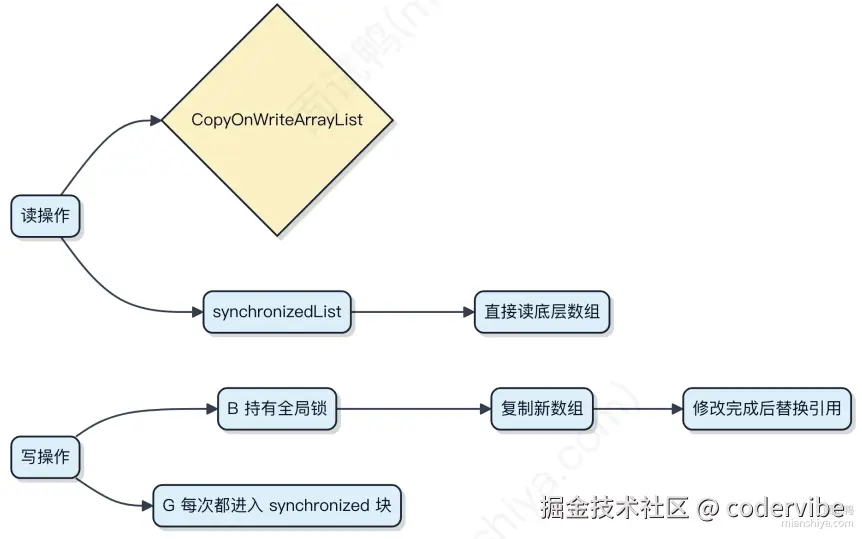
- CopyOnWriteArrayList:写操作加锁并复制整个数组,读操作无锁;缺点:写代价高,内存占用大,数据弱一致性。
3. Fail-Fast 机制
- 集合内部维护
modCount,遍历期间若结构被修改,迭代器比对发现不一致则抛出 ConcurrentModificationException。
- 安全删除:遍历时删除必须用
iterator.remove(),或直接使用并发容器。
七、实战避坑指南(⭐ 重点牢记)
- ArrayList 必预分配:已知大小时
new ArrayList<>(capacity),避免多次 1.5 倍扩容和数组拷贝。
- 禁用 LinkedList 的
get(i) :链表随机访问是 O(n),性能极差。
- CopyOnWriteArrayList 忌频繁写:写操作全量复制,大列表或高频写场景会拖垮性能。
- 遍历时安全删除:严禁
list.remove(obj),必须用迭代器的 remove()。
- HashMap 忌并发写:多线程 put 会导致环形链表和数据丢失,务必用 ConcurrentHashMap。
- 重写 equals 必重写 hashCode:否则 HashMap/HashSet 中逻辑相同的对象会被当成两个 Key,导致存取失败。
- ConcurrentHashMap 不允许 null:Key/Value 均不能为 null,避免
containsKey 和 get 歧义。
- 别用过时类:Stack(用 ArrayDeque)、Hashtable(用 ConcurrentHashMap)、Vector(用 CopyOnWriteArrayList)。
- HashMap 容量设 2 的幂:保证
hash & (n-1) 等效取模且分布均匀,减少哈希冲突。


