

有人翻了三个月的 Claude Code 日志,发现 Anthropic 在 3 月初悄悄把一个关键参数从 1 小时砍到了 5 分钟。没有任何公告,没有任何说明。结果就是:同样的使用习惯,配额消耗直接翻倍。很多人以为是自己用多了,其实是被偷偷"调"了。
先说你可能已经遇到了什么问题
最近有没有觉得 Claude Code 的配额莫名其妙就用完了?
明明上个月同样的工作量,还剩好多配额;这个月才工作两个小时,配额就见底了?
你不是一个人。
GitHub 上有人发帖:「Max 20 订阅,轻量使用 2 小时配额全空」;还有人说「配额 70 分钟就耗尽,以前从来没遇到过」。这些帖子在 4 月初密集出现。
直到有人挖出了原因——Anthropic 在 3 月初悄悄改了一个参数。
事情是怎么被发现的
4 月 13 日,开发者 Daniel Nguyen 发了一条推文,直接点名 Anthropic 在 3 月份悄悄修改了 Claude Code 的缓存有效期,从 1 小时缩短到了 5 分钟。

这条推文迅速引发了大量共鸣。评论区里有人愤怒、有人困惑、也有人一语中的:


也有人想出了歪招应对——每隔几分钟发一条"回复 OK"的消息,强行续命:

先搞懂"缓存"是什么意思
在讲数据之前,先给不熟悉的朋友解释一下"缓存"是什么。
你每次和 Claude Code 对话,它都要把大量内容(代码库、对话历史、系统提示等)送进模型处理。这些内容动辄几十万个字符,每次重新处理要花很多算力,也要消耗你的配额。
缓存的作用就是:如果这次发送的内容和上次完全一样,就不重新算了,直接用上次的结果。这样既省时间,也省你的配额。
**缓存有效期(TTL)**就是这个"上次结果"能保存多久:
- 1 小时:你工作了 45 分钟,中断了一会儿,回来继续——缓存还在,继续省配额
- 5 分钟:你上了个厕所回来——缓存已过期,Claude Code 要重新算一遍,重新消耗你的配额
对经常连续工作几小时的用户来说,1 小时缓存和 5 分钟缓存的区别,可以直接导致配额消耗量翻倍。
有人翻了 12 万条 API 调用记录来证明这件事
光说感觉不够,有人用数据说话。
GitHub 用户 seanGSISG 把两台机器、两个账号、从 1 月 11 日到 4 月 11 日的所有 Claude Code 日志全扒了出来,共计 119,866 次 API 调用。
每次 API 响应里都藏着两个字段,能直接显示用的是 5 分钟还是 1 小时缓存。他把数据按天整理,得出了一个非常清晰的时间线:
| 阶段 | 时间 | 缓存情况 |
|---|---|---|
| 第一阶段 | 1月11日–1月31日 | 几乎全是 5 分钟 |
| 第二阶段 | 2月1日–3月5日 | 连续 33 天,100% 1 小时缓存 |
| 过渡期 | 3月6–7日 | 5 分钟开始重新出现 |
| 第三阶段 | 3月8日–4月11日 | 5 分钟占到 80–93% |
最关键的是:他用的是两台不同机器、不同账号,但时间点完全一致。这直接排除了个人操作差异——问题一定出在 Anthropic 的服务端。
推文里附的三张数据截图清楚显示了这个变化:



Anthropic 在 3 月初改了服务端缓存策略,没有公告,没有文档更新,甚至没有在 Claude Code 的更新日志里提一句。用户的配额消耗悄悄涨了 20-32%,很多人还以为是自己用多了。
还有一个藏得更深的坑
这是整件事里最让人无语的细节。
如果你出于隐私考虑,关掉了 Claude Code 的遥测功能(telemetry off)——这是很多开发者会做的选择——那你从头到尾都在用 5 分钟缓存,连 1 小时缓存是什么感觉都没体验过。
原因是:Anthropic 的缓存优化是通过"实验配置"从服务端下发到客户端的。而关掉遥测之后,Claude Code 就不联系服务器了,只读取本地默认值。本地默认值,就是 5 分钟。
换句话说:你保护了自己的隐私,但因此损失了更好的缓存效果,每次用 Claude Code 都要多花配额——而 Anthropic 从来没有在任何文档里告诉你这个权衡关系。
不过,也有少数用户反映他们的 1h 缓存依然正常。有人还用抓包工具 HTTP Toolkit 直接验证了这一点:

这说明 Anthropic 是在做灰度测试,并非所有人都受到了影响——但大多数人被切换到了 5 分钟。
Anthropic 的员工后来确认了这件事
在 Daniel 发推前,Claude Code 的 GitHub issue 里已经有人找 Anthropic 员工问过了。Daniel 后来也更新了推文:

Anthropic 员工 Jarred 确认确实有变更,并表示这个调整应该让费用降低,而不是增加。
Claude Code 作者的官方回应
在 Daniel 推文发出大约 14 小时后,Claude Code 的作者 Boris Cherny 在 X 上做了一次详细回复。

他的核心意思是:
"1 小时不一定比 5 分钟更省钱"
1 小时缓存写入费用更贵(需要保存更久),但读取更便宜。如果你只发一条消息就关掉 Claude Code,1 小时缓存的写入费用就白付了——用 5 分钟反而更省。只有连续工作几小时的重度用户,1 小时才真的划算。
"我们一直在做实验,不是一刀切"
Anthropic 在根据使用场景动态调整:主流程用的主 agent 在部分场景已默认 1 小时;子 agent(subagent)保持 5 分钟,因为子 agent 很少被长时间持续使用。
"关遥测 = 用本地默认值 = 5 分钟"
他确认了这个问题,并表示即将把客户端本地默认值改为 1 小时,同时会提供环境变量让用户手动强制指定缓存时长。
"省钱幅度没有传言那么夸张"
1 小时缓存能节省的 token,"绝不是 12 倍",是"小幅改善"。
技术层面上,Boris 的解释是说得通的。但社区对这件事最大的不满并不是缓存策略本身,而是:
第一,这个调整是悄悄做的。 没有公告,没有文档更新,没有 changelog。用户只能靠翻日志、看账单来发现异常。
第二,关遥测的代价从来没被告知过。 这等于把"隐私保护"和"成本优化"变成了非此即彼的选择,而用户压根不知道这回事。
回复区里也有开发者提出了另一个视角——如果子 agent 从来不被恢复,是不是产品本身的 bug 导致的?
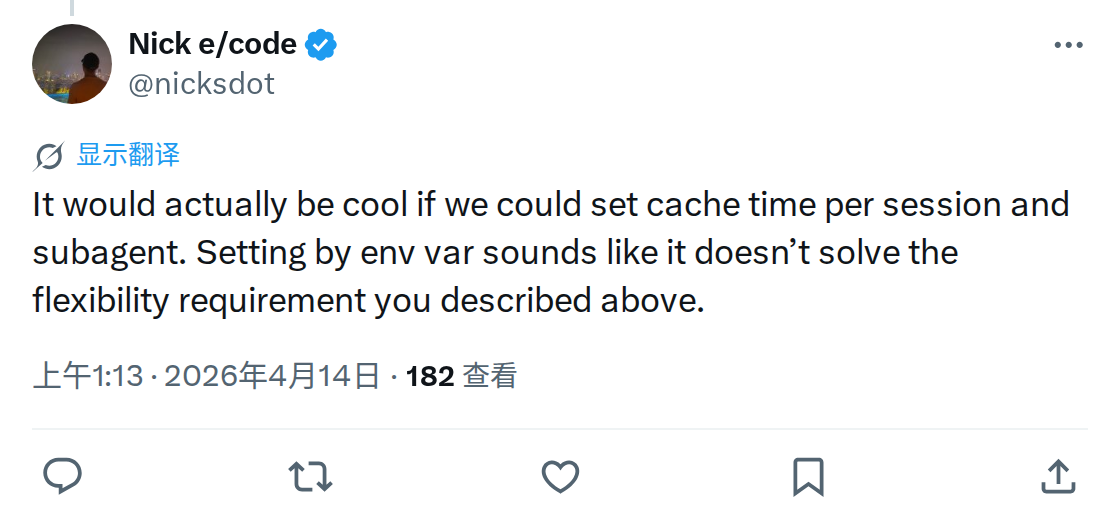
他说的是:Anthropic 说"子 agent 很少被恢复,所以给 5 分钟"——但子 agent 无法被恢复,可能本身就是一个没修好的 bug,20 多个版本以来一直存在。用"很少被恢复"来合理化 5 分钟缓存,逻辑上站不住脚。
你现在能做什么?
1. 确认自己是否受影响
找 Claude Code 的会话日志文件(在 ~/.claude/projects/ 目录下,macOS 在 ~/Library/Application Support/Claude/projects/),找 usage.cache_creation 字段,看里面 ephemeral_5m_input_tokens 和 ephemeral_1h_input_tokens 哪个更多。如果全是 5 分钟,大概率是遥测被关了,或者你还没进入 1 小时的实验组。
2. 如果关了遥测,短期内先开着
Boris 说即将把客户端默认值改成 1 小时,并支持环境变量手动控制。在官方修复落地之前,如果你现在开着遥测,至少有机会享受 1 小时缓存。
3. 减少短时间内的大量独立请求
把多个小任务合并成一次大请求,让 Claude Code 在一次会话里处理更多事情,能最大程度利用缓存——无论是 5 分钟还是 1 小时都适用。
🦞 想和一群 AI 玩家一起交流实战经验?
在公众号对话框回复「小龙虾」,加入龙虾养成群——一个专注 AI 工具提效、工作流搭建、自动化实操的交流社群。
只聊 AI 实战干货,一起玩转效率工具 👇
参考链接
- GitHub Issue #46829(缓存 TTL 回归分析):github.com/anthropics/…
- GitHub Issue #45381(关遥测导致 5 分钟缓存):github.com/anthropics/…
- Boris Cherny 官方回复:x.com/bcherny/sta…
