

🌟 【本文价值提示】 适合人群:数据开发工程师、AI 应用开发者、数据分析师、对 AI Agent 感兴趣的技术爱好者。 你将收获:
- 理解当前最火的 MCP (Model Context Protocol) 协议的核心工作原理。
- 掌握在 Cherry Studio 中零代码接入自定义 Python 脚本的方法。
- 获得一套生产可用的“AI + StarRocks + MySQL元数据”双库联动落地方案。
- 学会如何通过“系统提示词 (SOP)”彻底解决大模型胡编乱造 SQL 的“幻觉”问题。
- 避开密码解析报错、大查询 OOM 等真实生产环境中的“暗坑”。
大家好!随着大模型(LLM)能力的爆发,越来越多人尝试让 AI 帮自己写 SQL 查数据。但现实往往很骨感:AI 总是凭空捏造表名、瞎编字段,甚至有时候还会写出危险的 DROP TABLE 语句!
今天,我将带大家实战落地一套企业级的数据分析 Agent 方案。我们将使用 Cherry Studio 作为客户端,通过官方力推的 MCP 协议,结合 Python 脚本,让大模型安全、精准地连接到你的 StarRocks 生产库和 MySQL 元数据系统。
准备好了吗?让我们开始这场让 AI 真正懂你业务的数据之旅!🧳
💡 一、 什么是 MCP?为什么我们需要它?
在讲技术之前,我们先打个比方。
如果把大模型比作一个 “极其聪明但刚入职的实习生”:
- 他大脑很灵光(逻辑推理能力强),但他没有公司的内网权限,也不知道公司的数据库里存了什么。
- 过去,我们只能把表结构复制粘贴给他(Context 窗口限制),他写好 SQL 后,我们再手动去数据库跑,跑完报错了再把报错信息贴给他……整个过程极其痛苦。
而 MCP (Model Context Protocol),就像是给这位实习生配发了一台 “装了公司内网 VPN 和数据库客户端的工作电脑”。 MCP 是一种标准协议,它允许大模型直接调用本地或远程的工具(Tools)。通过 MCP,大模型可以自己去查表结构、自己执行 SQL、自己看报错并修改,最终直接把分析好的数据端到你面前!
🗺️ 核心架构流程图
让我们用一张图来看看这套系统的运转流程:
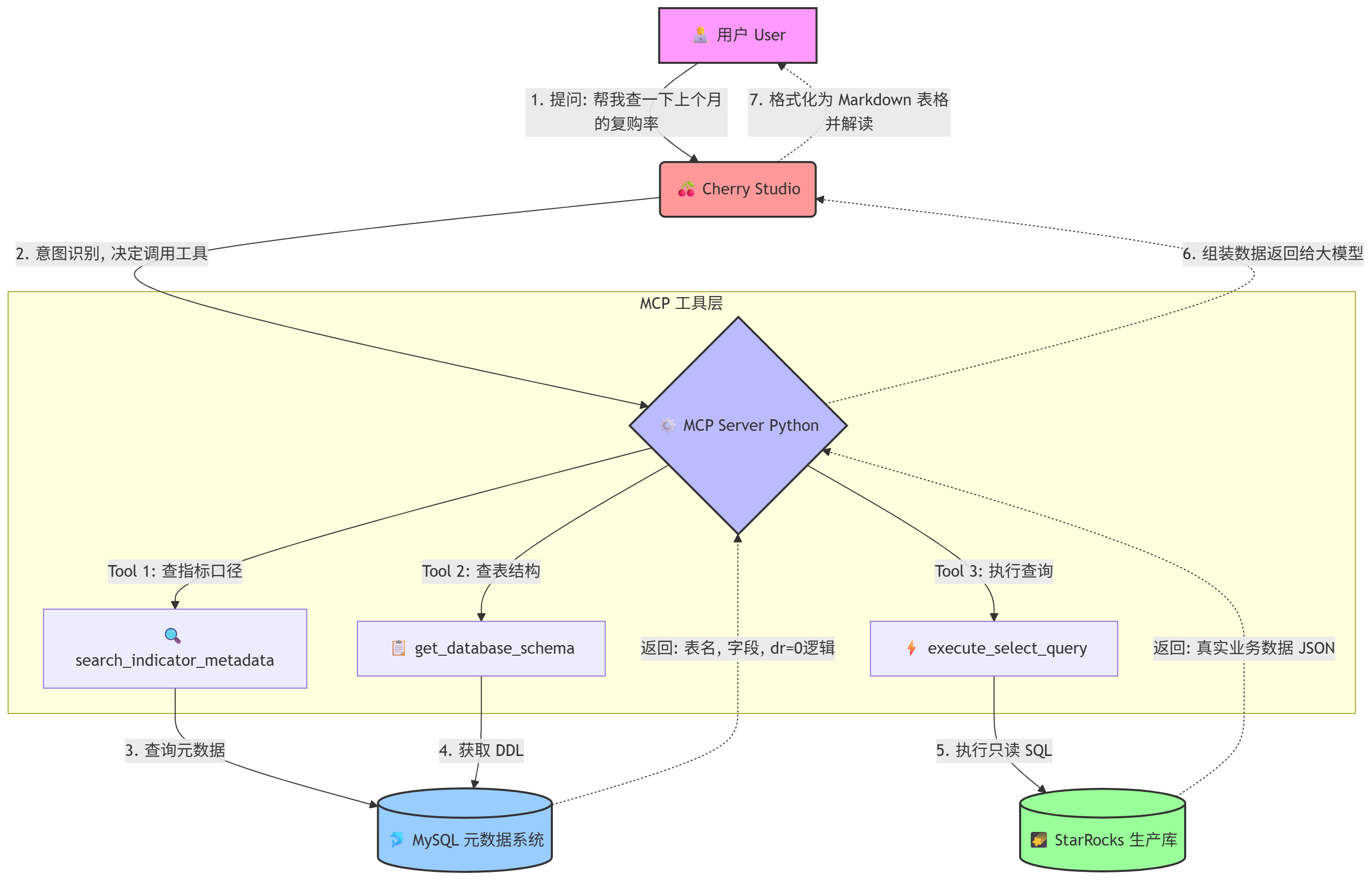
🛡️ 二、 生产环境的“排雷”指南:安全与稳定
在 MVP(最小可用产品)阶段,我们可能随便连个 SQLite 就能跑通。但要接入 StarRocks 这种生产级 OLAP 数据库,我们必须跨过几道坎。
1. 绝对的安全防御:防注入与防手抖
大模型再聪明,也有“发癫”的时候。为了防止它执行 DROP DATABASE,我们在 Python 脚本中加入了双重保险:
- 代码层正则拦截:强制校验 SQL 必须以
SELECT、WITH、SHOW或DESCRIBE开头,一旦检测到DELETE、UPDATE等关键字,直接拦截并返回警告给大模型。 - 数据库层权限隔离:强烈建议在 StarRocks 中为 MCP 分配一个纯只读账号。
2. 内存保卫战:防止 OOM
如果大模型写了一句 SELECT * FROM 亿级大表,返回的海量数据瞬间就会撑爆 Python 的内存,甚至让 Cherry Studio 崩溃。
对策:我们在脚本中强制加入了 MAX_ROWS = 100 的限制。使用 result.fetchmany(100),并在返回的 JSON 中温柔地提醒大模型:“为防止内存溢出,最多只返回 100 条数据,请合理使用 LIMIT 和聚合函数。”
3. 隐藏的暗坑:密码中的特殊字符
在实战中,我们遇到了一个经典的报错:getaddrinfo failed。
排查发现,是因为数据库密码中包含了 @ 符号,导致 SQLAlchemy 解析连接字符串时,把 @ 后面的内容当成了主机名!
解法:引入 urllib.parse.quote_plus 对账号密码进行 URL 编码,完美解决。
🧠 三、 注入灵魂:引入 MySQL 元数据系统
这是本文最核心的秘籍! 为什么很多人的 SQL Agent 效果极差?因为大模型不懂你的业务黑话。
用户问:“查一下订单表”。大模型怎么知道你的订单表叫 ods_order_info 还是 dwd_trade_order?它怎么知道有效数据必须加 dr = 0 的过滤条件?
为此,我们专门开发了 MySQL 元数据 MCP 服务,给大模型配备了两个“外挂”:
- 🗂️
search_table_metadata:大模型可以通过模糊搜索(如“订单”),去 MySQL 里查出真实的物理表名、中文名和表描述。 - 📊
search_indicator_metadata:当用户问“复购率”时,大模型先去查这个指标的计算口径和归属部门。
这就好比,我们在让实习生去仓库(StarRocks)搬砖之前,先让他去查阅了公司的《数据字典》(MySQL)。 这样写出来的 SQL,准确率直线上升!
📜 四、 驯服大模型:编写完美的 SOP 提示词
工具准备好了,接下来就是给这位“实习生”下达指令。在 Cherry Studio 中,我们为助手配置了如下的系统提示词(System Prompt),强制它按照我们的 SOP(标准作业程序)工作:
Role: 资深 StarRocks 数据开发工程师
SOP 流程: Step 1: 查阅元数据(定位) 绝对不要凭空猜测表名!优先调用
search_indicator_metadata和search_table_metadata查找业务口径和真实表名。查询元数据时务必加上dr = 0。Step 2: 确认物理表结构(防错) 调用工具执行
SHOW CREATE TABLE,确保你接下来写的 SQL 字段 100% 正确。Step 3: 编写 StarRocks SQL(执行) 严格使用 StarRocks 语法,注意系统最多返回 100 行数据,必须合理使用
ORDER BY和LIMIT。Step 4: 异常自愈(Self-Correction) 如果 SQL 报错,不要立即向用户道歉。仔细阅读错误日志,自行修改 SQL 后再次执行,直到获取正确结果!
特别是 Step 4(异常自愈),这是 Agent 的灵魂!你会惊奇地发现,当字段名拼错时,大模型会在后台默默地修改 SQL 并重试,最终只把成功的结果展示给你。这种体验,简直太优雅了!🍷
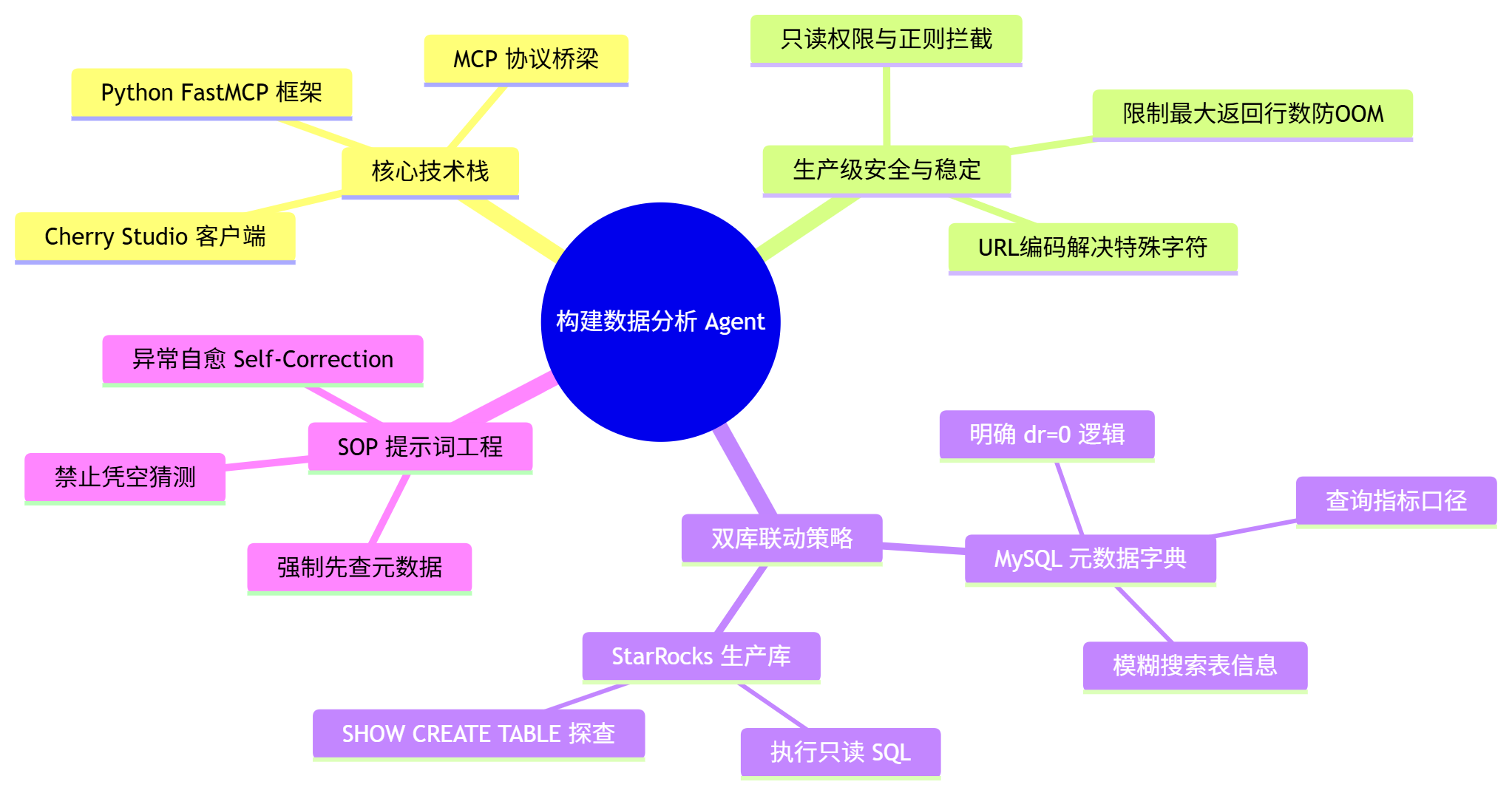
🎯 五、 总结与回顾
通过 Python + FastMCP + SQLAlchemy,我们成功地将 Cherry Studio 变成了一个强大的企业级数据分析终端。
让我们用一张思维导图来回顾一下今天的核心知识点:
💬 互动时间:聊聊你的踩坑经历!
将 AI 接入企业数据库,是一件既兴奋又充满挑战的事情。 你在让大模型写 SQL 的时候,遇到过哪些让人啼笑皆非的“幻觉”?或者你目前正在考虑将 AI 接入哪种数据库?
👇 欢迎在评论区留言分享你的看法! (如果你需要本文完整的 Python MCP 源码和 DDL 脚本,关注公众号【大数据与 AI 架构实战分享】后台回复关键词 【MCP源码】 获取!)
