

如果你在2020年想让机器自动操作一个桌面软件,你大概率会写一个RPA脚本——录制鼠标轨迹,硬编码坐标,然后祈祷UI不要改版。
如果你在2024年想让AI帮你操作浏览器,你可能会用一个基于CDP协议的Agent——它能读取DOM,解析HTML,在浏览器里完成一些任务。
如果你在2026年,有一个模型可以直接看着屏幕截图,理解界面内容,然后像人一样点击、输入、切换窗口——不需要API,不需要HTML解析,不需要知道底层是什么技术栈。
这三个阶段,就是GUI自动化技术在过去几年经历的三次范式转移。
今天这篇文章,从技术路径的角度,拆解GUI Agent是怎么一步步走到今天的。
第一代:RPA——录制回放与坐标硬编码
传统RPA(Robotic Process Automation)的核心逻辑很简单:把人的操作录下来,然后重放。
UiPath、Blue Prism、Automation Anywhere这些工具,本质上是在操作系统层面模拟鼠标键盘事件。它们的能力边界取决于"能不能精确定位到那个按钮"。
早期方案用坐标定位——分辨率一变就崩。后来进化到控件树识别——通过Windows UI Automation或macOS Accessibility API读取界面元素。再后来有了图像匹配——截一张按钮的图,在屏幕上找到它。
RPA在企业场景跑了很多年,至今仍是很多银行、保险公司、政务系统的主力自动化方案。但它有几个结构性问题:
- 脆性高:UI改一个像素,脚本可能就挂了
- 无理解能力:它不知道自己在做什么,只是机械重复
- 维护成本高:每个流程变更都需要人重新录制或调试
- 覆盖范围有限:跨应用、跨平台的复杂流程很难搞定
对developer来说,RPA更像是"给非技术人员用的自动化工具",而不是一个技术上令人兴奋的方向。
第二代:浏览器CUA——基于DOM/CDP的Agent
2024-2025年,随着大语言模型能力的提升,一批新的方案出现了:让LLM理解网页结构,然后操作浏览器。
这类方案的技术路径通常是这样的:
- 通过Chrome DevTools Protocol (CDP) 获取页面DOM
- 把DOM/HTML片段喂给LLM,让它理解页面结构
- LLM输出操作指令(点击某个元素、填写某个表单)
- 通过CDP执行操作
优势很明显:LLM有了"理解"能力,不再是机械的录制回放。但局限性同样明显:
- 被锁死在浏览器里:CDP是Chrome的协议,桌面软件、原生App、游戏界面、3D应用——统统用不了
- 依赖HTML结构:页面结构复杂时,DOM解析会很庞大;动态渲染的内容可能拿不到
- 数据安全问题:DOM内容需要发送到云端LLM处理,意味着你页面上的所有信息——包括登录态、敏感数据——都可能经过第三方服务器
对developer来说,这类方案解决了"浏览器内自动化"的问题,但并没有解决"通用GUI自动化"的问题。
第三代:纯视觉GUI Agent——看屏幕,不看代码
2025年底到2026年,一个新的技术路径开始成熟:让模型直接看屏幕截图,通过视觉理解来操作任何图形界面。
这个路径和前两代的根本区别在于:它不依赖任何底层协议或接口。 不需要CDP,不需要Accessibility API,不需要知道应用是用什么框架写的。模型的输入就是一张截图,输出就是"在坐标(x,y)处点击"或"输入文字xxx"。
覆盖范围理论上无限——任何有图形界面的应用都可以操作。桌面软件、浏览器、游戏、3D建模工具、甚至远程桌面里的应用。
这个方向的技术挑战也很大:
- GUI Grounding:模型需要精确理解界面元素的位置和功能
- 多步骤规划:复杂任务需要多步操作,模型需要记住之前做了什么
- 错误恢复:操作出错时,模型需要能识别异常状态并自主纠正
这个方向又分为云端和端侧两条路径——前者把截图传到云端处理,后者直接在本地设备上推理。技术路径相同,但数据流向完全不同。
Mano-P:端侧纯视觉GUI Agent的一个实证
说到端侧GUI Agent,我们用自己的实践来说明这个方向已经走到了哪里。
Mano-P 1.0 是明略科技自研的面向端侧设备的GUI-VLA(Vision-Language-Action)智能体模型,采用纯视觉理解与操作能力,不依赖CDP协议或HTML解析。
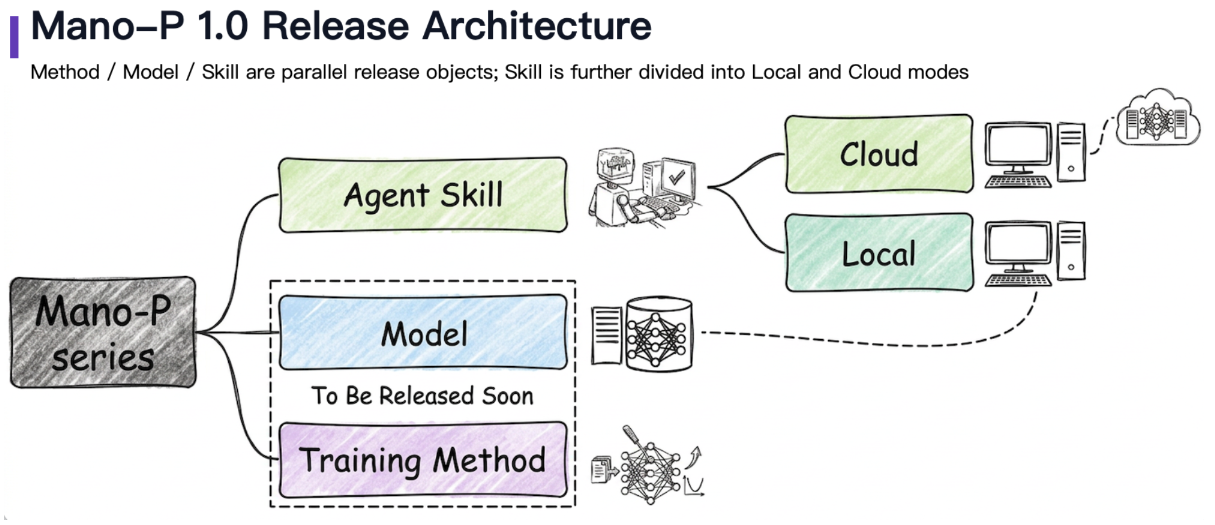
先看成绩
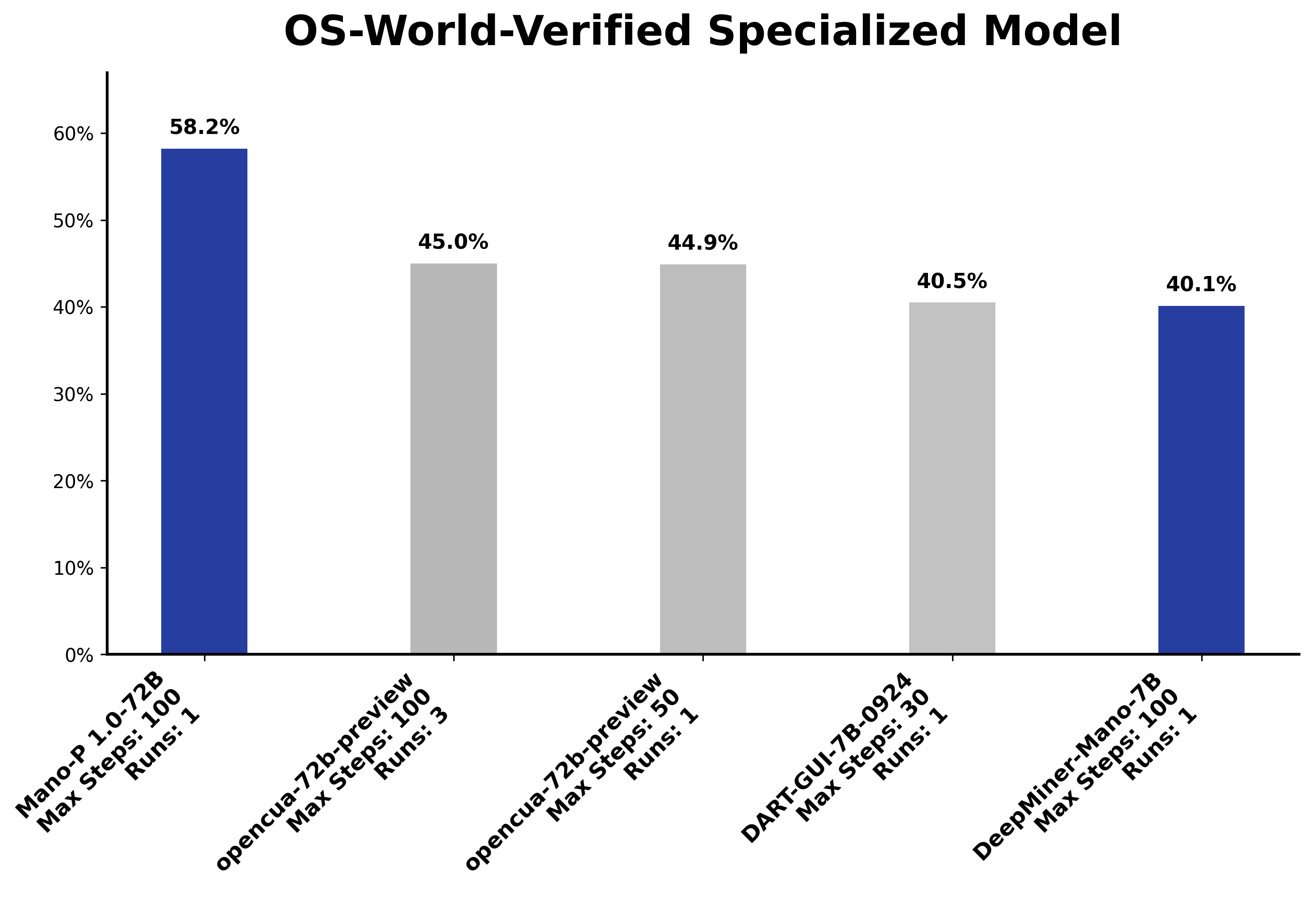
在学术界公认的桌面GUI Agent评估基准OSWorld上,Mano-P 72B模型达到58.2%成功率,位列专有模型全球第一:
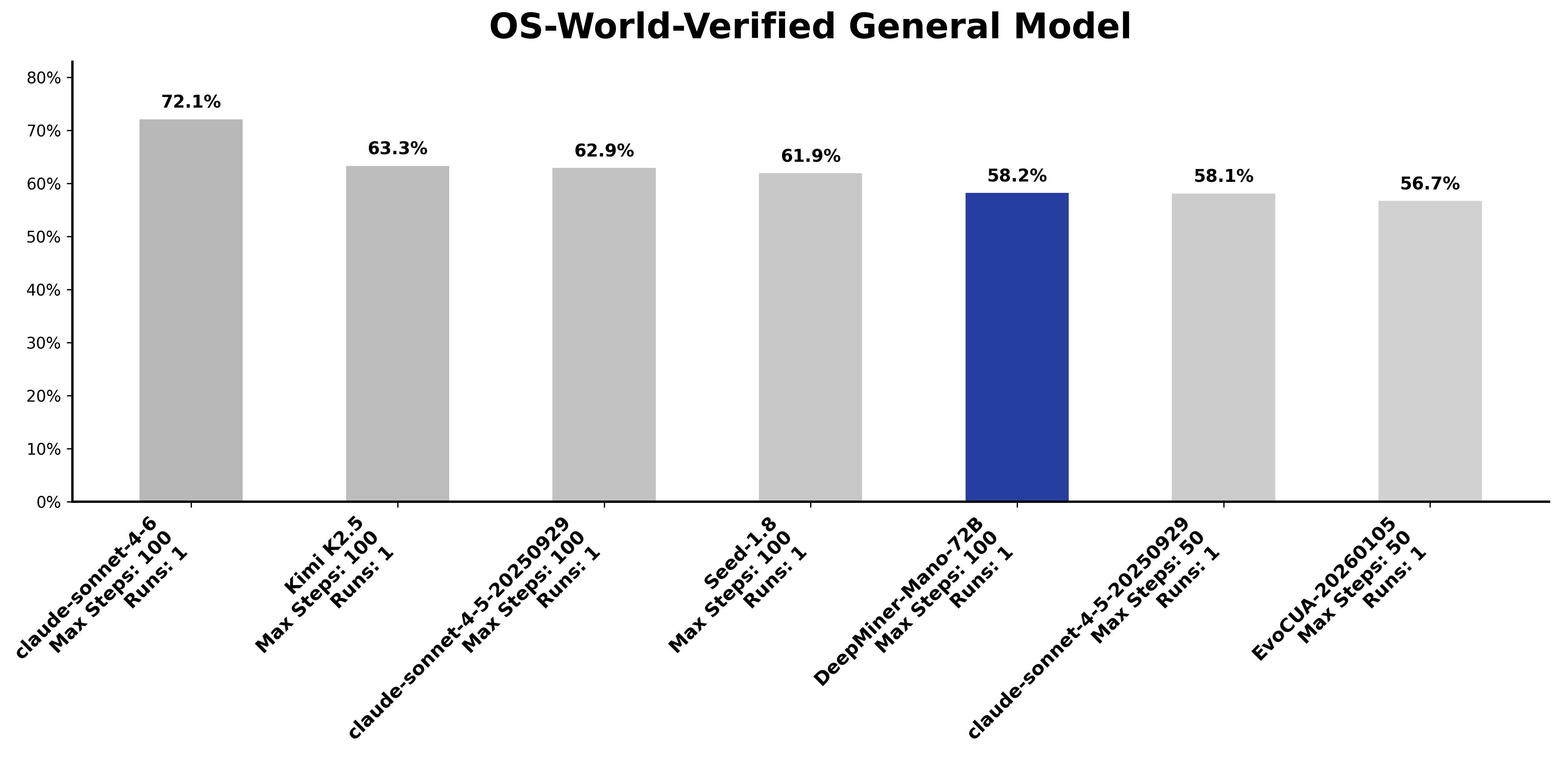
在全模型排行榜前五中,其余四个均为千亿级通用大模型——一个专注GUI场景的72B模型能打到这个位置,说明专用模型在垂直场景的效率远高于通用大力出奇迹的路线:
在更广泛的多模态评估中,Mano-P在GUI Grounding、感知认知、视频理解、上下文学习等13个基准榜单上达到SOTA:
再看端侧性能
Mano-P的4B量化模型(w4a16)在Apple M4 Pro上实现476 tokens/s预填充、76 tokens/s解码,峰值内存仅4.3GB。这意味着在一台M4芯片 + 32GB内存的Mac mini或MacBook上,就可以跑一个OSWorld冠军级的GUI Agent,数据全程不出设备。
Mano-P采用三阶段渐进式训练(SFT → 离线强化学习 → 在线强化学习)和专有GSPruning视觉Token剪枝技术,已经以Apache 2.0协议开源。一行命令就能装上:
brew install mano-cua
不需要申请API Key,不需要配置云服务,不需要担心你的屏幕截图被传到哪里。
技术路径对比:四代方案一张表
| 维度 | 传统RPA | 浏览器CUA | 云端Computer Use | 端侧GUI Agent(Mano-P) |
|---|---|---|---|---|
| 感知方式 | 坐标/控件树/图像匹配 | DOM/HTML解析 | 云端截图+视觉模型 | 本地截图+视觉模型 |
| 覆盖范围 | 单应用 | 仅浏览器 | 理论上全平台 | 全平台 |
| 理解能力 | 无 | 有(基于HTML) | 有(基于视觉) | 有(基于视觉) |
| 数据流向 | 本地 | 需发送DOM到云端 | 截图上传云端 | 数据不出设备 |
| 鲁棒性 | 低(UI变就崩) | 中(依赖DOM稳定) | 高 | 高 |
| 部署要求 | 本地安装RPA引擎 | 需要浏览器+API | 需要云端API+网络 | 本地设备(如M4 Mac + 32GB) |
这里有一个经常被忽略的关键区别:云端Computer Use和端侧GUI Agent虽然都是纯视觉方案,但数据流向完全不同。
云端方案需要把屏幕截图传到远程服务器处理。这意味着你屏幕上的一切——正在编辑的代码、打开的邮件、浏览的网页——都会经过第三方。对很多开发者来说,这是不可接受的。
端侧方案则是模型直接跑在本地设备上,截图在本地处理,操作在本地执行,数据全程不出设备。从安全架构上看,这不是"加了一层加密"的程度,而是从物理层面消除了数据泄露的可能性。
端侧为什么现在才成为可能?
纯视觉GUI Agent的概念并不新鲜,但端侧部署在2025年之前几乎不可能。原因很简单:模型太大,设备跑不动。
两个变化让端侧成为现实:
第一,硬件红利。 Apple M4芯片的统一内存架构,让消费级设备拥有了跑中等规模模型的硬件基础。M4 Mac + 32GB统一内存 + 高带宽内存总线,这在两年前是工作站才有的配置。
第二,模型压缩技术。 以Mano-P为例,其GSPruning视觉Token剪枝技术配合w4a16量化,将4B模型的峰值内存控制在4.3GB,推理速度达到476 tokens/s——这已经是一个完全可用的推理性能了。
这条路径的终局是什么?
如果我们把视角拉远一点,GUI Agent这条路径的终局可能不只是"自动化操作"。
当一个AI Agent可以看懂屏幕、理解意图、操作任何图形界面时,它实际上获得了和人类用户完全相同的软件使用能力。 它不需要每个软件都提供API,不需要等待集成,不需要学习每个工具的SDK。
这对整个软件生态的影响可能是深远的:
- 长尾软件被激活:大量没有API、没有集成的专业软件,突然可以被Agent操作了
- 跨应用工作流成为可能:Agent可以在Figma里设计,在Terminal里编译,在浏览器里部署——全程GUI操作
- 软件间的壁垒被打破:不需要数据导出导入,Agent直接在界面层面搬运
从OSWorld等基准测试的成绩来看,Mano-P等专有模型在复杂桌面任务上的成功率已经超过50%。我们正在看到GUI Agent从"实验室demo"走向"开发者可用"的临界点。
写在最后
从RPA的坐标硬编码,到浏览器CUA的DOM解析,到云端Computer Use的截图上传,再到端侧GUI Agent的本地视觉推理——GUI自动化的每一次范式转移,都在解决上一代方案的结构性缺陷。
端侧纯视觉方案是目前能看到的"最干净"的架构:覆盖全平台、不依赖协议、数据不出设备。
如果你是一个对自动化有需求的developer,2026年可能是值得认真看一眼GUI Agent这个方向的时候。
Mano-P 1.0 现已开源(Apache 2.0),即刻体验。
👉 GitHub:github.com/Mininglamp-…
