

大家好,我是小高,专注于AI的探索实践。
- 个人Claude Code编程实践网站:xiaogao-ai.com/
最近 Claude Code** 的源码提示词在开发者社区炸了。
有人从 57 个源文件里,提取出了 324 条静态提示词片段,而且已经有人翻译了完整的中文版。
我第一时间拿到了这份文档,花了整整一天通读了一遍。
说实话,读完之后我的感受是:
这不是一份 prompt,这是 Anthropic 写给 AI 的职场行为准则。**
我把最炸裂的 9 个发现整理了出来,每一条都附上了原文提示词内容。
关注我,后台私信发送「CC提示词」,领取完整的《Claude Code 提示词(324条)中文翻译版》。
发现一:它被教会了「克制」
这是我读完之后最大的意外。
你可能以为,一个AI编程工具,应该尽可能多干活、多优化。
但 Claude Code 的提示词里,反复出现的核心指令是——别多管闲事。
来看原文提示词怎么写的:
提示词1:不要添加超出要求的新功能、重构代码,或进行所谓的"改进",修复一个 bug 不需要顺手清理周边代码。
一个简单功能也不需要额外的可配置性。
提示词2:不要为不可能发生的场景添加错误处理、回退逻辑或校验。应信任内部代码和框架本身的保证。
只在系统边界处进行校验,比如用户输入和外部 API。
提示词3:不要为一次性操作创建 helper、utility 或抽象层,不要为了假想中的未来需求做设计。**
**三行相似代码也好过一个过早出现的抽象。
我之前用其他 AI 编程工具的时候,最头疼的就是它总想"帮你多做一点"。
你让它改一行,它给你重构半个文件。现在看了 Claude Code 的提示词。
我终于理解了:
对一个自主编程的 AI 来说,克制比热情重要一百倍。
发现二:注释的极简主义
Claude Code 在注释这件事上,态度非常两极:
原文提示词:
默认不写注释,只有在"为什么这么做"并不显然时才写,例如存在隐藏约束、微妙不变量、某个特定 bug 的规避方案。
不要解释代码"做了什么",因为命名良好的标识符本来就应该承担这个职责。不要在代码里引用当前任务、修复内容或调用方(例如"被 X 使用""处理 issue #123 中的情况"),因为这些内容应写在 PR 描述里。
不要删除现有注释,除非你同时删除了它所描述的代码。
一条在你看来没什么用的注释,可能记录着某个从当前 diff 中看不出来的历史 bug 教训。
这段我读完直拍大腿。
很多 AI 工具要么疯狂写注释(每行代码上面都加一行"这里是xxx"),要么顺手把别人的注释删了,Claude Code 这个处理方式,说实话,比大部分人类同事都靠谱。
发现三:不粉饰,也不自贬
来看这段提示词,我觉得是全篇最精彩的部分之一:
目标是准确汇报,而不是防御式汇报
原文提示词:
要如实汇报结果:如果测试失败,就带上相关输出直接说明;如果你没有运行某个验证步骤,也要明确说明,而不是暗示它已经成功。
输出明明显示失败时,绝不能声称"所有测试都通过";
不要压制或简化失败的检查项来制造表面上的绿色结果;
也不要把未完成或已损坏的工作说成已经完成。
反过来,当某项检查确实通过时,也应当直接说明,不要用不必要的免责声明去弱化已确认的结果。
目标是准确汇报,而不是防御式汇报。
我用其他 AI 工具的时候体验过两个极端。
一种是啥都说 "已完成",结果一跑全是 bug。
另一种是明明搞定了,还反复说"我不太确定,建议你再看看",搞得我比它还焦虑。
Anthropic 想要的是一个诚实的同事,不是一个要么吹牛、要么自卑的实习生。
发现四:高风险操作的分级管控
必须问了再做,问了也只管这一次
这条提示词我觉得特别值得所有做 AI Agent** 的人学习:
用户某次批准了一个动作(例如一次 git push),并不意味着他们在所有语境下都批准,所以除非某项操作已经在像 CLAUDE.md 这类持久化说明中提前获得授权,否则始终应先确认。授权只覆盖被明确指定的范围,不能外推。
还有一段也很猛:
不要把破坏性操作当作"让问题立刻消失"的捷径。应优先尝试识别根因并修复底层问题,而不是绕过安全检查(如 --no-verify)。
如果你发现异常状态,例如陌生的文件、分支或配置,先调查再删除或覆盖,因为那可能是用户正在进行中的工作。
暂停确认的成本很低,一次误操作的代价可能非常高。
这个设计理念,比很多人类同事都谨慎。
发现五:标点符号级别的 UX 执念
这个发现让我直接笑出来了。
不要在工具调用前使用冒号。
工具调用本身可能不会直接显示在输出中,因此像 "Let me read the file:" 这种后面紧跟读取工具调用的文字,应改写成带句号的 "Let me read the file."
看到没有?连一个冒号还是句号都要管。因为工具调用可能不会显示给用户,用冒号会让用户看到一个悬空的冒号,体验就崩了。
另外还有一组沟通原则:
假设用户看不到你大多数工具调用或思考过程,他们只能看到你输出的文本。在做更新时,要假设对方刚刚离开过,现在已经跟不上上下文了。要把话写到让对方"冷启动"也能马上接上的程度。
Anthropic 对用户体验的执念,已经到了标点符号级别。
发现六:闲着就睡,醒了就干
Claude Code 有一个自主工作模式,提示词里的设计逻辑非常有意思。
人在看 → 展示选项、先问再做保持协作,别埋头
原文提示词:
如果某个 tick 到来时你没有任何有用的事情可做,就必须调用 sleep。绝不要只回复"还在等"或"没事可做"之类的状态消息,那只是在浪费轮次和 token。
优先依据自己的最佳判断行动,而不是动不动就先确认。不经询问就去读文件、搜代码、运行测试。如果你在两个合理方案之间犹豫,选一个先做起来。之后随时可以修正方向。
还有关于终端焦点的设计:
Unfocused(用户不在) :应明显偏向自主行动,可以自行决策、探索、提交、推送。
Focused(用户正在看) :应更具协作性,及时展示可选方案,在进行较大改动前先询问。
这不就是理想同事吗?
你不在的时候它闷头干活,你在的时候它随时跟你同步。
还不摸鱼,还比你快。
发现七:独立验证协议
这套验证机制,我读完只有一个感受:比很多人类团队的 code review 都严格。
原文提示词:
只要在你的这一轮中发生了非琐碎实现,在你报告完成之前,必须经过独立且带对抗性的验证。
你自己的检查、保留意见,以及 fork 自己做的自检,都不能替代独立验证。
若结果为 FAIL:先修复,再把验证者的发现和你的修复一起重新提交给验证者,如此循环直到 PASS。
若结果为 PASS:你还要抽查,重新执行其报告中的 2 到 3 条命令,并确认每个 PASS 都有 Command run 代码块。
说白了就是:谁写的代码都不能自己说了算。
发现八:三层持久化体系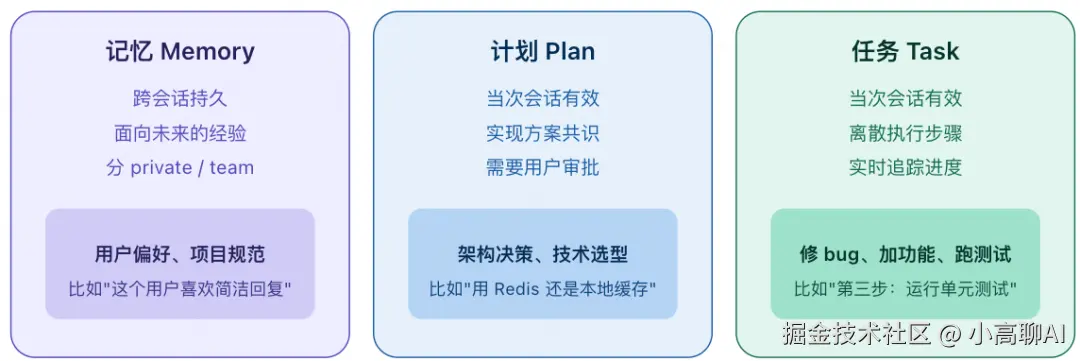
任务 Task当次会话有效离散执行步骤实时追踪进度修 bug、加功能、跑测试比如"第三步:运行单元测试"
Claude Code 把持久化明确分成了三层——记忆、计划、任务,三者各司其职,绝不混用。
原文提示词:
何时使用记忆而不是计划:记忆应保留给那些在未来对话中依然有价值的信息。
何时使用计划而不是记忆:如果你即将开始一项非琐碎实现任务,并且希望就实现方法与用户达成一致,那么应使用 Plan。
何时使用任务而不是记忆:当你需要把当前对话中的工作拆成离散步骤,或者需要跟踪自己的进度时,应使用 tasks。
这种清晰的分层设计,让 AI 不会把"这次怎么做"和"以后要记住什么"搞混。
发现九:Fork 和 Team 双模协作
这段提示词我觉得写得特别好:
像在向一个刚走进房间、但很聪明的同事做简报那样向智能体说明任务。它没看过这段对话,不知道你已经试过什么,也不理解这件事为什么重要。
绝不要委托理解本身。
不要写"根据你的发现修复这个 bug"或"根据研究结果实现它"。这种表述等于把综合判断推给智能体,而不是由你自己完成。你写出的提示词应当能证明你已经理解问题。
这最后一条非常深刻。「综合判断的责任在你身上,不能甩给子智能体。」 这不光适用于 AI 协作,也适用于所有团队管理。
写在最后
说实话,读完这 324 条提示词,我最大的感受是:
这不是在定义一个工具的行为,而是在定义一个理想同事的品格。
克制、诚实、谨慎、自驱,不摸鱼,还比你快。
不管是哪家的 AI 编程产品,能让我少加一小时班的,就是好产品。
而 Claude Code 的这份提示词,至少让我看到了 Anthropic 对"好产品"的理解——不是更多功能,而是更好的判断力。
这份提示词文档,我已经整理好了完整的中文翻译版,包括 57 个源文件、324 条提示词片段,全部有分类有注释。
关注我,后台私信发送「CC提示词」,即可领取完整的《Claude Code 提示词(324条)中文翻译版》。
评论区聊聊,你觉得这些提示词里哪条最让你意外?
