


几乎能做任何事情
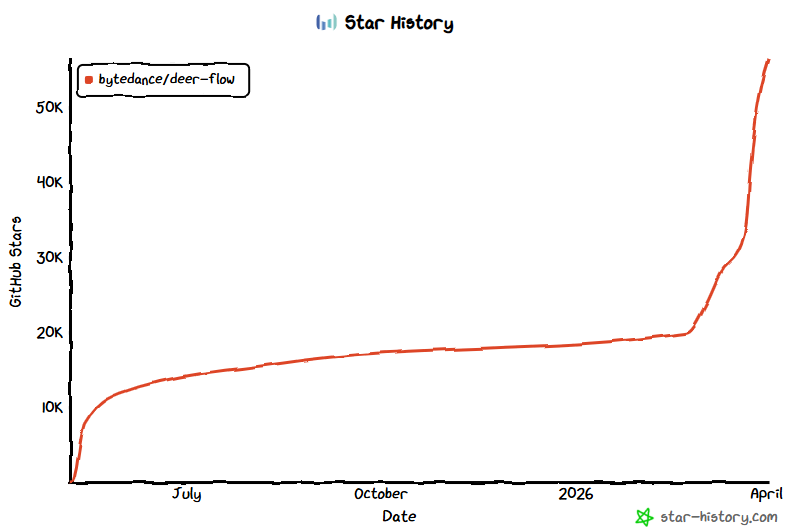
2026年2月28日,DeerFlow 2.0 发布后,直接冲上了 GitHub Trending 第一名。这是字节跳动开源的一个超级智能体框架,它能协调子智能体、记忆和沙箱,几乎能做任何事情。
想象一下,你有一个超级智能助手,它不是一个单独的 AI,而是一个由多个专家 AI 组成的团队。
- 有做研究的专家
- 有写代码的专家
- 有分析数据的专家
- 有做决策的专家
这些专家 AI 会互相协作,完成从几分钟到几小时的复杂任务。这就是 DeerFlow(Deep Exploration and Efficient Research Flow)。
为什么需要 DeerFlow?
普通的 AI 助手有什么问题?
- 只能做简单任务,复杂任务容易出错
- 没有长期记忆,每次对话都是重新开始
- 不能和其他工具很好地协作
- 遇到需要执行代码的任务就卡住
DeerFlow 解决了这些问题:
- 子智能体协作:不同领域的专家 AI 一起工作
- 长期记忆:记住之前的对话和结果
- 沙箱环境:安全运行代码,不怕搞坏系统
- 扩展技能:可以通过技能插件扩展功能
核心功能
1. 技能和工具
DeerFlow 有一个可扩展的技能系统,就像给 AI 装插件一样。
- 内置了各种工具:搜索、代码执行、文件操作
- 可以自己开发新技能
- 技能之间可以互相调用
使用场景:
比如你想做市场调研,DeerFlow 可以:
- 使用搜索技能查找最新资料
- 使用文件操作技能保存结果
- 使用数据分析技能整理数据
- 使用报告生成技能输出最终结果
2. Claude Code 集成
DeerFlow 可以和 Claude Code 无缝集成,让 Claude 成为你的编程助手。
配置示例:
models:
- name: claude-sonnet-4.6
display_name: Claude Sonnet 4.6
use: deerflow.models.claude_provider:ClaudeChatModel
model: claude-sonnet-4-6
max_tokens: 4096
supports_thinking: true
使用场景:
当你需要写代码时,DeerFlow 会自动调用 Claude Code 来生成和执行代码,然后把结果整合到最终答案中。
3. 子智能体
DeerFlow 可以创建多个子智能体,每个负责不同的任务。
- 可以同时运行多个子智能体
- 子智能体之间可以通信和协作
- 可以根据任务类型自动选择合适的子智能体
使用场景:
比如做一个完整的项目:
- 产品经理智能体:分析需求
- 架构师智能体:设计系统架构
- 开发者智能体:编写代码
- 测试智能体:测试功能
4. 沙箱和文件系统
DeerFlow 有安全的沙箱环境,可以安全运行代码。
- 隔离的文件系统,不会影响你的电脑
- 可以在沙箱中安装依赖和运行程序
- 支持多种编程语言
使用场景:
当你需要测试一段陌生的代码时,不用怕它会搞坏你的系统,DeerFlow 会在沙箱里安全运行。
5. 上下文工程
DeerFlow 能智能管理上下文,让 AI 更好地理解你的需求。
- 自动提取和组织相关信息
- 动态调整上下文长度
- 确保重要信息不被遗忘
使用场景:
当你和 AI 进行长对话时,DeerFlow 会自动整理对话内容,确保 AI 不会忘记之前的重要信息。
6. 长期记忆
DeerFlow 有长期记忆系统,可以记住之前的对话和结果。
- 存储和检索历史信息
- 识别和关联相关内容
- 持续学习和改进
使用场景:
比如你正在做一个持续几周的项目,DeerFlow 会记住项目的所有细节,不需要你每次都重新介绍背景。
高级功能
沙箱模式
沙箱模式让你可以在安全的环境中运行代码:
# 启用沙箱模式
python -m deerflow --sandbox
使用场景:
当你需要运行不受信任的代码,或者测试可能有风险的操作时,沙箱模式能保护你的系统安全。
MCP 服务器
MCP(Message Control Protocol)服务器让 DeerFlow 可以和其他系统集成:
# 启动 MCP 服务器
python -m deerflow --mcp
使用场景:
当你需要把 DeerFlow 集成到现有的系统中,或者让多个 DeerFlow 实例互相通信时,MCP 服务器就派上用场了。
IM 渠道
DeerFlow 支持多种即时通讯渠道:
- Discord
- Slack
- Telegram
使用场景:
你可以在自己常用的聊天工具中与 DeerFlow 互动,不用打开专门的界面。
跟踪和监控
DeerFlow 支持两种跟踪系统:
- LangSmith Tracing
- Langfuse Tracing
使用场景:
当你需要监控 DeerFlow 的运行情况,或者调试复杂任务时,这些跟踪系统能帮你了解每一步的执行情况。
常见问题
Q: DeerFlow 需要什么配置的电脑?
A: 基本的开发电脑就可以,建议:
- 8GB 以上内存
- 20GB 以上磁盘空间
- Python 3.9+
Q: 运行 DeerFlow 需要多少钱?
A: DeerFlow 本身是免费开源的,但使用 AI 模型需要付费。你可以选择不同的模型,价格也不同。
Q: 我是 AI 新手,能学会用 DeerFlow 吗?
A: 完全可以!DeerFlow 的设计就是为了让复杂的 AI 任务变得简单。按照本教程的步骤,一步步来,很快就能上手。
Q: 可以用 DeerFlow 做什么?
A: 几乎什么都可以做:
- 市场调研和分析
- 代码开发和调试
- 内容创作和编辑
- 数据分析和可视化
- 学术研究和文献综述
快速开始
第一步:克隆仓库
打开终端,运行:
git clone https://github.com/bytedance/deer-flow.git
cd deer-flow
第二步:生成配置文件
在项目根目录运行:
make config
这个命令会根据模板创建本地配置文件。
第三步:配置模型
编辑 config.yaml 文件,添加至少一个模型:
models:
- name: gpt-4 # 内部标识
display_name: GPT-4 # 人类可读名称
use: langchain_openai:ChatOpenAI # LangChain 类路径
model: gpt-4 # API 模型标识
api_key: $OPENAI_API_KEY # API 密钥(推荐:使用环境变量)
max_tokens: 4096 # 每次请求的最大 token
temperature: 0.7 # 采样温度
推荐模型:
- Doubao-Seed-2.0-Code(字节跳动)
- DeepSeek v3.2
- Kimi 2.5
第四步:运行应用
有两种方式运行:
方式1:Docker(推荐)
docker-compose up -d
方式2:本地开发
# 安装依赖
pip install -e .
# 运行应用
python -m deerflow
最佳实践
1. 从小任务开始
刚开始使用 DeerFlow 时,先尝试一些简单的任务,比如:
- 搜索并整理一些信息
- 写一个简单的脚本
- 分析一个数据集
等熟悉了之后,再尝试更复杂的任务。
2. 合理配置模型
不同的任务适合不同的模型:
- 代码任务:Doubao-Seed-2.0-Code、DeepSeek v3.2
- 对话任务:Kimi 2.5、GPT-4
- 分析任务:Claude Sonnet 4.6
3. 利用子智能体
对于复杂任务,分解成多个子任务,让不同的子智能体来处理:
- 研究子智能体:收集信息
- 分析子智能体:整理数据
- 执行子智能体:完成具体任务
- 审查子智能体:检查结果
4. 定期保存结果
在处理长时间任务时,定期保存中间结果,防止意外中断导致工作丢失。
总结
DeerFlow 是一个强大的超级智能体框架,它让 AI 从单打独斗变成了团队协作。
核心优势:
- 子智能体协作,分工明确
- 长期记忆,持续学习
- 沙箱环境,安全可靠
- 扩展技能,功能丰富
适用场景:
- 复杂的研究和分析任务
- 代码开发和调试
- 内容创作和管理
- 数据分析和可视化
开始你的 DeerFlow 之旅吧!
关注引导
如果觉得这篇文章对你有帮助,随手点个赞、在看、转发三连吧~如果想第一时间收到推送,也可以给我个星标⭐。谢谢你看我的文章,我们下次再见。
