

昨天(3月31日)下午,Anthropic 在 npm 上推送了 @anthropic-ai/claude-code v2.1.88 版本,看起来和往常没有区别。两个半小时后,安全研究员 Chaofan Shou(@Fried_rice)在例行检查新包时发现了异常——包里多了一个 59.8MB 的 cli.js.map 文件,这个文件本不该出现在生产环境的 npm 包里。借助这份 Source Map,他成功还原了 1,900 多个源文件,共计 51.2 万行未经混淆的完整 TypeScript 代码,随即发布到 X 平台。消息迅速扩散,还原后的源码被归档到 GitHub,一小时内获得 1.1 万 Star 和 1.7 万 Fork。当晚 19:00,Anthropic 紧急下架问题版本,推送修复。但一切都晚了——代码已经被数以千计的开发者备份,永久留存在网上。
从发现到扩散,不到三个小时。
大家关注的是什么
这件事引发的第一波讨论,集中在拆架构上。
tool loop 的设计、permission 系统的实现、多 agent 协调的方式——这些话题在开发者社区里热了整整一天,不少深度文章在几个小时内就跑到了热榜前列。从工程视角来看,这份意外开源的代码确实提供了一个难得的观察窗口。
但在这些讨论之外,有一个问题被相对忽略,而它实际上更值得关注:
当 AI Agent 帮你操作电脑时,你的数据在哪里?
云端 Agent 的数据链路
这不是针对哪个具体产品,而是关于一类工具的结构性描述。
目前主流的 GUI Agent,基本都跑在云端。工作方式大致是:截取当前屏幕,把截图连同任务描述上传到云端服务器,云端模型完成推理,返回下一步操作指令,本地执行,再截图,如此循环。
这条链路意味着:你的屏幕内容,在每一次操作间隔都会离开本机。
对于普通任务,这通常不是问题。但如果 Agent 工作时屏幕上有客户数据、内部系统的界面、或者来不及关闭的敏感窗口——这条数据链路就需要被认真对待。
Claude Code 这次的意外提供了一个具体的参照:即便是被广泛认可为工程能力很强的团队,也会在某次常规版本发布中,因为一行配置的遗漏,把本不该暴露的东西推到公网上。工程系统越复杂,出错的可能性就越难被完全消除。
端侧运行,让数据边界变得可验证
Mano-P 在设计上选择了另一条路径。
在本地模式下,模型完整跑在你的 Mac 上。截图在本机生成,在本机完成推理,操作指令在本机产生,整个过程不经过任何外部服务器。
这一点可以被验证:断网状态下 Mano-P 正常运行,网络监控工具不会捕捉到截图上传的流量,代码完整开源,任何人都可以直接审计。
性能上,Mano-P 4B 量化模型(w4a16)在 M4 Pro 上的实测数据:prefill 476 tokens/s,decode 76 tokens/s,峰值内存占用 4.3GB。日常操作任务的响应速度,不比调用云端 API 慢。
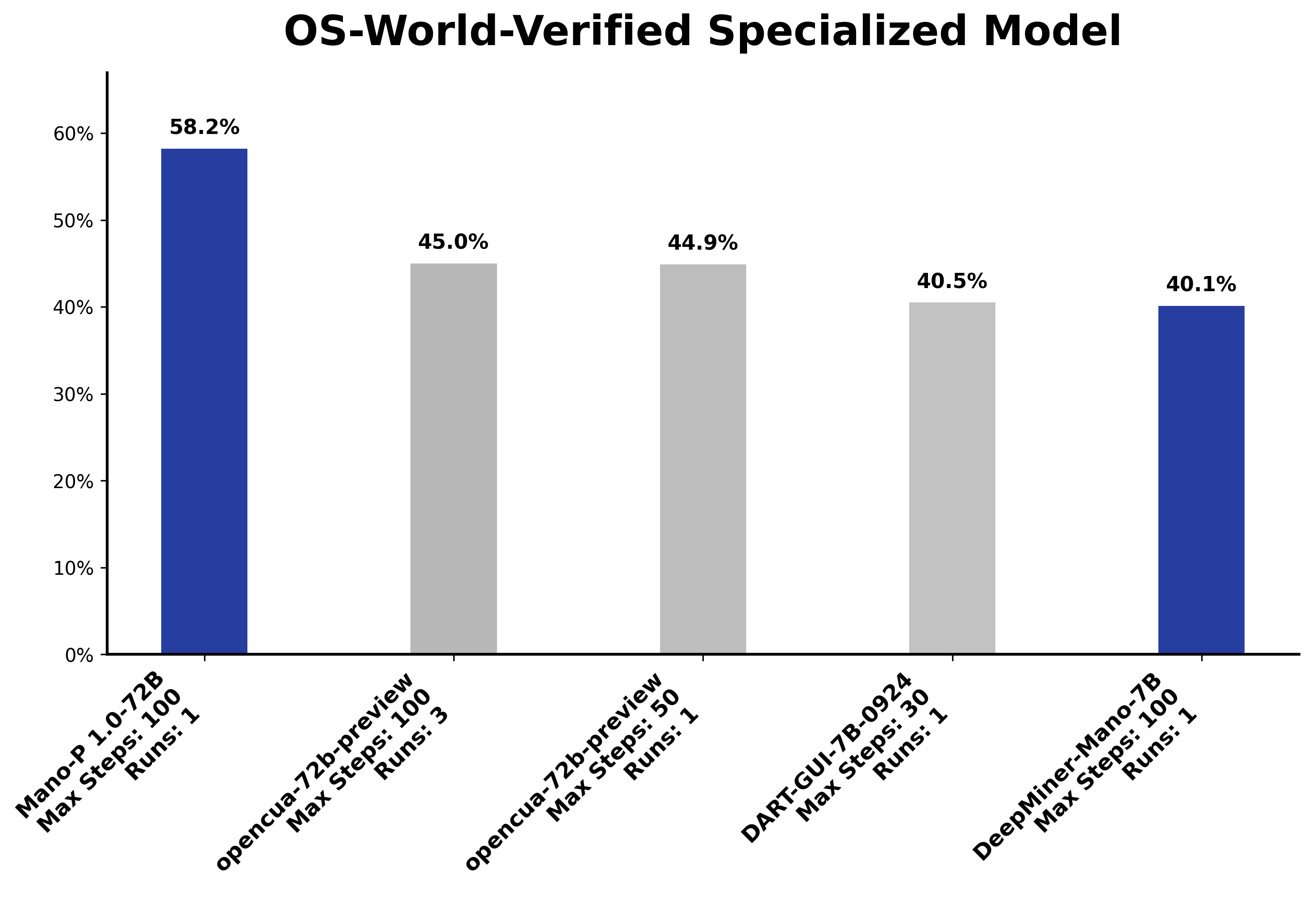
评测成绩上,Mano-P 在 OSWorld 专项拿到了开源第一,58.2%,比第二名高出 13.2 个百分点:
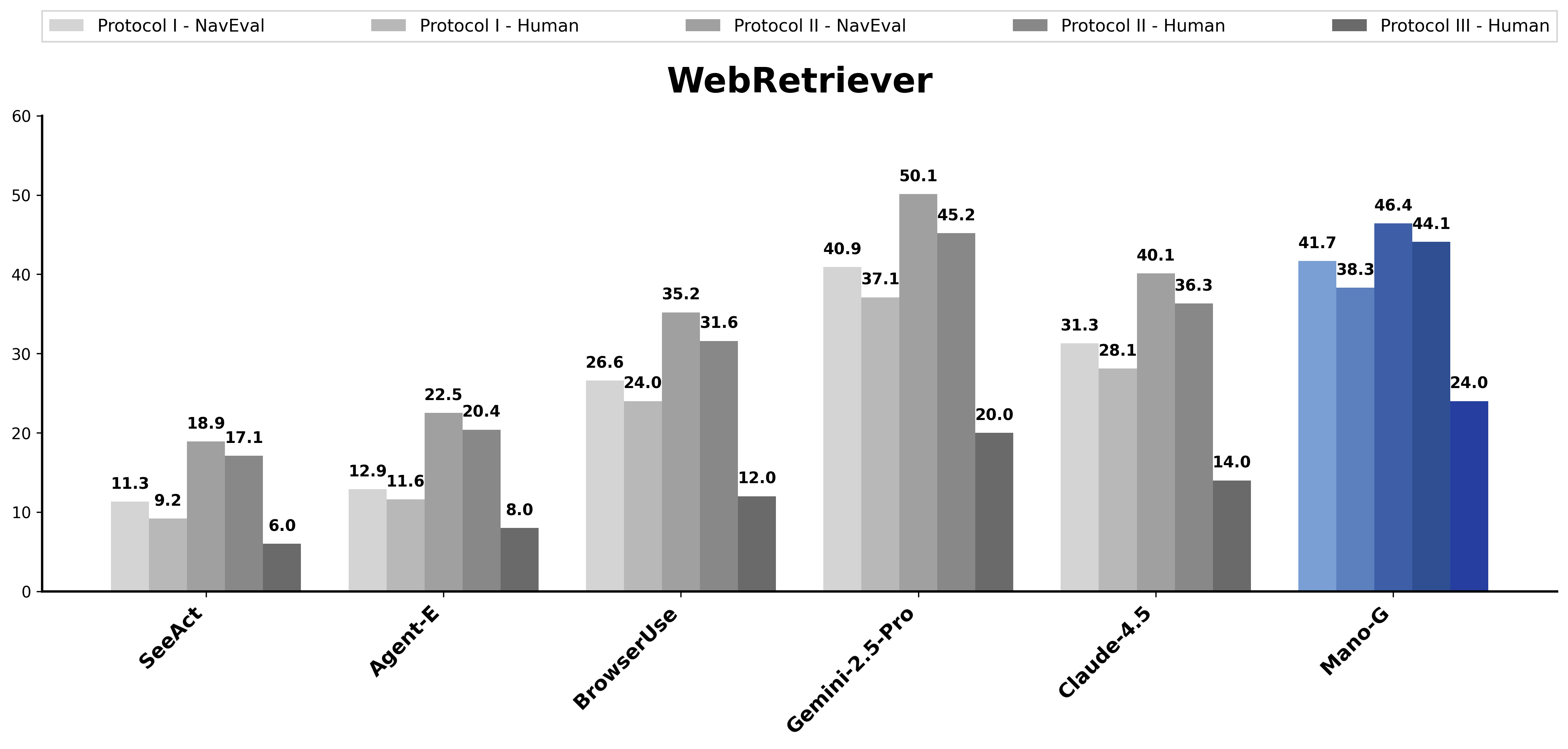
在 WebRetriever Protocol I 上,41.7 NavEval,超越 Gemini 2.5 Pro(40.9)和 Claude 4.5(31.3):
综合评测总览:
两种模式,两条数据边界
Mano-P 本身同时支持本地模式和云模式,两种模式的边界是显式声明的:
本地模式:截图和任务描述留在本机,不经过外部服务器,本地文件、剪贴板、系统凭证均不访问,代码开源可审计。需要 M4 Mac + 32GB RAM。
云模式:截图和任务描述发往 mano.mininglamp.com,适用于本地算力不满足要求的场景,本地文件、剪贴板、系统凭证同样不访问。
一个值得认真对待的问题
Claude Code 这次的意外在技术圈引发了很多讨论,多数集中在"源码里写了什么"上。这是自然的反应——源码就在那里,能读就读。
但这件事同时也提醒了一件事:在 AI Agent 越来越深度介入日常工作流的今天,它的数据流向是一个值得主动了解的信息,而不是默认接受的背景条件。
云端方案在算力、模型迭代速度上有明显优势;端侧方案在数据边界的确定性上有结构性的优势。两者面向的场景有所不同,适合不同的使用情境。
如果你有 M4 Mac,想试试完全本地运行的 GUI Agent:
brew tap HanningWang/tap && brew install mano-cua
或者在 Claude Code / OpenClaw 里直接装 Skill:
clawhub install mano-cua
