

Anthropic 的工程博客,有一篇文章聊"怎么让 AI Agent 长时间干活"。
看完之后我就去找了找有没有现成的工具能直接用。结果还真找到了——一个叫 Ralph 的开源项目。
今天就把 Anthropic 的思路和 Ralph 这个工具一起聊聊,顺便教大家怎么用起来。
问题:Agent 干着干着就"失忆"了
如果你用过 Claude Code、Cursor 之类的 AI 编程工具做过稍微大一点的项目,应该有体会。
刚开始写代码的时候,Agent 思路清晰,代码质量也不错。但写到后面,你会发现它开始忘事了——明明提示词里写了要做暗黑模式,做着做着就没影了。
这不是模型变笨了,是上下文窗口满了。
上下文窗口就那么大,任务一复杂,前面的对话内容就会被压缩或者丢掉。
Anthropic 官方也承认了这个问题。他们在博客里说,哪怕用最强的 Opus 模型,在单个上下文窗口里做一个复杂的 Web 应用,结果也是一塌糊涂。
失败模式有两种:
**一是贪多嚼不烂。**
Agent 试图一口气把所有功能都实现,代码写到一半上下文就爆了,留下一堆半成品。下一个上下文窗口的 Agent 得猜上一个做了什么,猜错了就更乱。
**二是摸鱼式完工。**
跑了一会儿之后,Agent 看了看已有的代码,觉得"嗯差不多了",然后直接宣布项目完成。。。哥们这才做了 30% 好吧。
Anthropic 的解法:两个 Agent 接力跑
Anthropic 的工程团队想了个办法,模仿人类团队交接班的流程。
**第一棒:初始化 Agent。**
这个 Agent 只在项目开始时跑一次,做三件事:
- 搭好项目骨架,写一个 init.sh 脚本,把环境配好
- 生成一个进度文件 claude-progress.txt,后面所有 Agent 都往里写日志
- 把需求拆成一个超详细的功能列表
功能列表这个东西是关键。不是那种"实现用户登录"这种笼统的描述,而是细到"用户点击新建聊天按钮,创建一个新对话,聊天区域显示欢迎状态,对话出现在侧边栏"这种级别。
Anthropic 做 claude.ai 克隆的时候,这个列表有超过 200 个功能。每个功能一开始都标记为 "passes": false,这样后面的 Agent 就知道还有多少活没干完——不会出现"以为做完了"的情况。
这些功能列表用 JSON 格式存储,不是 Markdown。因为 Anthropic 发现模型更不容易乱改 JSON 文件。Markdown 的话,Agent 动不动就重写一段,容易把别人的记录覆盖掉。
**第二棒:编码 Agent,一次只做一件事。**
编码 Agent 每次启动,先做几个固定动作:
代码块1. pwd —— 确认自己在哪个目录2. 读 git log 和进度文件 —— 了解前面做了什么3. 读功能列表 —— 找到下一个该做的功能4. 跑一遍基础测试 —— 确认现有功能没挂5. 开始实现新功能6. 做完了写 git commit + 更新进度文件
每个编码 Agent 只做一个功能。做完就走,留下清晰的记录。下一个 Agent 来了,先看记录,再接着干。
这样就不会出现"做到一半上下文爆了"的问题——因为一个功能足够小,一个上下文窗口就能搞定。
Anthropic 特别强调了测试。他们发现 Agent 特别容易"改完代码就说做好了",但实际上根本没测过。加了浏览器自动化测试之后(用 Puppeteer),Agent 能像真人一样打开页面点点点,效果提升了很多。
Ralph:把这套理论变成了一个工具
理论听着不错,但谁来帮你搭这套流程呢?
Ralph 就是干这个的。
它本质上是一个 Bash 脚本集合,帮你把 Claude Code 包在一个自动循环里——Agent 干完一轮活,Ralph 自动启动下一轮,直到所有任务完成。
安装
先把 Ralph 装上,一条命令的事:
代码块git clone github.com/frankbria/r… ralph-claude-code./install.sh
装完之后 ralph、ralph-monitor、ralph-setup 这些命令就全局可用了。装一次就行。
三种方式启动项目
**方式一:在现有项目上启用 Ralph(推荐)**
你已经有一个项目了,想让 Ralph 接管:
代码块cd my-existing-projectralph-enable
它会弹出一个交互式向导,帮你检测项目类型(TypeScript、Python、Go 之类的),问你任务从哪儿来,然后自动生成配置文件。
方式二:导入已有的需求文档
手头有个 PRD 或者需求文档?直接喂给它:
代码块ralph-import my-requirements.md my-projectcd my-project
Ralph 会用 Claude Code 把你的需求文档拆成任务列表,生成 .ralph/PROMPT.md(主指令)和 .ralph/fix_plan.md(任务优先级)。
方式三:从零开始
代码块ralph-setup my-awesome-projectcd my-awesome-project
然后手动编辑 .ralph/PROMPT.md 写你的需求。
跑起来
代码块ralph --monitor
加 --monitor 会启动一个 tmux 看板,实时显示当前循环到第几轮、API 调用量、最近的日志。
想看 Agent 实时输出的话:
代码块
Ralph 的几个亮点
用了一圈下来,有几个设计我觉得挺聪明的。
双条件退出机制
这是 Ralph 最核心的设计之一——怎么判断"活干完了"?
很多人的做法是看 Agent 的输出有没有"任务完成"之类的字眼。但这太容易误判了,Agent 说"这个阶段完成了"不代表整个项目完成了。
Ralph 的方案是双条件检查:
-
语义检测:从 Agent 的输出里提取完成信号(completion_indicators >= 2)
-
显式确认:Agent 必须在输出里明确写 EXIT_SIGNAL: true
两个条件都满足才退出。如果 Agent 说"阶段完成"但 EXIT_SIGNAL: false,Ralph 就继续跑——因为 Agent 自己说还有活没干。
熔断器
跑着跑着 Agent 卡住了咋办?连续 3 轮没有任何文件变更,或者连续 5 轮报一样的错误,Ralph 的熔断器就会跳闸,暂停循环。
等冷却 30 分钟之后自动恢复。这样不会浪费 API 额度在无效循环上。
会话管理
Ralph 会在循环之间保持会话上下文。也就是说下一轮的 Agent 能看到上一轮的对话记录,不是完全从零开始的。
当然如果熔断器跳了,或者你手动中断了,会话会自动重置——这很合理,因为上下文可能已经被污染了。
项目文件结构
Ralph 创建的文件结构长这样:
代码块my-project/├── .ralph/ # Ralph 的配置和状态│ ├── PROMPT.md # 主要开发指令│ ├── fix_plan.md # 优先级任务列表│ ├── AGENT.md # 构建和运行命令│ ├── specs/ # 详细需求规格
几个关键文件的关系是:
代码块PROMPT.md(高层目标) ↓specs/(需要细化时放详细需求) ↓fix_plan.md(具体任务,Ralph 按顺序执行) ↓AGENT.md(构建/测试命令,自动维护)
简单项目只需要 PROMPT.md + fix_plan.md 就够了。复杂项目再往 specs/ 里加详细说明。
配置文件怎么写
.ralphrc 是项目级配置,能调的东西不少:
代码块# 项目基本信息PROJECT_NAME="my-project"PROJECT_TYPE="typescript"# 循环参数MAX_CALLS_PER_HOUR=100 # 每小时最多调多少次 APICLAUDE_TIMEOUT_MINUTES=15 # 每轮超时时间CLAUDE_OUTPUT_FORMAT="json" # 输出格式# 工具权限——Agent 能用哪些工具ALLOWED_TOOLS="Write,Read,Edit,Bash(git *),Bash(npm *),Bash(pytest)"
如果 Claude Code 因为权限问题被拦了,改 ALLOWED_TOOLS 加上对应工具就行。
官方插件:Ralph Loop
除了开源项目,Anthropic 自己也在 Claude Code 的插件市场里上了一个官方版本,叫 Ralph Loop。
安装量 8.9 万,Anthropic 官方认证。
用法比开源版简单:
代码块/ralph-loop "你的提示词" --max-iterations 10 --completion-promise "DONE"
它会在 Claude Code 里开一个循环,每次 Agent 退出时自动重新喂入提示词,同时保留所有文件修改和 Git 历史。直到 Agent 输出你设定的完成标记(比如 "DONE"),或者达到最大迭代次数。
想停的话用 /cancel-ralph。
相比开源的 Ralph,官方插件更轻量,适合快速上手。但功能没有开源版那么多——没有熔断器、没有 tmux 看板、没有任务导入这些。
Codex 如何进行长任务
核心理念:持久的项目记忆
最重要的技巧是建立持久的项目记忆。用 Markdown 文件记录了 spec、plan、约束条件和项目状态,Codex 可以反复查阅这些文件。这避免了项目偏离主题,并保持了“完成”定义的稳定性。
参考代码库 :github.com/derrickchoi…
prompt.md (提示词)
文件关键部分:
- 项目目标
- 硬性限制(技术栈)
- 交付结果
- 完成条件
- 流程要求(先做计划)
plan.md (计划)
文件关键部分:
- 里程碑足够小,可以在一个循环中完成
- 每个里程碑的验收标准 + 验证命令
- 代码库的预期架构
- 避免波动的决策说明
implement.md(操作手册)
文件关键部分:
- plan.md 是权威来源
- 每个里程碑完成后运行验证
- 持续更新 markdown 文档
documentation.md (状态)
文件关键部分:
- 当前里程碑状态
- 已经做出的决定以及原因
- 如何运行演示
- 后续问题行动
Kiro 如何进行长任务
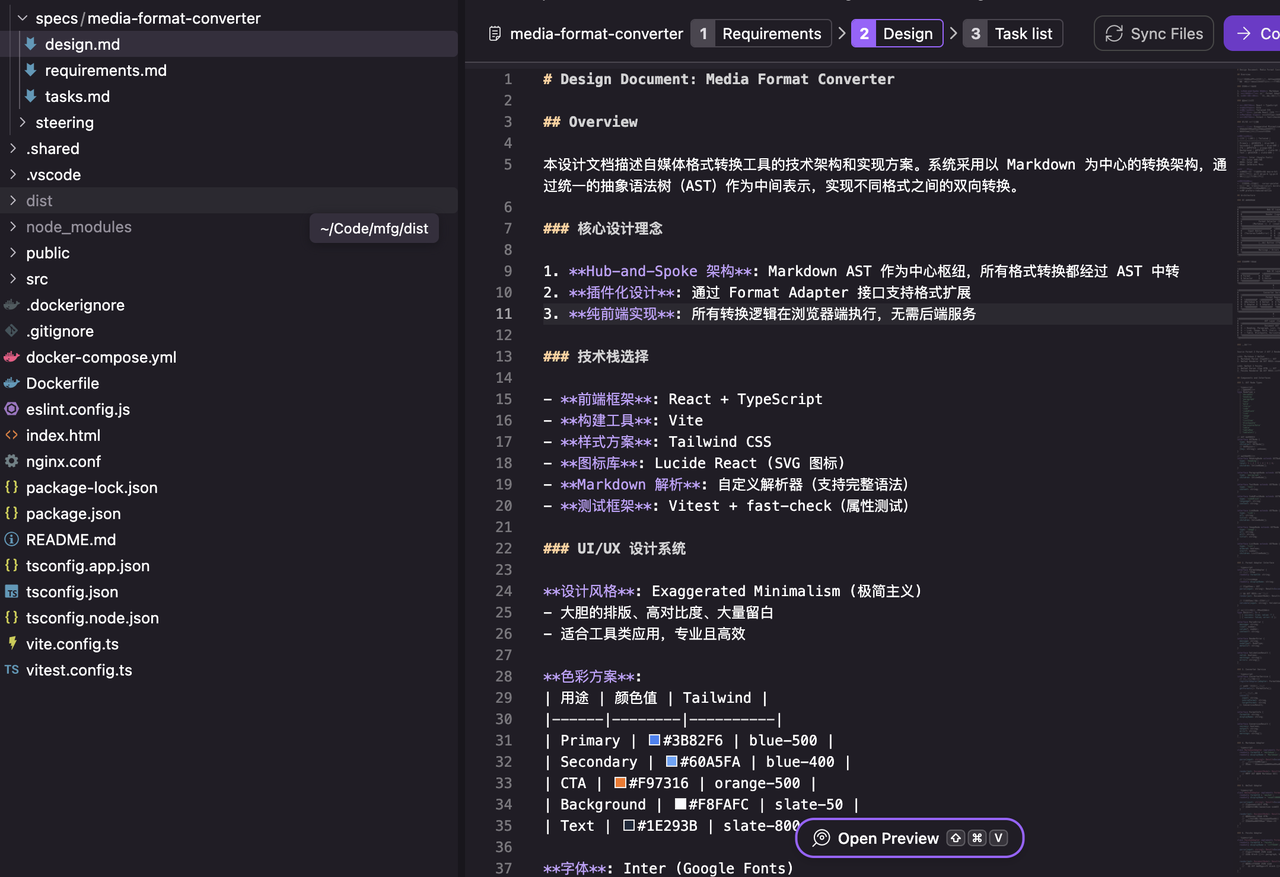
design.md
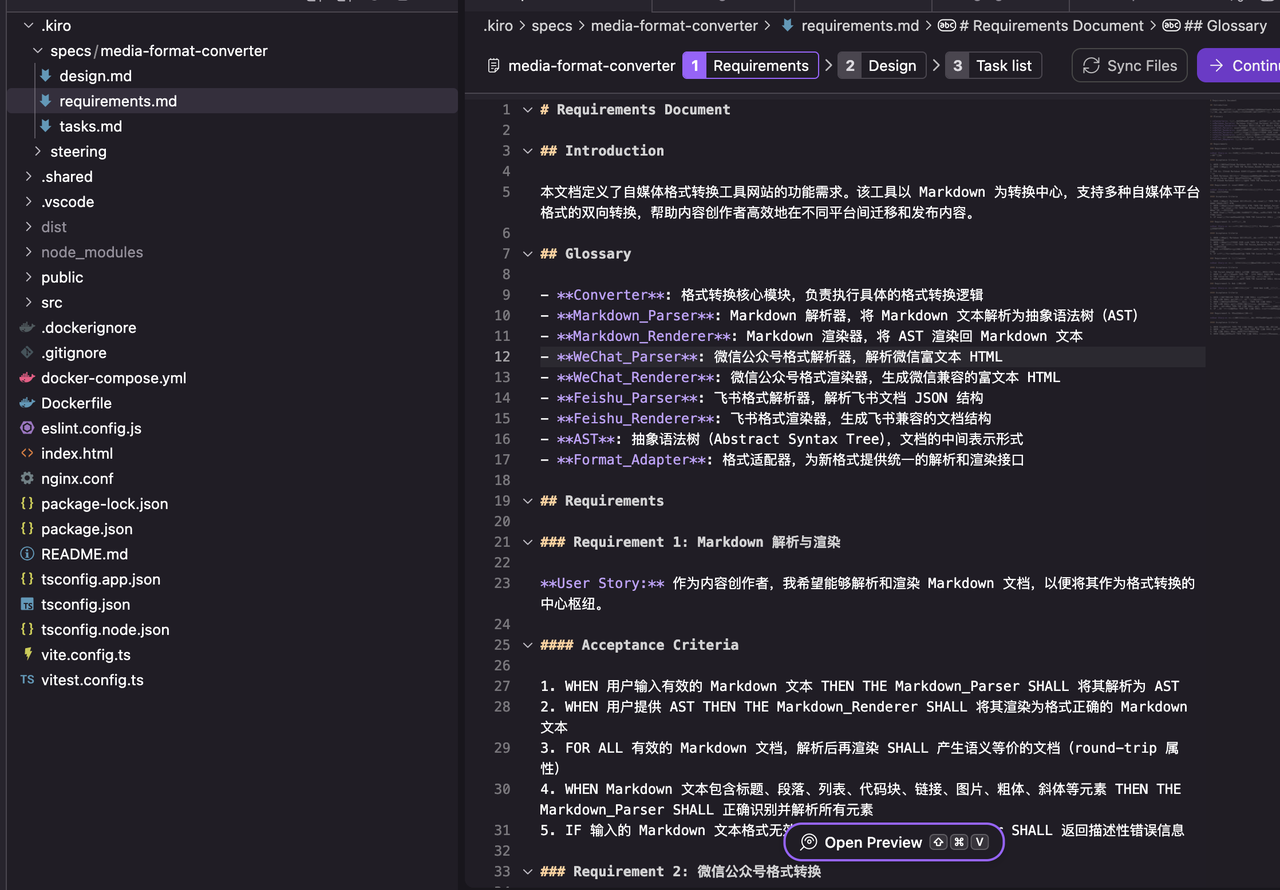
requirements.md
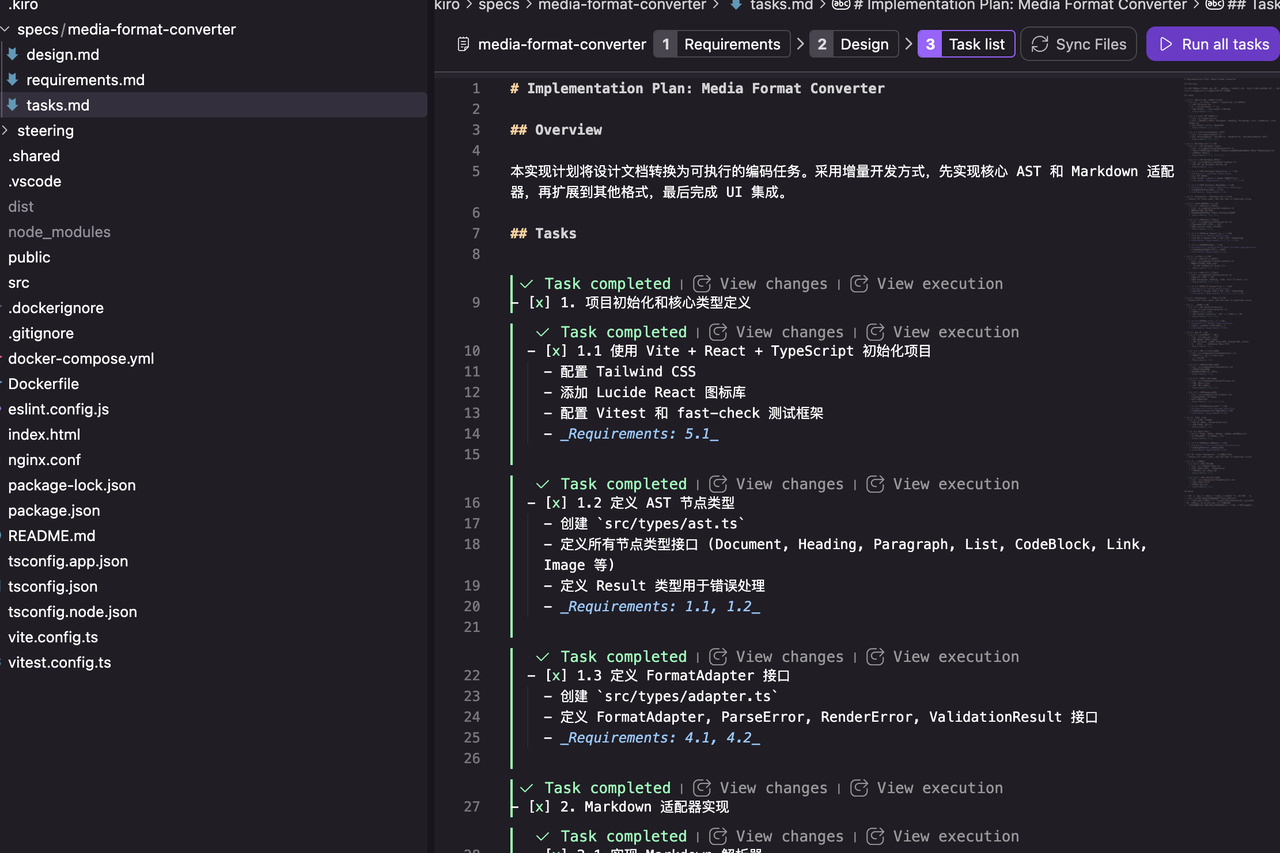
tasks.md
实战一个 long-running-system
提示词

› 我想做一个 skill, 这个 skill 用来帮助项目进行长任务开发,主要思路是 1.新项目自动生成 AGENTS.md ,如果是老项目,添加一段使用这个 skill 的描述 ,在 AGENTS.md 中要提到使用这个技能及相关说明 2.这个 skill 主要思想是用一文件夹来保存一次长任务所需要的 markdown 文件集合,主要是 prompt.md , plan.md ,implement.md , documentation.md ,参考 developers.openai.com/blog/run-lo… ,你可以参考@design-desk-main , 然后我觉得 4 个文件是不是有点多,你还可以参考下 claude 的做法 www.anthropic.com/research/lo… ,www.anthropic.com/engineering…,对了,你要用这套方法论来完成当前项目
在 AGENTS.md 中应该显示指定当前在哪个长任务运行文件夹,因为每次一个长任务呢,就是一个单独的文件夹,它是有一个全局标记,标记这个长任务完成了。那如果说我要开启下一个日常任务的时候,我是另一个文件夹,同时要把 AGENTS.md当中的指向指到新的文件夹,然后新的文件夹呢。他是能够先阅读上一个文件夹长任务大概做了什么以上是我对于咱们这个skill的新的想法和功能,我不知道你有没有理解。如果说你不理解的话,你再问我有不理解的地方。
你会有loop机制来控制当前任务最低的循环次数或者执行时间吗?我之前看到的一篇文章,我发给你啊,这个是你的竞争对手Claude已经实现的功能,我希望在这个skill里面你能够支持。这样的说话,我不会出现说我新开一个任务,我执行了两分钟就结束了,用户应该设定至少这个任务执行15分钟这种类似的需求我现在呢,把我看到的文章发你啊,你也可以去网上搜索一下,怎么样更好的,更轻量地实现这个功能,融入到我们的skill当中www.verdent.ai/guides/clau…
当用户明确说要你运行长任务的时候,你要头脑风暴一下,问用户具体的一些功能需求确定的,然后呢,生成至少10个子任务,每个子任务呢,要有明确的执行判断完成的要求
代码仓库
欢迎大家参与共建 github.com/mouuii/long…
测试效果
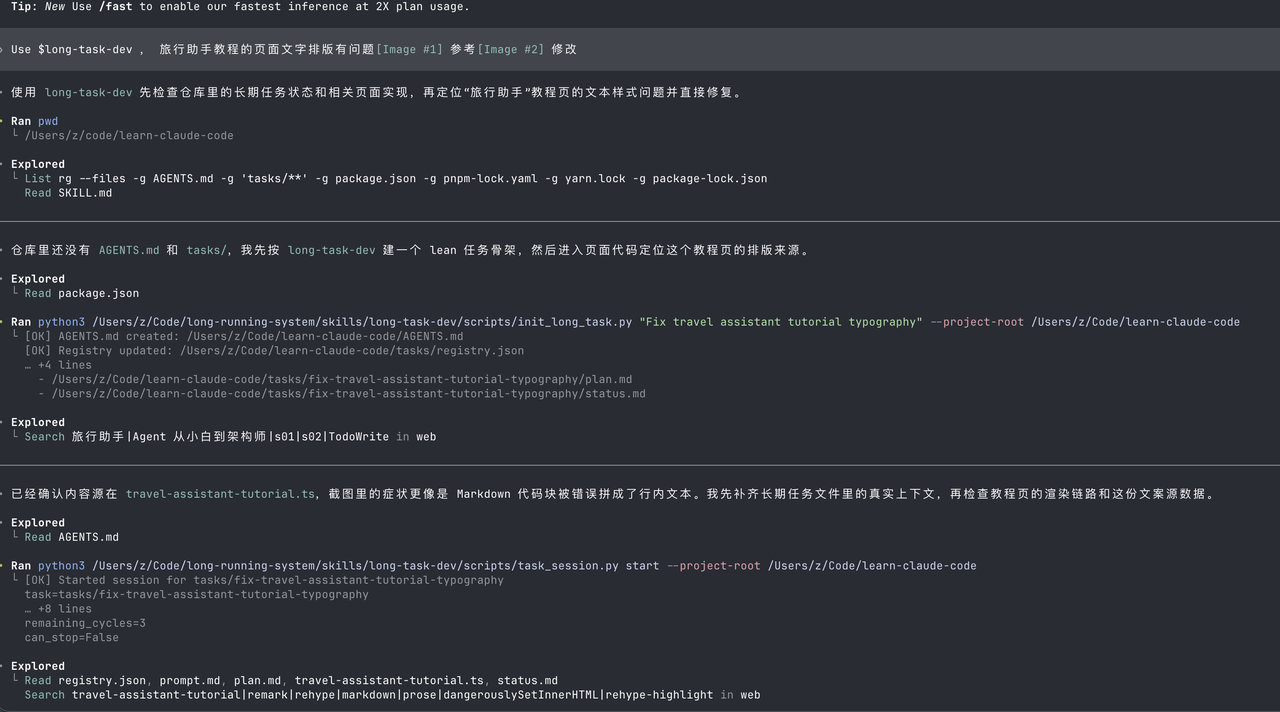
之前我不是写了个开源 Agent 教程网站吗,但是排版有点问题:learn.kubecit.com/
于是我和 codex 这样说:
改的不错,花了几分钟,这个任务太简单了
让他做个大改动
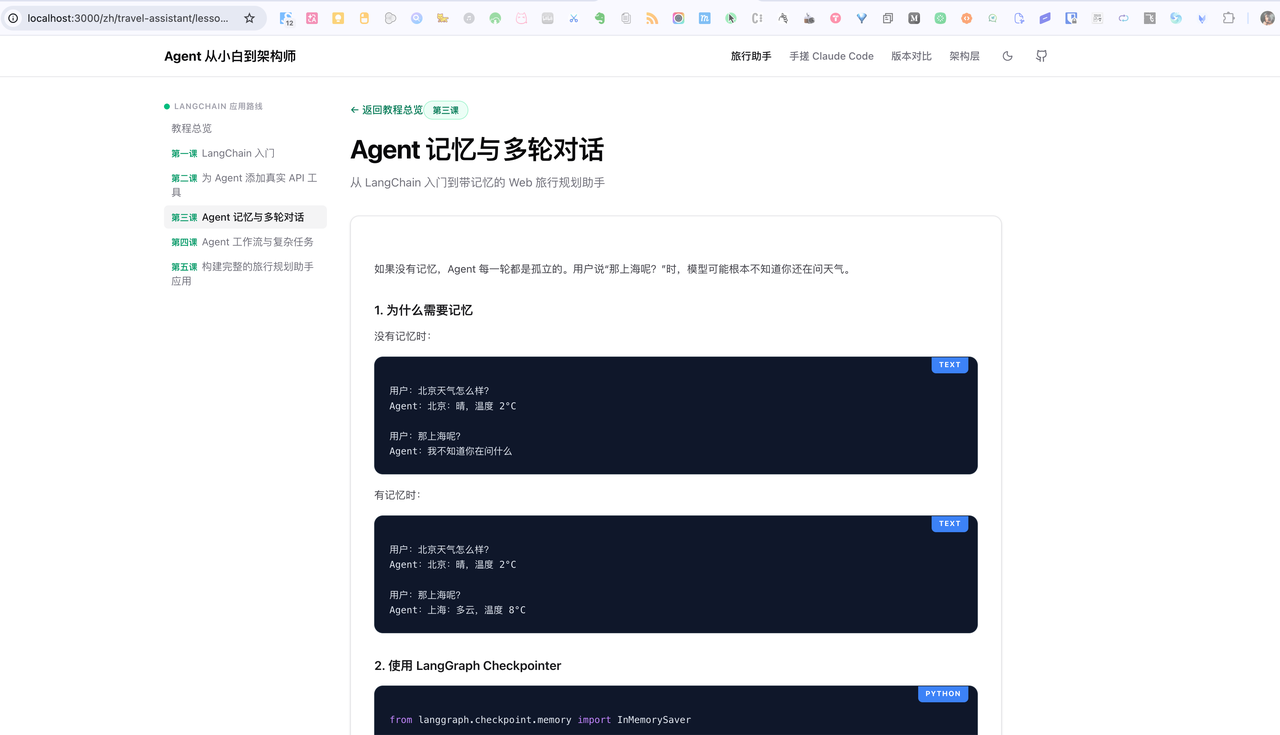
手搓的我觉得维护成本太高了,给我删除吧都,[Image #1] [Image #2] [Image #3] ,另外手搓cloud code的左侧呢,是教程的列表,但是旅行助手你的页面格式跟手搓cloud code的不太一样,能不能把这个风格弄得一样?另外呢,我觉得主页当中的对于手搓cloud code的描述太多了。比如说这个核心模式,比如说这个消息增长比如说这个架构层次,你要记住,你现在的主业是有很多个系列教程的组成"
然后 codex 干了半个小时,改的还算满意:
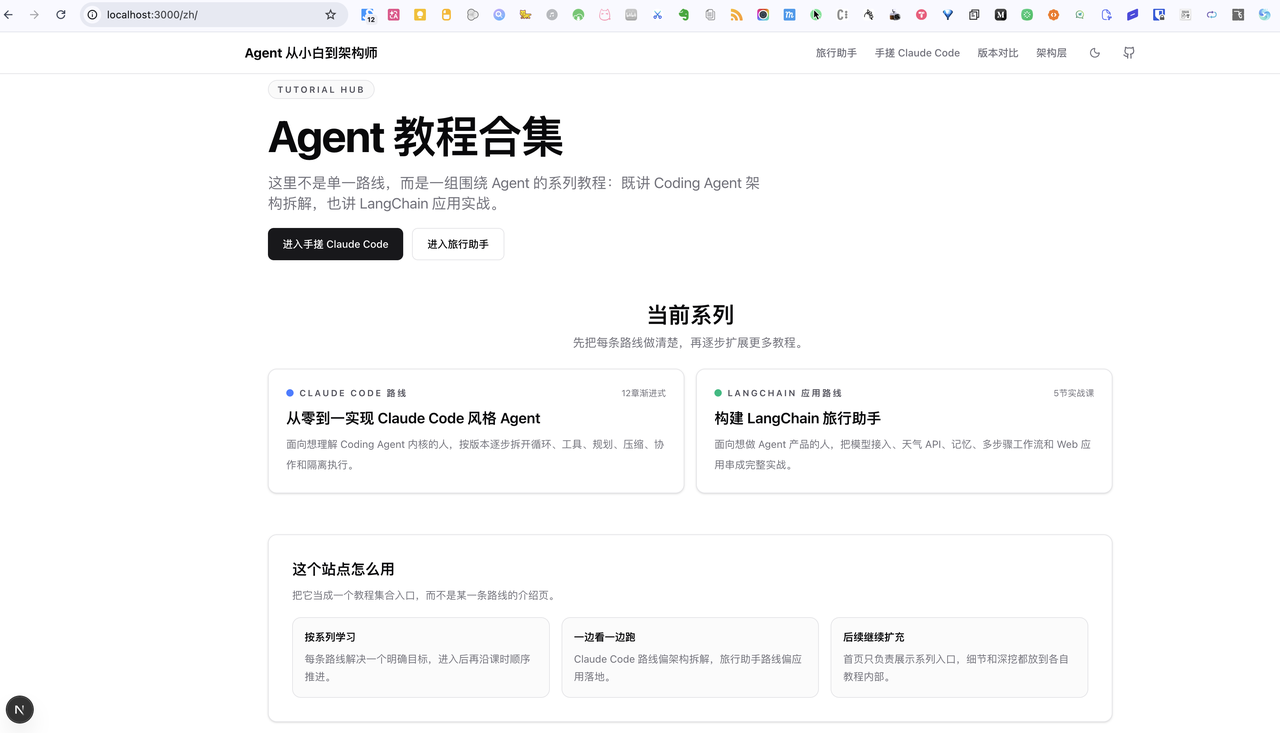
也使用了技能:
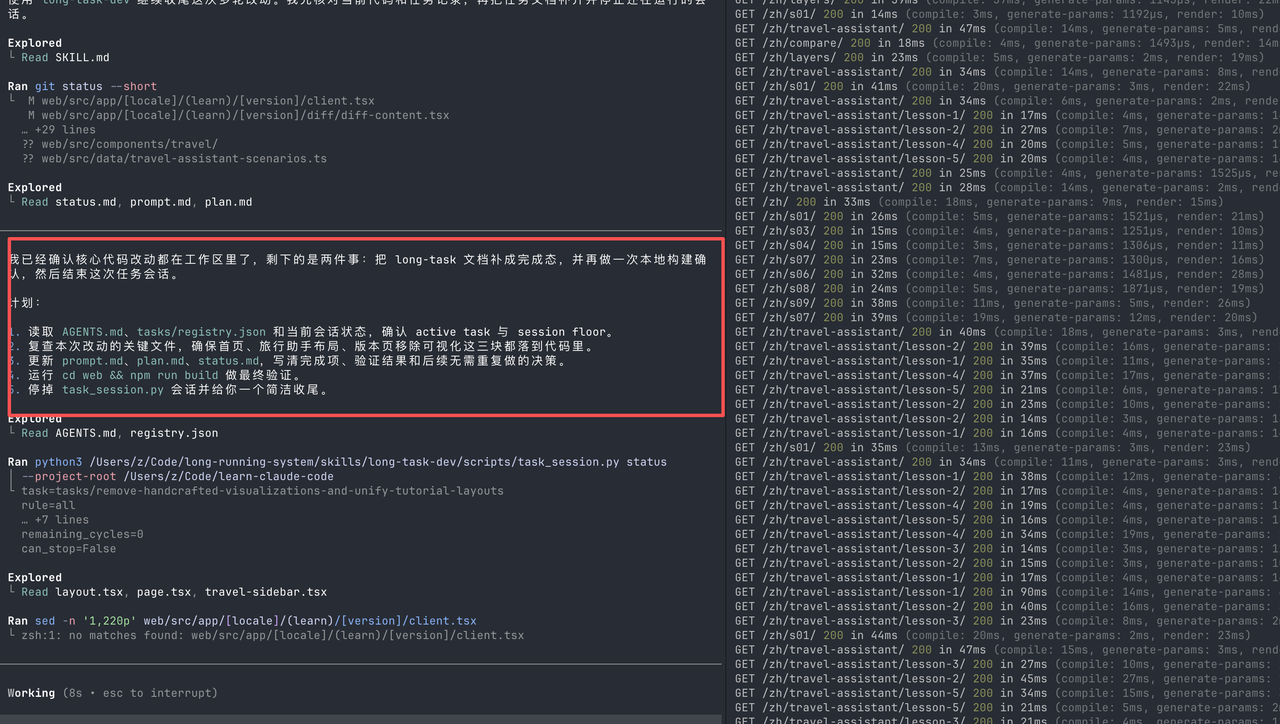
加载中...
