

一、背景介绍
在Flink实时计算的生产环境中,最令人头疼的往往不是复杂的业务逻辑,而是那些突如其来的“超时异常”。这些异常就像是系统中的“幽灵”,通常在业务高峰期或网络抖动时出现,导致作业重启、数据延迟甚至数据丢失。
最近几个月我们也遇到了好几起超时导致的作业异常案例,今天将结合近几年Flink相关生产实践,梳理Flink作业常见超时异常场景,详解核心超时参数含义,并给出对应的调优实践参考,为后续规避同类生产风险。
二、Flink作业常见超时异常场景
Flink作业实时运行涉及集群通信、状态持久化、消息收发、外部交互等多个环节,任一环节超时参数配置不合理,都会触发连锁异常,引发生产故障。往期有一篇HBaseSink超时排障的文章讲解了Flink与HBase交互的Hbase-connector参数配置不当引起的写入超时问题,今天我们主要聚焦在Flink与Kafka的超时异常场景
1.Kafka 消费者心跳超时 (Heartbeat Timeout)
- 现象:作业运行一段时间后,TaskManager 报错 "Consumer client timed out while receiving records from the broker"或 "LeaveGroup"异常,导致作业重启或部分 Source SubTask 无法消费数据。
- 根因:在处理大流量或高延迟的复杂算子(如大窗口聚合)时,TaskManager 处理一条 Record 的时间超过了 Kafka Consumer 与 Broker 之间的心跳维持时间,导致 Consumer 被踢出消费组。
2.网络与背压导致的 RPC 超时
- 现象:JobManager 与 TaskManager 断开连接,日志中出现 "Ask timeout"或 "Rpc connection timeout"。
- 根因:背压严重时,TaskManager 无法响应 JobManager 的探活请求(如 Heartbeat),导致 JobManager 判定 TaskManager 失联,触发 Failover。
3.Checkpoint 超时导致失败 (Checkpoint Expiration)
- 现象:Checkpoint 长时间处于 IN_PROGRESS状态,最终因 Checkpoint expired before completing失败。
- 根因:Barrier 对齐时间过长(通常由背压或数据倾斜引起),超出了 execution.checkpointing.timeout的限制,导致 Checkpoint 被丢弃,多次失败后作业重启。
三、Flink/Kafka常用超时参数详解
以下Flink参数选取1.16版本,Kafka参数选取2.8版本。
1.Flink核心框架超时参数
| 参数键 | 默认值 | 参数含义 |
|---|---|---|
| akka.tcp.timeout | 20s | JobManager与TaskManager之间tcp链接超时时间,超时则连接失败。 |
| akka.ask.timeout | 10s | JobManager与TaskManager之间RPC请求超时时间,超时则判定RPC调用失败。 |
| heartbeat.timeout | 50s | TM心跳超时时间,超时未收到心跳则标记TM失效。 |
| execution.checkpointing.timeout | 10min | 单次Checkpoint超时时间,超时则取消本次快照。 |
| execution.checkpointing.aligned-checkpoint-timeout | 0 | Barrier对齐超时时间。必须开启非对齐checkpoint,如果 Barrier 对齐耗时超过此阈值,会尝试将阻塞对齐切换为非对齐 Checkpoint。 |
| high-availability.zookeeper.client.connection-timeout | 15s | 基于zk做jm高可用,client连接zk的超时时间,超时则连接失败。 |
| high-availability.zookeeper.client.session-timeout | 60s | 基于zk做jm高可用,client与zk的会话超时时间,超时则连接断开。 |
2.Flink-Kafka超时参数
| 参数键 | 默认值 | 参数含义 |
|---|---|---|
| scan.topic-partition-discovery.interval | none | Kafka分区动态发现超时间隔,适配分区扩容场景,默认不开启。 |
| properties.request.timeout.ms | 30000ms | Kafka客户端请求超时时间,超时则请求失败。 |
| properties.session.timeout.ms | 10000ms | 消费者会话超时时间,超时触发组重平衡。 |
| properties.heartbeat.interval.ms | 3000ms | 心跳间隔。官方建议设置为 session.timeout.ms的 1/3,以确保及时发现连接问题 。 |
| properties.fetch.max.wait.ms | 500ms | 消息拉取最大等待时间,无消息时阻塞时长。 |
| properties.max.poll.interval.ms | 300000ms | 核心参数。两次 poll()调用的最大间隔。如果 Flink 处理一条消息的时间超过此值,Consumer 会认为该 Consumer 活锁,主动离开 Group。 |
| properties.max.poll.records | 500 | 一次poll()最大拉取条数。 |
| properties.delivery.timeout.ms | 120000 | 发送超时。记录从发送到收到确认(或失败)的总时间上限。 |
| properties.linger.ms | 0 | 发送批次数据等待延迟,0代表来一条发一条。 |
| properties.batch.size | 16384 | 发送批次数据大小,提升吞吐量。 |
3.超时参数关联示意图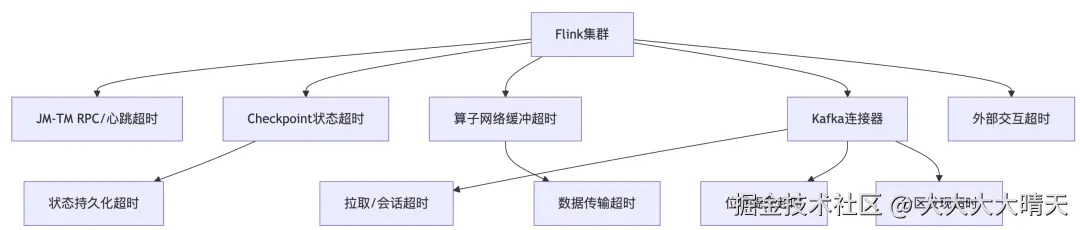
四、超时参数调优推荐与实践
在实际生产调优中,不能孤立地调整一个参数,而需要结合业务逻辑、资源和运维稳定性进行“组合拳”式的配置。一般参考以下原则:
- 贴合业务场景:低延迟业务、高吞吐业务、大状态业务的超时配置完全不同,禁止一刀切使用默认值。
- 兼顾容错与效率:超时时间不宜过短,避免误判故障;也不宜过长,避免故障发现延迟导致雪崩。
- 参数联动适配:上下游超时参数需匹配,如Kafka会话超时需小于Checkpoint超时,避免重平衡干扰快照。
- 预留容错空间:集群负载波动、网络抖动时,超时时间需预留缓冲余量。
1.解决 Kafka 消费组频繁 Rebalance (场景:大状态/慢节点)
在 Flink 消费 Kafka 时,如果算子逻辑较重(如涉及大量状态读写),处理单条记录可能耗时几十秒。默认的max.poll.interval.ms可能无法完成数据处理,Consumer Client 停止调用 poll(),触发“活锁”检测,Consumer 主动离组。
此场景下推荐配置如下:
max.poll.interval.ms = 600000 # 10分钟 (依据业务最大处理延迟)
session.timeout.ms = 60000 # 1分钟
heartbeat.interval.ms = 20000 # session.timeout 的 1/3 左右
request.timeout.ms = 120000 # 2分钟
或者调小单次poll()的等待时间/记录数,降低超时概率。
2.解决Checkpoint 超时或RPC超时
在流式计算中,背压往往伴随着 Checkpoint Barrier 对齐缓慢,导致 Checkpoint 超时,严重情况下还会触发RPC超时。默认的Checkpoint与RPC参数可能在高负载与背压场景下无法满足,容易引发超时重试,甚至重启乃至崩溃。
此场景下推荐配置如下:
execution.checkpointing.timeout = 900000
akka.ask.timeout = 30
sheartbeat.timeout = 70000
另外,还可以开启非对齐Checkpoint,减少背压对Checkpoint的影响,但是要接受非对齐Checkpoint无法保障exactly-once带来的不一致性。如果是因为状态过大,还需要对状态结构或大小进行优化,如设置TTL等。
3.通用生产稳定场景实践
适配绝大多数实时数仓、实时报表、常规数据清洗作业,兼顾稳定性和时效性。
- akka.ask.timeout:20s(默认10s过短,集群高负载时RPC易超时)
- heartbeat.timeout:60s(默认50s,网络波动时避免TM误判失联)
- execution.checkpointing.timeout:15min(默认10min,适配中等状态作业)
- Kafka session.timeout.ms:30000ms,heartbeat.interval.ms:10000ms(遵循心跳间隔为会话超时1/3的官方建议)
- Kafka request.timeout.ms:60000ms(避免大消息拉取超时)
4.低延迟实时场景实践
适配对延迟敏感、状态量小的作业,核心追求低延迟。
- execution.checkpointing.timeout:5min(小状态快照快,缩短超时快速失败重试)
- Kafka fetch.max.wait.ms:100ms(减少拉取等待,加快消息消费)
- heartbeat.timeout:30s(缩短心跳超时,快速感知节点故障)
5.超时参数调优流程
避坑要点:
- Checkpoint超时时间必须大于Checkpoint间隔,避免快照未完成就触发下一次快照。
- Kafka max.poll.interval.ms必须大于业务处理最大耗时,防止消费超时重平衡。
- RPC超时、心跳超时不宜设置过长,否则会导致故障发现延迟,扩大故障影响。
- 作业级参数优先级高于集群全局配置,核心作业建议单独配置,不依赖集群默认值。
五、总结展望
Flink 作业的超时配置本质上是在 “故障检测的灵敏度”与 “系统容错能力”之间做平衡,调优的核心是:找准异常场景、吃透参数含义、贴合业务选型、联动调优验证,兼顾实时作业的延迟、吞吐和容错能力。
随着Flink社区的迭代,自适应调优、智能运维成为发展趋势。未来Flink将逐步实现超时参数的自适应配置,基于作业运行状态、集群负载、数据量自动调整超时阈值,减少人工调参成本;同时,结合可观测性平台,实现超时异常的提前预警、根因自动定位,进一步提升实时作业的稳定性。
