

Anthropic 工程团队刚发了一篇深度技术博客,讲他们怎么用「多智能体套件」把 Claude 的能力往上推——从前端设计到连续跑几小时的自主编码。核心思路是从 GAN 借来的:让一个 agent 干活,另一个 agent 负责批评,两个来回打磨,最后出来的东西比单跑好很多。
问题从哪里来
Anthropic Labs 团队成员 Prithvi Rajasekaran 在博客里坦率地说:他之前做的前端设计 skill 和长跑编码 harness,通过提示词工程已经把 Claude 的表现提升到远超基线,但最终都遇到了天花板。
两个核心问题卡住了他:
一是上下文焦虑(context anxiety)。模型跑长任务时,随着上下文窗口被填满,会开始"预感"自己快到限制了,然后提前收尾,把工作草草了事。这不是假想,他在 Claude Sonnet 4.5 上观察得相当明显。解决方案是「上下文重置」——干完一段就清空窗口,通过结构化的交接文件把状态传给下一个 agent,给它一个干净的起点。
二是自我评估失真。让模型评价自己刚写的代码或设计,它会信心满满地说好——哪怕你看一眼就知道很烂。对主观性任务(比如设计美不美)这个问题尤其严重,因为没有像「跑通测试」那样的硬指标可以核查。
这两个问题,他都用了同一个思路来解:把做事的 agent 和评判的 agent 分开。
从 GAN 借来的框架
灵感来自生成对抗网络(GAN):一个 generator 负责生成,一个 discriminator 负责鉴别,两者对抗迭代。
他把这个思路搬到 agent 系统里:生成器(generator agent)负责干活,评估器(evaluator agent)负责打分和批评,反馈回去,生成器再改,如此循环。
关键洞察是:不需要让模型本身变得更自我批判,只需要把「评估」这个任务单独拎出来,给评估器专门调出一种「挑剔」的人格就够了。调一个独立的 evaluator 变得苛刻,比让 generator 批评自己容易得多。
第一个实验:让前端设计不再"千篇一律"
Claude 做前端有个毛病——倾向于选最安全的布局,功能没问题,但视觉上没有个性,一眼看出是 AI 生成的(比如那个经典的「紫色渐变白色卡片」)。
他设计了四个评分维度,同时给生成器和评估器:
- 设计质量:整体是否有统一的调性和身份感,而不是各个组件拼在一起
- 原创性:有没有故意为之的创意决策,而不是模板 + 库的默认值
- 工艺性:字体层次、间距、色彩对比——这是技术执行的基本功
- 功能性:用户能不能理解界面、找到主要操作
他有意把「设计质量」和「原创性」权重调高。因为 Claude 在工艺性和功能性上本来就还行,短板在于不敢出奇。
评估器拿到 Playwright MCP,可以直接在页面上点击操作,截图查看,而不是凭静态截图打分。每轮迭代大概跑 5 到 15 次,一次完整生成最长要四个小时。

效果很直观。他让 Claude 做一个荷兰艺术博物馆的网站——前九轮出来的是一个还不错的深色系页面,符合预期但没什么惊喜。然后第十轮,它把整个方向推翻了:变成了一个 3D 空间体验,CSS perspective 渲染的棋盘地板,画作挂在墙上自由排布,门洞代替滚动导航。他说这是他从没在单次生成里见过的创意跳跃。
值得注意的细节:评估标准的措辞会直接影响生成方向。他在 prompt 里加了一句「最好的设计是博物馆级别的」,结果输出整体就朝某个特定的视觉收敛——标准的语言本身就在塑造模型的审美倾向。
第二个实验:让 Claude 自主跑六个小时写完一个完整 app
把同样的逻辑推到全栈开发:生成器负责写代码,评估器相当于 QA,Playwright 点击跑测试,按 sprint 拆分任务。
架构变成了三个 agent:
- Planner:把一两句话的需求扩展成详细 spec。它不规定技术实现细节,只定义要做什么、要有哪些 AI 功能,把实现细节留给后续 agent 自己判断。
- Generator:按 sprint 一个功能一个功能地实现,每个 sprint 结束前自评,再交给 QA。
- Evaluator:用 Playwright MCP 真实点击 app,测 UI 交互、API 端点和数据库状态,对照 sprint 合同的测试条件打分,有硬阈值,任何一项低于就打回重做。
Generator 和 Evaluator 在每个 sprint 开工前要先「协商合同」:Generator 提方案(做什么、怎么算完成),Evaluator 审核,两边达成一致后才动手写代码。沟通通过文件来回读写,不直接对话。
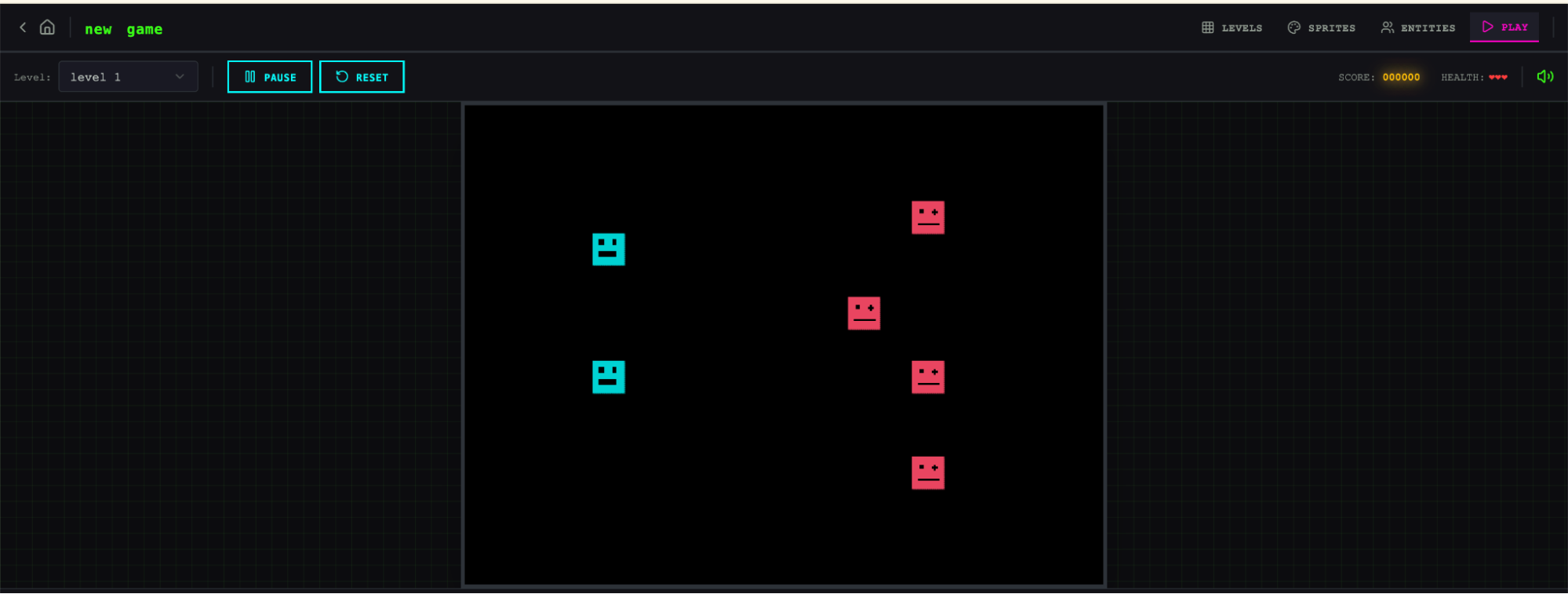
他用这套系统写了一个「2D 复古游戏制作器」(RetroForge),对比单 agent 跑了一次:
| 方案 | 耗时 | 成本 |
|---|---|---|
| 单 agent | 20 分钟 | $9 |
| 三 agent harness | 6 小时 | $200 |
贵了超过 20 倍,但差距一目了然。单 agent 的版本打开后 entity 在屏幕上出现,但操作无响应,核心游戏功能压根没跑通,代码里的连线断掉了。harness 版本的 app 打开就能看出更多打磨痕迹,而且 game 真的能玩,角色可以移动、跳台子,还内置了一个通过 prompt 生成游戏元素的 Claude 集成。
评估器的日志很能说明问题。Sprint 3 单独有 27 个验收条件,评估器发现的 bug 精确到代码行号和函数名:
| 测试条件 | 评估器发现 |
|---|---|
| 矩形填充工具支持拖拽填充 | 失败——fillRectangle 函数存在但未在 mouseUp 触发 |
| 用户可以选中并删除 entity spawn point | 失败——删除键条件需要同时有 selection 和 selectedEntityId,但点击 entity 只设了 selectedEntityId |
| 可通过 API 对动画帧重新排序 | 失败——PUT /frames/reorder 路由顺序在 /{frame_id} 之后,FastAPI 把 reorder 当成整数 frame_id 解析,返回 422 |
要把评估器调到这个水平花了不少工夫。开箱即用的 Claude 是个差劲的 QA——他观察到它发现了问题,然后说服自己问题不大,然后批准过了。它测试也不够彻底,边缘用例基本跳过。他通过反复读日志、找出判断偏差、更新 prompt 来校准,来回跑了好几轮才让评估器的严格程度达到他满意的水平。
Opus 4.6 让这套变得更轻
等到用 Opus 4.6 重跑这套流程,他发现可以大幅简化。
Opus 4.6 原生就有「更长任务的稳定性」和「更好的自我代码审查」,context anxiety 问题基本消失,所以他把 sprint 拆分整个去掉了——模型可以连续跑两个多小时不用切换上下文。原本专门为了对抗 Sonnet 4.5 context anxiety 而设计的上下文重置机制,现在也不需要了。
新版三 agent 系统(没有 sprint 结构)跑了一个 DAW(浏览器里的音乐制作软件):
| 阶段 | 时长 | 成本 |
|---|---|---|
| Planner | 4.7 分钟 | $0.46 |
| Build Round 1 | 2 小时 7 分钟 | $71.08 |
| QA Round 1 | 8.8 分钟 | $3.24 |
| Build Round 2 | 1 小时 2 分钟 | $36.89 |
| QA Round 2 | 6.8 分钟 | $3.09 |
| Build Round 3 | 10.9 分钟 | $5.88 |
| QA Round 3 | 9.6 分钟 | $4.06 |
| 合计 | 3 小时 50 分钟 | $124.70 |
最终跑出来的 DAW 有完整的 arrangement view、mixer、transport,内置 AI agent 可以通过 prompt 控制整个 app——设 tempo、定 key、铺旋律、写鼓点、调混音、加混响。当然离专业音乐软件还远,而且 Claude 本身听不见声音,QA 对「好不好听」没有判断力,这是明确的局限。

QA 在第二轮仍然抓到了实质性问题:录音功能只是个 stub,拖拽 clip 没实现,效果器 UI 只有数值滑块没有图形化(没有 EQ 曲线)。有 evaluator 在,这些问题都被递回去修了。
前端 demo 的动态效果:

几个值得拎出来的工程结论
evaluator 不是万能的,但它有用的时候非常有用。 Anthropic 的结论是:evaluator 在任务难度处于 generator 能力边界时最有价值。Opus 4.6 能力更强,很多以前需要 evaluator 兜底的地方现在 generator 自己就能搞定,evaluator 变成了一个「应该开还是关」的判断题,而不是永远必要的基础设施。
每个 harness 组件都是一个关于模型局限的假设。 博客里有句话说得很到位:harness 的每个组件都编码了「这件事模型自己做不好」的假设。这些假设会过时,新模型出来就应该去重新检验哪些组件还是必需的,哪些已经可以扔掉了。
Spec-first,不要 implementation-first。 Planner 的设计原则是只定义要交付什么,不规定技术细节怎么实现。如果 planner 在 spec 里猜错了技术细节,错误会级联到所有下游 agent。把选择权留给具体实现的 agent,往往比统一规定好。
X 社区的反应

这篇博客发出来之后,讨论里有个有意思的视角。Hardwire Media 的回复说:这套 harness 验证了多 agent 工作流的方向,但它的架构本质上还是中心化编排——单一 runtime 定义了所有 agent、运行循环和执行控制。下一个有意思的方向,是把 planner、generator、evaluator 做成相互独立的 agent,运行时动态发现彼此,通过开放协议协调,而不是在同一个 harness 里被同一段 Python 代码拉着走。

另一条评论指出:「evaluator 不只是在评判,它在塑造被构建的东西本身。Prompt 语言即架构。」这个观察其实贯穿了整篇博客——标准的措辞直接影响生成器的审美方向,合同里的验收条件决定了 app 最终长什么样。
这篇博客最有价值的地方,不是「多 agent 比单 agent 好」这个结论——这个大家早就猜到了。而是它把「如何校准评估器」、「sprint 合同怎么设计」、「什么时候上下文重置、什么时候不用」这些脏活累活的工程细节讲出来了。搭过 agent 系统的人看完会有共鸣;没搭过的人看完大概会对「$200 跑六小时的 agent」有更具体的感受。
🦞 想一起养成你的小龙虾军团?
在公众号对话框回复「小龙虾」,加入龙虾养成群——一个专门交流如何用 OpenClaw 做自媒体、搞变现的玩家社群。
军团越强,变现越快。来一起练级 👇
参考链接
- Anthropic Engineering Blog:www.anthropic.com/engineering…
- 上一篇:有效 harness 设计:www.anthropic.com/engineering…
- Claude Agent SDK:platform.claude.com/docs/en/age…
- 前端设计 skill(GitHub):github.com/anthropics/…
