

Lightpanda:不是 Chromium 魔改,是用 Zig 从零写的 AI 专用无头浏览器

当你还在用 Puppeteer 启动几百个 Chrome 实例跑爬虫的时候,有人已经从零造了一个浏览器——专门给 AI 和自动化用的那种。
为什么需要一个新浏览器?
做过爬虫或 Web 自动化的同学都知道一个痛点:现在的网页离了 JavaScript 根本没法用。
Ajax、SPA 单页应用、无限滚动、点击才加载——你再也不能像以前那样发个 HTTP 请求就拿到数据了。于是大家只能祭出终极武器:跑一个真正的浏览器。
Puppeteer、Playwright、Selenium……本质上都是在操控 Chromium 或 Firefox。问题是:
- 吃内存:一个 Chrome 实例轻松占 200-500MB,你跑 100 个试试?
- 吃 CPU:渲染引擎在跑,GPU 加速在跑,实际上你根本不需要看画面
- 启动慢:冷启动动辄好几秒
- 难维护:大规模部署 Chrome 的运维成本,谁做谁知道
本质矛盾在于:你只需要 JavaScript 执行能力,但 Chrome 给了你一整个桌面浏览器。
Lightpanda 的解法
Lightpanda 的思路很直接——既然 Chromium 太重,那就从零写一个轻量的。
不是 fork Chromium,不是魔改 WebKit,是用系统级编程语言 Zig 从第一行代码开始写的全新浏览器引擎。
核心理念:只做无头,不画画面
传统浏览器 80% 的复杂度在图形渲染。Lightpanda 把这一层完全砍掉,只保留:
- ✅ HTML 解析(基于 Servo 的 html5ever)
- ✅ JavaScript 执行(V8 引擎)
- ✅ DOM 操作和 Web API
- ✅ 网络请求(libcurl)
- ✅ CDP 协议(兼容 Puppeteer / Playwright)
不保留的:
- ❌ CSS 渲染
- ❌ GPU 加速
- ❌ 窗口管理
- ❌ 字体渲染
- ❌ 一切和"显示"相关的东西
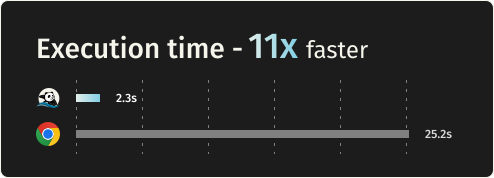
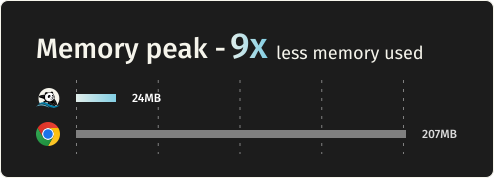
性能数据
官方 benchmark(AWS EC2 m5.large,Puppeteer 请求 100 个页面):
| 指标 | Chrome Headless | Lightpanda |
|---|---|---|
| 内存占用 | ~9x | 1x |
| 执行速度 | 1x | ~11x |
| 启动时间 | 数秒 | 瞬时 |
内存降 9 倍,速度快 11 倍。 这不是优化,是量级上的差距。
怎么用?
安装
# Linux
curl -L -o lightpanda https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-x86_64-linux && \
chmod a+x ./lightpanda
# macOS (Apple Silicon)
curl -L -o lightpanda https://github.com/lightpanda-io/browser/releases/download/nightly/lightpanda-aarch64-macos && \
chmod a+x ./lightpanda
# Docker
docker run -d --name lightpanda -p 9222:9222 lightpanda/browser:nightly
直接抓取页面
./lightpanda fetch https://example.com
一行命令,直接输出执行完 JavaScript 后的 HTML。比 curl 多了 JS 执行能力,比 Chrome 轻了 10 倍。
当 CDP 服务器用
./lightpanda serve --host 127.0.0.1 --port 9222
启动后就是一个标准的 CDP 服务器,你现有的 Puppeteer 脚本几乎不用改:
import puppeteer from 'puppeteer-core';
// 唯一要改的:指向 Lightpanda 而不是 Chrome
const browser = await puppeteer.connect({
browserWSEndpoint: "ws://127.0.0.1:9222",
});
const context = await browser.createBrowserContext();
const page = await context.newPage();
await page.goto('https://example.com', {waitUntil: "networkidle0"});
const links = await page.evaluate(() => {
return Array.from(document.querySelectorAll('a')).map(a => a.getAttribute('href'));
});
console.log(links);
为什么选 Zig?
这可能是很多人好奇的点。Lightpanda 没选 C++、没选 Rust,选了一个相对小众的 Zig。
Zig 的特点很适合写浏览器引擎:
- 零隐藏开销:没有隐式内存分配,性能可预测
- 编译时计算:大量逻辑在编译时就能解决
- C 互操作性好:直接调用 V8、libcurl 这些 C/C++ 库
- 无 GC:手动内存管理,适合高性能场景
当然 Zig 的生态还不成熟,这也是一个大胆的技术选型。
目前的状态
项目在 Beta 阶段,已经实现的能力:
- ✅ HTTP 请求(libcurl)
- ✅ HTML 解析(html5ever)
- ✅ DOM 树 + DOM API
- ✅ JavaScript 执行(V8)
- ✅ Ajax(XHR + Fetch API)
- ✅ CDP/WebSocket 服务器
- ✅ 点击、表单输入
- ✅ Cookie 管理
- ✅ 代理支持
- ✅ 网络拦截
- ✅ 遵守 robots.txt
还没做的:部分 Web API 覆盖率还不够,复杂网页可能会遇到问题。不过对于爬虫和自动化的主流场景,已经能用了。
适合什么场景?
最适合的:
- 🕷️ 大规模爬虫:内存占用低,可以跑更多并发
- 🤖 AI Agent 的浏览器工具:启动快、资源少
- 🧪 自动化测试:兼容 Puppeteer/Playwright 脚本
- 📊 数据采集:需要 JS 渲染但不需要看画面
不太适合的:
- 需要精确像素级截图的场景
- 需要完整 Web API 支持的复杂 SPA
- 需要 CSS 渲染结果的场景
和竞品比
| 特性 | Chrome Headless | Lightpanda | Playwright |
|---|---|---|---|
| 内存占用 | 高 | 极低 | 高 |
| 启动速度 | 慢 | 瞬时 | 慢 |
| Web API 覆盖 | 完整 | 部分 | 完整 |
| 部署难度 | 中 | 低 | 中 |
| 截图能力 | 有 | 无 | 有 |
| 生态成熟度 | 高 | 低 | 高 |
写在最后
Lightpanda 做的事情本质上是把浏览器拆开,只留 AI 和自动化真正需要的部分。
当大模型开始用浏览器当工具(Agent 范式),当爬虫规模越来越大,轻量级无头浏览器的需求只会越来越强。Chrome Headless 不是为这个场景设计的,它只是"能用"而已。
项目目前 2.4 万 Star,社区活跃,值得关注。如果你的业务场景是大规模爬虫或 AI Agent,可以跑个 benchmark 试试——内存账单可能会让你惊喜。
项目地址: github.com/lightpanda-…
本文基于 Lightpanda 项目 Beta 版本撰写,部分 Web API 覆盖率仍在完善中,生产环境使用请做好兼容性测试。
