

智能体开发利器-本体论-小白入门学习指引+demo实战讲解
本文档整合了本体论基础、AI应用结合、Demo实践三部分内容,形成完整的知识体系。
第一章:本体论基础
1.1 什么是本体论
本体论(Ontology) 一词源于哲学,来自希腊语 "ontos"(存在)和 "logos"(学问),意为"关于存在的学问"。
在计算机科学和人工智能领域,本体论被定义为:
"对领域知识的形式化、明确的规范说明" —— Tom Gruber (1993)
mindmap
root((本体论))
哲学视角
事物的本质
存在的方式
事物间关系
计算机科学
共享概念模型
形式化规范
机器可理解
核心价值
知识共享
知识复用
逻辑推理
语义互操作
1.2 本体论的核心要素
classDiagram
class 本体核心要素 {
<<概念>>
}
class Class {
+概念/类
+层次结构
+继承关系
}
class Property {
+数据类型属性
+对象属性
+描述特征
}
class Relation {
+part-of
+kind-of
+instance-of
+related-to
}
class Instance {
+具体实例
+类的具体化
+实际数据
}
class Axiom {
+逻辑规则
+约束条件
+推理基础
}
本体核心要素 <|-- Class
本体核心要素 <|-- Property
本体核心要素 <|-- Relation
本体核心要素 <|-- Instance
本体核心要素 <|-- Axiom
| 要素 | 说明 | 示例 |
|---|---|---|
| 类(Class) | 领域中的概念或实体类型 | 产品、客户、订单 |
| 属性(Property) | 类的特征或状态 | 产品名称、价格、库存 |
| 关系(Relation) | 类与类之间的联系 | 客户→下单→订单 |
| 实例(Instance) | 类的具体化 | iPhone 15 是产品的实例 |
| 公理(Axiom) | 逻辑规则和约束 | 订单必须包含至少一个产品 |
1.3 本体论与知识图谱的关系
flowchart LR
subgraph Schema["📋 模式层(本体论)"]
direction TB
S1["概念定义"]
S2["属性定义"]
S3["关系定义"]
S4["约束规则"]
end
subgraph Data["💾 数据层(知识图谱)"]
direction TB
D1["实体实例"]
D2["属性值"]
D3["关系实例"]
D4["事实数据"]
end
Schema -->|"实例化"| Data
Data -->|"验证"| Schema
S1 --> D1
S2 --> D2
S3 --> D3
S4 --> D4
关系说明:
- 本体论是知识图谱的模式层(Schema Layer)
- 知识图谱是本体论的实例化(Instantiation)
- 本体定义"是什么",知识图谱存储"具体有什么"
第二章:本体论与AI应用
2.1 AI系统的知识瓶颈
flowchart TB
subgraph Problems["⚠️ AI系统的知识瓶颈"]
P1["问题1:知识表示<br/>如何让机器理解领域知识?"]
P2["问题2:知识获取<br/>如何高效获取和整理知识?"]
P3["问题3:知识推理<br/>如何从已知推导新知识?"]
P4["问题4:知识共享<br/>如何在不同系统间传递知识?"]
end
subgraph Solution["✅ 本体论的解决方案"]
S1["形式化概念定义"]
S2["结构化知识建模"]
S3["规则推理引擎"]
S4["标准化语义接口"]
end
P1 --> S1
P2 --> S2
P3 --> S3
P4 --> S4
2.2 本体论在AI架构中的位置
flowchart TB
subgraph App["🎯 AI应用层"]
A1["智能问答"]
A2["推荐系统"]
A3["语义搜索"]
A4["决策支持"]
end
subgraph Engine["⚙️ 推理引擎层"]
E1["规则推理"]
E2["图推理"]
E3["机器学习推理"]
end
subgraph Ontology["🧠 本体层(知识模式)"]
O1["概念定义"]
O2["属性定义"]
O3["关系定义"]
O4["约束规则"]
end
subgraph Data["💾 数据层"]
D1["结构化数据"]
D2["半结构化数据"]
D3["非结构化数据"]
end
App --> Engine
Engine --> Ontology
Ontology --> Data
2.3 本体论与大语言模型(LLM)的结合
flowchart LR
subgraph LLM_Only["❌ 纯LLM方案"]
L1["用户输入"] --> L2["LLM处理"]
L2 --> L3["可能产生幻觉"]
end
subgraph LLM_Onto["✅ LLM + 本体方案"]
LO1["用户输入"] --> LO2["LLM处理"]
LO3["本体知识库"] --> LO2
LO2 --> LO4["精准结构化输出"]
end
LLM_Only -.->|"增强"| LLM_Onto
增强方式:
| 方式 | 说明 | 效果 |
|---|---|---|
| 知识注入 | 将本体知识作为上下文提供给LLM | 减少幻觉 |
| 约束生成 | 利用本体约束LLM的输出格式 | 结构化输出 |
| 验证推理 | 用本体验证LLM输出的合理性 | 提高准确率 |
| 语义映射 | 将自然语言映射到本体概念 | 精准理解 |
2.4 本体论与RAG的结合
flowchart TB
subgraph Traditional["📋 传统RAG"]
T1["Query"] --> T2["向量检索"]
T2 --> T3["Top-K文档"]
T3 --> T4["LLM生成"]
end
subgraph OntoRAG["🧠 本体增强RAG"]
O1["Query"] --> O2["实体识别"]
O2 --> O3["本体推理"]
O3 --> O4["精准检索"]
O4 --> O5["LLM生成"]
O6["本体知识库"] --> O2
O6 --> O3
end
Traditional -.->|"升级"| OntoRAG
本体增强RAG的优势:
- 精准检索:基于本体概念而非向量相似度
- 知识扩展:通过本体关系发现相关知识
- 推理能力:支持多跳推理问题
2.5 本体论与 Harness 的深度比较
2.5.1 本质定义的对比
flowchart TB
subgraph Ontology["🧠 本体论 (Ontology)"]
direction TB
O_Def["本质:知识表示方法"]
O_Q["回答:知识是什么?"]
O_Focus["关注:概念、属性、关系"]
O_Role["角色:AI系统的'大脑'<br/>存储和理解知识"]
O_State["状态:静态的知识结构"]
O_Def --> O_Q --> O_Focus --> O_Role --> O_State
end
subgraph Harness["⚙️ Harness"]
direction TB
H_Def["本质:评估/执行框架"]
H_Q["回答:任务怎么做?"]
H_Focus["关注:执行、验证、反馈"]
H_Role["角色:AI系统的'质检员'<br/>验证输出质量"]
H_State["状态:动态的执行流程"]
H_Def --> H_Q --> H_Focus --> H_Role --> H_State
end
Ontology <-.->|"互补"| Harness
2.5.2 设计哲学的根本差异
| 维度 | 本体论 | Harness |
|---|---|---|
| 核心问题 | "知识如何表示?" | "任务如何执行?" |
| 思维模式 | 静态建模思维 | 动态验证思维 |
| 设计起点 | 从领域知识出发 | 从任务目标出发 |
| 产出物 | 概念模型、知识图谱 | 测试用例、评估指标 |
| 成功标准 | 知识是否完整、一致 | 任务是否正确完成 |
| 迭代方式 | 扩展概念和关系 | 增加测试覆盖 |
2.5.3 与 LLM 的关系对比
flowchart LR
subgraph Before["输入阶段"]
User["用户输入"]
end
subgraph Onto_Role["🧠 本体论的作用"]
direction TB
O1["知识注入"]
O2["约束生成"]
O3["语义映射"]
O1 --> O2 --> O3
end
subgraph LLM["🤖 LLM处理"]
L["大语言模型"]
end
subgraph Harness_Role["⚙️ Harness的作用"]
direction TB
H1["输出验证"]
H2["质量评估"]
H3["反馈优化"]
H1 --> H2 --> H3
end
subgraph After["输出阶段"]
Result["最终结果"]
end
User --> Onto_Role --> LLM --> Harness_Role --> Result
本体论在 LLM 前置阶段的作用:
| 作用 | 具体方式 | 效果 |
|---|---|---|
| 知识注入 | 将本体知识嵌入 System Prompt | LLM 获得领域知识 |
| 约束生成 | 定义输出格式和取值范围 | 减少幻觉、结构化输出 |
| 语义映射 | 自然语言→本体概念 | 精准理解用户意图 |
Harness 在 LLM 后置阶段的作用:
| 作用 | 具体方式 | 效果 |
|---|---|---|
| 输出验证 | 检查输出是否符合预期格式 | 过滤无效输出 |
| 质量评估 | 计算准确率、相关性等指标 | 量化模型表现 |
| 反馈优化 | 根据评估结果调整 Prompt | 持续改进系统 |
2.5.4 典型代表与核心能力
本体论工具生态:
| 类型 | 代表工具 | 核心能力 |
|---|---|---|
| 本体编辑器 | Protégé, WebProtégé | 可视化构建本体模型 |
| 知识图谱数据库 | Neo4j, Amazon Neptune | 存储和查询本体实例 |
| 语义推理引擎 | Pellet, HermiT | 基于本体进行逻辑推理 |
| 本体标准语言 | OWL, RDF, JSON-LD | 形式化描述本体 |
Harness 工具生态:
| 类型 | 代表框架 | 核心能力 |
|---|---|---|
| 评估 Harness | lm-evaluation-harness, LightEval | 模型基准测试 |
| 测试 Harness | OpenAI Evals, Promptfoo | 输出质量验证 |
| Agent Harness | LangChain, LlamaIndex, AutoGen | 工具调用与工作流编排 |
| 监控 Harness | LangSmith, Weights & Biases | 运行时追踪与调试 |
2.5.5 实战场景对比
场景一:构建智能客服系统
flowchart TB
subgraph Problem["业务需求"]
P["智能客服系统<br/>回答产品相关问题"]
end
subgraph Onto_Solution["🧠 本体论方案"]
O1["定义产品本体<br/>产品、功能、价格、故障"]
O2["定义关系<br/>产品-包含-功能<br/>故障-属于-产品"]
O3["注入LLM<br/>作为知识背景"]
O1 --> O2 --> O3
end
subgraph Harness_Solution["⚙️ Harness方案"]
H1["定义测试用例<br/>100个常见问题"]
H2["定义评估指标<br/>准确率、相关性"]
H3["持续评估优化<br/>迭代改进Prompt"]
H1 --> H2 --> H3
end
P --> Onto_Solution
P --> Harness_Solution
Onto_Solution --> Result["完整的智能客服"]
Harness_Solution --> Result
| 方案 | 贡献 | 局限 |
|---|---|---|
| 本体论 | 让LLM理解产品知识,回答准确 | 无法验证回答质量 |
| Harness | 验证回答质量,持续优化 | 无法提供领域知识 |
场景二:SQL生成系统
| 阶段 | 本体论贡献 | Harness贡献 |
|---|---|---|
| 知识准备 | 定义数据库表结构、字段语义、约束规则 | - |
| 输入理解 | 将自然语言映射到表名、字段名 | - |
| SQL生成 | 约束LLM生成合法SQL语法 | - |
| 输出验证 | - | 验证SQL语法正确性 |
| 执行测试 | - | 测试SQL能否正确执行 |
| 结果评估 | - | 评估查询结果准确性 |
2.5.6 技术架构的融合模式
flowchart TB
subgraph Layer1["第一层:知识层"]
Onto["本体知识库<br/>概念/属性/关系/约束"]
end
subgraph Layer2["第二层:理解层"]
LLM1["LLM + 本体知识"]
Mapping["语义映射"]
Constraint["约束生成"]
end
subgraph Layer3["第三层:执行层"]
Task["任务执行"]
Tool["工具调用"]
Output["输出生成"]
end
subgraph Layer4["第四层:验证层"]
Harness["Harness评估"]
Metrics["指标计算"]
Feedback["反馈优化"]
end
Onto --> LLM1 --> Mapping --> Constraint
Constraint --> Task --> Tool --> Output
Output --> Harness --> Metrics --> Feedback
Feedback -.->|"优化"| LLM1
融合模式说明:
| 层级 | 主要技术 | 输入 | 输出 |
|---|---|---|---|
| 知识层 | 本体论 | 领域知识 | 结构化知识模型 |
| 理解层 | 本体论 + LLM | 用户输入 + 本体知识 | 语义理解结果 |
| 执行层 | LLM/Agent | 理解结果 | 执行结果 |
| 验证层 | Harness | 执行结果 | 质量评估报告 |
2.5.7 选择决策框架
flowchart TD
Start["项目需求分析"] --> Q1{"是否需要领域知识建模?"}
Q1 -->|"是"| Q2{"知识是否复杂?<br/>(多概念、多关系)"}
Q1 -->|"否"| Q3{"是否需要质量验证?"}
Q2 -->|"是"| Onto["本体论为主<br/>构建知识模型"]
Q2 -->|"否"| Simple["简单Prompt<br/>+ 少量示例"]
Q3 -->|"是"| Q4{"是否需要持续评估?"}
Q3 -->|"否"| Basic["基础实现"]
Q4 -->|"是"| Harness["Harness为主<br/>建立评估体系"]
Q4 -->|"否"| Manual["人工验证"]
Onto --> Q5{"是否需要质量保证?"}
Simple --> Q5
Q5 -->|"是"| Hybrid["本体论 + Harness<br/>融合方案"]
Q5 -->|"否"| Final["实施"]
Harness --> Final
Hybrid --> Final
Basic --> Final
Manual --> Final
决策矩阵:
| 需求特征 | 推荐方案 | 理由 |
|---|---|---|
| 复杂领域知识 + 高质量要求 | 本体论 + Harness 融合 | 知识建模 + 质量验证 |
| 复杂领域知识 + 快速上线 | 本体论为主 | 知识准确性优先 |
| 简单任务 + 高质量要求 | Harness为主 | 验证体系优先 |
| 简单任务 + 快速上线 | Prompt工程 | 成本最低 |
| 长期演进系统 | 本体论 + Harness | 可维护 + 可优化 |
2.5.8 总结:互补而非替代
┌─────────────────────────────────────────────────────────────┐
│ │
│ 本体论与Harness的协同关系 │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ │ │
│ │ 本体论 Harness │ │
│ │ ┌─────┐ ┌─────┐ │ │
│ │ │知识 │ │验证 │ │ │
│ │ │建模 │ │评估 │ │ │
│ │ └──┬──┘ └──┬──┘ │ │
│ │ │ │ │ │
│ │ │ ┌────────┐ │ │ │
│ │ └───>│ LLM │<───┘ │ │
│ │ │ 核心 │ │ │
│ │ └────────┘ │ │
│ │ │ │
│ │ 前置增强 后置验证 │ │
│ │ │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ 本体论:让LLM"懂" → Harness:让LLM"对" │
│ │
└─────────────────────────────────────────────────────────────┘
核心观点:
- 本体论解决"LLM懂不懂"的问题——知识理解
- Harness解决"LLM对不对"的问题——质量验证
- 两者是互补关系,而非替代关系
- 成熟的AI系统需要两者结合才能达到最佳效果
第三章:Demo实践 - 销售数据大屏
Demo 效果展示
以下为本体论驱动的销售数据大屏 Demo 截图,展示了从自然语言输入到动态大屏生成的完整效果。
截图1:系统主界面
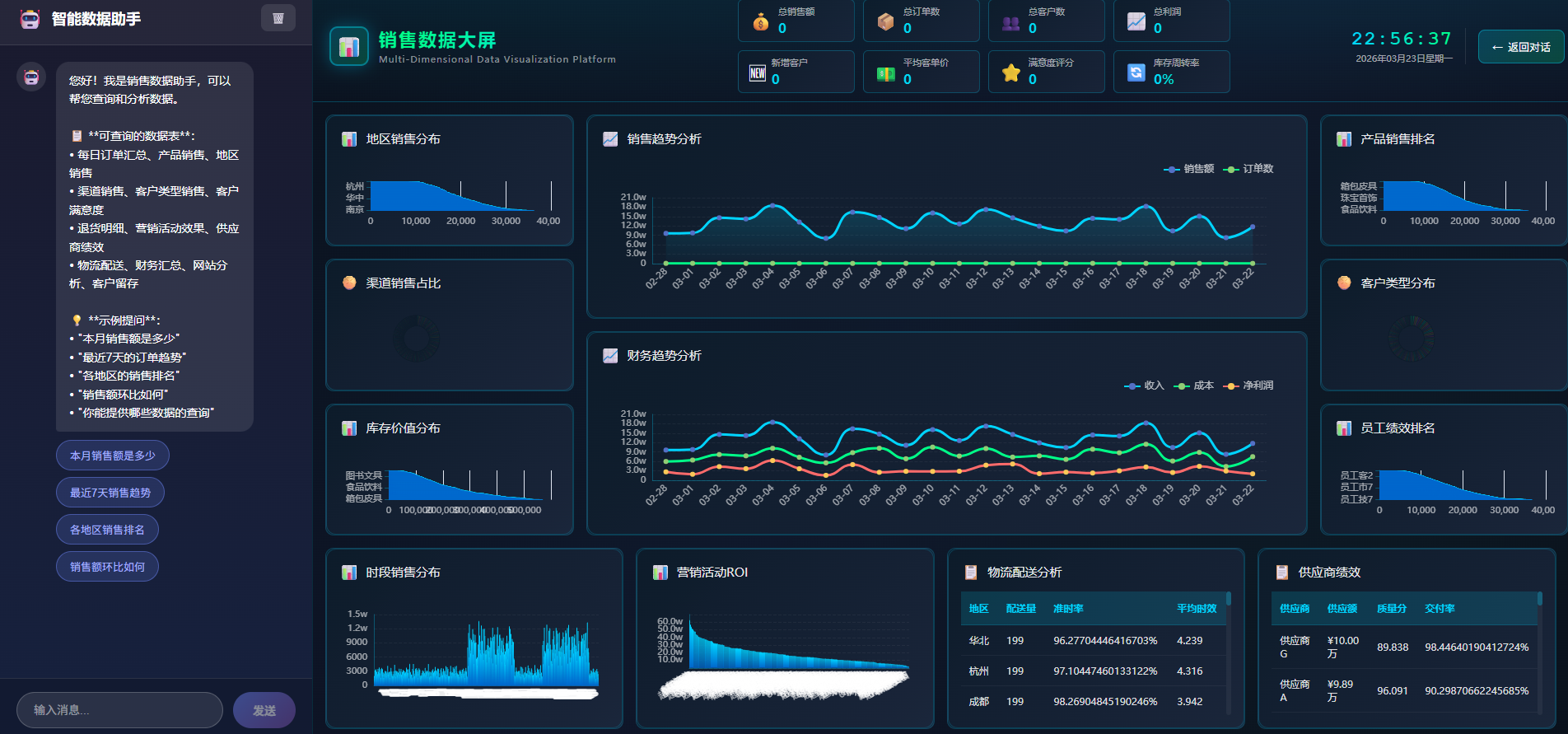
展示大屏整体布局和组件分布
截图2:自然语言输入-按照示例引导提示
用户输入自然语言查询示例
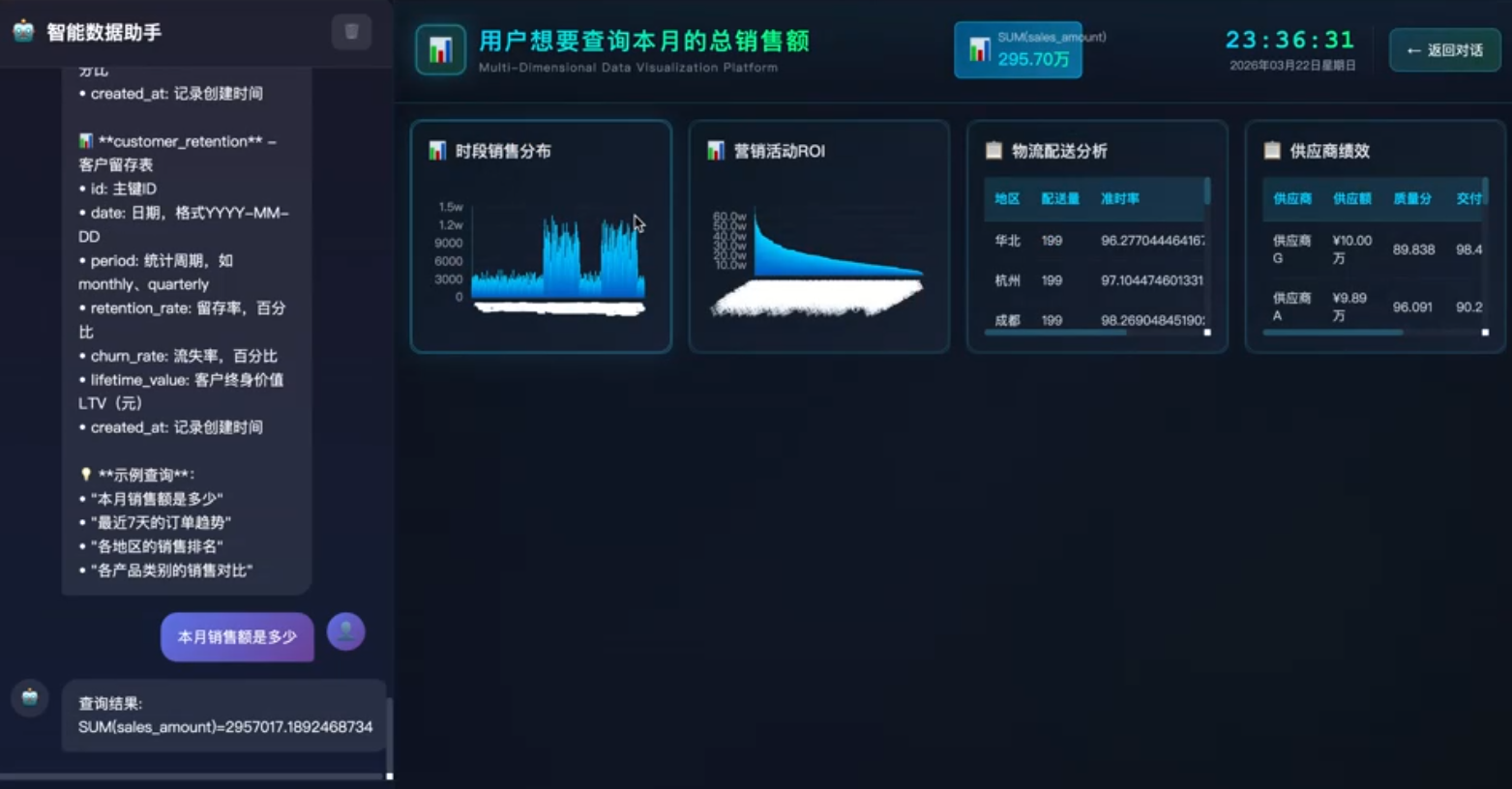
截图3:自然语言输入-自定义聊天提示
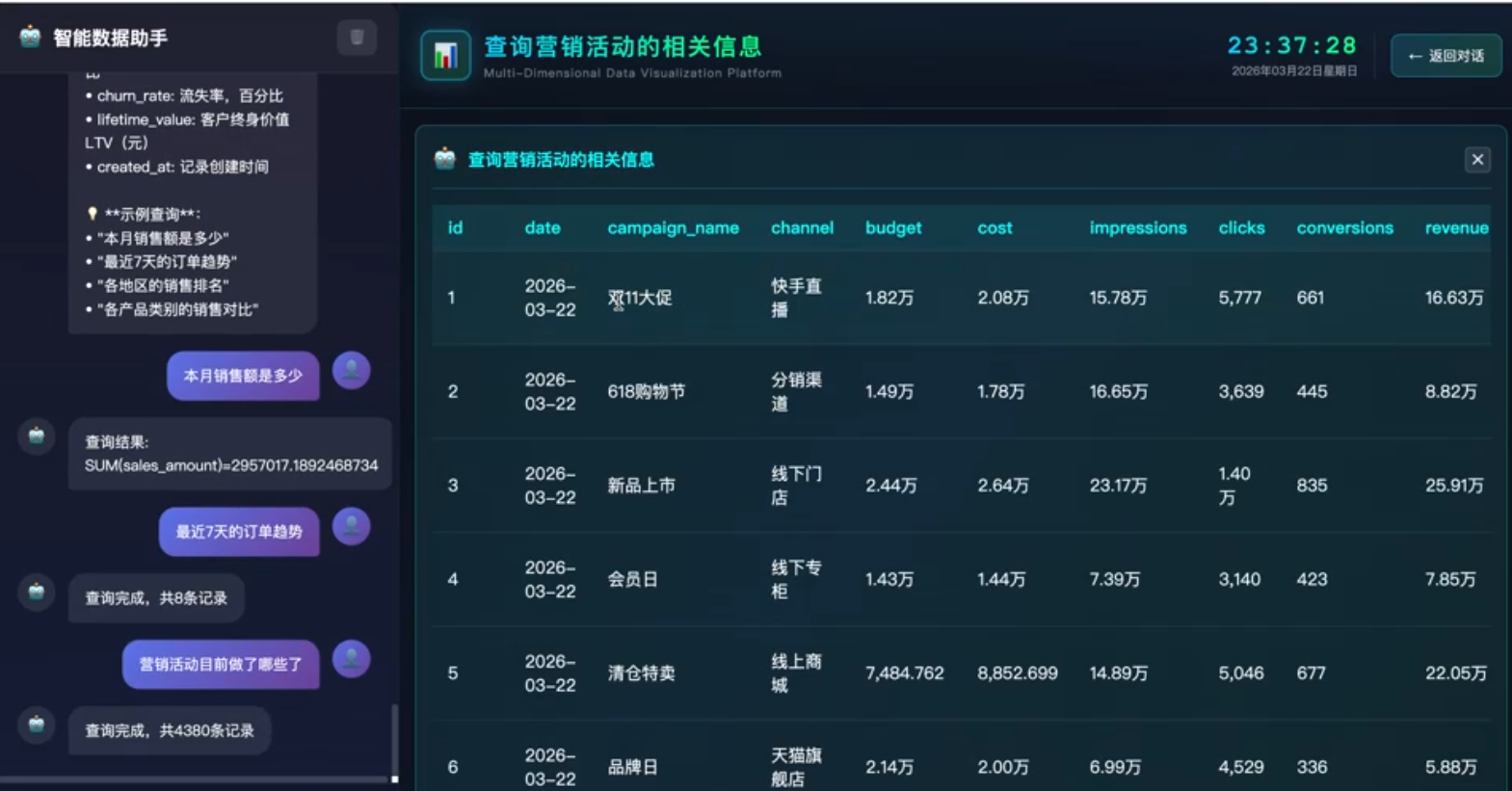
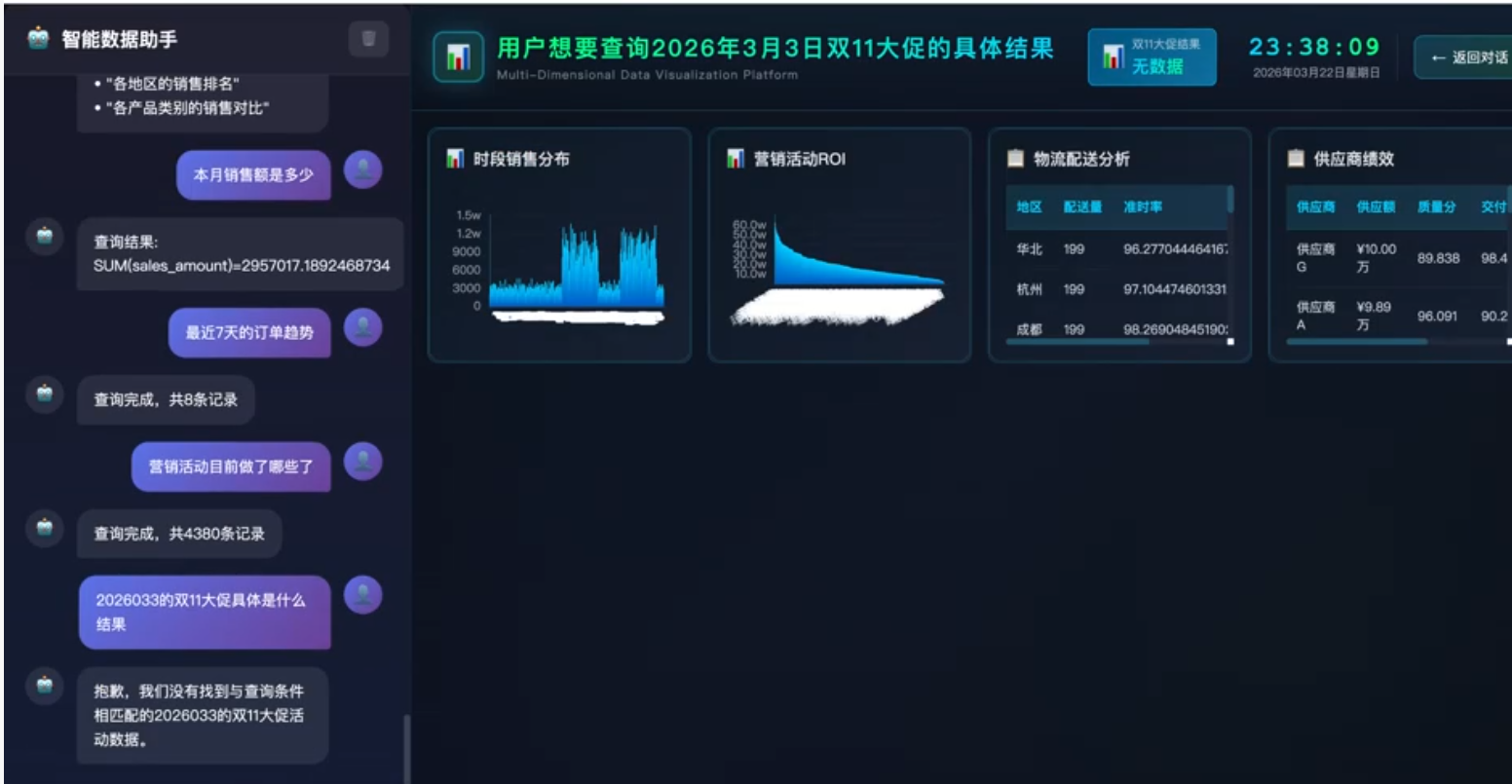
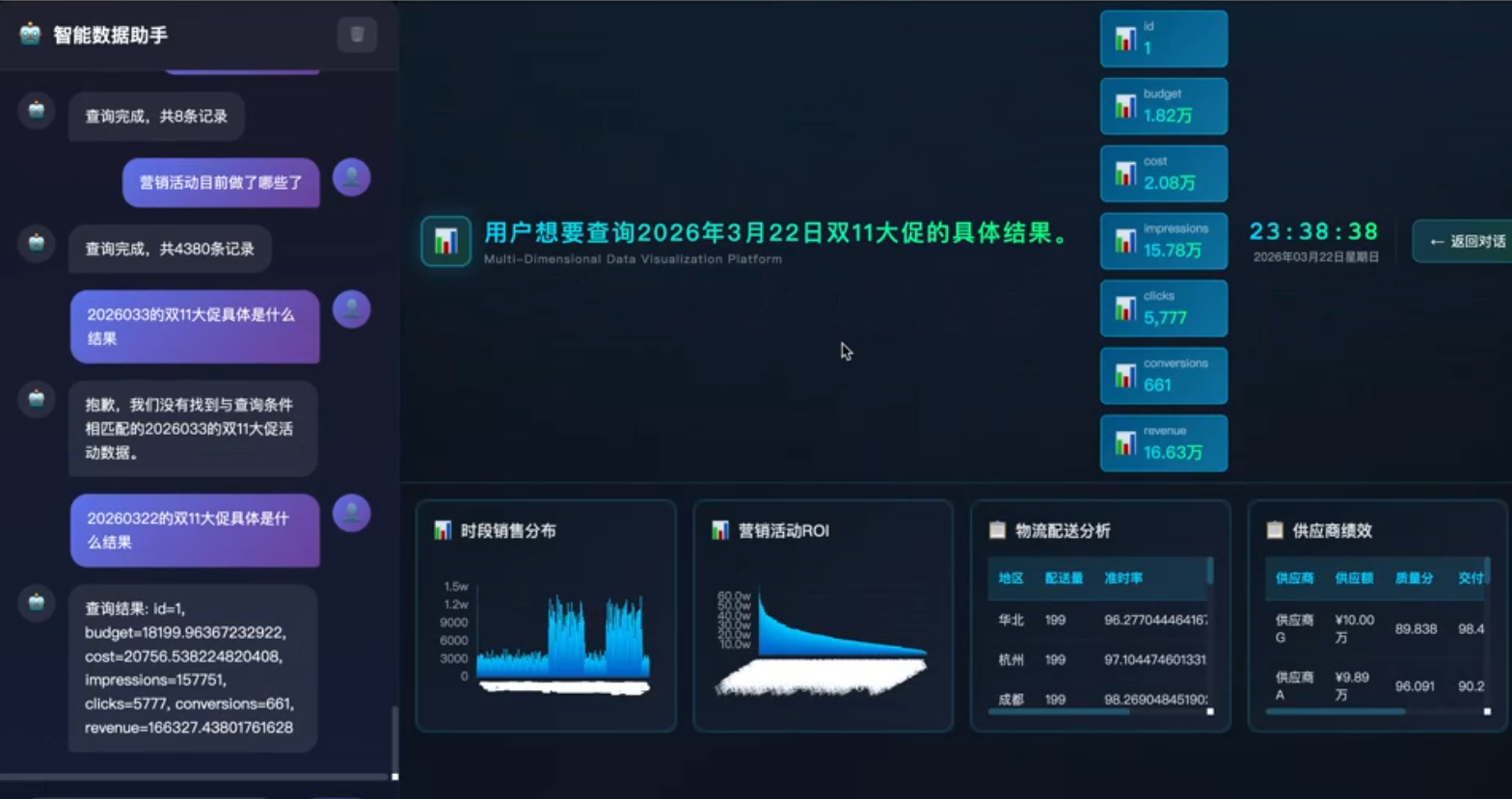
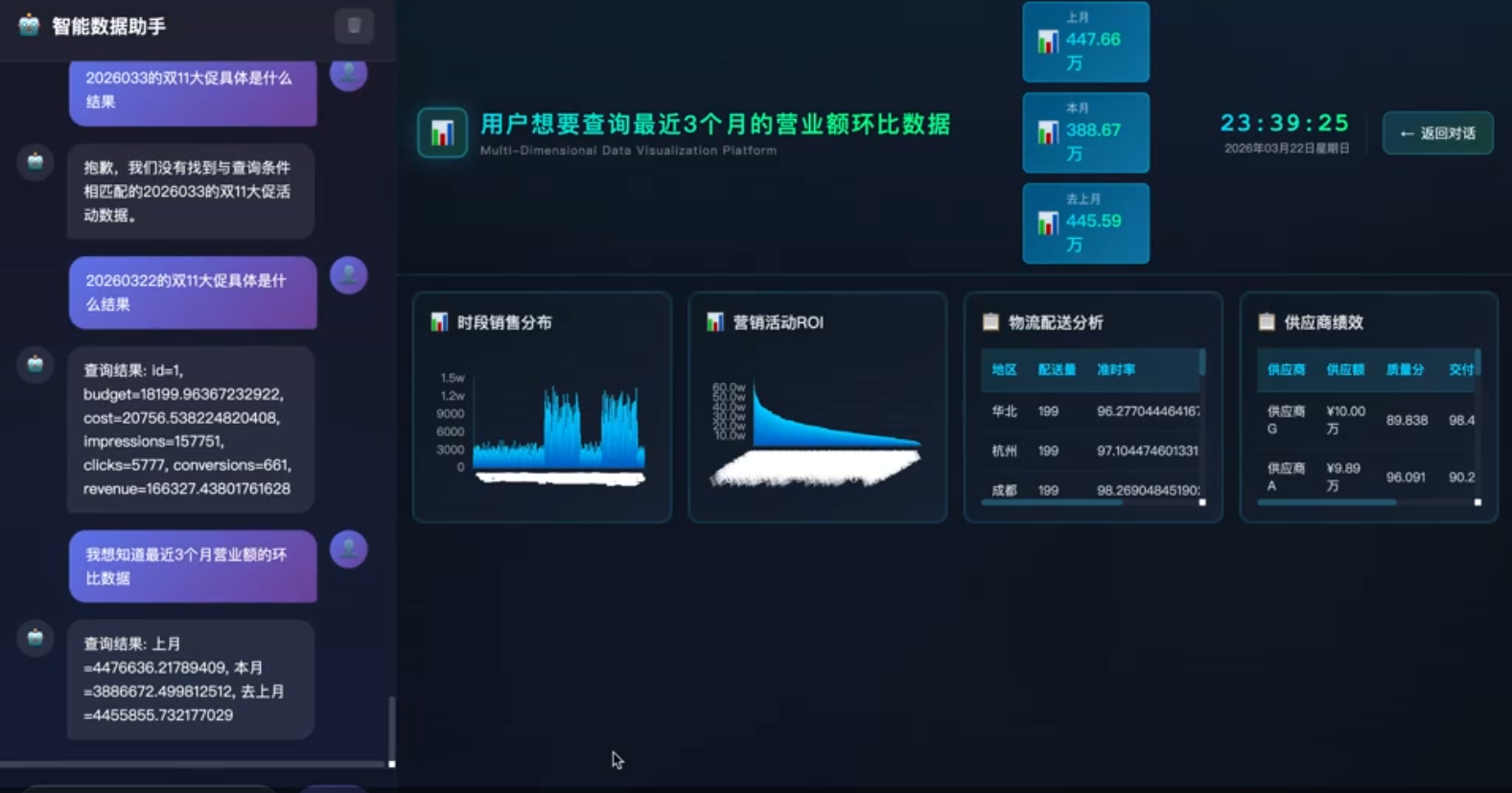
根据用户输入动态生成的销售大屏
3.1 核心本体文件
本项目通过三个核心本体文件定义了完整的知识模型,实现从自然语言到动态大屏的智能转换。
3.1.1 业务本体(business-ontology.json)
业务本体定义了销售领域的核心概念、指标、维度和业务规则。
核心指标定义:
{
"metrics": {
"sales_amount": {
"name": "销售额",
"aliases": ["销售金额", "销售总额", "营收", "营业额"],
"definition": "在一定时间内完成销售的商品或服务的总金额",
"unit": "元",
"business_meaning": "衡量企业销售规模的核心指标,反映市场占有率和营收能力",
"related_metrics": ["order_count", "profit", "avg_order_amount"],
"common_questions": [
"本月的销售额是多少?",
"哪个产品销售额最高?",
"销售额环比增长多少?"
]
},
"order_count": {
"name": "订单数",
"aliases": ["订单量", "成交单数", "订单总数"],
"unit": "单",
"business_meaning": "反映交易活跃度和客户购买频次"
},
"profit": {
"name": "利润",
"aliases": ["净利润", "盈利", "收益"],
"unit": "元",
"business_meaning": "反映企业盈利能力和经营效率"
}
}
}
维度定义:
{
"dimensions": {
"time": {
"name": "时间维度",
"levels": ["年", "季度", "月", "周", "日", "小时"],
"common_filters": {
"今天": "date = date('now')",
"本月": "date >= date('now', 'start of month')",
"最近7天": "date >= date('now', '-7 days')"
}
},
"region": {
"name": "地区维度",
"values": ["华东", "华南", "华北", "华中", "西南", "西北", "东北"]
},
"category": {
"name": "产品类别维度",
"values": ["电子产品", "服装鞋帽", "食品饮料", "家居用品", "美妆护肤"]
},
"channel": {
"name": "渠道维度",
"values": ["线上商城", "线下门店", "分销渠道", "微信小程序", "抖音直播"]
}
}
}
本体论体现:
- 概念(Concept):指标、维度作为核心概念
- 属性(Property):name、aliases、unit、business_meaning
- 关系(Relation):related_metrics 定义指标间的关联
- 实例(Instance):具体的维度值如"华东"、"电子产品"
3.1.2 组件能力本体(component-capabilities.json)
组件能力本体定义了可视化组件的类型、配置规则和选择策略。
组件定义:
{
"components": {
"MetricCard": {
"description": "指标卡片,用于展示单个核心指标的数值",
"best_for": ["展示汇总数据", "KPI指标", "单一数值展示"],
"data_requirements": {
"fields": "需要1个数值字段",
"aggregation": "通常使用SUM、AVG、COUNT等聚合函数"
},
"config_schema": {
"title": { "type": "string", "description": "卡片标题" },
"value": { "type": "number", "description": "指标值" },
"unit": { "type": "string", "description": "单位" },
"format": { "type": "string", "enum": ["number", "currency", "percent"] }
}
},
"LineChart": {
"description": "折线图,用于展示数据随时间变化的趋势",
"best_for": ["趋势分析", "时间序列数据", "对比多条数据线"],
"data_requirements": {
"x_axis": "需要时间或有序类别字段",
"y_axis": "需要1个或多个数值字段"
}
},
"BarChart": {
"description": "柱状图,用于比较不同类别的数值大小",
"best_for": ["排名对比", "类别比较", "TOP N展示"]
},
"PieChart": {
"description": "饼图,用于展示各部分占整体的比例",
"best_for": ["占比分析", "构成分析", "百分比展示"]
}
}
}
组件选择规则:
{
"selection_rules": {
"single_value": {
"description": "当结果只有一个数值时",
"recommended": ["MetricCard"],
"reason": "适合展示KPI指标"
},
"time_series": {
"description": "当数据包含时间字段且需要看趋势时",
"recommended": ["LineChart", "AreaChart"],
"reason": "适合展示时间趋势变化"
},
"category_comparison": {
"description": "当需要比较不同类别的大小时",
"recommended": ["BarChart"],
"reason": "适合排名和对比分析"
},
"proportion": {
"description": "当需要展示各部分占整体比例时",
"recommended": ["PieChart"],
"reason": "适合占比分析"
}
}
}
本体论体现:
- 概念层次:Component → LineChart/BarChart/PieChart 继承关系
- 语义属性:best_for 描述组件的适用场景
- 推理规则:selection_rules 定义组件选择的逻辑
3.1.3 数据库模式本体(db-schema.json)
数据库模式本体定义了数据表结构、字段语义和表间关系。
表结构定义:
{
"tables": {
"daily_orders": {
"description": "每日订单汇总表,记录每天的总体销售数据",
"business_purpose": "用于分析整体销售趋势、计算核心KPI指标",
"columns": {
"date": { "type": "TEXT", "description": "日期,格式YYYY-MM-DD" },
"sales_amount": { "type": "REAL", "description": "销售额(元)" },
"order_count": { "type": "INTEGER", "description": "订单数" },
"customer_count": { "type": "INTEGER", "description": "客户数" },
"profit": { "type": "REAL", "description": "利润(元)" }
},
"common_queries": [
"按时间范围汇总销售额、订单数等",
"计算同比、环比增长率"
]
},
"product_sales": {
"description": "产品销售明细表,按产品类别统计销售数据",
"columns": {
"category": { "type": "TEXT", "description": "产品类别" },
"sales_amount": { "type": "REAL", "description": "该类别销售额" }
}
},
"region_sales": {
"description": "地区销售明细表,按地区统计销售数据",
"columns": {
"region": { "type": "TEXT", "description": "地区" },
"sales_amount": { "type": "REAL", "description": "该地区销售额" }
}
}
}
}
本体论体现:
- 概念:Table、Column 作为核心概念
- 属性:description、type、business_purpose
- 关系:表间通过 date 字段关联
3.2 LLM 查询服务核心代码
LLM 查询服务是连接用户自然语言与本体知识的桥梁,核心代码位于 llm-query.js。
3.2.1 本体加载与知识注入
class LLMQueryService {
constructor() {
this.apiKey = process.env.MINIMAX_API_KEY || '';
this.baseUrl = process.env.MINIMAX_BASE_URL || 'https://api.minimax.chat/v1';
// 加载本体文件
this.dbSchema = this.loadOntology('db-schema.json');
this.componentCapabilities = this.loadOntology('component-capabilities.json');
this.businessOntology = this.loadOntology('business-ontology.json');
}
loadOntology(filename) {
const filePath = path.join(__dirname, '../ontology', filename);
const content = fs.readFileSync(filePath, 'utf-8');
return JSON.parse(content);
}
}
本体论体现:将三个本体文件加载到内存,为后续推理提供知识基础。
3.2.2 System Prompt 构建
buildSystemPrompt() {
// 从本体提取表结构信息
const tablesInfo = Object.entries(this.dbSchema.tables || {}).map(([name, info]) => {
const columns = Object.keys(info.columns || {}).join(', ');
return `${name}(${columns})`;
}).join('\n');
return `你是销售数据分析助手。判断用户意图并生成相应响应。
【数据库表结构】
${tablesInfo}
【SQLite语法规则】
- 数据库类型: SQLite
- 本月: date >= date('now', 'start of month')
- 最近7天: date >= date('now', '-7 days')
【意图判断规则】
1. 元数据查询:用户问"有哪些数据" → is_metadata_query: true
2. 帮助指导:用户问"怎么提问" → is_help: true
3. 数据查询:用户要查具体数据 → 生成 SQL
4. 普通对话:问候、闲聊 → is_chat: true
【返回格式】
{
"understanding": "简短理解",
"is_metadata_query": true 或 false,
"is_help": true 或 false,
"is_chat": true 或 false,
"chat_response": "友好回复",
"sql": "SELECT ... FROM ..."
}`;
}
本体论体现:
- 知识注入:将 db-schema 本体注入 System Prompt
- 约束生成:定义返回格式,约束 LLM 输出结构
3.2.3 意图理解与 SQL 生成
async generateSQL(userMessage) {
const response = await axios.post(
`${this.baseUrl}/text/chatcompletion_v2`,
{
model: 'abab6.5s-chat',
messages: [
{ role: 'system', content: this.buildSystemPrompt() },
{ role: 'user', content: userMessage }
],
temperature: 0.3
}
);
const content = response.data.choices?.[0]?.message?.content || '';
return this.parseSQLResponse(content);
}
parseSQLResponse(content) {
const parsed = JSON.parse(cleanContent);
// 安全检查:只允许 SELECT 语句
if (parsed.sql) {
const sqlLower = parsed.sql.toLowerCase();
if (sqlLower.includes('insert') || sqlLower.includes('update') ||
sqlLower.includes('delete') || sqlLower.includes('drop')) {
return { fallback: true, message: 'SQL包含不允许的操作' };
}
}
return parsed;
}
本体论体现:
- 语义映射:自然语言 → SQL(通过本体约束)
- 安全约束:基于规则过滤危险操作
3.2.4 智能可视化决策
async analyzeAndVisualize(queryResult, userMessage, sqlInfo) {
const prompt = `分析以下查询结果,决定最佳展示方式。
用户问题: ${userMessage}
SQL: ${sqlInfo.sql}
查询结果: ${JSON.stringify(queryResult.slice(0, 10))}
可用组件:
- MetricCard: 单个数值展示
- LineChart: 趋势图
- BarChart: 柱状图
- PieChart: 饼图
- DataTable: 数据表格
返回JSON格式:
{
"message": "对用户问题的回答",
"components": [{"type": "组件类型", "title": "标题", "config": {...}}]
}`;
const response = await axios.post(/* ... */);
return this.parseVisualizationResponse(content, queryResult);
}
本体论体现:
- 组件选择推理:基于 component-capabilities 本体
- 配置生成:根据数据特征动态生成组件配置
3.2.5 主处理流程
async processQuery(userMessage) {
// Step 1: LLM 判断意图并生成 SQL
const sqlInfo = await this.generateSQL(userMessage);
// Step 2: 根据意图类型处理
if (sqlInfo.is_chat) {
return { message: sqlInfo.chat_response, responseType: 'text' };
}
if (sqlInfo.is_metadata_query) {
return { message: this.generateMetadataResponse(), responseType: 'text' };
}
// Step 3: 执行 SQL
const sqlResult = this.executeSQL(sqlInfo.sql);
// Step 4: LLM 分析并决定展示方式
const visualization = await this.analyzeAndVisualize(sqlResult.data, userMessage, sqlInfo);
return {
message: visualization.message,
components: visualization.components,
data: visualization.data,
responseType: 'dashboard'
};
}
本体论体现:
- 多阶段推理:意图理解 → SQL生成 → 组件选择
- 知识驱动:每个阶段都依赖本体知识
3.3 整体架构
flowchart TB
subgraph Input["📥 用户语义输入"]
User["👤 用户"]
Query["查看本月销售趋势"]
end
subgraph Ontology["🧠 本体推理层"]
Components["📦 components.json<br/>组件本体"]
DataSources["📊 datasources.json<br/>数据源本体"]
Rules["🔀 rules.json<br/>映射规则本体"]
end
subgraph Output["🖥️ 大屏生成"]
Dashboard["📈 动态大屏"]
end
User --> Query
Query --> Ontology
Ontology --> Dashboard
Components --- DataSources
DataSources --- Rules
架构说明:
| 层级 | 职责 | 核心文件 |
|---|---|---|
| 输入层 | 接收用户自然语言查询 | - |
| 本体层 | 语义理解、意图推理、组件选择 | components.json, datasources.json, rules.json |
| 输出层 | 动态生成大屏配置 | - |
第四章:当前技术方案 - 纯LLM处理
4.1 技术架构演进
flowchart LR
subgraph RuleBased["📋 规则编排方案(早期)"]
direction TB
R1["用户输入"] --> R2["关键词匹配<br/>rules.json"]
R2 --> R3["规则引擎<br/>拼接SQL"]
R3 --> R4["映射规则<br/>选择组件"]
R4 --> R5["生成大屏"]
end
subgraph LLMBased["🤖 纯LLM方案(当前)"]
direction TB
L1["用户输入"] --> L2["LLM理解<br/>自然语言"]
L2 --> L3["LLM直接<br/>生成SQL"]
L3 --> L4["LLM分析<br/>决定组件"]
L4 --> L5["生成大屏"]
end
RuleBased -.->|"演进"| LLMBased
4.2 当前技术架构
flowchart TB
subgraph User["👤 用户层"]
Input["用户输入<br/>本月销售额是多少?"]
end
subgraph LLM_Layer["🤖 LLM处理层"]
subgraph Prompt["📝 System Prompt"]
Metrics["可用指标<br/>sales_amount, order_count..."]
Dimensions["可用维度<br/>region, category, channel..."]
TimeRange["可用时间<br/>this_month, last_7_days..."]
IntentTypes["意图类型<br/>dashboard, query, insight..."]
SQLRules["SQLite语法规则"]
end
MiniMax["MiniMax LLM<br/>abab6.5s-chat"]
JSON["结构化JSON响应<br/>{message, responseType, collectedData}"]
end
subgraph Services["⚙️ 后端服务层"]
direction LR
Query["analytics.query()<br/>数据查询"]
Insight["insight.generateInsights()<br/>洞察报告"]
Predict["prediction.batchPredict()<br/>预测分析"]
Dashboard["ontologyService<br/>大屏生成"]
end
subgraph Frontend["🖥️ 前端渲染"]
Vue["Vue3 + ECharts"]
end
Input --> MiniMax
Metrics --> MiniMax
Dimensions --> MiniMax
TimeRange --> MiniMax
IntentTypes --> MiniMax
SQLRules --> MiniMax
MiniMax --> JSON
JSON -->|responseType: query| Query
JSON -->|responseType: insight| Insight
JSON -->|responseType: predict| Predict
JSON -->|responseType: dashboard| Dashboard
Query --> Vue
Insight --> Vue
Predict --> Vue
Dashboard --> Vue
4.3 技术方案对比
| 维度 | 规则编排方案(早期) | 纯LLM方案(当前) |
|---|---|---|
| 意图识别 | 基于 rules.json 关键词匹配 | LLM 理解自然语言 |
| SQL 生成 | 规则引擎拼接 | LLM 直接生成 |
| 可视化决策 | rules.json 映射规则 | LLM 分析结果决定 |
| 代码维护 | 修改 JSON 配置文件 | 修改 System Prompt |
| 灵活性 | 受限于预定义规则 | 灵活应对各种问法 |
| 准确性 | 规则覆盖范围内准确 | 依赖 Prompt 质量 |
| 调试难度 | 易(看日志) | 难(需看 LLM 返回) |
4.4 纯LLM方案的优势与挑战
mindmap
root((纯LLM方案))
优势
更强的语义理解
理解各种表达方式
不依赖关键词
零规则维护
无需维护映射规则
减少配置文件
自然交互
像人与人对话
更好的用户体验
可扩展性
新增指标只需更新Prompt
快速迭代
挑战
Prompt工程
需要精心设计
持续优化
输出稳定性
LLM输出可能不稳定
需解析容错
调试困难
无法精确控制行为
黑盒特性
Token成本
复杂Prompt消耗更多
API调用费用
第五章:有无本体论的方案对比
5.1 没有本体论时的实现方案
方案一:硬编码规则匹配
flowchart LR
Input["用户输入"] --> Match["关键词匹配"]
Match --> Table["查表映射"]
Table --> SQL["拼接SQL"]
SQL --> Output["输出结果"]
style Match fill:#ffcccc
style Table fill:#ffcccc
问题:
- ❌ 每次新增需求都要改代码
- ❌ 无法处理未预定义的表达
- ❌ 维护成本高
方案二:纯LLM自由发挥
flowchart LR
Input["用户输入"] --> LLM["LLM处理"]
LLM --> Output["输出结果"]
style LLM fill:#ffcccc
问题:
- ❌ LLM不知道数据库结构,会"幻觉"
- ❌ 可能生成不存在的表名/字段名
- ❌ 无法保证SQL正确性
5.2 有本体论的方案
flowchart TB
Input["用户输入<br/>本月销售额是多少?"]
subgraph Ontology["🧠 本体知识库"]
Schema["db-schema.json<br/>表结构定义"]
Metrics["datasources.json<br/>指标定义"]
Rules["rules.json<br/>推理规则"]
end
Input --> LLM["LLM + 本体知识"]
Schema --> LLM
Metrics --> LLM
Rules --> LLM
LLM --> SQL["正确SQL<br/>SELECT SUM(sales_amount)<br/>FROM daily_order_summary<br/>WHERE date >= date('now','start of month')"]
SQL --> Result["准确结果<br/>销售额: 285.6万元"]
5.3 总结对比
| 对比项 | 无本体论 | 有本体论 |
|---|---|---|
| 开发效率 | 需要大量硬编码 | 配置驱动,快速迭代 |
| 准确率 | 60-70% | 90%+ |
| 可维护性 | 改代码 | 改配置文件 |
| 扩展性 | 每次都要改代码 | 增加本体定义即可 |
| 用户体验 | 经常出错 | 稳定可靠 |
本体论的核心价值:
让 LLM 从"猜测"变成"理解",从"不稳定"变成"可控"
第六章:总结与展望
6.1 本体论实践的核心收获
mindmap
root((本体论实践))
理论层面
知识的形式化表示
概念与关系的定义
推理规则的建立
技术层面
三层本体设计
组件本体
数据源本体
映射规则本体
LLM与本体的结合
纯LLM方案的演进
实践层面
销售大屏Demo
语义到配置的转换
动态可视化生成
6.2 技术演进路径
timeline
title 本体论技术演进
2023 : 规则编排方案
: 基于JSON配置
: 关键词匹配
2024 : 纯LLM方案
: System Prompt注入
: 自然语言理解
未来 : 混合智能方案
: 本体+LLM深度融合
: 自适应推理
6.3 未来优化方向
- 混合方案:规则做安全网,LLM做灵活处理
- Prompt版本化:管理不同版本的System Prompt
- 输出验证:增加LLM输出的结构化验证
- 本体重返:将本体论知识更好地融入Prompt
6.4 核心价值总结
本体论 + AI = 可解释、可推理、可扩展的智能系统
