

【智能体】OpenJiuWen开源智能体开发框架安装讲解
一、前言
最近技术圈有个词特别火,叫“AI Agent”。
大家聊起天来,动不动就是“自主推理”、“多步规划”、“智能体协同”。听起来很性感,但真到自己动手想做一个能干活、能落地、还能给老板演示的 Agent 系统时,往往就卡住了。
要么是需要从头写一堆底层代码,要么是各种模型接口对接得让人头大,最后做出来的东西除了能陪聊两句,干不了什么正经事。
前两天我正好去学习赋能了 openJiuwen。通过学习了解到它是开源的 Agent 开发平台。抱着“又是套壳项目吧”的心态去瞅了一眼,结果折腾了一下午,还真有点东西。今天不整那些虚头巴脑的概念,直接跟大家聊聊这玩意儿到底是啥,能干嘛,以及怎么用它快速搞出一个能用的智能体。
二、openJiuwen 是什么?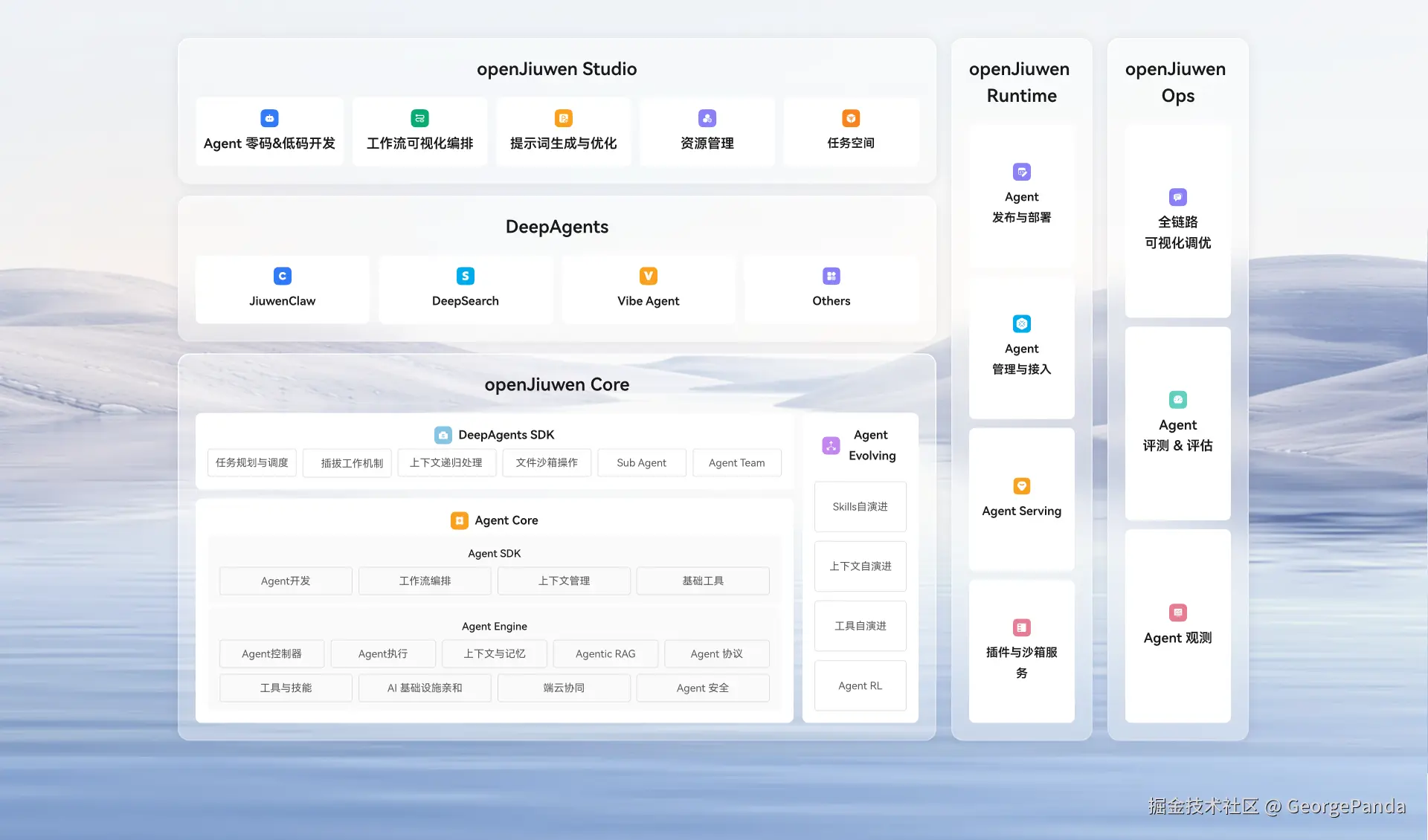
简单说,openJiuwen 就是一个帮你把大模型变成“能干活的员工”的流水线工厂。
如果你只用过大模型 API,你应该知道,光有一个聪明的“大脑”(大模型)是不够的。你想让它帮你查资料、写报告、甚至操作数据库,你得给它配“手”(工具调用)、配“记忆”(上下文管理)、还得有个“流程管家”(工作流编排)。
以前这些都得自己造轮子。openJiuwen 把这些底层能力都封装好了。它的定位很明确:开源、商用级、生产就绪。
我看了一下它的核心特点:
开箱即用:不用你从零搭建向量数据库、不用手写会话状态管理,部署起来就能跑。
多模型支持:不管是华为的盘古、月之暗面的 Kimi,还是开源的 Llama 系列,都能接进去。
多智能体协同:这是它比较强的地方,你可以让一个“项目经理”Agent 指挥几个“专员”Agent 一起干活,而不是只有一个光杆司令。
最核心的组成由两部分组成,低代码studio和高代码core两部分。
三、openJiuwen能做什么?
场景一:企业知识库问答(不仅仅是检索)
传统的 RAG(检索增强生成)往往只能回答“文档里写了什么”。但用 openJiuwen,你可以构建一个带工作流的 Agent。 比如,用户问“上个季度华东区的销售情况如何?”,Agent 可以自动拆解任务:先去数据库查销售数据 -> 再去知识库找分析报告 -> 最后综合生成一份带图表建议的简报。这个过程不需要你写复杂的 Python 脚本,在平台上拖拽或者配置一下节点就行。
场景二:复杂任务自动化
比如“帮我策划一次去大理的旅行”。 在 openJiuwen 里,你可以设置一个主 Agent,它下辖“交通查询子 Agent”、“酒店比价子 Agent”和“景点攻略子 Agent”。主 Agent 负责统筹,调用各个子工具,最后给你一份完整的 Excel 行程单。这种多角色协作,单靠一个 Prompt 是很难稳定实现的。
场景三:私有化部署的数据安全
很多国企或敏感行业不敢用公有云 API。openJiuwen 支持完全私有化部署(比如部署在华为云 EulerOS 上),数据不出内网,模型也可以换成自己微调的本地模型。这点对于要过合规审查的项目来说,简直是救命稻草。
四、 openJiuwen怎么用?
废话少说,直接上干货。我这次是在一台普通的 Ubuntu 服务器上试的,全程没超过半小时。
第一步:环境准备
https://openjiuwen.com/download
你只需要一台装了 Docker 的 Linux 服务器(当然本地 Mac/Win 装个 Docker Desktop 也能玩,但生产环境肯定推荐 Linux)。
如果还没装 Docker,官方有脚本一键安装,或者直接走官方源:
curl -fsSL https://get.docker.com | sh
装完记得把当前用户加到 docker 组,不然每次都要输 sudo 很烦:
sudo usermod -aG docker $USER
注:执行完这步记得重新登录一下终端生效。
第二步:一键启动 openJiuwen
这一步是最爽的。不需要你去配置什么 Redis、MySQL、向量库,它都用 Docker Compose 给你包好了。
找个顺眼的目录,克隆项目或者直接拉取镜像(具体命令参考官方最新文档,这里以常见的部署方式为例):
假设我们使用官方提供的快速启动脚本或 docker-compose 文件
git clone https://github.com/OpenJIuWEN/openjiuwen.git
cd openjiuwen
docker compose up -d
等进度条跑完,输入 docker ps 看看,如果看到几个容器都在 Up 状态,那就成了。
这时候,打开浏览器,访问 http://你的服务器IP:端口号(默认通常是某个特定端口,如 8080 或 1049,具体看日志输出)。
你会看到一个挺清爽的管理后台界面。没有那些花里胡哨的动画,全是实打实的配置项。
第三步:接入大模型
平台只是个壳,灵魂是大模型。
进入后台,找到 “模型管理” 或 “接入配置”。 选择你要用的模型。比如我想用 Kimi-K2(最近长文本处理很猛),就选对应的提供商。 填入你的 API Key。这步很简单,去对应的模型官网申请一个填进去就行。 点个“测试连接”,通了就保存。
小贴士:如果是企业内部用,这里也可以配置本地部署的 vLLM 或 Ollama 服务地址,完全不用花钱买 Token。
第四步:创建一个真正的 Agent
咱们来做个简单的“历史知识讲解员”。
新建应用:在控制台点击“创建智能体”,起个名儿,比如“历史通”。
设定人设:在提示词框里写上:“你是一位幽默风趣的历史老师,擅长用讲故事的方式讲解历史事件,喜欢引经据典,但语言要通俗易懂。”
挂载知识库(可选):上传几本你本地的历史 PDF 书籍。平台会自动做切片和向量化,这步是自动的,不用你操心。
配置工作流(进阶): 如果你想让它更智能,可以开启“工作流模式”。 添加一个节点:先判断用户问的是人物还是事件。 如果是人物,调用“人物百科”工具;如果是事件,调用“时间线梳理”工具。 最后把结果汇总输出。
调试与发布:右侧有个预览窗口,直接输入“给我讲讲王安石变法”,看看它能不能结合知识库回答。没问题了,点击“发布”,它会生成一个分享链接或者 API 地址。
第五步:集成到你的业务里
生成的 API 地址,可以直接嵌到你公司的 OA 系统、微信公众号或者客服系统里。
因为它支持标准的 HTTP 接口,后端开发人员对接起来几乎没有门槛。而且它自带了会话记忆管理,用户第二次问“那后来呢?”,它能记得上文在聊王安石,不需要你在业务代码里自己去维护那个庞大的 Context 列表。
用下来,openJiuwen 给我的感觉不像是一个“玩具”,更像是一个工程化工具。
它没有试图教你什么是 AI,而是直接把 AI 变成了一种可调用的基础设施。对于开发者来说,它省去了最痛苦的“状态管理”和“多轮对话逻辑编写”部分;对于企业来说,它提供了一个能私有化部署、能管控数据的底座。
当然,它也不是完美的。目前的社区生态还在成长中,一些特别复杂的自定义插件可能还需要你懂点 Python 去写扩展。但相比于从零开始搭建一套 Agent 框架,它的效率提升至少是十倍级的。
