

工程复盘说明:本文基于单次案例产出,重点描述可验证的产物链路与协作结构,不构成对多 Agent 通用能力的泛化判断。
📺 视频版:B站观看 🎮 在线体验:itch.io 原型页面 📝 原文首发:GameAI.one
你现在就可以打开 itch.io 上的原型页面,进入一个叫「雷音寺的失火案」的互动推理场景。
故事的设定很直接:孙悟空被控纵火焚毁雷音寺藏经阁,护寺僧人自称亲眼目睹,而你作为玩家,需要在废墟里搜集物证、在神话法庭上逐条追问证词、在关键矛盾点出示证据,最终揭开僧人自导自演嫁祸悟空的真相。
这不是一份概念设计稿,也不是内部 demo 截图。它已经被打包成 HTML5,部署到了 itch.io,任何人都可以用浏览器直接打开体验。案件包含 6 个角色、6 件可收集证物、4 组层层递进的矛盾链,以及从调查到庭审到最终对质的 7 个完整场景。
更重要的是,它跨过了一个比"生成出来"更难的门槛:从内部 run 走到了可以公开给外人玩的页面。
这个页面的文案也没有过度包装。它诚实说明了当前状态:视觉未完成、功能不完整,但核心玩法可体验。页面放了 3 张真实截图,让玩家在点开前就知道自己会看到什么。中间隔着的也不是人工重做,而是一条自动化发布链路:构建产物、butler push 推送、切换页面为 Public。真正需要人工把关的是最后一道发布审核:文案是否诚实、截图是否真实、有没有做超过产品实际状态的承诺。
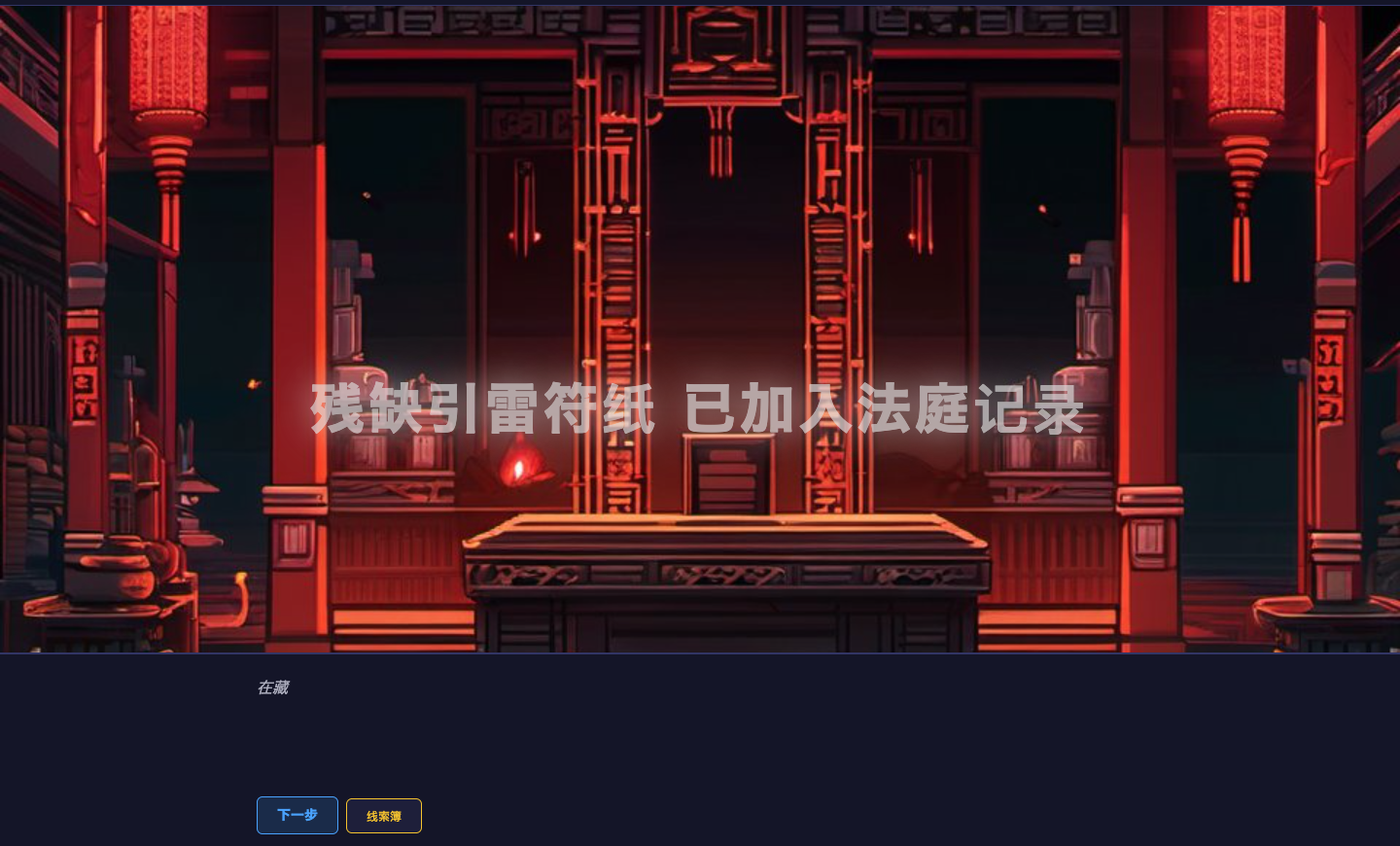
这个原型本身成立在哪里
案件的叙事不是一次性写出的长文本,而是一套结构在控制它的节奏。
3 个调查场景分别负责释放特定证据:在火灾废墟发现烧毁的经卷残片,在藏经阁深处找到带有新鲜指纹的引雷符纸和被人为重置的沙漏,在寺门记录处获取天气档案、符法规则书和钥匙借还簿。每件证物都携带明确标注的事实条目,比如「沙漏被重新倒置,二次操作发生在子时之前」「符纸指纹属于僧人」。这些事实不是装饰,它们是后续庭审触发矛盾的弹药。
2 轮庭审按难度递进展开。第一轮「雷鸣之证」先推翻"自然雷火"的说法:僧人声称子时闻雷惊醒赶往藏经阁,但天气记录显示当夜没有自然雷暴。第二轮「符纸时机与沙漏之谜」再把矛盾推进到时间线:僧人自称案发时在殿内诵经,但符纸上的新鲜指纹证明他亲手贴附了引雷符,而沙漏的重置时间戳直接瓦解了他的不在场证明。最终对质场景再把烧毁经卷残片上的墨迹内容和僧人"护经受伤"的叙事正面对碰,焚书灭证的真实动机才成立。
这条从"否定自然雷火"到"揭露焚书动机"的四级证明链,不是写作者当场发挥出来的,而是对应着案件设计文件里预先定义的矛盾结构表。
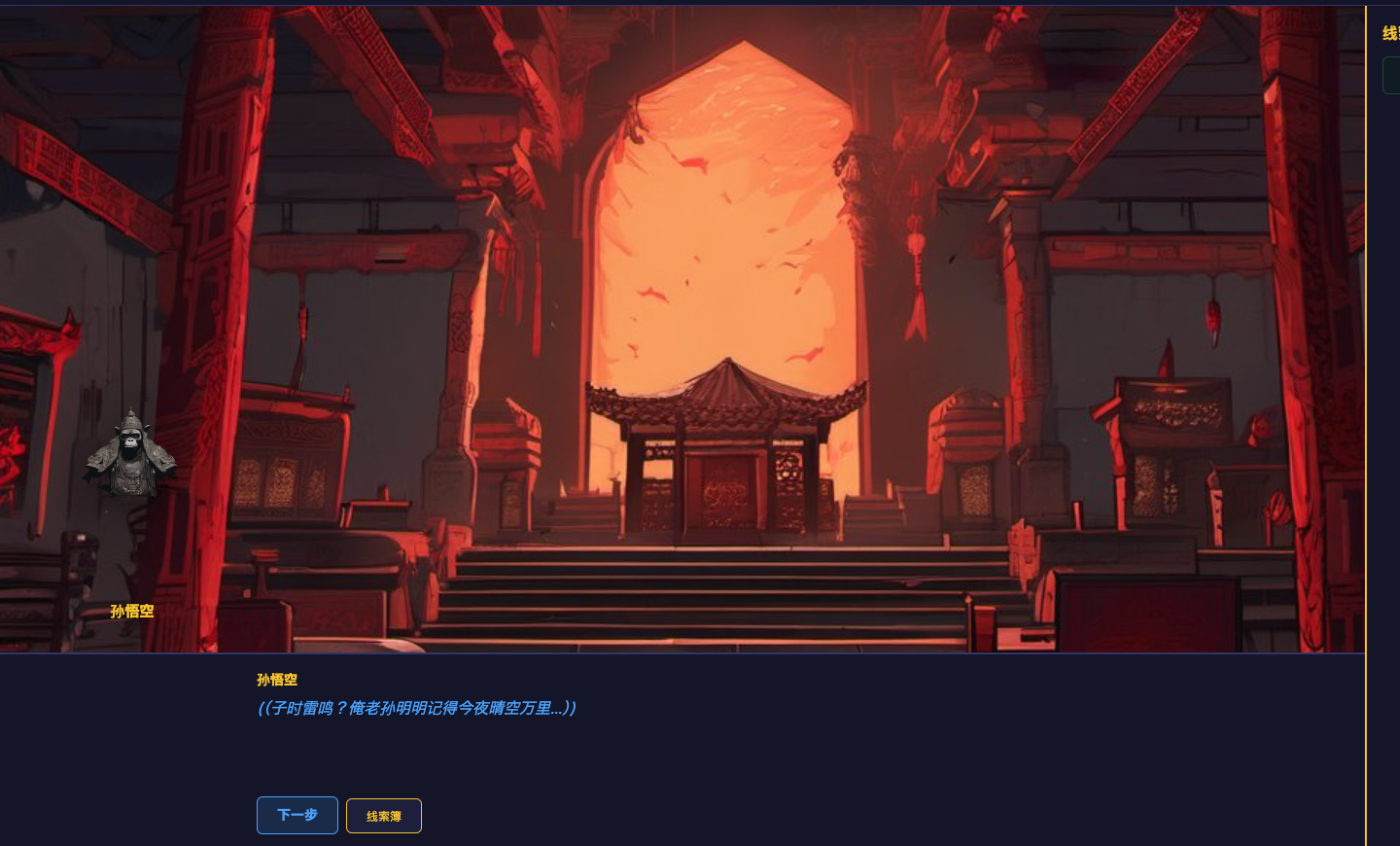
在庭审界面里,你还能看到这套设计如何落到交互上:证词被拆成可逐条追问的条目,每条证词背后绑定可出示的证据编号。只有命中正确的"证据-证词"对,剧情才会推进到下一阶段。这意味着推理链的严密性不是靠某次生成时"刚好写得顺",而是靠结构约束来保证。
这个剧本是怎么被生产出来的
这个案件的生产,本身就是一次多 Agent 协作实例。它大致可以分成三层:规划、执行、校验。
第一层是规划。
一个 chief Agent 先产出计划文件,定义案件骨架:前提设定、6 个角色的立场与出场位置、6 件证物的事实标注、4 组矛盾的精确对应关系,以及 7 个场景之间的依赖图。每个场景不是一句"写得精彩一点",而是被拆成一个工作槽位:谁出场、能发现什么证据、要埋什么伏笔、结束后接到哪里,都写清楚。
第二层是执行。
worker 并行认领场景槽位,实际被领取的数量取决于该次 run 的执行情况,其余未领取的槽位保持待命。被认领的 worker 再各自产出对应的场景 JSON。比如负责废墟开场的 Agent 要让玩家发现烧毁经卷,并埋下护寺僧人的首次伤情陈述;负责第一轮庭审的 Agent 要写出 3 条证词,并把天气记录对应的矛盾点埋进证词结构里。它们拿到的是精确输入契约,而不是开放式创作命题,这让输出更稳定,也更容易组合。
第三层是校验。
每份场景 JSON 在进入最终产物前都必须通过结构校验。证据 ID 是否存在、角色引用是否合规、转场目标是否正确、矛盾触发条件是否引用了正确的证词编号和证物,这些都能被 lint 拦下来。换句话说,这个系统不是先生成、再靠人"感觉差不多",而是先把结构错误挡在合入之前。
之后,chief 再把已产出且通过校验的场景 JSON 整合进最终 case.json,完成最后一次逻辑一致性检查,再打包构建成 HTML5,并通过发布流程推到 itch.io。整个过程里,Agent 不是在"自由发挥做一个故事",而是在一个明确约束的生产链上,分工完成各自负责的结构片段。
这件事真正说明了什么
它并不能证明"多 Agent 已经可以自动生产任意互动叙事游戏"。
这个原型是 n=1,运行在一个特定案件模板和特定协作协议下。案件的矛盾结构、场景数量、角色设定都来自人工预先设计,Agent 是在框架内填充对话和叙事内容,而不是自主发明一个完整案件。当前原型也是线性推进,不支持自由探索、分支叙事或多路径庭审。
但它确实说明了一件更具体、也更重要的事:
当计划文件足够细、场景约束足够硬、校验循环足够早时,Agent 协作的产物可以走完从结构设计到公开部署的完整链路。
它不再只是内部演示,也不只是"生成了一堆文本"。它第一次跨过了"可以给外人玩"的门槛。
人工判断仍然存在,而且应该存在。案件骨架设计、质量门的制定、以及最终发布审核,都还是人工负责的关键节点。但这篇文章要说的不是"人已经可以退出",而是:在被严格约束的生产链里,Agent 已经可以把一部分原本只能停在内部的内容,稳定地推到公开可体验的形态。
后续可以继续往下挖的方向
这篇从产物本身出发,后面还有几条更偏工程的线索可以继续展开:
- 54 次运行里,不同 Agent/Provider 的行为指纹到底有什么稳定差异?
- 当"公理"跨 zone 传播时,为什么会发生意外污染?
- 为什么单个组件验证都通过了,集成阶段仍然会失败?
- 当发布链路真的面向外部玩家时,哪些质量门必须由机器拦,哪些必须保留人工审核?
局限声明:本文基于单次运行(run593)的单个案件模板产出(n=1)。案件骨架(矛盾结构、场景、角色)均为人工预先设计,Agent 在框架内填充内容而非自主创作案件。当前原型不支持自由探索、分支叙事或多路径庭审。所有观察结论仅适用于本次运行的特定协议与模板条件,不应泛化为多 Agent 系统的一般性能力判断。人工判断介入了案件骨架设计、质量校验规则制定和最终发布审核。
