

去年团队做数据平台选型的时候,老板直接甩出一句话:"Airflow 太重了,运维成本扛不住,找个轻量点的替代品。"
说实话,当时心里是崩溃的。Airflow 确实重,Python 环境一堆依赖,Celery Executor 还得配 Redis 或 RabbitMQ,稍微规模大点就得上 Kubernetes。但数据团队就那么几个人,让他们去维护 Crontab 脚本?那不是开历史倒车吗。
后来翻遍 GitHub,在 Apache 孵化器里发现了 DolphinScheduler(海豚调度)。14.1K Stars,Apache 2.0 协议,国内易观团队开源的项目,现在已经毕业成为 Apache 顶级项目。试用之后发现,这玩意儿确实有点东西。
低代码拖拽,不写 YAML 也能干活
Airflow 的 DAG 配置大家都懂,Python 代码写工作流,灵活是灵活,但数据分析师看不懂啊。DolphinScheduler 直接给你一个可视化拖拽界面,鼠标点点拉拉就能搞定任务依赖关系。
支持 30 多种任务类型:Shell、SQL、Spark、Flink、HTTP、DataX、Python...基本覆盖了大数据场景的所有常见任务。想跑个 Hive SQL?拖个 SQL 节点,配置数据源和脚本,连上上游依赖,搞定。不需要写一行 Python,也不需要搞什么 BashOperator、SparkSubmitOperator。
这对非研发岗位友好得多,数据分析师自己就能上手配工作流,不用天天跑来找你帮忙写 DAG。
去中心化高可用,不依赖 ZooKeeper
Airflow 的架构大家都知道,Scheduler 是单点,虽然后来支持了多 Scheduler HA,但还是得依赖数据库锁来保证任务不重复调度。DolphinScheduler 从一开始就是按去中心化设计的。架构很清晰,五大核心组件:
- API Server:前端交互入口,工作流配置、用户权限管理都在这
- Master Server:DAG 解析和任务分发,可以部署多个 Master,每个 Master 都能独立工作
- Worker Server:任务执行节点,接收 Master 分发的任务,执行完回传结果
- Alert Server:告警通知,支持邮件、钉钉、企微、飞书等多种渠道
- Registry:注册中心,负责服务发现和分布式锁,支持三选一:JDBC、ZooKeeper、Etcd
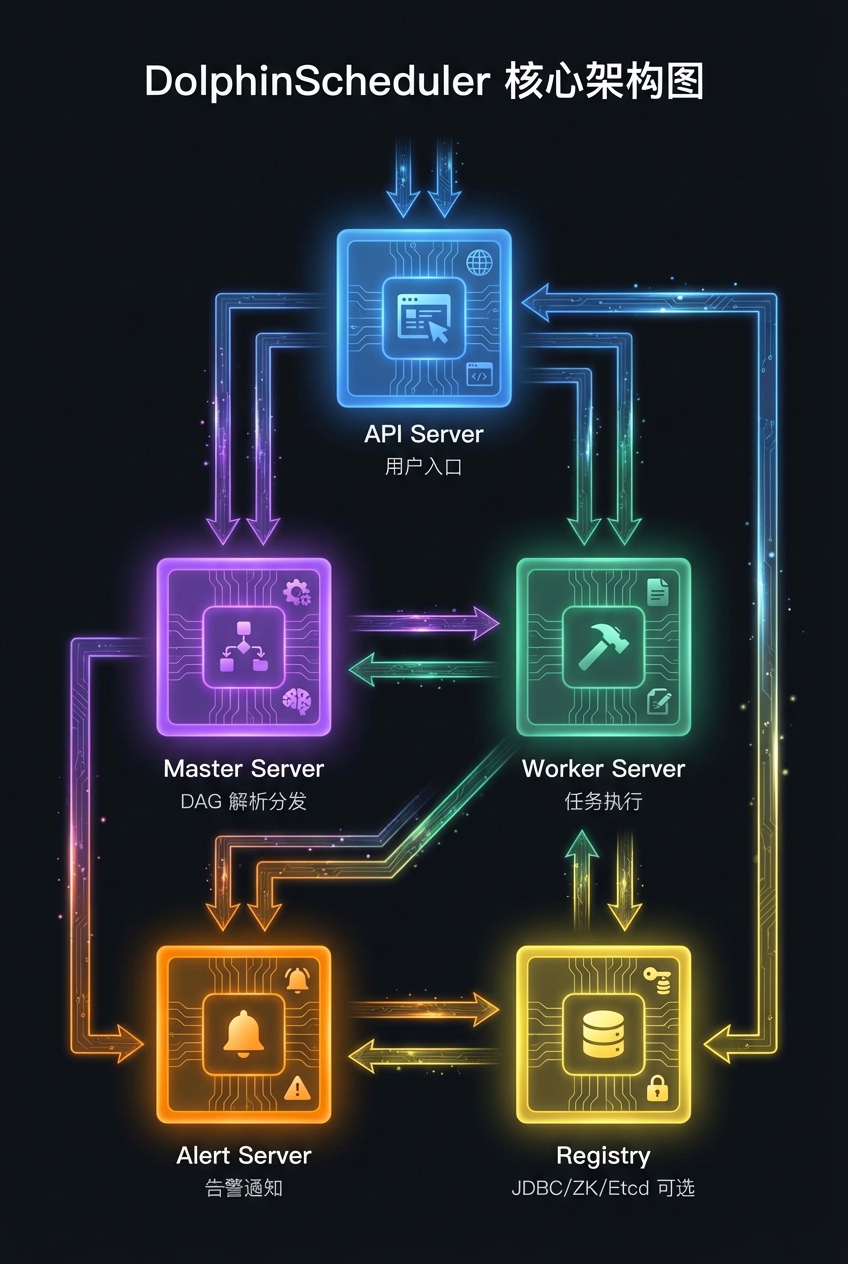
重点说说 Master 的去中心化设计。多个 Master 之间不存在主从关系,每个 Master 启动后会到 Registry 注册自己,然后根据槽位分片算法来抢任务。
具体怎么分片?用的是 ID 取模,Command ID % Master 总数 = 当前 Master 的槽位。比如你有 3 台 Master,Command ID 为 1001 的任务就分给槽位 1(1001 % 3 = 2,槽位从 0 开始算)。某台 Master 挂了,它的槽位会被其他 Master 接管,任务不会丢。
这个设计比 Airflow 的 Scheduler HA 简单多了,不需要复杂的选主逻辑,Master 可以随时横向扩展。
注册中心用 JDBC,告别 ZooKeeper 依赖
以前做分布式调度系统,绕不开 ZooKeeper。Airflow 早期版本也依赖 ZK,后来改成数据库锁,但还是有性能瓶颈。DolphinScheduler 支持三种注册中心:JDBC、ZooKeeper、Etcd。
官方推荐用 JDBC,直接复用业务数据库(MySQL 或 PostgreSQL),不需要额外部署 ZK 或 Etcd 集群。对于中小规模团队来说,少维护一套组件就是降本增效。
当然,如果你们已经有 ZK 集群了,或者对性能要求极高(上万并发任务调度),还是可以选 ZK 或 Etcd 的。
任务分发机制:主动推送,不是拉取
Airflow 的 Celery Executor 是典型的任务队列模型,Scheduler 把任务扔到 Redis 队列里,Worker 自己去拉。这种方式灵活,但队列积压的时候就头疼了。
DolphinScheduler 用的是主动推送:Master 解析完 DAG 之后,直接通过 Netty RPC 把任务推给 Worker。Worker 不需要轮询,Master 说干啥就干啥。
任务分配的时候会做负载均衡,默认是动态加权轮询,综合考虑 Worker 的 CPU、内存、线程池使用情况,把任务分给负载低的机器。如果某个 Worker 快扛不住了,Master 会自动把任务调度到其他节点。
这种推送机制的好处是调度延迟低,Master 能实时掌握 Worker 的状态,不会出现任务在队列里躺几十秒才被消费的情况。
插件化架构,想换啥换啥
DolphinScheduler 的插件化做得挺彻底的:
- 任务插件:30 多种内置任务类型,还可以自己写插件扩展
- 告警插件:邮件、钉钉、企微、飞书、Telegram,不够的话自己实现 Alert Plugin 接口
- 数据源插件:MySQL、PostgreSQL、Hive、Spark SQL、ClickHouse...支持上百种数据源
- 存储插件:任务日志、资源文件可以存本地、HDFS、S3、OSS
想换个告警渠道?写个插件打成 jar 包扔进去,重启服务,搞定。不需要改源码,维护成本低。
部署方式灵活,Docker 一键体验
官方提供四种部署方式:
- Standalone:单机模式,开发测试用,一条命令就能跑起来
- Cluster:集群模式,生产环境标配,手动部署各个组件
- Docker:一键拉起完整环境,适合快速体验
- Kubernetes:用 Helm Chart 部署,云原生团队首选
想快速体验的话,直接用 Docker Compose:
docker-compose -f docker/docker-compose.yaml up -d
等容器启动完,浏览器打开 http://localhost:12345/dolphinscheduler,默认账号 admin/dolphinscheduler123,拖拽配个 Shell 任务试试,几分钟就能跑通一个工作流。
生产部署的话,建议至少 3 台 Master + 若干 Worker,数据库用 MySQL 主从或 PostgreSQL,注册中心选 JDBC 就行。官方文档写得还算详细,踩坑的地方不多。
3.4.0 新版本亮点
去年底发布的 3.4.0 版本,主要优化了几个点:
- 任务优先级队列:高优任务可以插队执行,不用干等前面的大任务跑完
- 动态资源分配:Worker 可以根据任务类型动态调整线程池大小,避免资源浪费
- 工作流版本管理:DAG 修改后自动保存历史版本,支持一键回滚
- 血缘分析增强:数据表的上下游依赖关系可视化,方便排查影响范围
最实用的是任务优先级队列,以前遇到紧急任务插入,只能手动暂停其他任务腾出资源。现在直接给任务打个高优先级标签,调度器自动帮你插队。
适合什么团队?
说了这么多优点,也得说说适用场景。 适合用 DolphinScheduler 的团队:
- 数据团队 10 人以下,运维资源有限,不想维护 Airflow 全家桶
- 任务以离线批处理为主,ETL、数据同步、报表调度等场景
- 需要低代码平台,让数据分析师、业务人员也能配工作流
- 已经有 MySQL/PostgreSQL,不想额外部署 ZooKeeper 集群
不太适合的场景:
- 实时流式任务为主(虽然支持 Flink,但调度粒度还是偏批处理)
- 深度依赖 Python 生态,工作流逻辑需要大量自定义代码(Airflow 更灵活)
- 任务量特别大,上万并发调度(可能需要 ZK 注册中心 + 深度调优)
总体来说,DolphinScheduler 定位就是易用、稳定、轻量的数据调度平台。没有
