


GitHub: github.com/nimiplatfor… | Apache-2.0 / MIT
一、本地推理正在变成标配,但碎片化问题没人解
随着如今的模型越来越强,也越来越小,本地推理不再是极客的玩具,正在变成 AI 应用的标配。IDC 预测,到 2027 年 80% 的 AI 推理将在本地或边缘执行。
Stack Overflow 2025 开发者调查显示,59% 的开发者同时使用 3 个以上的 AI 工具。但打开我们正在做的 AI 项目,以一个 AI 角色应用为例,它需要:理解用户说的话(STT),思考怎么回答(LLM),把回答读出来(TTS),根据对话生成一张场景图(图像生成),偶尔配一段背景音乐(音乐生成)。
五种模态。在今天的工具链下,我们需要:
- 本地文本推理:Ollama 或 llama.cpp
- 本地图像生成:ComfyUI 或 AUTOMATIC1111
- 本地语音合成:Piper 或 GPT-SoVITS
- 云端视频生成:Runway API
- 云端音乐生成:Suno API
五个工具,五个进程,五套配置,五种接口格式。
每一种 AI 能力都是一座孤岛。
这像什么?像要做一道菜,但厨房被拆成了五间。切菜在 A 房间,炒菜在 B 房间,调味在 C 房间。每间厨房的门锁不一样,灶台型号不一样,量杯单位都不一样。
而我们在开发应用上,花了 40% 的时间在写"胶水代码"——Provider 切换、fallback 逻辑、健康检查、流式传输适配、Token 计量、错误重试。这些代码跟业务逻辑没有任何关系,但它们占了代码库的一大块。而且每个 AI 应用都在重复写这同一套东西。
花在我们内心真正的想要实现的东西上,可能只有只有20%——剩下的40%是处理服务器、部署等。
二、本地工具和云端 SDK,各自解决了一半问题
那这个开发链路里的前半部分,现有的解决方案分两类。OpenRouter 的数据很能说明问题——500 万开发者在它上面路由请求,覆盖 60 多个 Provider、300 多个模型。多 Provider 不是少数人的需求,是常态。
第一类:本地模型运行器。Ollama、LM Studio、LocalAI。它们解决了"在本地跑模型",但不管云端。当本地 GPU 不够用、或者需要 GPT-4 级别的能力时,得自己切换到云端 SDK。
第二类:云端 API 网关。OpenRouter、LiteLLM。它们统一了多个云端 Provider 的接口,但不管本地。想用本地模型省钱,或者在离线环境下工作,它们帮不了我们。
还有一类:应用层框架。LangChain、Vercel AI SDK。它们在应用层做了抽象,但不管推理实际在哪里执行、Provider 挂了怎么降级、本地引擎的生命周期怎么管理。
没有一个方案同时解决:本地 + 云端 + 多模态 + 路由降级 + 生命周期管理。
每一个都解决了拼图的一块。但没有人把拼图拼完。
Nimi Runtime 就是这份完整的拼图。
三、Runtime:不是模型运行器,是执行面
我们做了 Nimi Runtime。一句话说清楚它是什么:
AI 推理的 Docker。
Docker 解决的不是"怎么跑一个程序"——那个问题早就被解决了。Docker 解决的是"不管在哪里跑,行为一致"。Nimi Runtime 也一样:不管调用的是本地 Llama 还是云端 GPT-4,不管是文本还是图像还是语音,接口一样,行为一致。
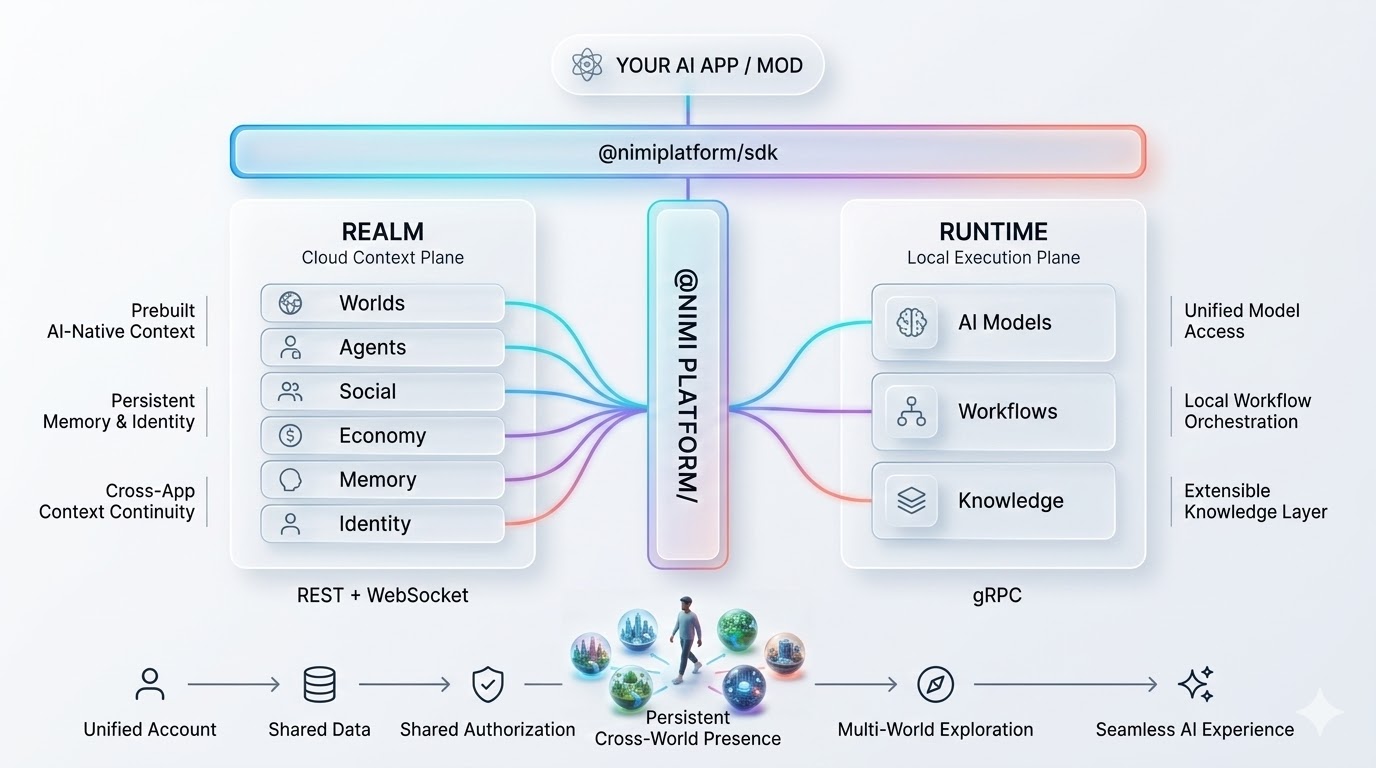
一个 Go daemon,后台常驻。装上启动,所有 AI 能力通过一个端口进来。
nimi start # 启动
nimi run "你好" # 默认推理(本地或云端,看你配置)
nimi run --provider gemini "你好" # 指定云端
nimi run --model llama3.2 "你好" # 指定本地
同一个命令,同一个接口。执行面在哪里,不用关心。
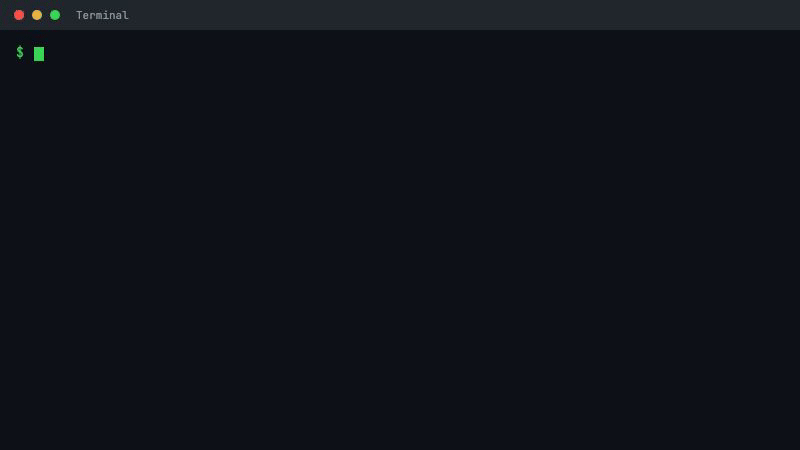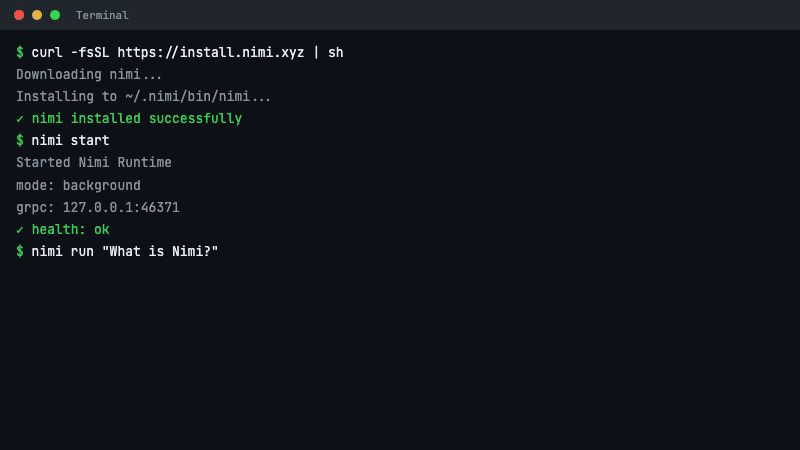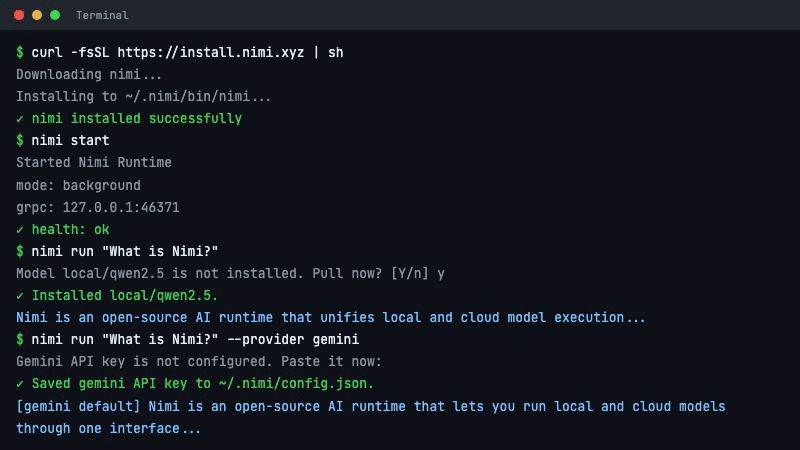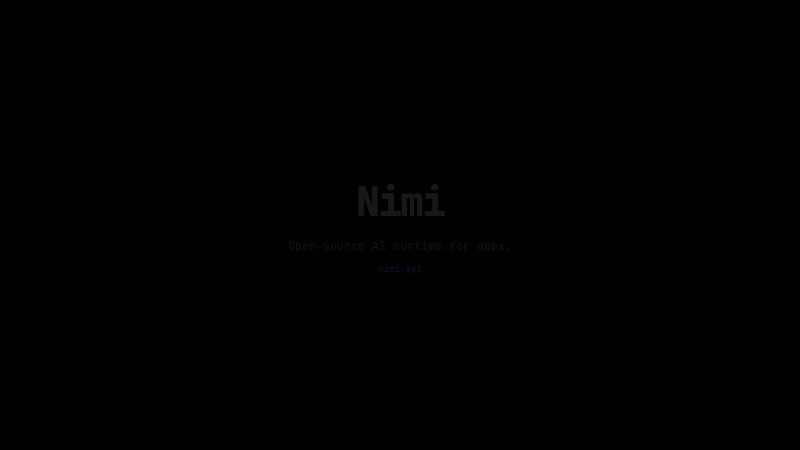
42 个云端 Provider。覆盖 OpenAI、Anthropic、Gemini、DeepSeek、通义千问、混元、Kimi、GLM——国内外全覆盖。本地引擎支持 LocalAI 和 Nexa SDK,Runtime 自动管理它们的生命周期——启动、关停、健康探测、故障恢复,不需要手动管。
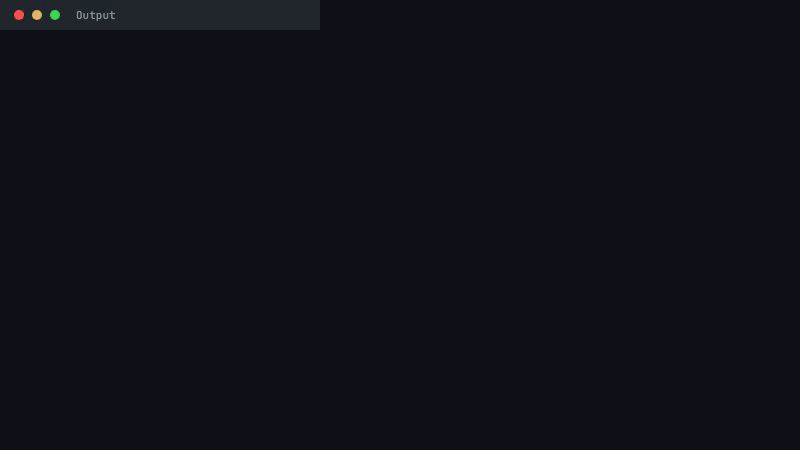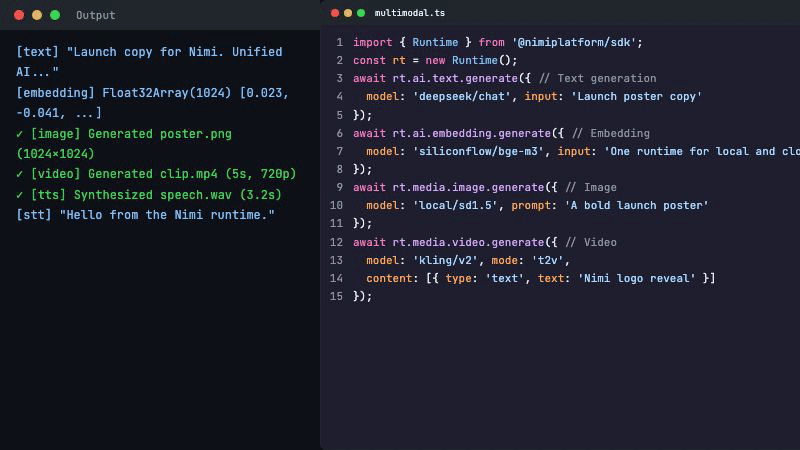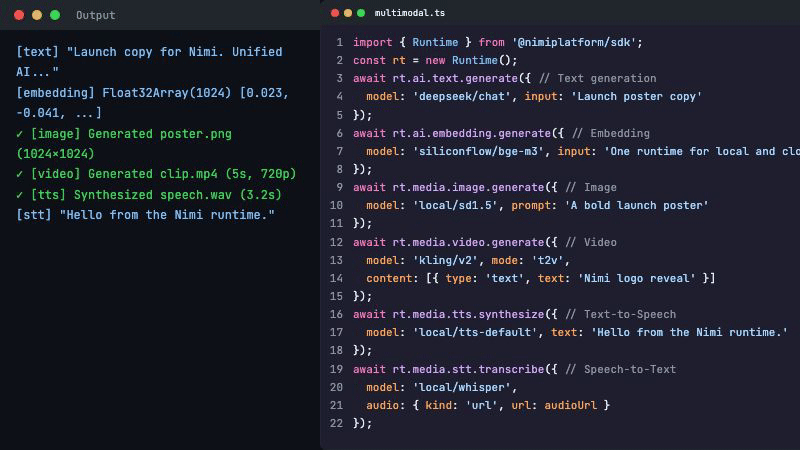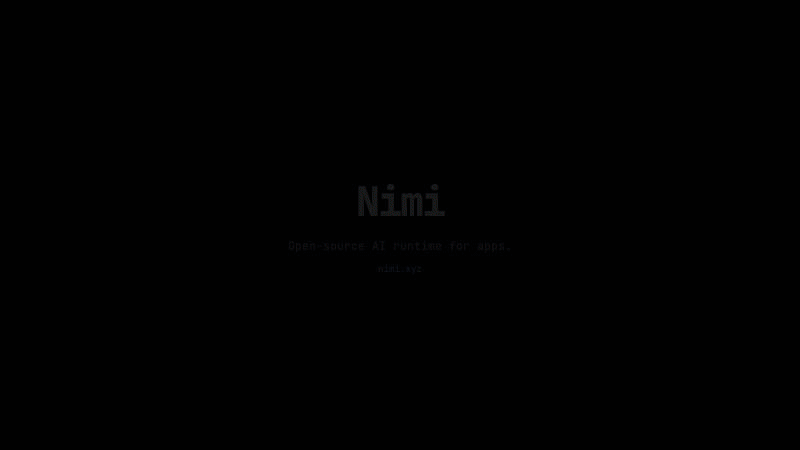
12 种模态,一套协议:
| 模态 | 能力 |
|---|---|
| 文本生成 | 对话、指令、工具调用 |
| 文本 + 视觉 | 图片理解、OCR |
| 图像生成 | 文生图、图生图 |
| 视频生成 | 文生视频、图生视频 |
| 语音合成 | TTS + 声音克隆 |
| 语音识别 | STT + 时间戳对齐 |
| 音乐生成 | 文生音乐、风格迁移 |
| 嵌入向量 | 语义搜索、RAG |
| 知识检索 | 文档索引 + 语义搜索 |
全部走同一个 gRPC 接口。
四、关键能力:路由、降级、和我们不需要再写的代码
智能路由。设了本地优先,本地 LocalAI 正常就走本地。LocalAI 挂了,自动切到云端 OpenAI。OpenAI 限流了,自动切到 Gemini。不需要写一行 if-else。
健康监控。Runtime 每 8 秒探测一次每个 Provider 的状态——HEALTHY、DEGRADED、UNREACHABLE、UNAUTHORIZED。我们在应用里看到的永远是一个可用的推理服务,后面谁在跑不用管。
幂等去重。10,000 条请求窗口,防止同一个请求被重复计费。并发控制:全局上限 8,每应用上限 2,可配置。
审计追踪。每一次 AI 调用都有记录——调了谁、花了多少 token、路由决策是什么、有没有自动切换。环形缓冲区存最近 20,000 条。用于调试、成本分析、合规。
这些代码,我们以前每个项目都在自己写。现在不用了。
五、对比
把所有方案放到一张表里:
| 能力 | Ollama | LM Studio | LocalAI | ComfyUI | OpenRouter | LangChain | Nimi Runtime |
|---|---|---|---|---|---|---|---|
| 本地文本推理 | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ✅ |
| 本地图像生成 | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ✅ |
| 本地 TTS/STT | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ✅ |
| 云端 Provider | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ | ✅ (42 个) |
| 本地+云端路由 | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ |
| 自动降级 | ❌ | ❌ | ❌ | ❌ | 部分 | ❌ | ✅ |
| 视频 / 音乐 | ❌ | ❌ | ❌ | 部分 | ❌ | ❌ | ✅ |
| Daemon 架构 | ✅ | ❌ | ❌ | ❌ | N/A | ❌ | ✅ |
| 工作流 DAG | ❌ | ❌ | ❌ | ✅ | ❌ | ✅ | ✅ |
| 权限 / 审计 | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ |
Ollama 把"本地跑模型"做到了极致简洁,ComfyUI 把图像工作流做到了无人能及。但它们各自解决的是一个维度的问题。
Nimi Runtime 要做的是把这些维度统一到一个执行面上。我们的应用只需要知道一件事:调 Runtime。
六、在应用里用
SDK 集成:
import { Runtime } from '@nimiplatform/sdk/runtime';
const runtime = new Runtime();
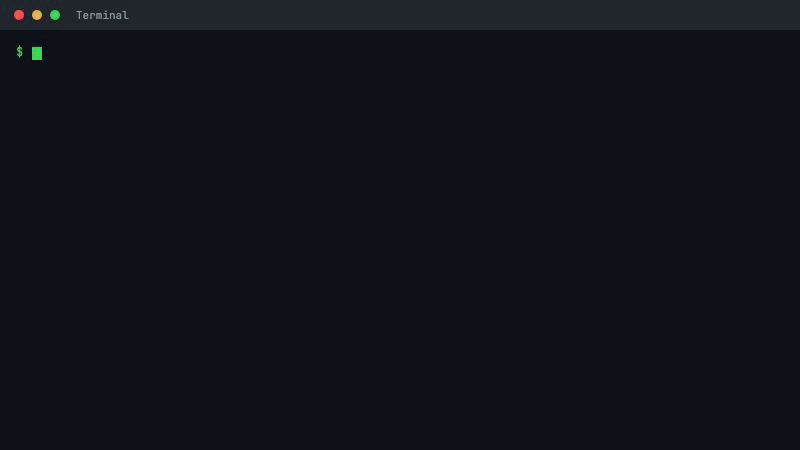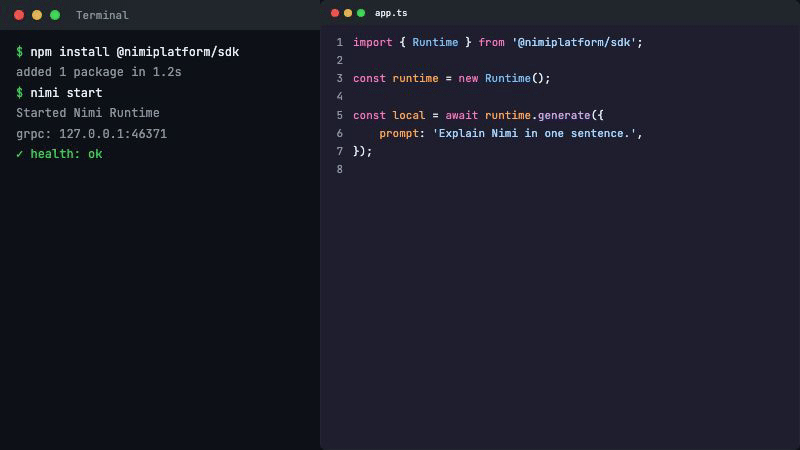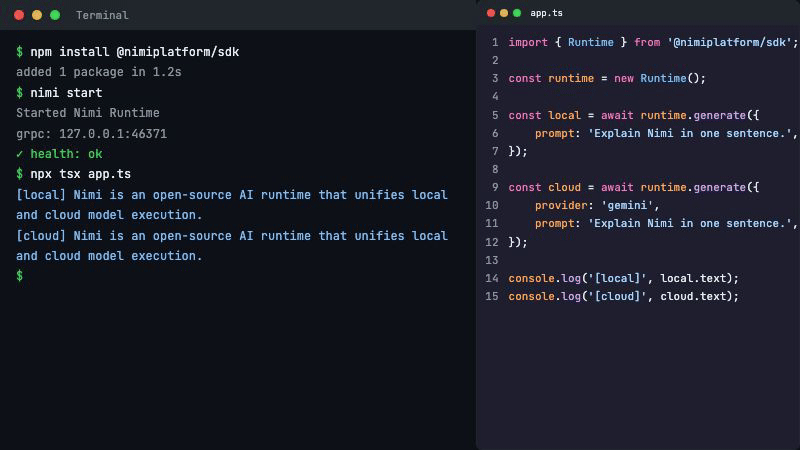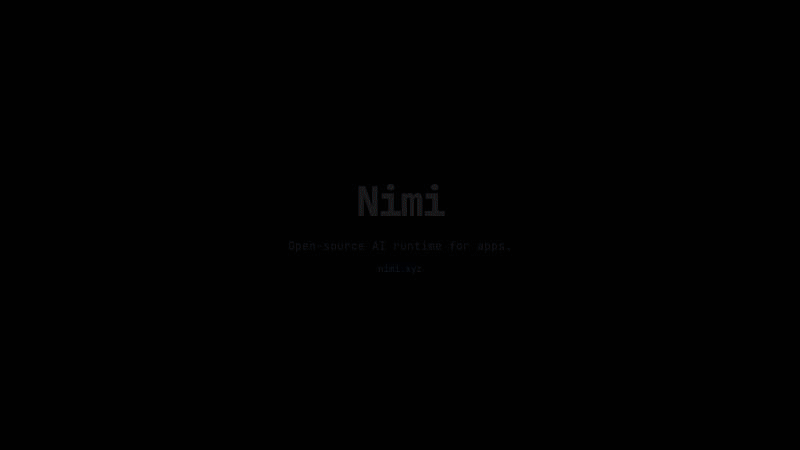
// 本地推理
const local = await runtime.generate({
prompt: '用一句话介绍你自己',
});
// 云端推理——同一个接口,加一个参数
const cloud = await runtime.generate({
provider: 'gemini',
prompt: '用一句话介绍你自己',
});
已经在用 Vercel AI SDK?零迁移成本:
import { generateText } from 'ai';
import { createNimiAiProvider } from '@nimiplatform/sdk/ai-provider';
const nimi = createNimiAiProvider({ runtime });
const { text } = await generateText({
model: nimi.text('gemini/default'),
prompt: 'Hello from Vercel AI SDK + Nimi',
});
底层走 Nimi Runtime 的路由和降级逻辑,但写出来的代码跟用 OpenAI Provider 一模一样。
Nimi Runtime 是开源的。Apache-2.0 / MIT 双许可。
GitHub: github.com/nimiplatfor…
curl -fsSL https://install.nimi.xyz | sh
nimi start
nimi run "Hello"
三行命令,我们的机器就有了一个统一的 AI 推理执行面。42 个云端 Provider,本地引擎,12 种模态,一个接口。
别再为每个 AI 模态单独写集成了,让 claude 打开这个链接,它会告诉你接下来该怎么做了。
Nimi Team GitHub: github.com/nimiplatfor…