

在分布式微服务架构成为主流的今天,系统复杂度呈指数级增长。当线上出现故障,你是否还在靠"重启大法"和"日志翻找"来定位问题?当服务数量从 10 个增长到 100 个,你还在用传统的监控方式吗?是时候构建一套现代化的可观测性体系了。
一、云原生时代的监控困境与破局
1.1 传统监控的局限性
还记得单体应用时代吗?一个应用、一个数据库、一个日志文件,出了问题直接看日志就能定位。但现在呢?
现实场景:
- 用户反馈"设备列表加载很慢"
- 你查了 Gateway Service 日志 → 正常
- 查了 Device Service 日志 → 有点慢但不明显
- 查了数据库日志 → 连接池正常
- 查了 Redis 日志 → 也没问题
- 最终发现:Kafka 消费积压导致 Data Service 响应变慢,影响了整个调用链
这就是分布式系统的黑盒困境:一个请求可能跨越 5-10 个服务,传统监控方式根本无法追踪完整的调用链。
1.2 可观测性(Observability)是什么?
可观测性是指通过系统的外部输出来推断系统内部状态的能力。与传统监控不同,可观测性强调的是主动发现问题、快速定位根因。
可观测性建立在三大支柱之上:
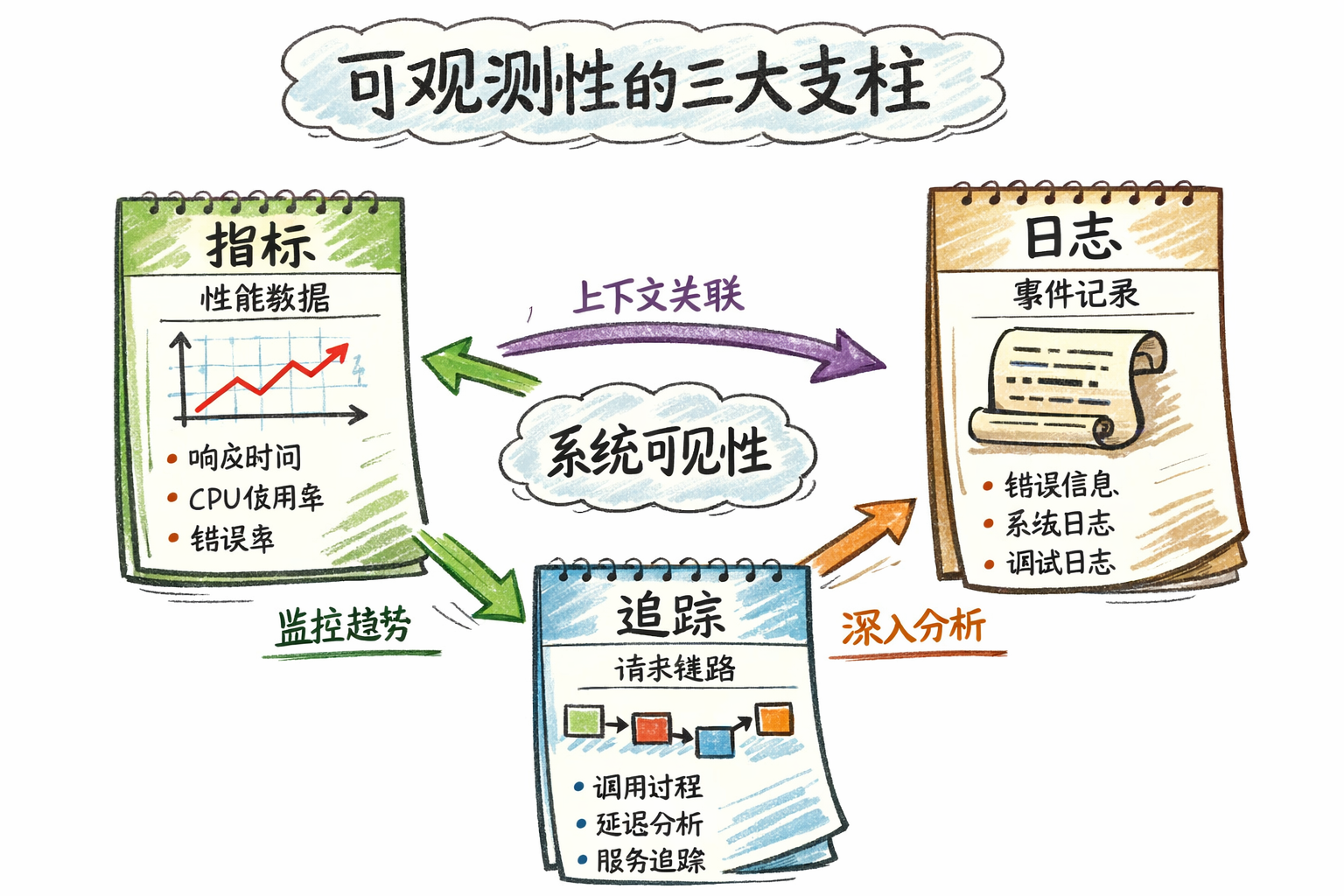
| 支柱 | 作用 | 解决的问题 | 典型工具 |
|---|---|---|---|
| Metrics(指标) | 系统运行状态的整体视图 | "系统现在怎么样?" | Prometheus + Grafana |
| Logs(日志) | 详细的事件记录 | "具体发生了什么?" | Loki / ELK |
| Traces(链路追踪) | 请求的完整调用链 | "请求经过了哪些服务?耗时在哪?" | Tempo / Jaeger / SkyWalking |
三大支柱如何协作?
- Metrics 发现问题:通过仪表盘发现"设备列表接口 P95 延迟飙升至 5 秒"
- Traces 定位瓶颈:通过链路追踪发现"80% 时间花在数据库查询"
- Logs 查看详情:通过日志发现"数据库连接池等待告警,连接数已耗尽"
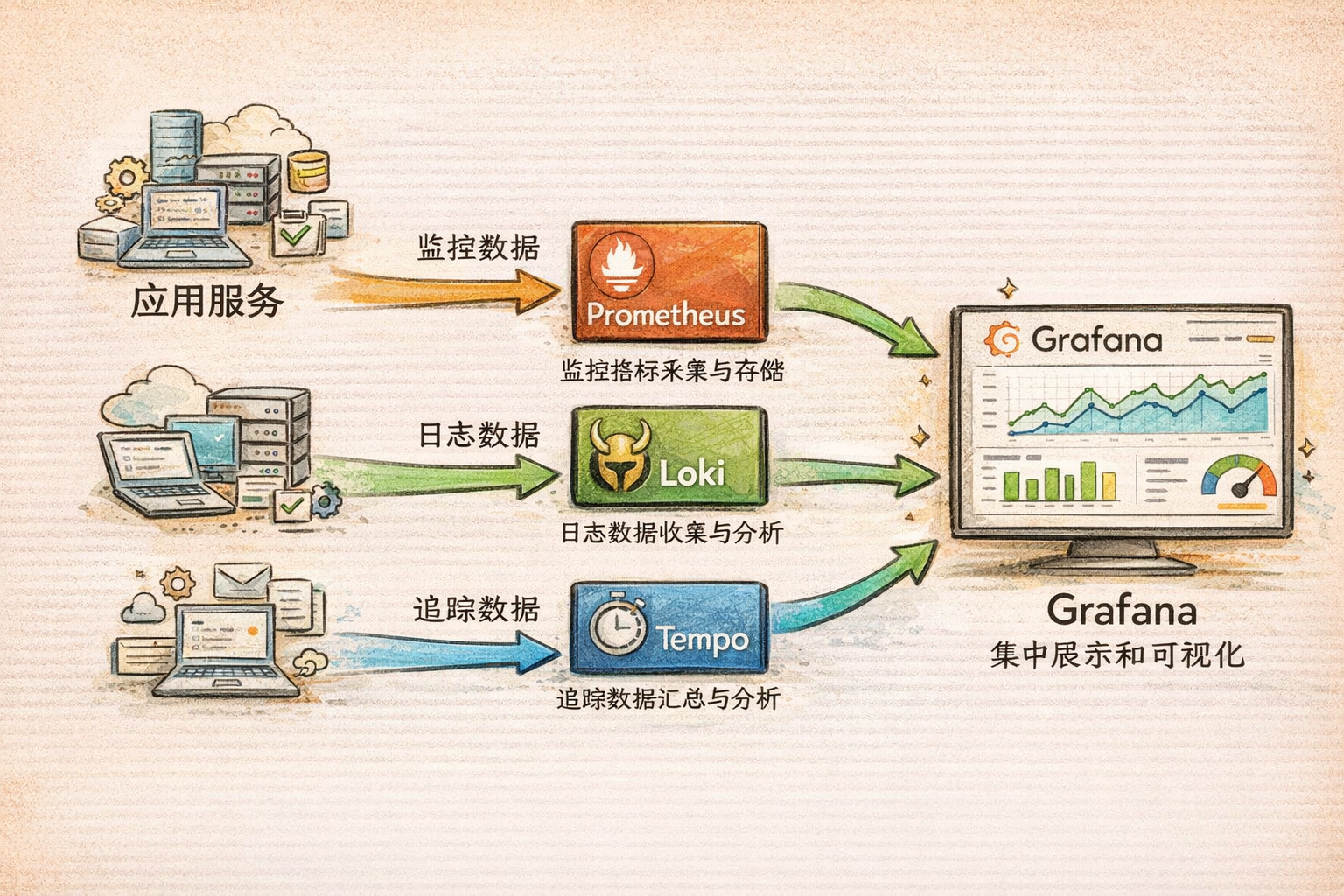
二、LGTM Stack:云原生监控的事实标准
2.1 什么是 LGTM Stack?
LGTM Stack 是目前最流行的开源可观测性解决方案,由四个核心组件组成:
- Loki - 日志聚合系统
- Grafana - 统一可视化平台
- Tempo - 分布式链路追踪
- Prometheus(M) - 指标采集与存储
注意:虽然缩写是 LGTM,但通常按照 Prometheus → Loki → Tempo → Grafana 的顺序学习和使用。
2.2 为什么选择 LGTM Stack?
| 对比项 | LGTM Stack | 传统方案(如 ELK + Zipkin) |
|---|---|---|
| 成本 | 低(资源消耗仅为 ELK 的 10-20%) | 高 |
| 部署复杂度 | 低(云原生设计) | 高 |
| 学习曲线 | 平缓(统一的查询风格) | 陡峭(多种查询语言) |
| 集成性 | 高(Grafana 统一可视化) | 低(多个独立系统) |
| 适用场景 | 云原生、Kubernetes、微服务 | 传统架构 |
三、LGTM 四大组件详解
3.1 Prometheus:指标采集与存储
核心作用
Prometheus 是一个开源的系统监控和告警工具,主要负责采集、存储和查询时间序列指标数据。
工作原理
┌─────────────────┐
│ 应用服务 │ 暴露 /metrics 端点
│ (Spring Boot) │
└────────┬────────┘
│
▼ Pull 模式(每 15 秒)
┌─────────────────┐
│ Prometheus │ 采集并存储指标
└────────┬────────┘
│
▼ PromQL 查询
┌─────────────────┐
│ Grafana │ 可视化展示
└─────────────────┘
关键特性
- Pull 模式采集:Prometheus 主动从目标服务拉取指标(默认 15 秒一次)
- 多维数据模型:通过标签(Labels)实现灵活的维度查询
# 示例:按服务和状态码分组查询请求量 http_requests_total{method="GET", status="200"} - PromQL 查询语言:强大的时序数据查询能力
- 告警管理:基于规则的告警和通知
四大指标类型
| 指标类型 | 特点 | 使用场景 | 示例 |
|---|---|---|---|
| Counter(计数器) | 只增不减 | 累积值(请求总数、错误总数) | http_requests_total |
| Gauge(仪表盘) | 可增可减 | 瞬时值(当前内存、当前连接数) | memory_usage_bytes |
| Histogram(直方图) | 分布统计 | 延迟分布、请求大小分布 | http_request_duration_seconds |
| Summary(摘要) | 分位数统计 | 预计算的分位数 | request_duration_seconds{quantile="0.95"} |
PromQL 常用查询
# 1. 查询最近 5 分钟的请求速率
rate(http_requests_total[5m])
# 2. 查询 P95 延迟
histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m]))
# 3. 查询错误率
sum(rate(http_requests_total{status=~"5.."}[5m]))
/
sum(rate(http_requests_total[5m]))
# 4. 按服务分组查询
sum by (service) (rate(http_requests_total[5m]))
3.2 Loki:轻量级日志聚合
核心作用
Loki 是 Grafana Labs 开源的日志聚合系统,专门用于存储和查询日志。它的设计灵感来自 Prometheus,采用标签(Labels)来索引日志。
与 ELK 的区别
| 对比项 | Loki | ELK (Elasticsearch) |
|---|---|---|
| 存储方式 | 只索引标签,不索引日志内容 | 全文索引 |
| 资源消耗 | 低(仅为 ELK 的 10-20%) | 高 |
| 查询语言 | LogQL(类似 PromQL) | Lucene |
| 适用场景 | 云原生、Kubernetes | 复杂日志分析 |
为什么选择 Loki?
- ✅ 与 Prometheus、Grafana 深度集成
- ✅ 资源消耗低,适合中小规模部署
- ✅ 操作简单,学习曲线平缓
- ✅ 支持多租户隔离
工作原理
┌─────────────────┐
│ 应用服务 │ 输出 JSON 格式日志到 stdout
└────────┬────────┘
│
▼ 采集(Docker 日志驱动 / Promtail)
┌─────────────────┐
│ Loki │ 索引标签,存储日志
└────────┬────────┘
│
▼ LogQL 查询
┌─────────────────┐
│ Grafana │ 可视化展示
└─────────────────┘
LogQL 查询示例
# 1. 查询特定服务的 ERROR 日志
{service="device-service", level="ERROR"}
# 2. 查询包含特定关键字的日志
{service="gateway-service"} |= "timeout"
# 3. 查询特定租户的所有日志
{tenantId="tenant-001"}
# 4. 统计最近 5 分钟的错误日志数量
count_over_time({level="ERROR"}[5m])
# 5. 根据 Trace ID 查询日志
{service="data-service"} |= "trace-id-12345"
3.3 Tempo:高效链路追踪
核心作用
Tempo 是 Grafana Labs 开源的分布式链路追踪后端,用于存储和查询分布式追踪数据。
与 Jaeger/Zipkin 的区别
| 特性 | Tempo | Jaeger | Zipkin |
|---|---|---|---|
| 存储成本 | 极低(仅索引 Trace ID) | 中等 | 中等 |
| 扩展性 | 高(依赖对象存储) | 中等 | 中等 |
| 集成性 | 深度集成 Grafana LGTM | 独立系统 | 独立系统 |
| 协议支持 | OTLP、Jaeger、Zipkin | Jaeger | Zipkin |
为什么选择 Tempo?
- ✅ 存储成本极低(仅索引 Trace ID)
- ✅ 与 Prometheus、Loki 深度集成
- ✅ 支持多种协议(OTLP、Jaeger、Zipkin)
- ✅ 适合云原生环境
工作原理
请求进入 Gateway Service
↓
生成 Trace ID(如 abc123)
↓
调用 Device Service(传播 Trace ID)
↓
Device Service 调用数据库(创建 Span)
↓
所有 Span 发送到 Tempo
↓
Grafana 查询展示完整链路
Trace 结构示例
Trace (Trace ID: abc123)
├── Span 1: HTTP GET /api/devices (Gateway Service) - 150ms
│ ├── Span 2: Database Query (Device Service) - 50ms
│ └── Span 3: Redis Cache (Device Service) - 10ms
└── Span 4: Kafka Publish (Device Service) - 20ms
关键概念:
- Trace ID:整个请求链路的唯一标识
- Span ID:单个操作的唯一标识
- Parent Span ID:父 Span 的 ID(用于构建调用树)
- Duration:操作耗时
TraceQL 查询示例
# 1. 查询特定服务的追踪
{service="gateway-service"}
# 2. 查询耗时超过 1 秒的追踪
{duration > 1s}
# 3. 查询包含错误的追踪
{status=error}
# 4. 根据 Trace ID 查询
{traceId="abc123def456"}
3.4 Grafana:统一可视化平台
核心作用
Grafana 是一个开源的数据可视化和监控平台,它本身不存储数据,而是从各种数据源读取数据进行展示。
主要功能
- 多数据源支持:支持 Prometheus、Loki、Tempo、InfluxDB、Elasticsearch 等 30+ 种数据源
- 丰富的可视化:提供图表、仪表盘、表格、热力图等多种可视化方式
- 告警管理:支持基于指标的告警规则配置和通知
- 仪表盘共享:可以导入/导出仪表盘配置,与团队共享
在 LGTM 中的角色
Grafana 是整个栈的统一入口,用户通过 Grafana:
- 查看 Prometheus 的指标数据
- 查询 Loki 的日志
- 分析 Tempo 的链路追踪
- 配置告警规则
Dashboard 组织建议
📁 项目名称
├── 📊 服务概览(所有服务健康状态、请求量、错误率)
├── 📊 JVM 详情(内存、GC、线程)
├── 📊 数据库监控(连接池、慢查询)
├── 📊 Kafka 监控(消费延迟、吞吐量)
└── 📊 业务指标(设备在线数、消息量)
四、组件协作与数据流转
4.1 三大支柱的协作关系
┌─────────────────────────────────────────────────────┐
│ 用户请求入口 │
└────────────┬────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────┐
│ Gateway Service │
│ • 生成 Trace ID: abc123 │
│ • 记录 HTTP 请求指标(Metrics) │
│ • 输出访问日志(Logs) │
└────────────┬───────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────┐
│ Device Service │
│ • 传播 Trace ID: abc123 │
│ • 记录数据库查询指标(Metrics) │
│ • 输出业务日志(Logs) │
│ • 创建 Span(Database Query - 50ms) │
└────────────┬───────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────┐
│ 数据采集与存储层 │
│ • Prometheus:采集指标数据 │
│ • Loki:采集日志数据 │
│ • Tempo:采集链路追踪数据 │
└────────────┬───────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────┐
│ Grafana 统一可视化 │
│ • 展示指标仪表盘(Metrics) │
│ • 查询和展示日志(Logs) │
│ • 分析链路追踪(Traces) │
│ • 配置告警规则 │
└────────────────────────────────────────────────────┘
4.2 实际应用场景
场景 1:服务故障快速定位
问题:用户反馈"设备列表加载很慢"
排查步骤:
- 查看 Grafana 仪表盘 → 发现 Gateway Service 的 P95 延迟飙升至 5 秒
- 点击延迟图表 → 跳转到 Tempo 链路追踪 → 查看慢请求的 Trace
- 分析 Trace → 发现 80% 的时间花在 Device Service 的数据库查询
- 点击 Span → 跳转到 Loki 日志 → 发现数据库连接池等待告警
- 根因定位:数据库连接池配置过小(最大 10 个连接),已耗尽
解决:调整连接池配置 maximum-pool-size: 20
场景 2:跨服务调用链分析
问题:设备数据上报失败,但不知道哪个环节出错
排查步骤:
- 在 Loki 查询错误日志:
{service="data-service", level="ERROR"} |= "device-data" - 从日志中提取 Trace ID:
traceId: xyz789 - 在 Tempo 查询 Trace → 看到完整调用链:
Gateway (10ms) → Device Service (20ms) → Kafka (5ms) → Data Service (150ms) └── Database Insert (140ms) - 失败 - 点击 Database Span → 查看错误信息:
Duplicate key violation - 根因定位:设备重复上报相同数据,主键冲突
解决:业务逻辑增加幂等性检查
五、OpenTelemetry:统一采集标准
5.1 什么是 OpenTelemetry?
OpenTelemetry 是 CNCF 的顶级项目,目标是统一可观测性的三大支柱(Metrics、Logs、Traces)的采集标准。
5.2 核心组件
- OTLP(OpenTelemetry Protocol):统一的传输协议
- SDK:多语言支持(Java、Go、Python、Node.js 等)
- Collector:数据采集和转发
5.3 为什么强调 OpenTelemetry?
- 避免厂商锁定:采集层标准化,后端可替换(Prometheus、Jaeger、Tempo)
- 跨语言统一:Java、Go、Python 使用相同的协议和标准
- 与 LGTM 兼容:Prometheus 支持 OTLP,Tempo 原生支持 OTLP
- 未来趋势:2026 年已成为 CNCF 活跃度排名前三的项目
5.4 OpenTelemetry 与 LGTM 的关系
┌────────────────────────────────────────────────────┐
│ 应用层(Application) │
│ • OpenTelemetry SDK(Java/Go/Python) │
│ • 统一采集 Metrics、Logs、Traces │
└────────────┬───────────────────────────────────────┘
│
▼ OTLP 协议
┌────────────────────────────────────────────────────┐
│ OpenTelemetry Collector │
│ • 数据接收、处理、转发 │
└────────────┬───────────────────────────────────────┘
│
├─→ Prometheus(Metrics)
├─→ Loki(Logs)
└─→ Tempo(Traces)
六、其他主流监控方案对比
| 方案 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| LGTM Stack | 开源免费、云原生、资源消耗低 | 功能相对简单 | 中小型企业、云原生项目 |
| SkyWalking | 一体化 APM、拓扑分析强大 | 资源消耗较高 | 大型企业、重度 APM 需求 |
| ELK Stack | 日志分析强大、生态成熟 | 成本高、维护复杂 | 日志为主、复杂查询需求 |
| Datadog | 功能全面、开箱即用 | 商业方案、成本高 | 快速上线、预算充足 |
| Zipkin/Jaeger | 追踪功能成熟 | 需要组合其他组件 | 追踪专用场景 |
如何选择?
- ✅ 云原生项目:优先 LGTM Stack
- ✅ 重度 APM 需求:考虑 SkyWalking
- ✅ 快速上线:商业方案 Datadog
- ✅ 预算有限:开源 LGTM Stack
七、开发人员应该掌握到何种程度?
7.1 基础能力(所有开发必备)
Metrics(指标):
- ✅ 理解 Prometheus 的基本概念(指标类型、标签、时间序列)
- ✅ 能够阅读和理解 Grafana Dashboard
- ✅ 能够编写简单的 PromQL 查询(如查询请求量、错误率)
- ✅ 理解指标在故障排查中的作用
Logs(日志):
- ✅ 理解结构化日志的重要性
- ✅ 能够在 Grafana 中查询 Loki 日志
- ✅ 理解 Trace ID 在日志中的作用
- ✅ 能够通过日志快速定位问题
Traces(链路追踪):
- ✅ 理解 Trace ID、Span ID 的基本概念
- ✅ 能够在 Grafana 中查看链路追踪
- ✅ 理解链路追踪在性能分析中的作用
- ✅ 能够通过链路追踪定位慢调用
7.2 应用能力(日常开发需要)
Metrics(指标):
- 🔥 能够为应用添加指标埋点(使用 Micrometer、Prometheus Client 等)
- 🔥 能够设计合理的业务指标(QPS、延迟、错误率)
- 🔥 能够编写复杂的 PromQL 查询(聚合、分组、过滤)
- 🔥 能够设计简单的 Grafana Dashboard
Logs(日志):
- 🔥 能够配置结构化日志输出(JSON 格式)
- 🔥 能够在日志中添加 Trace ID、租户 ID 等标签
- 🔥 能够编写 LogQL 查询(过滤、正则匹配、统计)
- 🔥 能够进行日志脱敏处理
Traces(链路追踪):
- 🔥 能够集成 OpenTelemetry SDK
- 🔥 能够自定义 Span 属性(如租户 ID、设备 ID)
- 🔥 能够分析链路追踪,定位性能瓶颈
- 🔥 能够理解 Trace ID 的传播机制
告警配置:
- 🔥 能够配置基本的告警规则(服务宕机、错误率过高)
- 🔥 理解告警分级(Critical、Warning、Info)
- 🔥 能够避免告警风暴
7.3 架构能力(技术专家/架构师)
架构设计:
- 🚀 能够设计多集群、多数据中心的监控架构
- 🚀 能够评估和选择监控方案(LGTM vs SkyWalking vs Datadog)
- 🚀 能够规划数据保留策略、采样策略、存储成本优化
高可用设计:
- 🚀 Prometheus 高可用(联邦集群、Thanos)
- 🚀 Loki 水平扩展(读写分离、对象存储)
- 🚀 Tempo 分布式部署
平台化能力:
- 🚀 构建统一的可观测性平台
- 🚀 实现"一键接入":应用自动注册到监控系统
- 🚀 多租户隔离、成本分摊
八、学习路径建议
8.1 第一阶段:理解概念(1-2 周)
-
学习可观测性基础
- 理解 Metrics、Logs、Traces 三大支柱
- 了解 Prometheus、Loki、Tempo、Grafana 的作用
-
部署 LGTM Stack
- 使用 Docker Compose 快速部署
- 访问各组件的 Web UI
-
学习基础查询
- PromQL 基础查询(rate、sum、avg)
- LogQL 基础查询(标签过滤、关键字搜索)
- TraceQL 基础查询(按服务、按 Trace ID)
8.2 第二阶段:动手实践(2-4 周)
-
为应用添加监控
- 集成 Spring Boot Actuator + Micrometer
- 添加自定义业务指标
- 配置结构化日志
-
设计 Grafana Dashboard
- 创建服务概览 Dashboard
- 创建 JVM 监控 Dashboard
- 创建业务指标 Dashboard
-
配置告警规则
- 服务宕机告警
- 错误率告警
- 延迟告警
8.3 第三阶段:深入理解(4+ 周)
-
链路追踪集成
- 集成 OpenTelemetry SDK
- 自定义 Span 属性
- 分析链路追踪,定位性能瓶颈
-
性能优化
- 通过指标、日志、追踪快速定位根因
- 优化慢查询、慢调用
-
架构设计
- 学习监控系统高可用架构
- 评估不同监控方案的优劣
九、常见问题(FAQ)
Q1: LGTM Stack 和 ELK Stack 有什么区别?
| 对比项 | LGTM Stack | ELK Stack |
|---|---|---|
| 核心能力 | Metrics + Logs + Traces | 以 Logs 为主 |
| 资源消耗 | 低(仅为 ELK 的 10-20%) | 高 |
| 部署复杂度 | 低 | 高 |
| 查询语言 | PromQL + LogQL + TraceQL(风格统一) | Lucene(仅日志) |
| 适用场景 | 云原生、微服务 | 日志分析为主 |
选择建议:
- ✅ 如果需要完整的可观测性(Metrics + Logs + Traces),选择 LGTM
- ✅ 如果只需要强大的日志分析能力,选择 ELK
Q2: Trace ID 如何在服务间传播?
通过 HTTP Header 传播:
GET /api/devices HTTP/1.1
Host: gateway-service:8080
traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01
- Spring Boot 自动通过
Micrometer Tracing传播 - Kafka 消息通过 Header 携带 Trace ID
- 所有组件(数据库、Redis)自动关联到同一个 Trace
Q3: 生产环境 Trace 采样率应该设置为多少?
建议:
- 生产环境:10% 采样(避免存储成本过高)
- 测试环境:100% 采样(方便调试)
- 错误请求:100% 采样(必须捕获所有错误)
Q4: 如何降低可观测性系统的成本?
- 调整采样率:生产环境 Trace 采样率降至 10%
- 缩短保留时间:日志保留 7 天,链路保留 3 天,指标保留 15 天
- 使用对象存储:Loki 和 Tempo 数据存储在 S3/MinIO
- 聚合指标:只保留关键指标,细粒度指标通过预聚合降低存储
十、总结与展望
10.1 核心要点回顾
1. 可观测性是云原生时代的必备能力
- 传统监控无法应对分布式系统的复杂性
- 三大支柱(Metrics、Logs、Traces)缺一不可
2. LGTM Stack 是当前最优解
- 开源免费、云原生、资源消耗低
- 与 Spring Boot、Kubernetes 深度集成
3. 开发人员能力分级
- 基础能力:理解概念、能够查询和分析
- 应用能力:能够埋点、配置、设计 Dashboard
- 架构能力:能够设计监控架构、评估方案
4. 学习路径清晰
- 从理解概念 → 动手实践 → 深入理解
- 循序渐进,实战驱动
10.2 未来趋势
趋势 1:OpenTelemetry 成为统一标准
- 2026 年已成为 CNCF 活跃度排名前三的项目
- 大厂纷纷从自研方案迁移到 OpenTelemetry
趋势 2:AI 辅助运维(AIOps)
- 通过机器学习自动识别异常模式
- 智能告警聚合,减少告警噪音
- 根因分析自动化
趋势 3:边缘计算监控
- IoT 设备、边缘节点的监控需求增长
- 轻量级 Agent、边缘数据预处理
趋势 4:可观测性平台化
- 统一的可观测性平台(Metrics + Logs + Traces + Events)
- 多租户隔离、成本分摊、自助接入
10.3 下一步建议
对于初学者:
- 立即部署 LGTM Stack(Docker Compose 一键启动)
- 为现有项目添加指标埋点和结构化日志
- 在 Grafana 中创建第一个 Dashboard
对于有经验的开发者:
- 深入学习链路追踪,集成 OpenTelemetry
- 优化告警策略,减少告警噪音
- 探索监控系统高可用架构
对于架构师:
- 评估企业级可观测性方案
- 设计多集群、多数据中心的监控架构
- 探索 AIOps、边缘计算监控等前沿方向
延伸阅读
官方文档:
社区资源:
写在最后:
在云原生时代,可观测性不再是"锦上添花",而是"雪中送炭"。一个优秀的开发,不仅要能写出高质量的代码,更要能让系统"看得见"、"看得清"、"看得懂"。
记住这句话:没有监控的系统,就是在裸奔。
希望这篇文章能帮助你建立起完整的可观测性知识体系,在云原生时代脱颖而出!
欢迎关注公众号 FishTech Notes,一块交流使用心得
