


本文为 《深入理解 Apache DolphinScheduler:从调度原理到 DataOps 实战》 系列专栏第五篇,将以 Apache DolphinScheduler 为例,解析调度系统中的失败重试、手动重跑与补数回填机制,澄清调度语义中的 Exactly Once 含义,并总结常见误用场景与实践建议,帮助构建稳定可靠的数据调度体系。
在数据平台的日常运行中,任务失败几乎是不可避免的。网络抖动、资源不足、下游依赖异常、代码 Bug……都可能导致调度任务执行失败。面对失败,很多团队通常依赖 自动重试、手动重跑或补数回填 来恢复数据。
但一个经常被忽视的问题是:
调度系统中的失败重试、手动重跑与补数回填,其语义其实完全不同。
如果理解不清,很容易导致 重复数据、数据错位甚至数据污染。本文将结合 Apache DolphinScheduler 的设计机制,深入解析调度系统中最常见但也最容易被误解的三种能力:失败重试、手动重跑与补数回填,并进一步探讨 调度系统中 “Exactly Once” 的真实含义。
一、失败重试 vs 手动重跑:两种完全不同的恢复机制
在调度系统中,失败任务通常有两种恢复方式:
- 自动重试(Retry)
- 手动重跑(Rerun)
很多人认为两者只是触发方式不同,但实际上它们在 执行语义 上有本质差异。
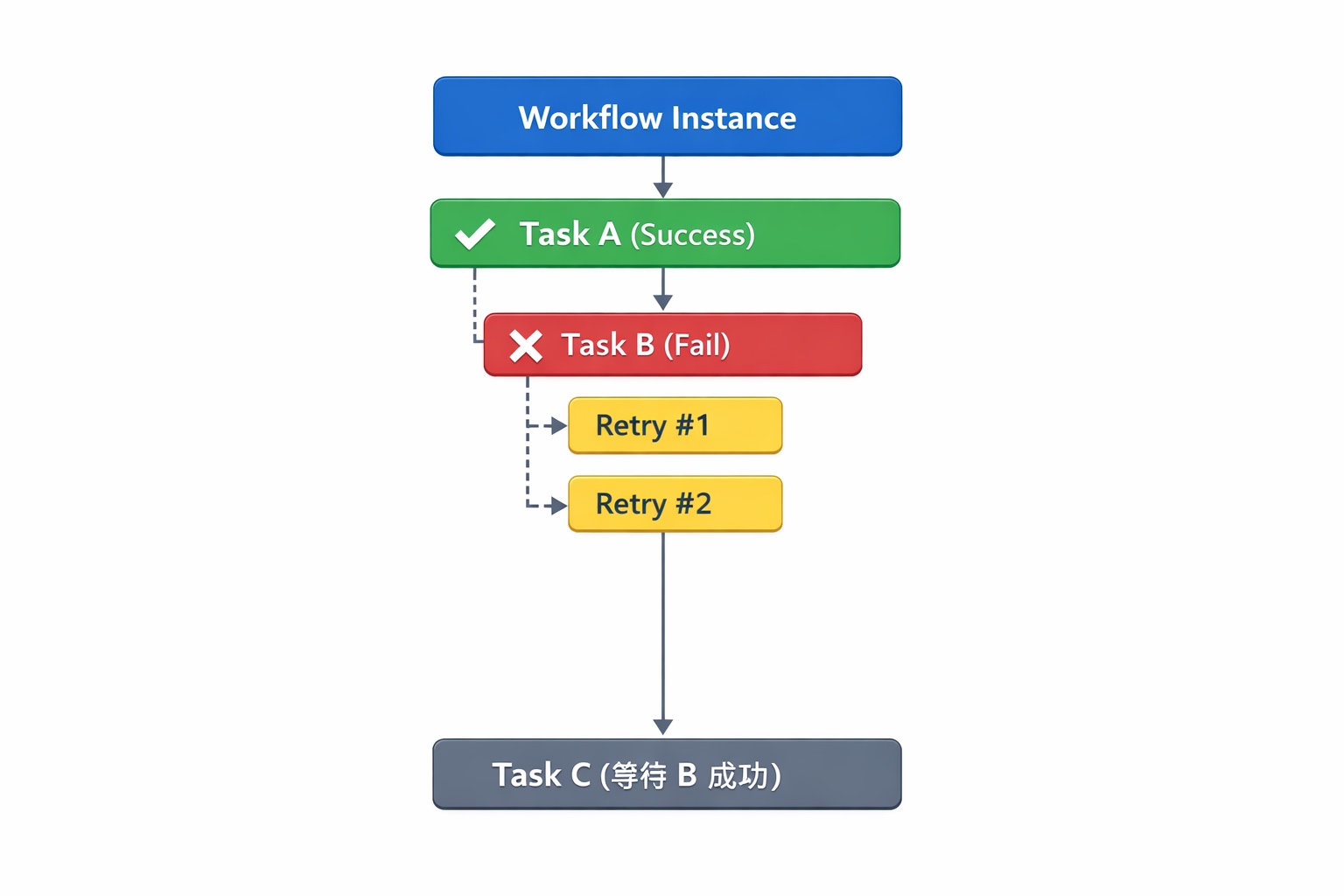
1 自动重试:同一次实例的再次执行
在 Apache DolphinScheduler 中,每一次调度都会生成一个 Workflow Instance(流程实例),实例中包含多个 Task Instance(任务实例)。
当某个任务失败时,如果配置了 Retry Times,系统会在同一个任务实例下触发自动重试。
其特点是:
- 属于同一次工作流实例
- 保持相同的调度时间(Schedule Time)
- 依赖关系不会改变
- 仅重新执行失败任务
执行流程示意:
自动重试的设计目标是:
解决瞬时失败(Transient Failure)
例如:
- 网络波动
- 临时资源不足
- 外部系统短暂不可用
在这种情况下,自动重试通常可以快速恢复任务。
2 手动重跑:创建新的实例
与自动重试不同,手动重跑会生成新的实例。
在 Apache DolphinScheduler 中,用户可以选择:
- 重跑失败节点
- 从当前节点开始重跑
- 从头重跑整个流程
这时系统会生成一个新的 Workflow Instance。
示意:
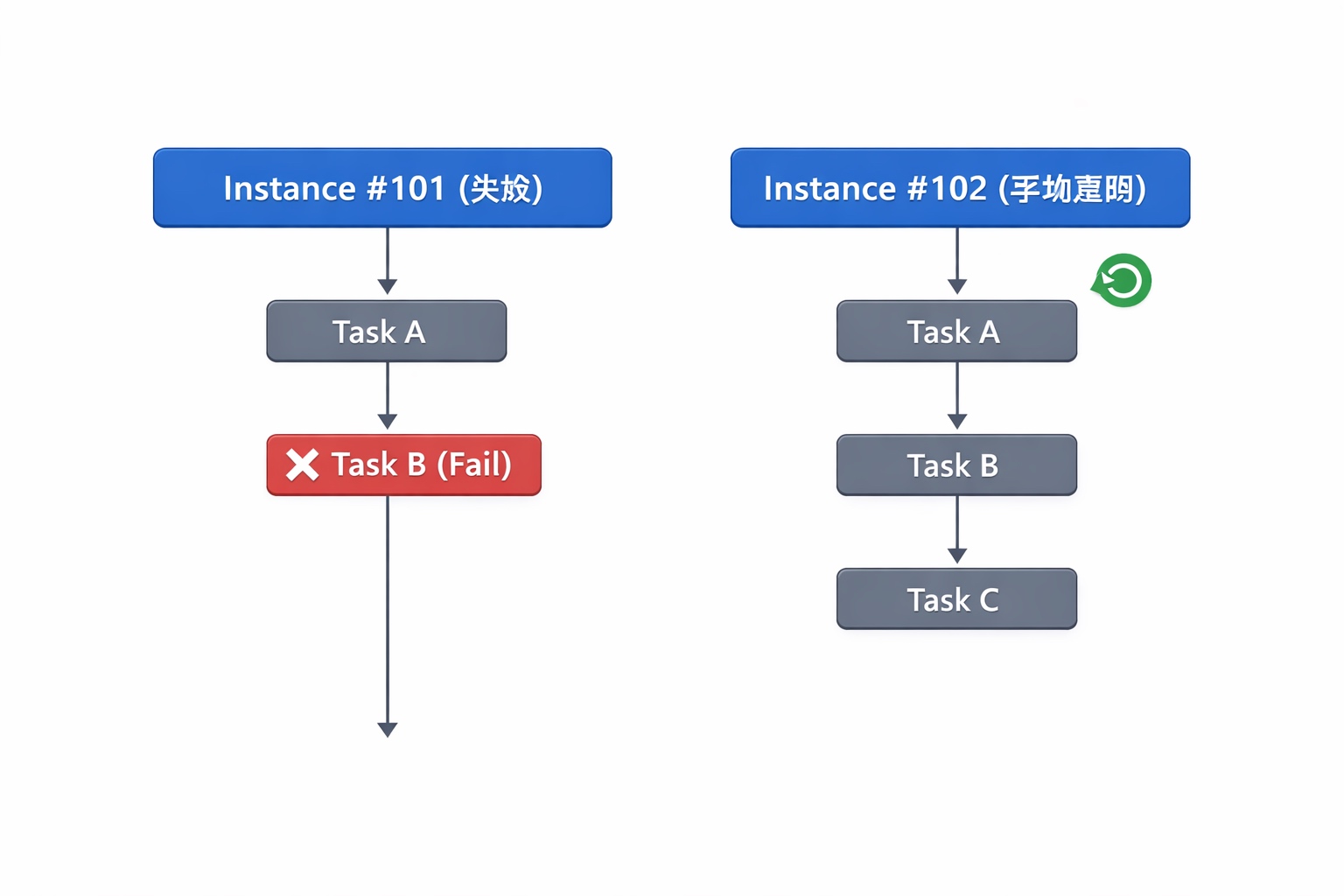
这意味着,两个实例 可能处理同一时间的数据,下游任务 可能重复写入数据。
如果任务不是 幂等(Idempotent) 的,就可能导致 重复数据问题。
二、补数与回填:调度系统中的时间重建
在数据仓库场景中,补数(Backfill)是一项非常常见的操作。例如:
- 新建任务后需要补历史数据
- 某天任务失败,需要补跑
- 上游数据延迟,需要回填
在 Apache DolphinScheduler 中,补数通常通过 Backfill Run 实现。
1 补数的本质:生成多个历史实例
假设一个任务是 每日调度。
补数区间:
2025-03-01 → 2025-03-05
系统会创建多个实例:
Instance (2025-03-01)
Instance (2025-03-02)
Instance (2025-03-03)
Instance (2025-03-04)
Instance (2025-03-05)
每个实例都有:
- 独立执行状态
- 独立依赖关系
- 独立参数
调度时间会被设置为历史时间。
2 补数的关键:调度时间 vs 执行时间
在调度系统中,有两个非常重要的概念:
调度时间(Schedule Time)
数据逻辑时间
执行时间(Execution Time)
任务实际运行时间
例如:
Schedule Time : 2025-03-01
Execution Time: 2025-03-10
如果 SQL 使用的是:
WHERE dt = ${schedule_time}
补数是安全的。
但如果使用:
WHERE dt = today()
补数就会产生 错误数据。
这也是很多数据问题的根源。
三、调度系统中的 Exactly Once:真实含义是什么?
在流处理系统中,例如 Apache Flink,Exactly Once 通常意味着:
每条数据只被处理一次。
但在调度系统中,Exactly Once 的含义完全不同。
调度系统并不能保证任务不会被重复执行,也无法保证数据不会被重复写入。这是因为自动重试可能重复执行,手动重跑可能重复执行,以及补数会重复执行历史逻辑。
因此,调度系统中的 Exactly Once 更接近于:
同一个调度时间只生成一个逻辑实例。
但任务本身仍然可能执行多次。
因此真正的 Exactly Once 需要 任务逻辑保证幂等。
常见实现方式包括:
1 覆盖写入
INSERT OVERWRITE TABLE
2 基于分区写入
partition dt='${schedule_time}'
3 去重写入
MERGE INTO
四、常见误用场景
很多数据事故其实都来自于对调度语义的误解。
1 使用当前时间作为数据日期
错误示例:
dt = today()
正确方式:
dt = ${schedule_time}
2 非幂等写入
例如:
INSERT INTO table
如果任务重跑:
数据会重复
3 手动重跑整个流程
很多用户习惯:
失败 → 从头重跑
但实际上更安全的方式是:
只重跑失败节点
五、最佳实践建议
结合 Apache DolphinScheduler 的使用经验,可以总结出几个重要实践:
1 任务必须设计为幂等
所有任务都应该允许:
重复执行
不会影响数据正确性。
2 数据逻辑必须基于调度时间
避免使用:
now()
today()
统一使用:
${schedule_time}
3 合理使用重试策略
建议配置:
Retry Times: 1~3
Retry Interval: 1~5 min
避免无限重试。
4 补数要控制并发
补数区间过大时:
一次性生成大量实例
可能导致:
- 调度队列阻塞
- 集群资源耗尽
建议:
分批补数
结语
在数据平台中,调度系统往往被认为只是“任务触发器”。但实际上,它承担着 时间管理、依赖控制和故障恢复 的核心职责。
通过理解 失败重试、手动重跑与补数回填 的真实语义,我们才能真正构建 稳定、可靠的数据生产系统。
像 Apache DolphinScheduler 这样的现代调度系统,已经提供了非常完善的机制。但最终决定数据质量的,仍然是:
正确理解调度语义 + 设计幂等的数据任务。
只有这样,数据平台才能在面对失败时依然保持 可恢复、可追溯、可重建。
- 前文回顾: 第 1 篇 | 调度系统,不只是一个“定时器” 第 2 篇|Apache DolphinScheduler 的核心抽象模型 第 3 篇|调度是如何“跑起来”的? [第 4 篇|状态机:调度系统真正的灵魂](mp.weixin.qq.com/s/cAPhDyZS5…
