

开篇:你的声音,正在被"偷走"?
你有没有遇到过这种尴尬场景——
给客户发语音消息,发现自己的声音像刚睡醒的鸭子;做视频配音,找遍全网找不到合适的AI声音;更离谱的是,想克隆自己的声音做播客,结果某收费软件告诉你要先充个年度会员,还要录半小时音频……
😅 咱就是说,2026年了,克隆声音还得这么费劲吗?
今天这个项目,直接让隔壁收费软件连夜改PPT——Fish Speech,GitHub狂揽26.3k Star,号称"开源+闭源里最强的TTS(文本转语音)"。更离谱的是,它完全免费,10秒录音就能克隆声音,还能让你用[laugh]、[whispers]这种聊天语气控制情绪。
基础信息:这玩意儿什么来头?
| 项目 | 详情 |
|---|---|
| ⭐ Star数 | 26.3k(还在疯涨) |
| 🔧 语言 | Python |
| 🏠 团队 | Fish Audio(专注音频AI的团队) |
| 📜 协议 | FISH AUDIO RESEARCH LICENSE(开源可商用,别干坏事) |
| 🚀 热榜 | 常年霸榜GitHub Trending |
简单说,这是一帮技术宅搞出来的"声音复印机",而且印出来的效果——比原声还像原声(不是)。
核心功能:它到底能干嘛?
1️⃣ 10秒克隆,声音"复印"术
传统语音克隆:录30分钟 → 等半天训练 → 效果像机器人。
Fish Speech:扔进去10-30秒录音 → 直接开用。
原理?它用了Dual-Autoregressive架构(双自回归,听着唬人,其实就是分两步走:先抓语义,再补细节),再加上在1000万小时音频上练出来的底子——50种语言,啥口音都见过。
2️⃣ 用"聊天语气"控制AI说话
这是小编最爱的功能!直接在文本里加标签:
"大家好[laugh],今天[whispers]偷偷告诉你们一个秘密[super happy],这个项目真的绝了!"
AI就会:正常说 → 笑一下 → 压低声音窃窃私语 → 超级兴奋地喊出来。
还支持更骚的操作:[professional broadcast tone](播音腔)、[pitch up](升高音调)…… essentially,你给AI写剧本,AI给你演出来。
3️⃣ 多人对话,一键生成
做有声书?做播客?以前要分别生成再剪辑。
现在直接这样写:
<|speaker:0|> 小明:今天天气不错啊
<|speaker:1|> 小红:是啊,适合摸鱼
<|speaker:0|> 小明:嘘,别让老板听见[whispers]
一次生成,多人对话,还能保持每个人声音的一致性。懒人狂喜。
4️⃣ 实时生成,延迟100毫秒
部署到服务器上,配合SGLang推理框架:
- 首包延迟:~100毫秒(人耳几乎无感知)
- 实时率(RTF):0.195(说1秒话,AI只用0.195秒生成)
- 吞吐量:3000+ tokens/秒
啥概念?你打字速度还没AI说话快。
benchmark:数据不会骗人
| 测试项目 | Fish Speech S2 | 对比对手 |
|---|---|---|
| 中文识别错误率(WER) | 0.54% | Qwen3-TTS 0.77%,MiniMax 0.99% |
| 英文识别错误率 | 0.99% | Seed-TTS 2.25%(直接吊打) |
| 图灵测试得分 | 0.515 | 超过人类基准,Seed-TTS才0.417 |
| 新兴TTS评测胜率 | 81.88% | 全场最高 |
翻译成人话:在"这声音是真人还是AI"的测试里,Fish Speech比某些真人还像真人。
怎么用?三种姿势任选
🖥️ 懒人版:WebUI点点点
# 有Docker的同学直接跑
docker pull fishaudio/fish-speech
打开浏览器,上传音频、输入文本、点生成,完事。
文档地址:https://speech.fish.audio/install/
💻 极客版:命令行调用
# 安装
pip install fish-speech
# 命令行推理
# 详见 https://speech.fish.audio/inference/#command-line-inference
🚀 部署版:SGLang服务器
想要高并发、低延迟的生产环境?直接用SGLang部署,继承LLM级别的优化(连续批处理、PagedAttention这些大模型标配)。
SGLang部署文档:https://github.com/sgl-project/sglang-omni/blob/main/sglang_omni/models/fishaudio_s2_pro/README.md
适合谁用?
| 人群 | 使用场景 |
|---|---|
| 🎬 视频创作者 | 配音、多角色对话、情绪化旁白 |
| 🎙️ 播客主播 | 克隆自己声音,批量生成内容 |
| 🎮 游戏开发者 | NPC语音、动态剧情对话 |
| ♿ 无障碍需求者 | 语音合成、辅助阅读 |
| 🤖 AI开发者 | 给LLM Agent加上"嘴",做语音交互 |
| 💼 企业用户 | 客服语音、品牌声音IP化 |
小编锐评
说实话,TTS这赛道卷了这么多年,从最早的"机器人念经"到现在的"以假乱真",Fish Speech算是把开源和好用两个标签同时贴脸上了。
更难得的是,它没搞"开源阉割版、收费完整版"那套——40亿参数的全量模型直接放HuggingFace,论文和技术报告也写得明明白白。这种"我全都要"的态度,在AI圈属实清流。
当然,免责声明还是要念的:别拿它搞诈骗、伪造身份,Fish Audio明确说了会追究违规使用。技术无罪,但用技术的人得有底线。
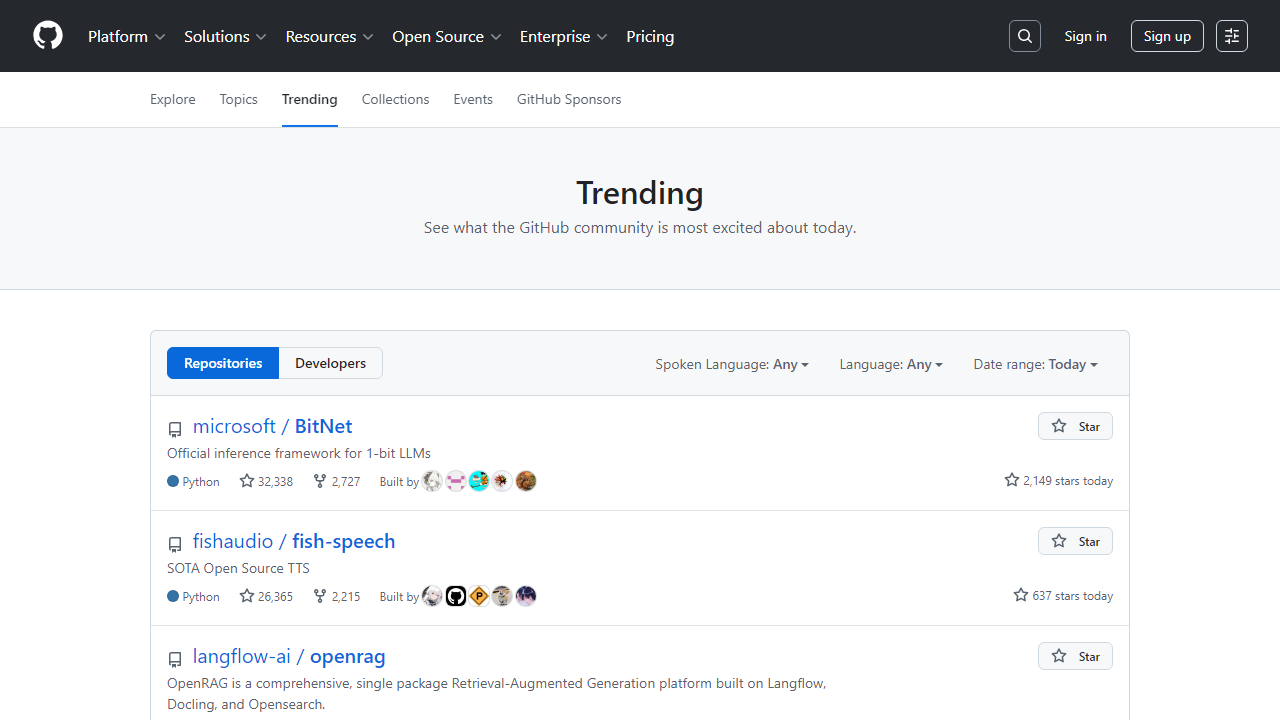
最近这个项目又双叒叕冲上了GitHub热榜,Star数蹭蹭涨。如果你正好需要一个好用、免费、强大的语音合成工具——
别犹豫了,这可能就是2026年最值得收藏的开源项目之一。
📌 项目地址:https://github.com/fishaudio/fish-speech
📌 在线体验:https://fish.audio/
📌 技术报告:https://arxiv.org/abs/2603.08823
本文部分技术细节参考Fish Speech官方README,小编已尽量用人话翻译,如有错误,欢迎评论区拍砖。 🐟
