论文标题:Contrastive Multi-View Representation Learning on Graphs
文章链接:[2006.05582] Contrastive Multi-View Representation Learning on Graphs
文章代码:GitHub - kavehhassani/mvgrl · GitHub
1. 介绍
我们提出了一种通过对比图的结构视图来学习节点和图级别表示的自监督方法。研究表明,与视觉表示学习(计算机视觉)不同,增加视图数量至两个以上、或对比多尺度编码并不能提升模型性能;最佳性能是通过对比来自一阶邻居和图扩散(Graph Diffusion)的编码来实现的。
2. 方法
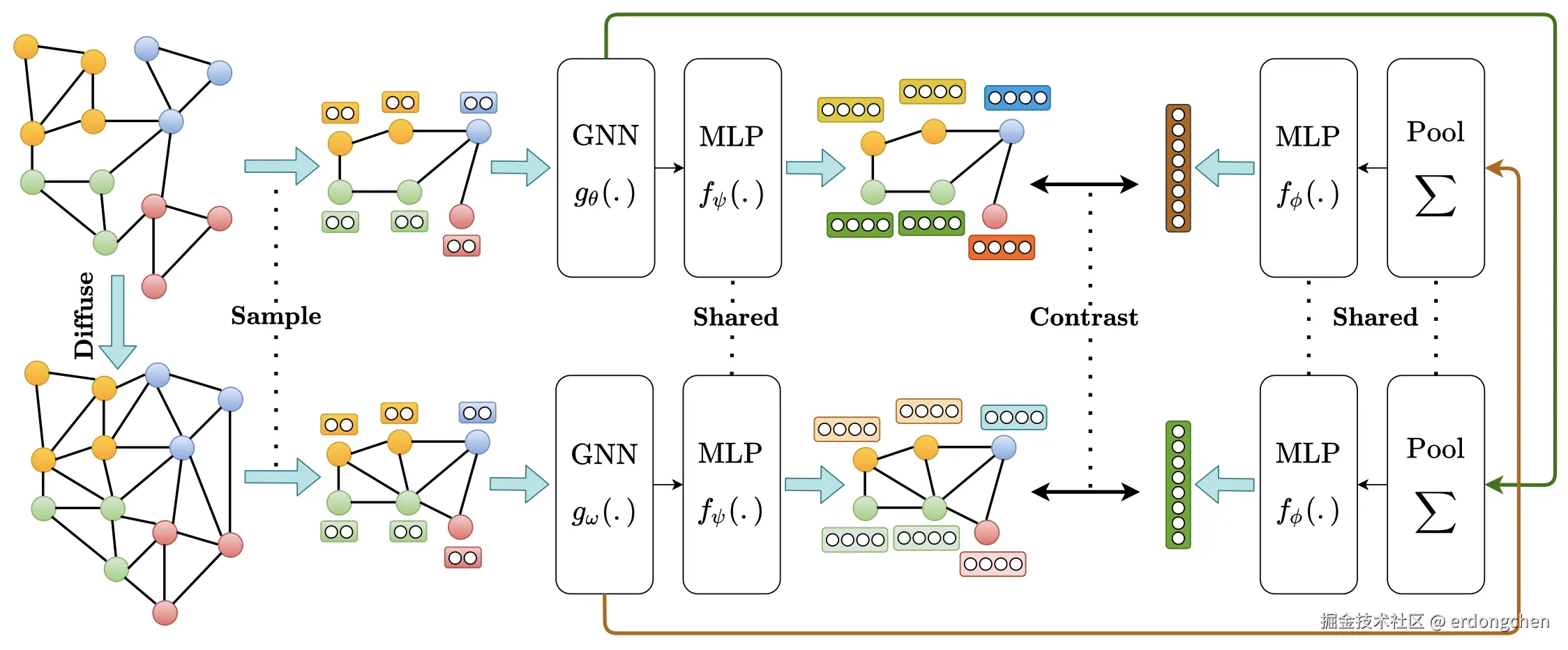
如图 1 所示,我们的方法由以下组件组成:
- 增强机制: 将样本图转换为同一图的相关视图。我们仅对图的结构进行增强,而不改变初始节点特征。随后是一个采样器,对两个视图中的相同节点进行子采样
- 两个专用 GNN(图编码器): 每个视图各一个,随后接一个共享的 MLP(投影头),用于学习两个视图的节点表示。
- 图池化层: 随后接一个共享的 MLP(投影头),用于学习两个视图的图表示。
- 判别器: 将一个视图的节点表示与另一个视图的图表示进行对比,并对它们之间的一致性进行评分。
2.1 数据增强
在大多数情况下,通过将邻接矩阵转换为扩散矩阵,并将这两个矩阵视为同一图结构的两个一致视图,可以获得最佳结果。我们推测,由于邻接矩阵和扩散矩阵分别提供了图结构的局部和全局视角,最大化这两个视图所学表示之间的一致性,使得模型能够同时编码丰富的局部和全局信息。
扩散过程如公式 (1) 所示,其中T∈Rn×n是广义转移矩阵,θ是决定全局与局部信息比例的权重系数。
S=k=0∑∞θkTk∈Rn×n(1)
通过设定参数\theta和T满足下面两个条件,可以保证扩散过程是可收敛的。
- ∑k=0∞θk=1,θk∈[0,1]
- T 的特征值 λi∈[0,1]
本文给出了广义图扩散的两个具体实例:PPR 和 热核 (Heat Kernel) 。
通过分别设置 T=AD−1 以及 θk=α(1−α)k(PPR)或 θk=e−ttk/k!(热核)来定义。其中 α 表示随机游走中的传送概率,t是扩散时间。热核扩散和 PPR 扩散的解析解分别如公式 (2) 和 (3) 所示:
Sheat=exp(−tAD−1−t)(2)SPPR=α(In−(1−α)D−1/2AD−1/2)−1(3)
其中, A∈Rn×n 是邻接矩阵, D∈Rn×n是对角度矩阵。
Heat Kernel: 模拟热量在图上的连续演化,通常能提供更平滑的全局特征。
PPR: 倾向于保留更多的局部结构,α 越大,越不容易“走远”。
对于下采样的方法,我们从一个视图采样节点和它们之间的边,从另一个视图采样同样的相应的节点以及边。
推导公式 (2):热核 (Heat Kernel)
在热核中,权重遵循泊松分布:θk=k!e−ttk,其中 t 是扩散时间。
-
将θk带入公式(1):
Sheat=k=0∑∞θkTk=k=0∑∞k!e−ttkTk=e−tk=0∑∞k!(tT)k
Sheat=exp(tAD−1−tI)
推导公式 (3):Personalized PageRank (PPR)
在 PPR 中,设定权重为几何分布:θk=α(1−α)k,其中α∈(0,1] 是传送概率。
SPPR=k=0∑∞α(1−α)kTk=αk=0∑∞((1−α)T)k
- 利用矩阵几何级数公式: 对于矩阵 M,如果其特征值绝对值小于 1,则有 ∑k=0∞Mk=(I−M)−1。这里 M=(1−α)T。
SPPR=α(I−(1−α)T)−1
2.2 Encoders
本文不限制编码器的选择,在实验阶段本文选择的是图卷积神经网络(GCN)。也就是如图 1 所示的 gθ(⋅),gω(⋅):Rn×dx×Rn×n→Rn×dh,邻接矩阵和扩散矩阵被视为两个结构一致的视图,并分别定义GCN层为 σ(A~XΘ)和 σ(SXΘ),以此学习两组节点表示,每组对应一个视图。
其中,A~=D^−1/2A^D^−1/2∈Rn×n 是对称归一化邻接矩阵,D^∈Rn×n是 A^=A+In的度矩阵(In为单位矩阵),S∈Rn×n是扩散矩阵,X∈Rn×dx 是初始节点特征,Θ∈Rdx×dh 是网络参数,σ 是 PReLU 非线性激活函数。
然后,我们将图卷积编码器学习到的特征表示送入一个共享的投影头fψ(⋅),它是一个带有两个隐藏层和 PReLU 激活的 MLP。最终得到两组分别对应于两个视图的节点表示的集合 Hα,Hβ∈Rn×dh。
对于每个视图,我们使用图池化函数 P(⋅),将GNN学习到的节点表示聚合为图表示(注:这里是没有经过共享MLP处理过得节点表示)。我们使用类似于跳跃连接网络 (JK-Net) 的readout函数。具体过程如下:
- 将每一层
GCN 中的节点向量表示进行加和
- 再将每个
GCN层的加和结果进行拼接
- 将拼接后的结果输入单层前馈网络,以确保节点表示与图表示之间的维度一致:
h~g=σ([∥l=1Li=1∑nh~i(l)]W)∈Rdh(4)
其中 h~i(l) 是节点 i 在第 l层的潜在表示,∥是拼接运算符,L是 GCN层数,W∈R(L×dh)×dh是网络参数,σ是 PReLU激活函数。在实验中这种readout方式被证明比一些比较复杂的readout函数(比如DiffPool)效果要好。
对节点表示应用readout函数会产生两个图表示,如公式(4)所示。随后,这些表示被送入共享投影头 fϕ(⋅),生成最终的图表示:h~gα,h~gβ∈Rdh。
2.3. 训练
为了学习到与下游任务无关的丰富节点及图级别表示,我们利用 Deep InfoMax (DIM) 方法,通过对比一个视图的节点表示与另一个视图的图表示,来最大化两个视图之间的互信息。我们将目标函数定义如下:
θ,ω,ϕ,ψmax∣G∣1g∈G∑∣g∣1i=1∑∣g∣(MI(h~iα,h~gβ)+MI(h~iβ,h~gα))(5)
其中,θ,ω,ϕ,ψ分别是图编码器和投影头的参数;∣G∣ 是训练集中的图数量;∣g∣ 是图 g中的节点数;h~iα 和 h~gβ 分别是从视图 \alpha 和 \beta 编码得到的节点 i 和图 g 的表示。
互信息(MI)由判别器 D(⋅,⋅):Rdh×Rdh→R 进行建模。该判别器接收一个视图的节点表示和另一个视图的图表示,并对它们之间的一致性进行评分。判别器简单地实现为两个表示之间的点积(Dot Product) :D(h~n,h~g)=h~n⋅h~gT。
用来进行对比学习的正样本对是当前图的一个视图的节点表示与当前图的另一个视图的图表示,负样本对是当前图的一个视图的节点表示与其他图的另一个视图的图表示。假设给定一组训练图 G,其中样本图g=(A,X)∈G由邻接矩阵A∈{0,1}n×n和初始节点特征 X∈Rn×dx 组成,我们提出的多视图表示学习算法总结如下:

3. 实验
- 数据集
下表展示了使用的数据集统计情况:
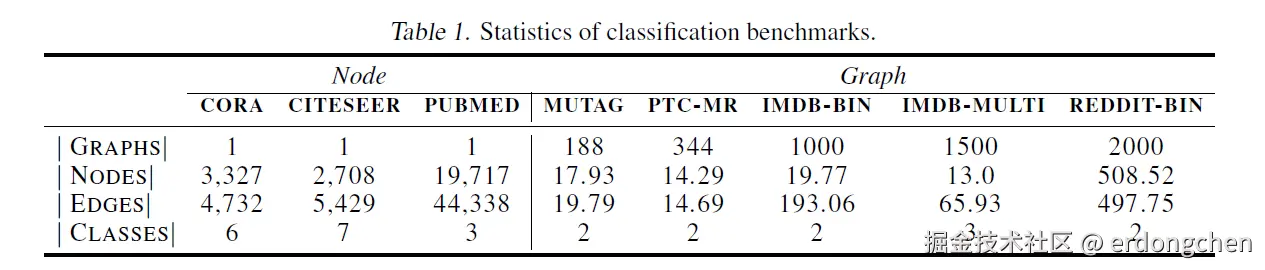
Cora / Citeseer / Pubmed:
- 类型: 引文网络(Citation Networks)。
- 内容: 节点是科学论文,边是论文之间的引用关系。
- 任务: 根据论文的内容(词向量特征)预测其所属的研究领域。
MUTAG:
- 类型: 生物信息学数据集。
- 内容: 节点代表原子,边代表化学键。
- 任务: 预测该分子是否具有致突变性(Mutagenic),常用于化学/药物筛选研究。
PTC (Predictive Toxicology Challenge):
- 类型: 毒理学数据集。
- 内容: 节点代表原子,边代表化学键(分子图)
- 任务: 预测化学物质对实验动物(如雄鼠、雌鼠等)是否具有致癌性。
Reddit-Binary:
- 类型: 社交网络数据集。
- 内容: 节点是 Reddit 用户,如果两个用户在同一个帖子下回复过,则连边。
- 任务: 预测该图属于哪种类型的讨论社区(例如:是关于问答的还是关于讨论的)。这类图通常比分子图大得多,且没有初始节点特征(通常使用节点的度数作为特征)。
- 实验结果
下面的表展示了各类实验的结果:

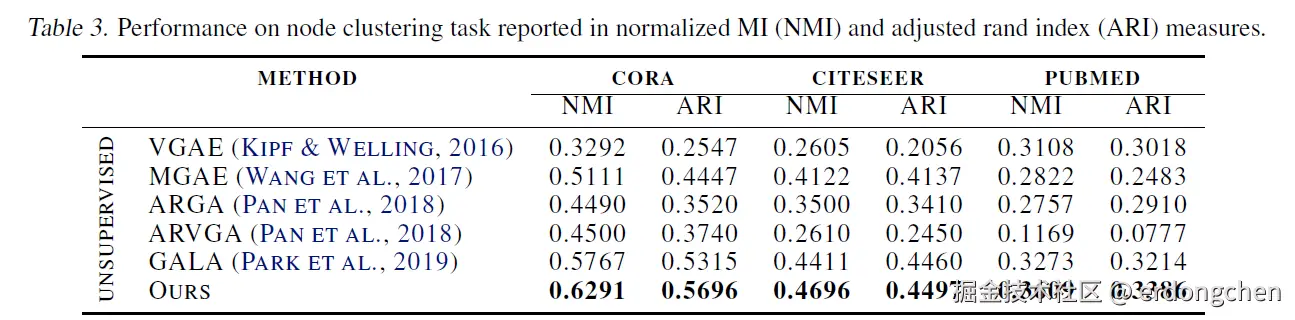

- 消融实验
另外本文进行了一系列消融实验来探索不同的互信息估计器、对比方式以及数据增强方式的影响: