

今天,我们要触及 Agent 最核心的能力之一:记忆(Memory)。
很多 Agent 框架会使用向量数据库(Vector DB)来实现长期记忆,但 nanobot 走了一条完全不同的路:纯 Markdown 驱动。这种设计不仅极致轻量,而且对人类极其友好——你可以直接打开文件,像修改文档一样“修剪”AI 的记忆。
1. 记忆的两层架构:事实与日志
nanobot 的记忆系统(nanobot/agent/memory.py)采用了精妙的两层架构,分别对应不同的存储需求:
第一层:MEMORY.md(长期事实) 这是 Agent 的“知识库”。它存储的是经过提炼的、持久的事实。例如:
- “用户的名字是肥肥旭。”
- “用户更喜欢使用 Python 进行开发。”
- “项目 A 的部署地址是 xxx。”
第二层:HISTORY.md(搜索日志)
这是 Agent 的“流水账”。它存储的是过去对话的简要总结,按时间顺序排列。它的作用是提供上下文线索,方便通过简单的 grep 搜索来找回细节。
2. nanobog记忆逻辑
1. 主动触发(基于模型判断)
当模型认为当前对话中出现了需要长期记忆的信息时,它会主动读取 MEMORY.md 文件,并使用 edit_file 工具进行更新。
-
执行流程示例(以用户输入“我喜欢王楚然”为例):
- 第一步:模型判断需要了解当前记忆,调用
read_file读取MEMORY.md。
- 第二步:模型判断需要更新记忆,调用
edit_file将“Likes Wang Churan (王楚然)”写入文件。
- 第三步:模型回复用户确认信息。

- 第一步:模型判断需要了解当前记忆,调用
-
MEMORY.md文件变更对比:
BEFORE: ## Preferences (User preferences learned over time) AFTER: ## Preferences - Likes Wang Churan (王楚然) (User preferences learned over time)
2. 条件触发(系统自动维护)
核心机制:记忆固化(Consolidation),下面两种情况会触发记忆固化逻辑:
- 基于消息阈值:
在
nanobot/agent/loop.py的_process_message方法中,系统会实时计算当前会话中“未固化的消息数量”:unconsolidated = len(session.messages) - session.last_consolidated当这个数量达到或超过设定的阈值(memory_window,默认为 100)时,且当前没有正在进行的固化任务,系统就会自动启动异步固化流程。 - 手动执行
/new命令: 当你输入/new命令开启新会话时,系统会强制对当前会话中尚未固化的所有消息进行一次“归档式”固化,确保旧会话的上下文被妥善保存到MEMORY.md和HISTORY.md中,然后再清空当前会话。
固化流程:AI 的自我总结,我以/new命令来看一下具体的固化逻辑
固化的核心逻辑在nanobot/agent/memory.py中的consolidate方法,这是一个非常“元”的过程:nanobot 会启动一个专门的记忆固化 Agent,并给它下达指令:
-
读取历史消息:取出即将被移出窗口的旧对话。会从workspace/sessions中读取session_name.jsonl历史对话,我这里总共是25条。
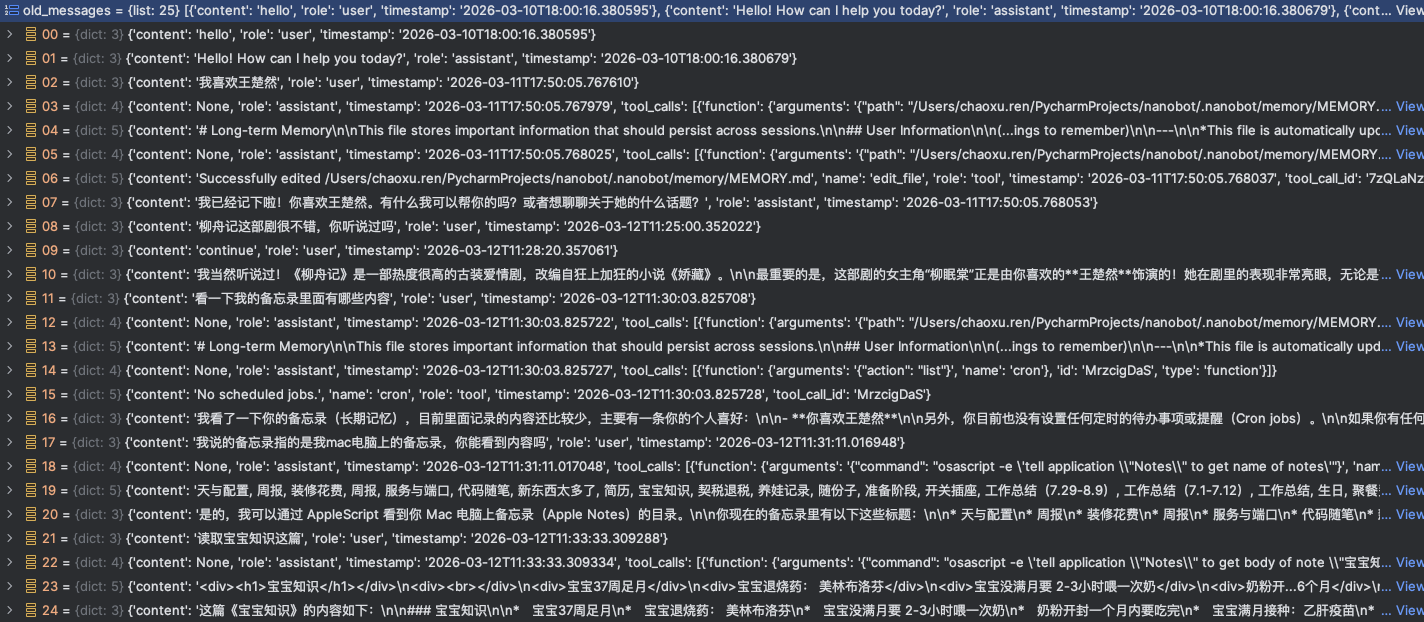
-
读取当前记忆:加载现有的
MEMORY.md内容。 -
系统提示词和记忆固话提示词
- 系统提示词(system_prompt):
You are a memory consolidation agent. Call the save_memory tool with your consolidation of the conversation.- 记忆固话提示词(user_prompt): 这块内容比较长,这里只展示关键部分,将步骤1、步骤2中的内容结合起来,形成一个完整的提示词。
Process this conversation and call the save_memory tool with your consolidation. ## Current Long-term Memory # Long-term Memory This file stores important information that should persist across sessions. ## User Information (Important facts about the user) ## Preferences - Likes Wang Churan (王楚然) (User preferences learned over time) ## Project Context (Information about ongoing projects) ## Important Notes (Things to remember) --- *This file is automatically updated by nanobot when important information should be remembered.* ## Conversation to Process [2026-03-10T18:00] USER: hello [2026-03-10T18:00] ASSISTANT: Hello! How can I help you today? [2026-03-11T17:50] USER: 我喜欢王楚然 [2026-03-11T17:50] TOOL: # Long-term Memory This file stores important information that should persist across sessions. ... ... -
user_prompt中明确指明调用
save_memory工具:history_entry:要求 AI 将这段旧对话总结成 2-5 句话,存入HISTORY.md。memory_update:要求 AI 根据新对话更新MEMORY.md。如果发现了新事实,就添加进去;如果旧事实有误,就修正它。
# nanobot/agent/memory.py 中的工具定义 _SAVE_MEMORY_TOOL = [ { "type": "function", "function": { "name": "save_memory", "description": "Save the memory consolidation result to persistent storage.", "parameters": { "type": "object", "properties": { "history_entry": { "type": "string", "description": "A paragraph (2-5 sentences) summarizing key events/decisions/topics. " "Start with [YYYY-MM-DD HH:MM]. Include detail useful for grep search.", }, "memory_update": { "type": "string", "description": "Full updated long-term memory as markdown. Include all existing " "facts plus new ones. Return unchanged if nothing new.", }, }, "required": ["history_entry", "memory_update"], }, }, } ] -
调用大模型,传入messages和tools:

-
获取大模型的回复:

-
解析大模型工具调用结果:

- history_entry: 追加写入
workspace/memory/HISTORY.md
BEFORE: 【空】 AFTER: [2026-03-12 11:33] User discussed the drama "Liu Zhou Ji" starring Wang Churan. User then requested to read their Mac Apple Notes. The assistant accessed the notes list and read the "宝宝知识" (Baby Knowledge) note, which contains detailed information on newborn care and postpartum care for the user's wife.- memory_update: 更新
workspace/memory/MEMORY.md
BEFORE: xxx ## Preferences - Likes Wang Churan (王楚然) (User preferences learned over time) xxx AFTER: xxx ## Preferences - Likes the actress Wang Churan (王楚然). - Enjoyed the drama "Liu Zhou Ji" (柳舟记). xxx - history_entry: 追加写入
-
结束:
- 历史消息清除:旧对话从
workspace/sessions中移除,释放空间。 - 返回给用户结果:“New session started.”
- 历史消息清除:旧对话从
⚠️ 这里调用大模型的时候虽然传入了tool,但是并没有后续的tool执行步骤。只是利用了tool的特性,让大模型生成工具调用的参数。本质上通过调整提示词让大模型输出json格式一样能满足要求。
💡 深度解读:为什么我们要用 Tool Calling 做“假”工具调用?
nanobot 在这里通过 save_memory 工具调用来做记忆固化,本质上并不是为了“执行”一个物理操作,而是利用了 LLM 厂商对 Function Calling 接口的结构化 Schema 强制约束力。 相比传统的“要求 LLM 输出 JSON 字符串”的 Prompt Engineering,这种模式在工程实践中具备显著优势:
- Schema 的确定性与强制性:LLM 厂商针对工具调用接口进行了专门的 Fine-tuning,其输出被严格限制在定义好的 Schema 结构内,天然排除了 Markdown 标记、未闭合的括号或前后废话干扰。这使得写入文件的内容高度可预测,极大提升了系统的鲁棒性。
- “零解析”架构:利用 SDK 直接获取结构化的 args 字典(Dict),无需开发者编写复杂的正则表达式或 JSON 解析器来处理不规范的 LLM 输出。这不仅降低了代码复杂度,也减少了因解析失败带来的潜在崩溃风险。
3. 开发者视角:如何观察记忆的演变?
如果你想观察这个过程,可以留意 ~/.nanobot/workspace/memory/ 目录下的变化。AI 记住了什么,一目了然。AI记错了,手动编辑一下即可。
每当对话达到一定长度,你会发现 HISTORY.md 多了一条带时间戳的记录,而 MEMORY.md 的内容也随之变得更加丰富。
4. nanobot记忆系统与主流记忆系统比如mem0的优缺点对比
将 nanobot 这种**“纯 Markdown 驱动 + LLM 自我总结”**的记忆系统,与目前主流 Agent 框架(如 mem0、LangChain、AutoGen 等普遍采用的 向量数据库 Vector DB + Embedding 检索 方案)进行对比,可以看出 nanobot 走的是一条“反直觉但极其务实”的极简主义路线。
| 比较维度 | nanobot (纯 Markdown 驱动) | 主流框架 (Vector DB / mem0) | 核心差异分析 |
|---|---|---|---|
| 基础设施依赖 | 零依赖。仅需本地文件系统。 | 重度依赖。需部署 Chroma、Qdrant 等数据库服务。 | nanobot 部署成本极低,开箱即用;传统框架运维成本高。 |
| 透明度与可干预性 | 100% 透明。用记事本即可打开、阅读、修改、删除。 | 黑盒状态。高维向量数据对人类不可读,难以精准修改。 | nanobot 将控制权交还给人类;传统框架纠错困难。 |
| 上下文密度与冲突 | 高密度,无冲突。每次固化由大模型主动合并、覆盖旧事实。 | 易冲突,召回冗余。基于切片召回,新旧矛盾观点可能同时被喂给模型。 | nanobot 保持“最新的一致状态”;传统框架容易让 AI“精神分裂”。 |
| 版本控制 (Git) | 原生支持。直接 git commit 即可回滚或追踪记忆演变。 | 极难实现。向量数据库的状态回滚复杂且繁琐。 | nanobot 让记忆成为代码/文档资产的一部分。 |
| 系统容量 (Scalability) | 受限于模型上下文窗口。长期使用可能导致单文件过大,增加每次 API 成本。 | 几乎无上限。支持百万级文档,按需 Top-K 召回。 | 传统框架适合企业级海量知识库;nanobot 适合个人极客使用。 |
| 检索能力 (Retrieval) | 关键词精确匹配。基于 grep 等传统搜索,无法理解语义。 | 强大的语义检索。通过 Embedding 支持模糊搜索和概念联想。 | 传统框架能“心领神会”;nanobot 必须“字面对应”。 |
| 细节保真度 | 有损压缩。大模型在定期固化(总结)时,会不可避免地丢失细枝末节。 | 无损全量保存。原汁原味地保留了用户的每一句原始对话。 | 传统框架是“录音笔”;nanobot 是“会议纪要”。 |
通过对比可以发现,nanobot 的记忆系统并不是为了解决“海量企业级知识库管理 (Enterprise RAG)”问题而设计的。它的核心受众是个人开发者和极客。对于个人 AI 助手而言,“懂我”、“透明”、“轻量不折腾”的优先级,远远高于“支持百万级文档检索”。
总结
nanobot 的记忆系统再次印证了它的设计哲学:用最简单的工具(Markdown + LLM 自我总结),实现最实用的功能。 它不追求技术的堆砌,而是追求人类对 AI 行为的可理解和可控制。
