

《A surrogate-assisted multi-objective particle swarm optimization of expensive constrained combinatorial optimization problems》
如果把多目标组合优化比作在迷宫里找路,那么“昂贵评估”意味着你每走一步都要付出很高代价,“约束”意味着很多路根本不能走,而“离散变量”则意味着你不能沿着光滑曲面滑行,只能一格一格跳着前进。Gu 等人在这篇论文里做的事,就是请来一个并不完美、但足够便宜的向导——随机森林;再配上一支更会判断方向的搜索队——改进的多目标粒子群;最后给这支队伍补上约束边界修正与离散状态更新两套规矩。结果是,路走得更少了,方向却更准了。
摘要:
这篇论文面向“评估代价高、变量离散、还带约束”的多目标组合优化问题,提出了一个随机森林(Random Forest, RF)辅助的多目标粒子群优化(Multi-Objective Particle Swarm Optimization, MOPSO)算法 RFMOPSO;它通过代理模型(Surrogate Model)降低精确评估次数,通过自适应随机排序(Adaptive Stochastic Ranking)平衡“目标更优”与“解可行”,并通过离散粒子状态更新策略改善搜索方向,最终在多目标背包问题(Multi-Objective Knapsack Problem, MOKP)基准上取得了较好的收敛性与效率。
一、论文基本信息
论文标题:A surrogate-assisted multi-objective particle swarm optimization of expensive constrained combinatorial optimization problems
作者:Qinghua Gu,Qian Wang,Xuexian Li,Xinhong Li;主要来自西安建筑科技大学(Xi’an University of Architecture and Technology)相关院系与实验室。
出处:Knowledge-Based Systems,2021,223:107049。
DOI/链接:10.1016/j.knosys.2021.107049
原文链接:doi.org/10.1016/j.k…
二、研究背景与动机
这篇文章讨论的问题,并不只是“组合优化”这么简单,而是昂贵约束多目标组合优化。所谓“昂贵”(Expensive),意思是一次真实评估就可能对应一次物理实验、一次高成本仿真,或者一次难以并行的大规模数值计算;所谓“组合优化”(Combinatorial Optimization),意思是决策变量往往是离散的,例如 0-1 选择、排序、分配、装配;所谓“约束多目标”,则意味着研究者不仅要同时优化多个彼此冲突的目标,还要满足可行性约束。把这三件事叠加在一起,问题立刻就从“难”变成了“非常难”。 从工程视角看,这类问题并不罕见。背包问题(Knapsack Problem)、车辆路径问题(Vehicle Routing Problem)、作业车间调度(Job-shop Scheduling Problem)这些经典对象,往往都可以落入这一框架。真正麻烦之处在于:许多现有多目标进化算法(Multi-Objective Evolutionary Algorithms, MOEAs)默认目标函数和约束函数要么显式可写、要么廉价可算,而现实世界偏偏经常不是这样。 作者抓住了两个关键痛点。第一,约束处理并不容易。传统罚函数(Penalty Function)方法虽然朴素,但罚参数高度依赖问题本身,调不好就会把搜索引向歧途。第二,搜索机制也并不容易。离散、多目标、昂贵评估三者叠加以后,既要避免盲目精确计算,又要防止代理模型把算法带偏,这对优化器本身提出了更苛刻的要求。 已有代理辅助进化算法(Surrogate-Assisted Evolutionary Algorithm, SAEA)大多集中在连续、无约束问题上;即便有一些工作开始触及离散问题,往往也还是直接拿连续代理模型去近似离散结构,针对性不足。作者因此提出:既然随机森林天然适合处理离散变量,为什么不把它和多目标粒子群结合起来,再为“约束判别”和“粒子更新”各补上一块更合适的机制?这就是本文的动机所在。
三、核心方法与创新点
3.1 核心思想
这篇论文的中心思想其实很清楚:用随机森林替代大量昂贵的真实评估,用粒子群优化维持较强的全局搜索能力,再用专门为约束和离散变量设计的策略,把“代理误差”与“离散搜索”这两个老大难问题压住。 从结构上看,RFMOPSO 由三层组成。第一层是随机森林代理模型,分别近似每个目标和每个约束;第二层是多目标粒子群优化器,负责在代理空间里推进搜索;第三层是两项关键修正:其一是逻辑回归(Logistic Regression)+ 自适应随机排序做约束处理,其二是自适应状态更新策略,把连续 PSO 的速度-位置思想,改造成适合 0-1 离散变量的更新规则。
3.2 图 1:粒子“飞行”机制的直观含义
在进入作者的改进之前,先看标准粒子群优化(Particle Swarm Optimization, PSO)的思想。PSO 的经典图景并不复杂:粒子一方面受自身历史最好位置影响,另一方面受群体最好位置吸引,于是会在“个体认知”(Individual Cognition)与“社会交互”(Social Interaction)之间不断折中。
图 1:粒子的飞行模式(The flight mode of the particles)。图中展示了当前位置、速度影响、个体最优、群体最优与更新方向之间的关系。
这张图的意义在于提醒我们:PSO 的精髓从来不是“随机乱飞”,而是“带记忆的受引导搜索”。本文后面的改进,基本都围绕着如何在离散空间里保留这种“受引导性”。
3.3 问题形式化
作者讨论的是一般形式的约束多目标组合优化问题,可以写成:
其中,(x) 是由离散、有限元素组成的决策向量。因为多个目标通常彼此冲突,所以并不存在一个在所有目标上同时最优的单点解;我们真正追求的是帕累托解集(Pareto Set, PS)及其对应的帕累托前沿(Pareto Front, PF)。
3.4 创新点一:用随机森林做代理模型
作者选择随机森林(Random Forest, RF)而不是克里金(Kriging)、径向基函数网络(Radial Basis Function Network, RBFN)或神经网络(Artificial Neural Network, ANN),判断是有道理的。原因不在于随机森林“更高级”,而在于它更贴合离散变量的结构特征。树模型对 0-1 变量、分段规则和非线性交互的表达往往更自然,这比把离散空间硬塞进连续回归框架里要踏实得多。
图 2:随机森林的生成过程(The generation process of the random forest)。
图中展示了作者的代理思路:从训练样本中自助采样(Bootstrap Sampling),构造多棵分类与回归树(Classification and Regression Tree, CART),最终取多个树输出的平均作为预测结果。对于本文问题,作者为每个目标和每个约束分别训练一个随机森林,因此总共需要构造 (m+c) 个代理模型。
这一步的价值非常直接:把昂贵真实评估,替换成便宜得多的近似评估。但作者也很清楚,代理模型不可能没有误差,因此他们进一步利用均方根误差(Root Mean Square Error, RMSE)去修正由代理预测得到的目标值。若记第 (j) 个目标上的 RMSE 为 (e_j),则最小化问题中的预测值会被向“更保守”的方向修正,以降低误判风险。
3.5 创新点二:逻辑回归修正约束边界
代理模型最容易犯错的地方,往往不是显然可行或显然不可行的区域,而是可行边界附近。这正是本文处理约束的第一处亮点:作者没有简单依赖代理给出的约束值 (g_i(x)),而是再用逻辑回归(Logistic Regression)去估计一个候选解“成为可行解的概率”。 其形式为:
当预测可行概率达到阈值(文中取 0.95)时,作者会据此修正约束边界,把原来 (g_i(x)\le 0) 的判别,调整成 (g_i(x)\le \theta_i)。这一步看似只是“边界平移”,本质上却是在说:代理模型对于约束的判断不值得被完全相信,尤其是靠近边界时,必须做统计校正。 这一点很重要。很多代理优化算法失败,不是因为优化器太弱,而是因为它们把代理输出当成了事实。本文至少在约束问题上,保留了一种必要的怀疑精神。
3.6 创新点三:自适应随机排序
标准随机排序(Stochastic Ranking, SR)的核心思想,是在比较两个解时,以某个概率选择“按目标优劣排”,以另一个概率选择“按约束违背程度排”。它的优点在于避免了罚函数的繁琐调参,但它的问题同样明显:那个概率若是固定的,就难以适应不同搜索阶段。 作者的改进,是把原先固定的可行性排序概率 (P_f) 改为随个体状态动态变化的值:
这里,(FV(i)) 表示个体的约束违反程度,(FC) 表示经逻辑回归校正得到的可行性修正量。直觉上说,违反约束越严重,算法就越应该按“约束”来排;而如果一个解只是轻微触碰边界,过早把它扔掉,反而可能损失潜在优解。 这一步的思想并不花哨,但很扎实:不要把“目标优化”和“约束满足”当成静态二选一,而要把它们视作搜索过程中的动态权衡。
3.7 创新点四:离散粒子的自适应状态更新
标准 PSO 的位置更新是连续的,但本文面对的是 0-1 组合变量,不能直接照搬。因此作者引入了一个基于速度的概率映射,把速度先通过 Sigmoid 函数转成取 1 的概率,再据此更新粒子状态:
如果映射值靠近 1,则对应位置更可能变成 1;如果靠近 0,则更可能变成 0;如果恰在中间,则再借助随机数打破平局。这样的更新机制,本质上把“连续速度”变成了“离散选择倾向”,既保留了 PSO 的记忆和引导,又避免了将离散变量粗暴连续化。
图 3:随机森林辅助自适应多目标粒子群优化(RFMOPSO)流程图(Flowchart of the RFMOPSO algorithm)。
这张图是全文最重要的结构图。它清楚展示了算法主循环:初始化训练数据 → 构建目标/约束代理模型 → 代理评估粒子 → 逻辑回归做约束校正 → 自适应随机排序选父代 → 更新个体最优与全局最优 → 用自适应状态更新、交叉与变异产生新解 → 再用模型管理策略更新代理。换句话说,RFMOPSO 不是一个单点改进,而是一套彼此配合的系统工程。
四、实验与结果分析
4.1 数据集与实验设置
作者使用了 10 个多目标背包问题(MOKP)实例,决策变量规模从 10 到 100 不等,目标数为 2 或 3。背包问题模型写成:
其中,(w_i) 是物品重量,(v_i^j) 是第 (i) 个物品在第 (j) 个目标上的价值,(W) 是背包容量。作者假设每次精确评估都很昂贵,因此把“总精确评估次数”视作主要计算预算。
4.2 表 1:参数设置
实验参数并不复杂,但很关键。作者设置种群规模为 100,最大精确评估次数为 2000,其中前 1000 次用于建模,后 1000 次用于优化;交叉概率为 1,变异概率为 0.4,随机森林每个模型使用 100 棵 CART。 表 1:RFMOPSO 的参数设置(The parameter settings of RFMOPSO)。
| Parameters | Definition | Value |
|---|---|---|
| (N_p) | Population size | 100 |
| (P_c) | Cross probability | 1 |
| (P_m) | Mutation probability | 0.4 |
| (P_\theta) | Feasibility probability | 0.95 |
| (k) | The number of CARTs | 100 |
| (t) | Splitting tolerance of CARTs | (1e^{-4}\ast \sigma^2) |
| (EF_{max}) | Maximum exact evaluations | 2000 |
从这里可以看出,作者刻意把总体预算控制得比较紧,这对于代理优化研究是合理的:如果精确评估可以无限做,那么代理模型也就没什么存在意义了。
4.3 基线模型
作者选取了两类基线。第一类是通用多目标进化算法(MOEAs),包括 MOPSO、NSGA-II(Non-dominated Sorting Genetic Algorithm II)和 MOEA/D(Multi-Objective Evolutionary Algorithm based on Decomposition);第二类是已有的随机森林辅助方法 RFCMOCO。这样的比较设置是合理的,因为它既考察“代理辅助是否有必要”,也考察“本文改进是否优于同类代理方法”。
4.4 自适应随机排序是否真的有用?
这篇论文最先验证的,不是整个算法,而是其中一块关键部件:自适应随机排序。我很赞成这种做法。把系统拆开来做消融(Ablation),比只报总成绩更有说服力。
图 4:在一个 3 目标、20 物品的 MOKP 实例上,两种排序策略的平均选择准确率(Average selection accuracy of the two different ranking strategies)。
从图中可以看到,无论代理模型使用 1000 个还是 1500 个随机样本训练,自适应随机排序的曲线都明显高于原始随机排序,尤其在中后期提升更明显。作者据此指出,选择准确率最高可提升到约 85%。这说明动态概率机制确实更善于处理“约束/目标如何平衡”的问题。
值得注意的是,训练样本从 1000 增加到 1500 后,排序效果又有所提升。这一结果并不意外:代理模型更准,排序当然更稳。但它也提醒我们,本文性能的一部分,仍然是建立在足够好的代理建模之上的。
4.5 自适应状态更新是否真的有用?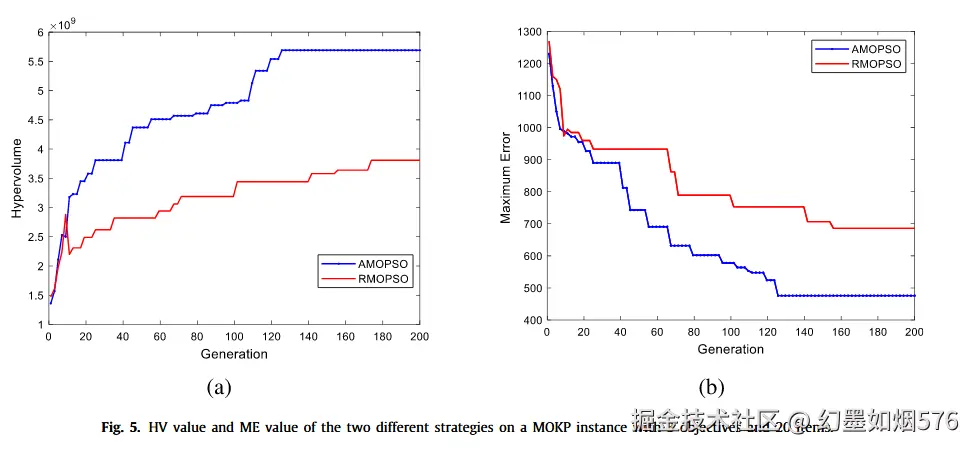
图 5:两种状态更新策略在超体积(Hypervolume, HV)与最大误差(Maximum Error, ME)指标上的表现(HV value and ME value of the two different strategies)。
作者把带有自适应位置更新的 AMOPSO 与随机位置更新的 RMOPSO 进行比较。结果是:在早期两者差距不大,但从大约第 20 代开始,AMOPSO 在 HV 和 ME 两项指标上都逐渐拉开差距。换言之,本文提出的离散状态更新机制并不是一个装饰性的改写,而是真的提升了粒子的搜索引导质量。
这个结果的解释也符合直觉:离散空间里的粒子若没有合理的状态更新规则,很容易退化为“带惯性的随机翻转”;而一旦更新机制能够更精确地将速度映射到位置选择,搜索过程就会更像真正的优化,而不是受噪声驱动的游走。
4.6 总体结果:RFMOPSO 到底强在哪里?
表 2:RFMOPSO、RFCMOCO、MOPSO、NSGA-II、MOEA/D 在各 MOKP 实例上的 HV 值。
从作者的统计看,RFMOPSO 在 10 个实例中有 7 个取得最优 HV,RFCMOCO 在其余 3 个实例中领先。对一篇新算法论文而言,这样的结果是相当像样的:它并非“全盘碾压”,但优势已经足够稳定,且并不局限于单一规模。
图 6:所有算法在 2 目标或 3 目标 MOKP 上的 HV 值(The HV values for all the algorithms)。
图 6 的信息很清楚:代理辅助算法整体上优于不带代理的基础进化算法,说明在昂贵评估条件下,引入代理建模是值得的;而在代理辅助方法之间,RFMOPSO 又优于 RFCMOCO,说明本文的优化器设计和约束处理策略并非可有可无。
另外,作者也指出,在传统 MOEAs 中,NSGA-II 通常优于 MOPSO,而 MOEA/D 在这类离散受约束问题上表现最弱。这并不奇怪。MOEA/D 更依赖分解权重在目标空间中的均匀性,但面对复杂可行域与离散结构时,这种优势不一定能兑现。
表 3:RFMOPSO、RFCMOCO、MOPSO、NSGA-II、MOEA/D 在各 MOKP 实例上的 IGD(Inverted Generational Distance)值。
IGD 越小越好。从表 3 看,RFMOPSO 在 10 个实例中的 7 个上取得最优,RFCMOCO 在另外 3 个上领先。这个结果与 HV 的结论基本一致,说明算法优势并不是某个单一指标下的偶然现象。
图 7:所有算法在 2 目标或 3 目标 MOKP 上的 IGD 值(The IGD values for all the algorithms)。
从趋势图看,随着决策变量数量增加,所有算法的 IGD 都会上升,但 RFMOPSO 上升得最慢,这说明它在问题规模扩大时仍保留了更好的逼近能力。这一点尤其重要,因为小规模问题上的漂亮结果,往往在稍大规模下就会破功;而本文的优势恰恰是在规模变大后更加明显。
表 4:RFMOPSO、RFCMOCO、MOPSO、NSGA-II、MOEA/D 在各 MOKP 实例上的 ME(Maximum Error)值。
ME 指标反映与参考解集之间的最大偏差。从表 4 可以看出,RFMOPSO 相比 RFCMOCO 通常略优,而相较三种通用 MOEAs 的优势更明显。作者也坦率指出,在 10–30 个决策变量的小规模实例上,这种优势并不算特别大;真正的差距是在问题规模扩大后逐步显现出来的。这个结论是可信的,因为“代理+快速收敛”的协同效应,往往需要更复杂的问题才能充分显现。
4.7 运行时间:性能提升是否靠“更慢”换来的?
表 5:RFMOPSO 与 RFCMOCO 的 HV 和运行时间对比(The HV and Running Time values of RFMOPSO and RFCMOCO)。
这张表非常关键。很多代理优化论文的尴尬之处在于,它们确实优化得更好,但代价是算法本身更复杂、总时间反而更高。本文的结果则较为讨喜:RFMOPSO 在多数基准上不但解更好,而且耗时更少。
图 8:两种代理辅助进化算法(SAEAs)在 2 目标或 3 目标 MOKP 上的运行时间(Runtime of the two SAEAs on MOKPs with 2 or 3 objectives)。
图中显示,RFMOPSO 通常比 RFCMOCO 更快收敛。作者特别提到,在一个 10 个物品、3 个目标的小实例上,RFMOPSO 的总运行时间甚至会更长;但这是因为它在 30 代左右就已经接近最优,却仍然被统一跑满了 100 代。也就是说,那里的“更慢”并不是算法本身低效,而是实验协议下的表面现象。
五、论文贡献
如果要把这篇论文的贡献压缩成三句话,那么我会这样概括。
第一,它把随机森林(RF)真正放到了一个离散、受约束、昂贵评估的多目标优化框架里,而不是把连续代理模型生硬挪用到组合问题上。 第二,它没有停留在“代理 + 优化器”的简单拼接,而是认真处理了代理辅助算法最容易失真的两个地方:约束边界与离散状态更新。逻辑回归修正边界,自适应随机排序处理可行性权衡,这两步都不是噱头,而是切中要害。 第三,它的实验呈现出一种相对可信的节制:没有声称在所有场景下都压倒性领先,也没有回避小规模问题上的优势有限;恰恰相反,作者展示的是一种更值得相信的叙事——在问题复杂度真正上来之后,RFMOPSO 的结构性优势才逐渐显现。
六、个人思考
这篇文章给我最大的启发,不在于“随机森林 + 粒子群”这个组合本身,而在于它体现了一种正确的方法论:当问题是离散的,就不要假装它是连续的;当代理模型是不可靠的,就不要假装它是真实函数;当约束边界最脆弱,就应该把力气花在边界上。 这三点,恰恰是很多代理优化工作最容易偷懒的地方。 当然,这篇论文也并非没有可以继续推进之处。首先,实验对象主要还是 MOKP 基准,虽然足以说明方法有效,但离真实工业问题还有一步距离。若能在更具结构性的实际场景——例如调度、路径规划、资源配置——上给出验证,结论会更硬。其次,随机森林虽然适合离散变量,但其不确定性表达能力仍然比较粗糙;若未来能结合更明确的代理不确定性度量(Uncertainty Quantification),模型管理策略可能会更稳健。再者,当前的对比对象虽然合理,但若能补充与更多现代离散代理优化方法的比较,论文的说服力还会更强。 但即便如此,我仍然愿意给这篇文章一个相当正面的评价。它没有发明一个华而不实的宏大框架,而是认真地把三个小而关键的问题——代理选择、约束处理、离散更新——一一补齐。对于优化研究而言,这往往比空泛地喊“统一框架”更可贵。真正推动算法前进的,常常不是壮丽的口号,而是这些看上去不那么耀眼、却恰好卡在瓶颈处的改进。
