

哈喽,掘金的同学们大家好!👋 我是你们的 AI 领路人。
今天我们要搞点好玩的!咱们不聊枯燥的理论,直接以此生最爱的武侠小说 《天龙八部》 为例,带大家从零开始,手搓一个 RAG(Retrieval-Augmented Generation,检索增强生成) 应用。
想象一下,你有一个 AI 助手,它不仅懂聊天,还熟读金庸先生的《天龙八部》,无论是“段誉的凌波微步怎么走?”,还是“乔峰的降龙十八掌有几招?”,它都能基于原著给你最精准的回答。是不是很酷?😎
这就是 RAG 的魅力:给大模型外挂一个“知识库”,让它从“一本正经胡说八道”变成“引经据典的博学大师”。
废话不多说,咱们开整!🚀
📚 第一章:心法总纲 —— RAG 的修炼路径
在开始写代码(练招式)之前,我们先要懂心法(原理)。
RAG 的核心流程其实就几步,就像把大象装进冰箱一样简单(误):
- 资源获取 (Load Source):首先你得有书。不管是 PDF、Markdown 还是我们今天要用的 EPub 电子书,先得把数据搬进来。
- 切分 (Split):大模型胃口有限(上下文窗口),不能一口吃成个胖子。我们需要把长篇小说切成一个个小片段(Chunk)。
- 向量化 (Embedding):这是最关键的一步!计算机看不懂中文,它只认数字。我们需要把文字片段转换成一串串数字(向量),存入向量数据库(Milvus)。
- 检索 (Retrieve):当用户提问时,把问题也变成向量,去数据库里找最相似的片段。
- 生成 (Generate):把找到的片段作为“参考资料”(Context),连同用户的问题一起扔给大模型:“嘿,根据这些资料,回答这个问题!”
听起来是不是很清晰?接下来,我们进入实战环节!🛠️
🛠️ 第二章:铸剑 —— 环境与工具准备
我们要用到的“神兵利器”有:
- LangChain 🦜🔗:大模型开发的瑞士军刀。
- Milvus 🦅:高性能的开源向量数据库(存数据的藏经阁)。
- OpenAI Embedding & Chat 🧠:提供大脑和向量化能力。
- Node.js 🟢:我们的开发环境。
1. 导入模块:召集各路英雄
我们要创建一个 ebook-writer.mjs 文件,专门负责数据的处理和入库。
// ebook-writer.mjs
// 引入环境变量配置,保护你的 API Key 不泄露
import "dotenv/config";
import { parse } from 'path';
// 🦅 1. 引入 Milvus 客户端及相关类型
// MilvusClient: 用于连接和操作数据库
// DataType: 定义字段类型(比如整数、字符串、向量)
// MetricType: 距离计算方式(比如余弦相似度)
// IndexType: 索引类型(决定检索速度和精度)
import {
MilvusClient,
DataType,
MetricType,
IndexType,
} from '@zilliz/milvus2-sdk-node'
// 🧠 2. 引入 OpenAI 的 Embedding 模型
// 它的作用是把“文字”变成“向量”
import {
OpenAIEmbeddings
} from '@langchain/openai'
// 📚 3. 引入 LangChain 社区的加载器
// 这里我们专门处理 EPub 格式的电子书
import {
EPubLoader
} from '@langchain/community/document_loaders/fs/epub'
// 🔪 4. 引入文本切割器
// RecursiveCharacterTextSplitter 是最常用的切割器
// 它会递归地尝试分割文本,尽量保持语义完整
import {
RecursiveCharacterTextSplitter
} from '@langchain/textsplitters'
2. 初始化配置:排兵布阵
接下来我们要配置一些全局参数,这些参数就像是武功的“内力值”,决定了系统的性能。
// 集合名称,相当于数据库里的表名
const COLLECTION_NAME = 'ebook';
// 向量维度。注意!这个必须和你的 Embedding 模型匹配。
// OpenAI 的 text-embedding-3-small 通常是 1536,但很多老模型或自定义设置是 1024 或 768。
// 这里一定要去查你所用模型的文档,维度错了是存不进去的!
const VECTION_DIM = 1024;
// 切片大小。每个片段包含 500 个字符。
// 太小了语义不完整,太大了检索不精准。500 是个经验值。
const CHUNK_SIZE = 500;
// 切片重叠。让相邻的切片有 50 个字符的重叠。
// 为什么要重叠?为了防止一句话正好被切在两刀中间,导致意思断了。
// 就像接力赛跑,交接棒总得有一段共同跑的距离。
const CHUNK_OVERLAP = 50;
// 我们的目标书籍的路径
const EPUB_FILE = './天龙八部.epub';
// Milvus 的地址和 Token
const ADDRESS = process.env.MILVUS_ADDRESS;
const TOKEN = process.env.MILVUS_TOKEN;
// 获取书名,后面存元数据要用
const BOOK_NAME = parse(EPUB_FILE).name;
console.log('当前处理书籍:', BOOK_NAME);
// 🧠 初始化 Embedding 模型
const embeddings = new OpenAIEmbeddings({
apiKey: process.env.OPENAI_API_KEY,
// 指定使用的模型名称
model: process.env.EMBEDDING_MODEL_NAME,
configuration:{
baseURL: process.env.OPENAI_BASE_URL, // 如果用的是代理或中转,这里很关键
},
dimensions: VECTION_DIM, // 再次强调,维度要对齐!
})
// 🦅 初始化 Milvus 客户端
const client = new MilvusClient({
address: ADDRESS,
token: TOKEN,
})
// 封装一个简单的获取向量的函数
async function getEmbedding(text) {
// embedQuery 是专门用来把查询文本或文档片段变成向量的方法
const result = await embeddings.embedQuery(text);
return result;
}
🏗️ 第三章:藏经阁建设 —— 数据库初始化
数据入库前,我们得先建好“仓库”。在 Milvus 中,这个仓库叫 Collection(集合)。
我们来看看 main 函数和 ensureBookCollection 函数的设计。
1. 主流程控制
async function main() {
try{
console.log('📖 电子书处理程序启动...');
console.log('🔌 正在连接 Milvus...');
// ⚡ 重点:等待连接成功
// connectPromise 是 Milvus SDK 提供的一个属性,await 它能确保连接建立后再进行后续操作
await client.connectPromise;
console.log('✅ Milvus 连接成功');
const bookId = 1; // 假设这本书 ID 为 1
// 第一步:确保存放数据的集合(表)已经建好了
await ensureBookCollection(bookId);
// 第二步:开始流式加载并处理电子书
await loadAndProcessEPubStreaming(bookId);
} catch(err) {
console.error('❌ 程序执行出错:', err);
}
}
2. 确保集合存在(建表)
这一步非常关键,相当于 MySQL 里的 CREATE TABLE IF NOT EXISTS。但向量数据库有它独特的 Schema(结构)。
async function ensureBookCollection(bookId) {
try {
// 🔍 检查集合是否已经存在
const hasCollection = await client.hasCollection({
collection_name: COLLECTION_NAME,
})
console.log('集合是否存在状态:', hasCollection);
// ⚠️ 注意:hasCollection 返回的是一个对象,.value 才是布尔值
if (!hasCollection.value) {
console.log(`🚧 ${COLLECTION_NAME} 集合不存在,开始创建...`);
// 🏗️ 创建集合与定义 Schema
await client.createCollection({
collection_name: COLLECTION_NAME,
// schema 定义字段
fields: [
// id: 主键,VarChar 类型
{ name: 'id', data_type: DataType.VarChar, max_length: 100, is_primary_key: true },
// book_id: 书籍 ID,方便后续按书筛选
{ name: 'book_id', data_type: DataType.VarChar, max_length: 100 },
// book_name: 书名
{ name: 'book_name', data_type: DataType.VarChar, max_length: 100 },
// chapter_num: 章节号
{ name: 'chapter_num', data_type: DataType.Int32 },
// index: 片段在章节中的序号,用于排序
{ name: 'index', data_type: DataType.Int32 },
// content: 具体的文本内容,最大长度设大点,防止溢出
{ name: 'content', data_type: DataType.VarChar, max_length: 10000 },
// vector: 最核心的向量字段,FloatVector 类型,维度必须匹配
{ name: 'vector', data_type: DataType.FloatVector, dim: VECTION_DIM },
]
});
console.log('✅ 集合创建成功');
// 🚀 创建索引
// 就像给字典加目录,不建索引的话,搜索会非常慢(暴力扫描)
await client.createIndex({
collection_name: COLLECTION_NAME,
field_name: 'vector', // 给向量字段建索引
index_type: IndexType.IVF_FLAT, // 倒排文件索引,平衡速度和召回率
metric_type: MetricType.COSINE, // 相似度计算用余弦相似度(方向一致性)
params: {
nlist: 1024, // 聚类中心的数量,跟数据量有关
}
});
console.log('✅ 索引创建成功')
}
// 📥 加载集合
// Milvus 的特性:集合创建后必须 Load 进内存才能被检索
try {
await client.loadCollection({
collection_name: COLLECTION_NAME // 注意代码里的 typo 修正:collection_name
});
console.log('✅ 集合加载成功,准备就绪');
} catch(err) {
// 如果已经加载过,可能会报错,忽略即可
console.log('ℹ️ 集合可能已处于加载状态')
}
} catch(err) {
console.error('❌ 创建集合失败:', err.message);
throw err; // 抛出错误,中断流程
}
}
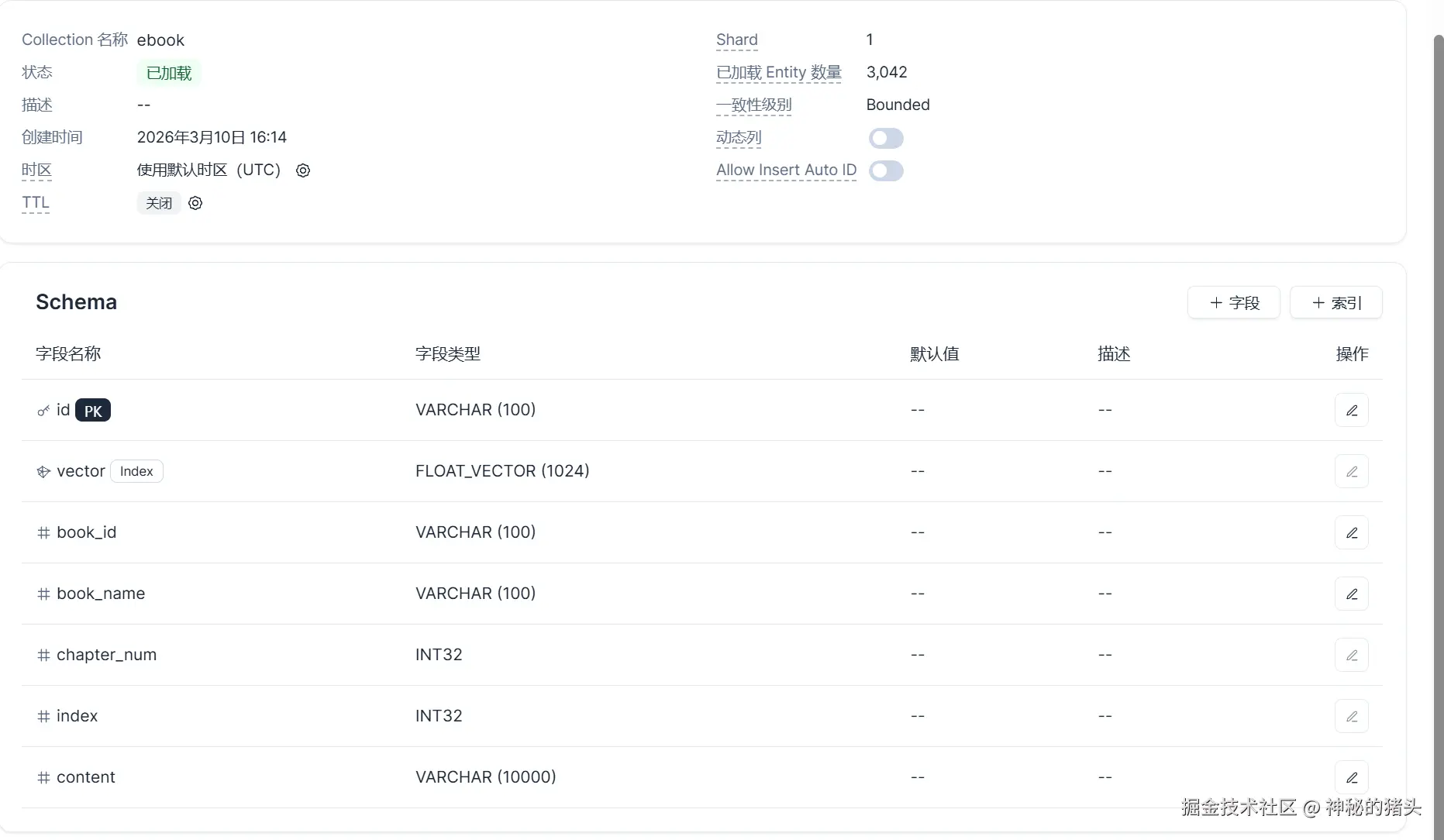
云端数据库查看表结构:
🔪 第四章:庖丁解牛 —— 文本处理与向量化
这里是整个数据处理的核心。我们需要把 EPUB 文件变成一条条可以入库的记录。
1. 加载与切割
async function loadAndProcessEPubStreaming(bookId) {
try {
console.log('📂 开始加载 EPUB 文件...');
// 1. 初始化 Loader
// splitChapters: true 表示它会尝试按章节帮你把书拆开,这非常有用!
const loader = new EPubLoader(
EPUB_FILE,
{
splitChapters: true
}
);
// load() 返回的是 Document 对象数组
const documents = await loader.load();
console.log(`📚 书籍加载完毕,共识别到 ${documents.length} 个章节`);
// 2. 初始化 Splitter (切割器)
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: CHUNK_SIZE,
chunkOverlap: CHUNK_OVERLAP,
// separators: 默认不需要填
// 默认分隔符优先级:["\n\n", "\n", " ", ""]
// 它会优先在段落间切,段落太长就在换行切,还不行就在空格切...
// 这样能最大程度保留语义完整性
});
let totalInserted = 0;
// 3. 逐章处理
// 为什么不用 Promise.all 并发处理所有章节?
// 因为书可能很大,一次性全部读入内存并处理可能会爆内存 (OOM)。
// 逐章处理比较稳妥。
for (let chapterIndex = 0; chapterIndex < documents.length; chapterIndex++) {
const chapter = documents[chapterIndex];
const chapterContent = chapter.pageContent;
console.log(`🔄 正在处理第 ${chapterIndex + 1}/${documents.length} 章`);
// 开始切割这一章的内容
const chunks = await textSplitter.splitText(chapterContent);
console.log(` 👉 本章拆分为 ${chunks.length} 个片段`);
if (chunks.length === 0) {
console.log(` ⚠️ 跳过空章节`);
continue;
}
console.log(' ⚡ 生成向量并插入中...');
// 调用批量插入函数
const insertedCount = await insertChunksBatch(chunks, bookId, chapterIndex + 1);
totalInserted += insertedCount;
console.log(` ✅ 成功插入 ${insertedCount} 个片段 (累计: ${totalInserted})`);
}
console.log(`\n🎉 全部处理完成! 共插入 ${totalInserted} 个知识片段`);
return totalInserted;
} catch(err) {
console.error('❌ 加载 EPUB 文件失败:', err.message);
throw err;
}
}
2. 批量向量化与入库(性能优化的关键点)
这里有一个非常重要的性能优化技巧:并发 Embedding。
如果我们一个一个片段去调 OpenAI 的接口,那速度会慢到让你怀疑人生。利用 Promise.all 可以并发请求,速度提升几十倍!
async function insertChunksBatch(chunks, bookId, chapterNum) {
try {
if (chunks.length === 0) {
return 0;
}
// 🚀 性能优化核心:Embedding 并发
// 我们利用 map 生成一组 async 任务,然后用 Promise.all 等待它们全部完成
const insertData = await Promise.all(
chunks.map(async (chunk, chunkIndex) => {
// 每一小块文本都要变成向量
const vector = await getEmbedding(chunk);
// 返回符合 Milvus Schema 的数据结构
return {
// 构造一个唯一的 ID,方便排查问题
id: `${bookId}_${chapterNum}_${chunkIndex}`,
book_id: bookId,
book_name: BOOK_NAME,
chapter_num: chapterNum,
index: chunkIndex,
content: chunk, // 原文内容也要存,不然检索出来只有向量没法看
vector // 向量数据
}
})
)
// 📥 批量插入数据库
// insert 接口支持一次插入多条数据,效率远高于逐条插入
const insertResult = await client.insert({
collection_name: COLLECTION_NAME,
data: insertData,
})
return Number(insertResult.insert_cnt) || 0;
} catch(err) {
console.error('❌ 插入片段失败:', err.message);
throw err;
}
}
🔍 第五章:小试牛刀 —— 向量检索测试
数据入库后,我们怎么知道对不对呢?写个 ebook-query.mjs 测试一下。
这个脚本不需要大模型参与,只是单纯测试“找得准不准”。
// ebook-query.mjs
// ... (引入模块和初始化的代码与 writer 类似,略过) ...
async function main() {
try{
console.log('Connection to Milvus...');
await client.connectPromise;
// 必须先 Load 集合
await client.loadCollection({
collection_name: COLLECTION_NAME
});
// ❓ 提出一个测试问题
const query = '段誉会什么武功?';
console.log(`❓ 问题: ${query}`);
// 1. 把问题变成向量
const queryVector = await getEmbedding(query);
// 2. 在数据库中搜索最相似的向量
const searchResult = await client.search({
collection_name: COLLECTION_NAME,
vector: queryVector, // 问题的向量
limit: 3, // 只取前 3 个最相似的结果
metric_type: MetricType.COSINE, // 使用余弦相似度
// 指定要返回哪些字段,content 最重要
output_fields: ['id','content','book_id','chapter_num','index','book_name'],
})
// 3. 打印结果
searchResult.results.forEach((item,index) => {
console.log(`\n🏆 第 ${index+1} 个结果 (相似度 Score: ${item.score.toFixed(2)})`);
console.log(`📄 内容片段: ${item.content}`);
console.log(`📍 来源: 第 ${item.chapter_num} 章`);
})
} catch(err) {
console.error('Test failed:', err.message);
}
}
运行这个脚本,如果能在控制台看到关于“六脉神剑”、“凌波微步”的小说原文片段,说明我们的数据库已经构建成功了!🎉
🤖 第六章:神功大成 —— RAG 完整实现
最后,我们将所有模块串联起来,实现真正的问答。创建 ebook-rag.mjs。
1. 引入 Chat 模型
这次我们需要引入 ChatOpenAI,因为它才是负责说话的那个“人”。
// ebook-rag.mjs
import {
ChatOpenAI
} from '@langchain/openai'
// ... (Milvus 和 Embedding 初始化同上) ...
// 🤖 初始化大语言模型
const model = new ChatOpenAI({
temperature: 0.7, // 0.7 比较平衡,既有创造性又不会太发散
model: process.env.MODEL_NAME, // 比如 gpt-4o 或 gpt-3.5-turbo
apiKey: process.env.OPENAI_API_KEY,
configuration:{
baseURL: process.env.OPENAI_BASE_URL,
},
});
2. 检索函数封装
async function retrieveContent(question, k=3) {
try {
// 问题 -> 向量
const queryVector = await getEmbedding(question);
// 向量 -> 搜索 -> 结果
const searchResult = await client.search({
collection_name: COLLECTION_NAME,
vector: queryVector,
limit: k,
metric_type: MetricType.COSINE,
output_fields: ['content', 'chapter_num'],
})
return searchResult.results;
} catch(err) {
console.error('检索内容失败:', err.message);
return [];
}
}
3. 核心问答逻辑:Prompt 工程
这是 RAG 的灵魂。我们需要构建一个 Prompt,告诉 AI:“你不要瞎编,要根据我给你的这些资料来回答”。
async function answerEbookQuestion(question, k=3) {
try {
console.log('🤔 正在思考问题:', question);
// 1. 检索相关内容
const retrievedContent = await retrieveContent(question, k);
console.log(`📚 检索到 ${retrievedContent.length} 条相关资料`);
if (retrievedContent.length === 0) {
return '抱歉,我在书中没有找到相关内容。';
}
// 2. 构建上下文 (Context)
// 把检索到的多个片段拼接成一个字符串
const context = retrievedContent
.map((item, i) =>
`[资料片段 ${i+1}]
章节:第 ${item.chapter_num} 章
内容:${item.content}`
).join('\n\n-----\n\n');
// 3. 构建 Prompt (提示词)
// 这里的提示词设计很重要,要强调“基于内容回答”
const prompt = `
你是一个专业的《天龙八部》小说专家助手。
请严格根据以下提供的小说片段回答用户问题。如果片段中没有答案,请直接说明,不要编造。
=== 参考资料 ===
${context}
=== 资料结束 ===
用户问题:${question}
回答要求:
1. 结合小说情节,语言风格可以生动一些。
2. 引用原文中的关键描述来支持你的观点。
3. 答案要准确、完整。
AI 专家的回答:
`
// 4. 调用大模型
const response = await model.invoke(prompt);
// 5. 返回结果
return response.content;
} catch(err) {
console.error('回答出错:', err);
return '抱歉,修炼走火入魔了,暂时无法回答。';
}
}
4. 主函数调用
async function main() {
try {
await client.connectPromise;
await client.loadCollection({ collection_name: COLLECTION_NAME });
// 🎤 提问时间!
const answer = await answerEbookQuestion('段誉第一次遇见王语嫣是在哪里?发生了什么?');
console.log('\n💬 AI 回答:\n', answer);
} catch(err) {
console.error('系统错误:', err.message);
}
}
main();
🎉 总结
恭喜你!到这里,你已经亲手打造了一个基于《天龙八部》的 RAG 系统。
我们回顾一下今天的知识点:
- 数据清洗:利用
EPubLoader和RecursiveCharacterTextSplitter把书拆成小块。 - 向量存储:利用
OpenAI Embedding和Milvus构建了私有知识库。 - RAG 生成:通过
Search+Prompt+LLM的组合拳,实现了有理有据的问答。
现在的 AI 就像是一个刚学会认字的孩童,而 RAG 就是我们塞给他的《百科全书》。只要你的知识库足够丰富(比如塞进去几百本编程书、医学书),他就能成为任何领域的专家!
还在等什么?快去把你硬盘里的电子书都喂给它吧!💪
Happy Coding! 👩💻👨💻
希望这篇文章能帮你深入理解 RAG 的实现流程。如果有任何问题,欢迎在评论区交流讨论!
